.webp)
July 10, 2026
|
5 min read

Published: June 29, 2026

Blazingly fast way to build, track and deploy your models!
Every LLM request that passes through TrueFoundry AI Gateway generates a trace. That trace captures the full span tree of the request: gateway handling and JWT validation and authorization resolution and provider routing and the outbound model call and the streamed response. These traces are stored internally for the TrueFoundry Monitor UI. But they can also be exported over standard OpenTelemetry protocols to external observability backends. Arize is one such backend.
This post walks through how the trace export works at the architecture level: what OTEL primitives are involved and how the gateway emits traces without adding latency to the request path and what Arize does with the trace data once it arrives. It also covers the configuration surface and the data privacy controls that let you strip prompt content before it leaves your infrastructure.
OpenTelemetry defines a vendor neutral wire format for distributed traces. A trace is a tree of spans connected by parent child relationships. Each span represents a discrete unit of work: one HTTP handler or one LLM call or one tool invocation. Spans carry typed key value attributes that encode operational context like latency and status codes and token counts.
The standard OTEL semantic conventions cover general purpose distributed systems well but they were not designed for LLM workloads. LLM calls carry structured inputs (multi turn message arrays with system prompts and tool definitions and multimodal content) and structured outputs (completions with finish reasons and function calls). Token economics are first class operational metrics: prompt tokens and completion tokens and cached tokens and reasoning tokens all need to be tracked per span. A single input.value string attribute is insufficient.
This is where LLM specific semantic conventions come in. Arize maintains the OpenInference specification which defines a concrete attribute schema and span kind taxonomy on top of OTEL spans. Every OpenInference trace is a valid OTLP trace. The conventions give attribute names their AI specific meaning. Span kinds like LLM and CHAIN and RETRIEVER and TOOL and EMBEDDING classify operations so observability platforms can render traces with AI aware visualizations and aggregations.
TrueFoundry AI Gateway emits traces using its own attribute namespace (tfy.input and tfy.output and tfy.input_short_hand along with standard gen_ai.* attributes for token counts and model metadata and completion finish reasons). Arize ingests these as valid OTLP traces and maps the attributes into its trace UI.
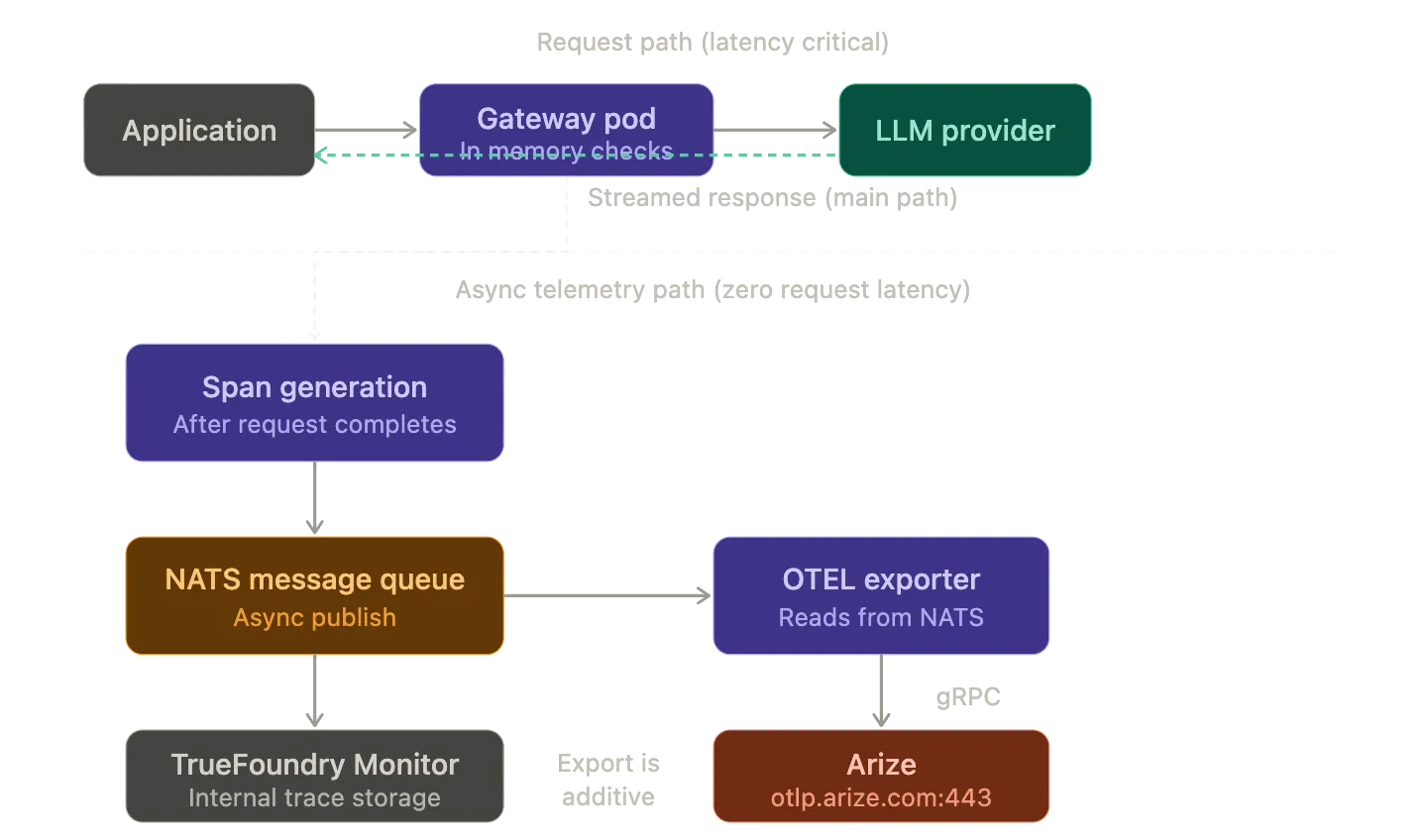
TrueFoundry AI Gateway uses a split architecture: a control plane that manages configuration and a gateway plane that processes inference requests. The gateway plane is built on the Hono framework which is an ultra fast edge optimized HTTP runtime. A single gateway pod on 1 vCPU and 1 GB RAM handles 250+ requests per second with approximately 3 ms of added latency.
The critical design principle is that there are no external calls in the request path except the actual LLM provider call. When a request arrives at a gateway pod the following happens entirely in memory:
Trace generation happens asynchronously alongside this flow. The gateway creates OTEL spans for each stage of the request lifecycle: the inbound HTTP handler and the authentication check and the model resolution and the outbound provider call and the streaming response. These spans carry attributes that capture token usage and latency and model name and provider and cost estimate and request metadata. After the request completes the gateway publishes the trace data to a NATS message queue. This is the same NATS bus that handles configuration sync between the control plane and gateway pods.
The OTEL exporter picks up trace data from this async path and forwards it to the configured external endpoint. Because trace export is decoupled from the request path it adds zero latency to inference requests. The gateway never fails a request even if the external OTEL endpoint is unreachable.

Arize is an AI observability and evaluation platform built specifically for LLM and agent workloads. It accepts OTEL traces over gRPC at otlp.arize.com:443 and provides several layers of analysis on top of the raw trace data.
Trace visualization. Arize renders full trace waterfalls showing the span tree for each request. You can inspect individual spans to see token usage and latency breakdown and input output content and model metadata. For agent workflows where a single user request triggers multiple LLM calls and tool invocations this waterfall view makes the execution path legible.
Performance analytics. Arize computes aggregate metrics across your trace stream: latency distributions by model and by provider and error rates over time and throughput trends. You can set up alerting rules that fire when anomalies appear in these distributions. This is useful for catching provider degradation before it impacts end users.
LLM evaluation. Beyond raw tracing Arize supports automated evaluation pipelines. You can run LLM as a Judge workflows that score completions on dimensions like relevance and coherence and factuality. You can also bring in human annotation workflows for more nuanced quality assessment. The traces provide the raw data (inputs and outputs and model parameters) that feed these evaluation loops.
The key differentiator is that Arize understands LLM specific semantics natively. It parses token counts and model identifiers and prompt content out of span attributes and surfaces them in purpose built views rather than treating them as generic string key value pairs.
The integration is a direct gRPC export from the gateway to Arize. No collector sidecar is needed. No custom SDK is involved. You configure the OTEL exporter in the TrueFoundry dashboard and traces start flowing.
You can follow the integration steps here: https://www.truefoundry.com/docs/ai-gateway/arize
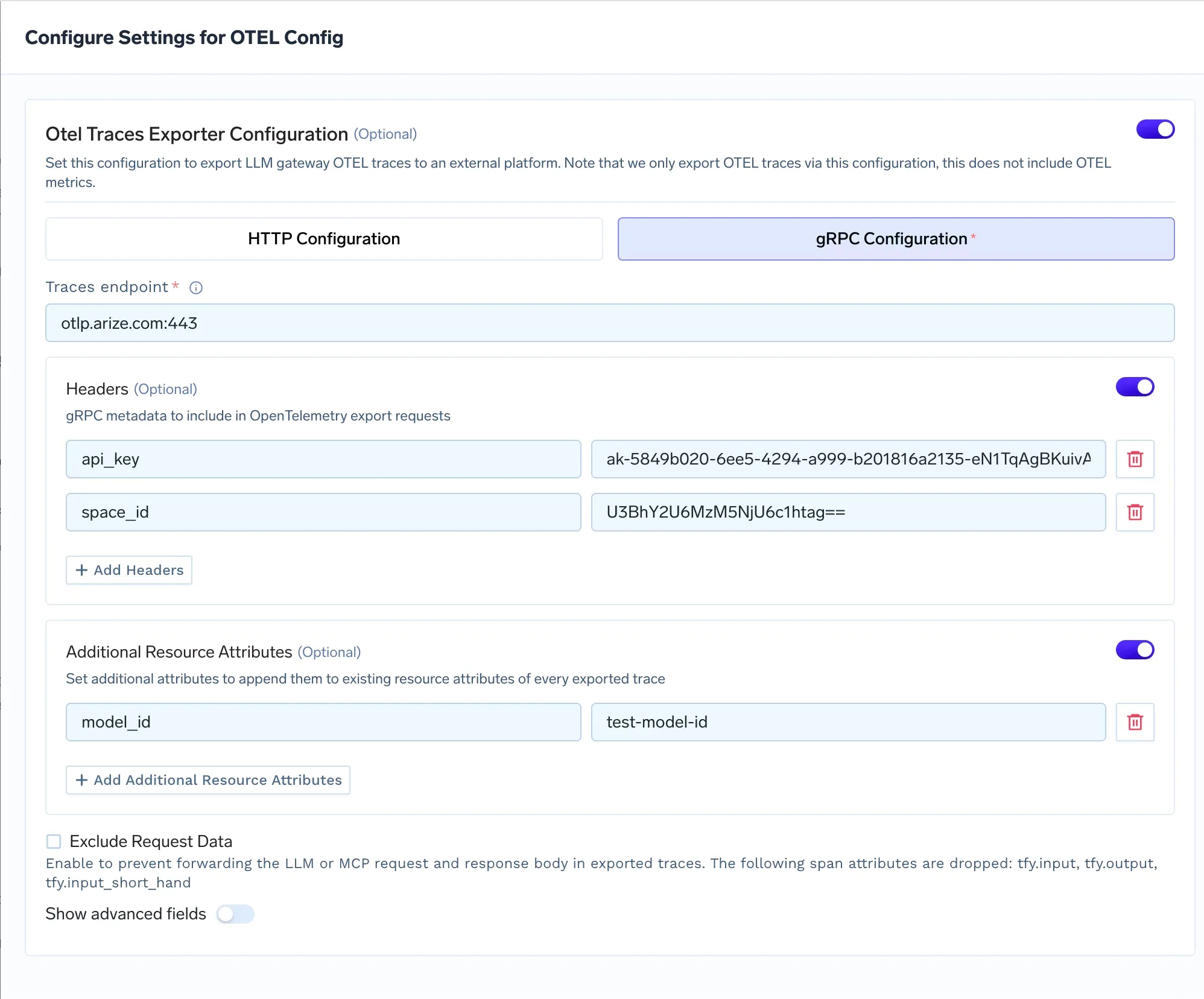
You can attach additional resource attributes to every exported trace. These are key value pairs that get appended at the trace level and are useful for filtering and grouping in Arize.
The most common attribute to set is model_id. Arize uses this to group traces by model in its dashboard views. If you are routing production traffic through a fine tuned LLama model you might set model_id to finetuned-llama-3-production. You can also add model_version if you are running parallel deployments and want to compare performance across versions in Arize.
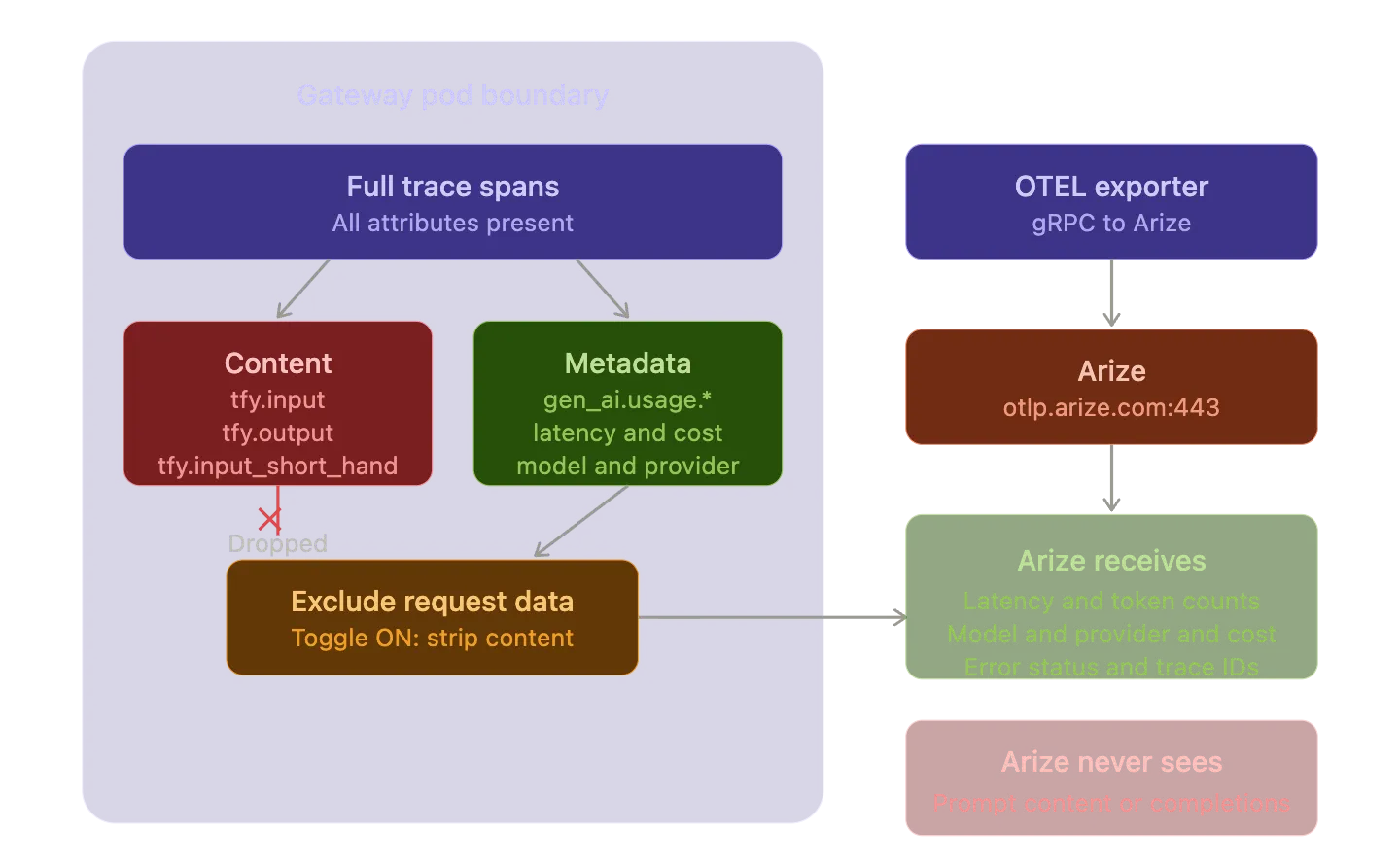
There are deployment scenarios where prompt content and completion content must not leave your infrastructure. Compliance requirements might prohibit sending request bodies to third party services. PII in prompts might make external export a non starter.
TrueFoundry handles this with the Exclude Request Data toggle in the OTEL exporter configuration. When enabled the gateway drops three span attributes before export: tfy.input and tfy.output and tfy.input_short_hand. Arize still receives the structural trace data (latency and token counts and model metadata and error status) but never sees the actual content of prompts or completions.
This is an important architectural detail. The filtering happens at the gateway level before the trace data hits the gRPC exporter. The content never leaves the gateway pod. You get full observability over performance and cost and reliability without exposing sensitive content to an external platform.
After saving the OTEL configuration send a few LLM requests through the gateway. Then open the Arize dashboard and navigate to Traces. Look for traces from the tfy-llm-gateway service. Each trace should show the full span tree with gateway handling spans and the outbound LLM provider call span. Click into individual spans to verify that token usage and latency and model metadata are populated correctly.
If you configured resource attributes you should see those reflected in the trace metadata. Use the model_id attribute to filter the trace list and verify that traces are grouping correctly by model.
The data flow is straightforward. Applications send LLM requests to TrueFoundry AI Gateway. The gateway processes the request in memory (authentication and authorization and routing and rate limiting) and forwards it to the configured model provider. In parallel the gateway generates OTEL spans for the request lifecycle and publishes them asynchronously to the NATS message queue. The OTEL exporter reads from this queue and sends traces over gRPC to otlp.arize.com:443. Arize ingests the OTLP traces and makes them available for visualization and analysis and evaluation.
No external calls are added to the inference path. No collector sidecars need to be deployed. No application code changes are required. The gateway is the single instrumentation point and the OTEL export is additive to the gateway's own internal trace storage. You can export to Arize while continuing to use TrueFoundry's built in Monitor UI for the same trace data.
This is the pattern that makes OTEL valuable as a protocol choice. The gateway emits standard OTLP traces. Arize accepts standard OTLP traces. If you decide to switch observability backends tomorrow you change the endpoint and headers in the gateway configuration and point at a different OTLP receiver. Your application code and your gateway configuration and your trace instrumentation stay exactly the same.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.webp)
.webp)
.webp)







.png)
.webp)