Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
AI Gateway: The Central Control Pane of Today’s Generative AI Infrastructure
In our recent webinar on AI Gateway, we kicked things off by checking where the audience currently stands in their generative AI (genAI) journey.
Interestingly, over 50% shared that they already have genAI running in production, and another 15% are scaling it across multiple teams—clear signs of strong enterprise adoption and growing maturity in deploying genAI applications.
The Evolution of the LLM Gateway as a Central Control Plane
We focused on how the AI gateway has evolved over the past 6 to 9 months—from a basic model routing layer to becoming a critical central control plane within the modern generative AI stack
Initially, LLMs were used primarily to generate single-turn responses to prompts, viewed largely as advanced next-word predictors.
Current State of Agents: Fast forward to 2025, LLM-powered agents have become autonomous and goal-oriented, capable of invoking multiple tools and systems behind the scenes. For example, a password reset agent can authenticate a user, call APIs to reset passwords, and send confirmation emails—all without human intervention.
Organizational Complexity: Enterprises often run dozens of such complex agents spanning multiple teams, using various models from different providers, frameworks, and infrastructures (including hyperscalers and hybrid clouds).
Challenges Without Centralization: This decentralization causes significant governance issues, including inconsistencies in model APIs, deployability, auditability, cost management, and failover strategies.
The LLM gateway has become indispensable as the central gateway consolidating these diverse resources and operational needs, enabling governance, observability, cost control, and reliability at scale.
Challenges Faced by Enterprises Using Multiple LLM Providers
Inconsistent API Formats: Despite general claims of OpenAI API compatibility, providers differ in parameter syntax (e.g., max tokens, temperature ranges, stop sequences), complicating switchability and interoperability.
Frequent Outages: Model providers are themselves startups, with frequent downtimes causing application failures; thus, applications must be model-agnostic and able to failover gracefully.
High Latency Variance: Latency across providers fluctuates widely, making application performance unpredictable. Latency impacts user experience as severely as full downtime.
Complex Rate Limits: Multiple rate limits per provider require throttling and cost controls across business units and cost centers. Centralized enforcement is difficult but essential.
Hybrid Infrastructure Demands: Many enterprises must manage rate limits and key rotations across cloud providers and on-prem GPU infrastructure.
Costly Repeat Queries: Generative AI applications often receive many identical or semantically similar queries (e.g., greeting messages), increasing the cost of generative AI unnecessarily unless mitigated by semantic caching.
Guardrails and Compliance: Enterprises require prompt-level input filtering (e.g., no PII leaks) and output validation (filtering profanity) across multiple teams and models, necessitating central enforcement.
Governance and Audit Requirements: Requests may span multiple providers and data sources within a single UI action, so enterprises demand centralized observability, audit logging, explainability, and traceability to meet compliance needs.
These challenges justify the role of the best LLM gatewaysas the core control plane in enterprise generative AI ecosystems.
Core Functions and Benefits of an AI Gateway
An AI gateway plays a key role in addressing these challenges by offering a range of technical capabilities designed to streamline model access, governance, and reliability.
Key Gateway Functionalities:
Unified API Layer: Provides a single, consistent API interface abstracting away provider-specific details and authentication mechanisms. This ensures:
No vendor lock-in.
Seamless switching of providers without code changes.
Simplified SDK usage for developers.
Centralized Key Management: Manages diverse authentication methods (AWS IAM roles, OpenAI API keys, GCP identities) through a unified system. Benefits include:
User-level API key issuance for traceability.
Service accounts or virtual keys for applications.
Easy key rotation and management.
Avoids blanket API key sharing and enables finer permission controls.
Retries and Callbacks: Handles provider outages gracefully with automated failover policies. Configurable fallback from one model to another ensures uninterrupted service without impacting application code.
Rate Limiting and Cost Controls: Enables precise enforcement of API usage policies on a per-user, per-application, or per-business-unit basis. Examples include:
Load Balancing: Automates routing of requests to the fastest or most reliable model in real-time, performing latency-based load balancing and health checks.
Canary Rollouts for New Models: Facilitates gradual, controlled rollout of new model versions, enabling testing and performance comparison before full migration.
Different Types of Load Balancing
Central Guardrails : Implements enterprise-wide prompt and response filters such as:
PII removal before sending data externally.
Detection and removal of profanity or harmful content in responses.
Ability to block or mutate prompts centrally.
Transparent integration so application developers do not need to manage these rules individually.
Semantic Caching: Maintains a cache of semantically similar prompt-response pairs to reduce model calls, decreasing latency and costs for repetitive queries.
Key Benefits
Strong central governance for enterprises.
Immediate ability to swap models and providers without downtime.
Auditable and observable access to all model interactions with granular metrics.
Reduced engineering effort in managing multi-model complexity.
Enhanced user experience with failover and latency optimizations.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Future Vision: Integration with MCP Servers with AI Gateway
In future, the LLM gateway will extend beyond models to manage entire tools and agents via MCP and A2A protocols -
What is an MCP Server?
An MCP server exposes product APIs (e.g., Slack channels, messages, users) in a form that LLM-based agents can discover and consume.
Example: A Slack MCP server exposes APIs to read channels, messages, and send messages, all understandable by an LLM agent.
Agent Interaction with MCP Servers:
Agents query the MCP server to identify available tools.
Based on a natural language request, the agent autonomously plans and calls the correct sequence of tools (e.g., retrieving messages, summarizing, creating Jira tasks).
Gateway Integration with MCP:
The gateway will act as a unified access point for both LLM models and MCP servers within an organization.
Users will be able to issue natural language commands (e.g., “Create tasks in Jira based on my Slack messages”) across integrated tools without coding.
Authentication will be seamlessly managed, federated through existing identity providers like Okta or Azure AD.
This integration empowers non-technical users to automate business processes easily.
Unified access point for both LLM models and MCP servers within an organization
Centralized auditing and governance over all agent activities and tool invocations.
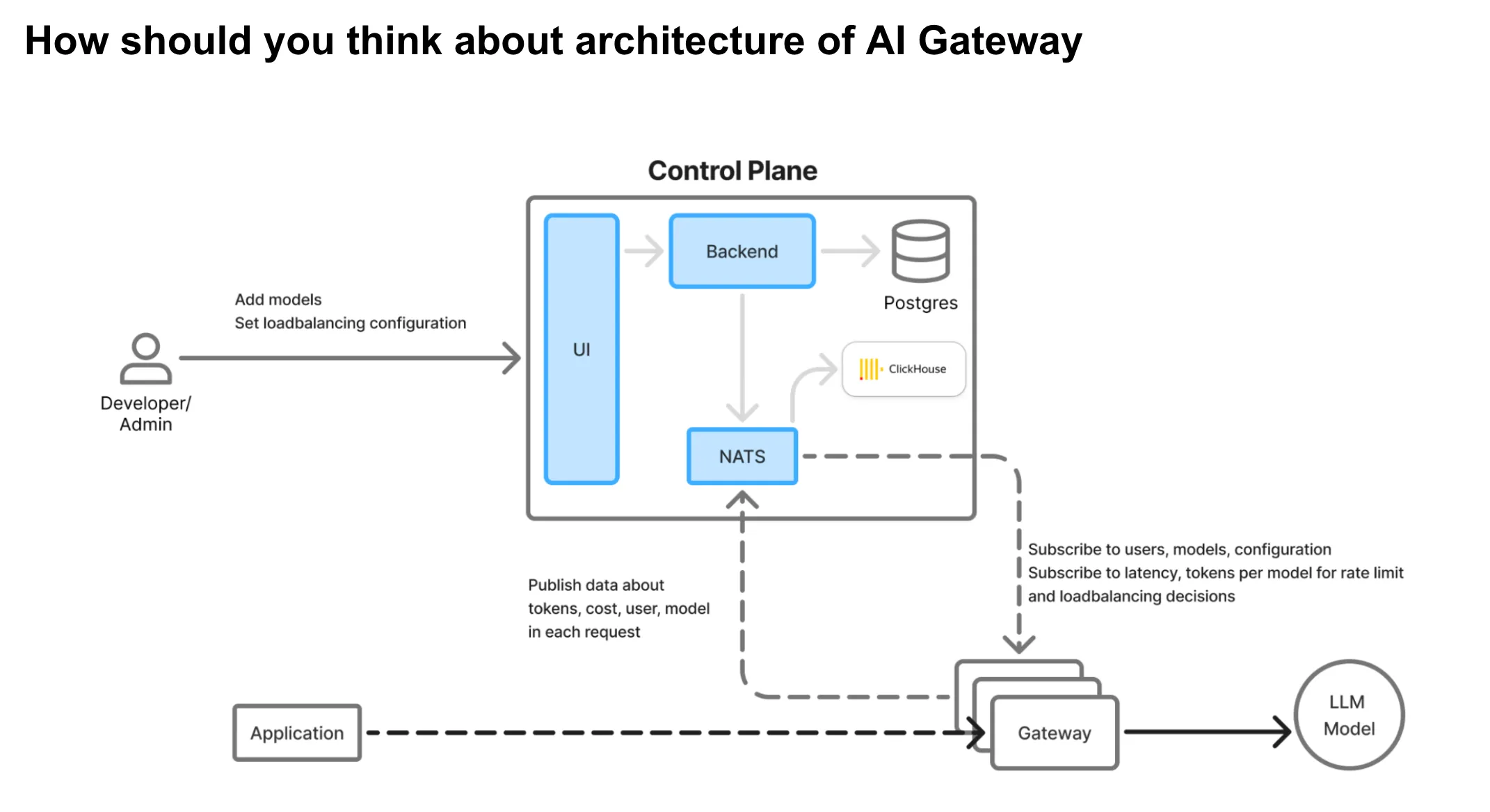
AI Gateway Architecture
The AI Gateway functions as the critical proxy layer between applications and language model (LLM) providers. Because the gateway lies in the critical path of production traffic, it must be designed with the following core principles in mind:
Key Architectural Priorities:
High Availability: The gateway must not become a single point of failure. Even in the face of dependency issues (like database or queue outages), it should continue serving traffic gracefully.
Low Latency: Since it sits inline with every inference request, the gateway must add minimal overhead to ensure a snappy user experience.
High Throughput and Scalability: The system should scale linearly with load and be able to handle thousands of concurrent requests with efficient resource usage.
No External Dependencies in the Hot Path: Any network-bound or disk-bound operations should be offloaded to asynchronous systems to prevent performance bottlenecks.
In-Memory Decision Making: Critical checks like rate limiting, load balancing, authentication, and authorization should all be performed in-memory for maximum speed and reliability.
Separation of Control Plane and Proxy Plane: Configuration changes and system management should be decoupled from live traffic routing, enabling global deployments with regional fault isolation.
TrueFoundry’s AI Gateway embodies all of the above design principles, purpose-built for low latency, high reliability, and seamless scalability.
TrueFoundry's AI Gateway Architecture
Built on Hono Framework: The gateway leverages Hono, a minimalistic, ultra-fast framework optimized for edge environments. This ensures minimal runtime overhead and extremely fast request handling.
Zero External Calls on Request Path: Once a request hits the gateway, it does not trigger any external calls (unless semantic caching is enabled). All operational logic is handled internally, reducing risk and boosting reliability.
In-Memory Enforcement: All authentication, authorization, rate-limiting, and load-balancing decisions are made using in-memory configurations, ensuring sub-millisecond response times.
Asynchronous Logging: Logs and request metrics are pushed to a message queue asynchronously, ensuring that data observability does not block or slow down the request path.
Fail-Safe Behavior: Even if the external logging queue is down, the gateway will not fail any requests. This guarantees uptime and resilience under partial system failures.
Horizontally Scalable: The gateway is CPU-bound and stateless, which makes it easy to scale out. It performs efficiently under high concurrency and low memory usage.
True Foundry’s AI Gateway
Multi-provider Support: Easily add and manage models from AWS, GCP, OpenAI, Anthropic, DeepInfra, and custom/self-hosted options.
Unified Playground: Test and run prompts against any model through one interface. API keys and model names are configurable with no need for code changes.
Prompt Management with Guardrails: Shows real-time redaction of sensitive data during prompt submission, integrated with the centralized guardrails server.
Detailed Metrics and Observability:
Live tracking of who is calling which model.
Detailed latency statistics including “time to first token” and “inter-token latency” (critical for LLM performance monitoring).
Rate limiting, fallback, and guardrail trigger statistics.
Audit logs of all request-response pairs, exportable for compliance.
Configurable Admin Settings: Define rate limits by developer or team, set fallback policies, Latency-based routing, and manage guardrails centrally.
MCP Server Integration Roadmap: Preview of upcoming functionality supporting all internal MCP servers for tools like Gmail, Slack, Confluence, Jira, GitHub, and custom APIs.
Live Q&A: Addressing Scalability, Integration, and Technical Queries
The session concludes with audience Q&A covering:
Gateway Scalability: Designed to be horizontally scalable; performance benchmarks show one CPU can handle 350 requests per second (RPS), requiring scale-out deployments for higher rates.
Latency and Stability: Gateway provides callback and retry mechanisms for higher reliability and automatically switches models when providers face outages.
Model Input Size Limits: Models cannot handle extremely large inputs (e.g., 500 MB); recommended to use retrieval-augmented generation (RAG) systems.
Framework Integrations: Compatible with major agent-building frameworks such as LangChain, LangGraph using standard OpenAI-compatible APIs without need for special SDKs.
Programming Language Support: Gateway is built using performant, lightweight frameworks (Hono, similar to those used in Cloudflare workers), and is language agnostic for API clients (Python, JavaScript, Go, etc.).
Rapid Adaptation to New Model APIs: Continuous updates to support vendor-specific parameters and multimodal inputs with rigorous documentation.
Governance and Auditing Tools: Ability to export detailed latency, usage, and cost data for audits aligned with governance needs.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.































.webp)











.webp)
.webp)
.webp)


