














June 26, 2026
|
5 min read

Published: May 12, 2026

Blazingly fast way to build, track and deploy your models!
Healthcare, financial, and a few other sectors are deploying generative AI without ever touching the public internet. Air-gapped is not a configuration flag — it is an architecture where every dependency the system needs at runtime is already inside the enclave.
"Air-gapped" is not a marketing claim about the deployment shape. It is the deployment shape's foundational constraint. Everything else follows from "no route to the outside."
In a typical enterprise deployment, "isolated" means a private VPC, a NAT gateway, restricted egress, and an allowlist of approved external endpoints — package registries, model APIs, telemetry endpoints, identity providers. The system is segregated; it is not isolated. Egress exists, controlled but present. An auditor asking "what does the system phone home to?" gets a list of allowlisted destinations, not silence.
Air-gapped is a stronger claim. There is no NAT gateway. There is no DNS server that resolves external hostnames. There is no certificate authority chain that trusts anything outside the enclave. There is — depending on the regime — either no network connection to the outside at all, or only a one-way data diode for telemetry export. Code, data, and dependencies enter via signed physical media; nothing enters by network. The auditor asking the same question gets a definitive answer: nothing leaves, nothing enters, except on the controlled cadence the deployment was certified against.
This is the deployment posture for classified defense workloads (typical accreditation frameworks: DoD IL5 and IL6, FedRAMP High, sometimes CMMC Level 2 or Level 3 for the defense industrial base), for healthcare systems handling controlled clinical data (HIPAA with HITRUST CSF attestation, sometimes additional state-level requirements), for financial systems under stricter regulatory regimes (FFIEC and SR 11-7 for bank model risk, NYDFS Part 500 for cyber), and for industrial control environments where any outbound traffic is forbidden by policy. The distinction matters legally, not just operationally: an "isolated" deployment may still constitute a data transfer to a vendor under some regulatory frameworks; an air-gapped deployment, by construction, cannot.
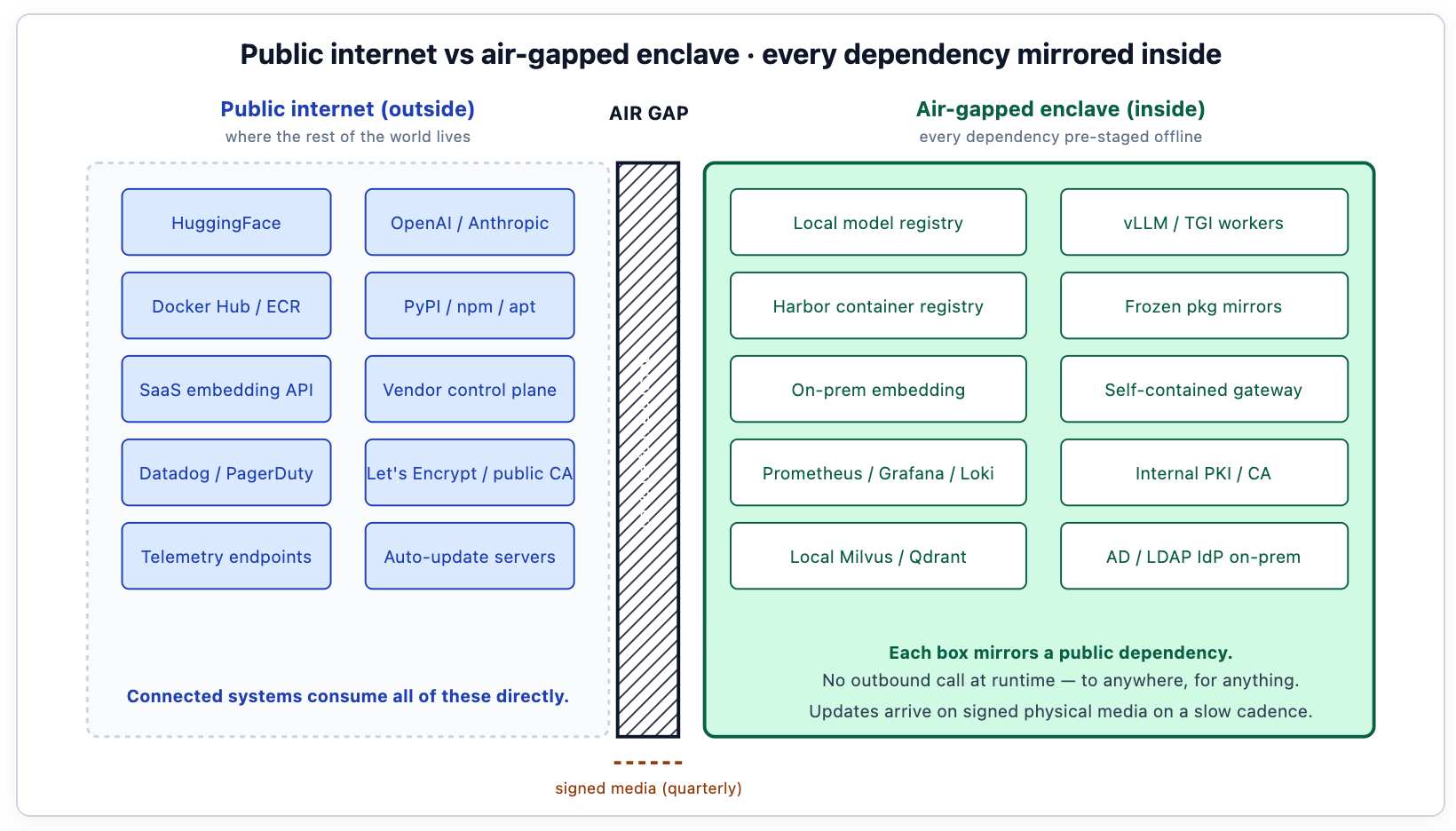
The diagram is the architecture. Every component that an internet-connected deployment would consume from somewhere external has to have a mirror inside the enclave. The mirror exists; the consumption is local. The integrity of the deployment depends on every byte of every dependency being accountable — versioned, signed, scanned, and frozen at staging time. The right side of the diagram is what a Helm-based install of an AI platform like TrueFoundry populates inside the enclave: the gateway data plane, the model registry, the serving workers, the vector store, the observability stack, the policy engine — all wired to the customer's on-prem IdP, internal CA, and SIEM via Helm values rather than vendor endpoints.
Model weights are imported once via signed package, SHA-256 verified against the published hash from the model author, and then sealed inside the enclave. Subsequent inference workers pull from the local registry, never from HuggingFace. Updates follow the same path: a new model version arrives on physical media, gets signature-verified, and is staged into the registry under a new version label.
This sounds onerous for teams used to pip install, and it is. The reason it is worth it is that the integrity of the deployment depends on every byte of every weight being accountable. The signed-import process is the audit trail. When the auditor asks "where did this model come from, and how do you know it hasn't been tampered with?", the deployment answers with a chain of signatures: the model author signed the release, the security team verified the signature on import, the registry recorded the version under a custodial process. That chain is what makes the model usable in a regulated context.
The registry's metadata schema matters as much as the storage. Each model version is recorded with its source, its hash, its import date, its responsible engineer, and the eval results that qualified it for production. This is the same versioned-artefact discipline the team applies to code, applied to model weights. On TrueFoundry the Model Registry holds these fields as first-class metadata, so the auditor's question has a structured answer in the platform itself rather than living in a spreadsheet owned by one person. Teams that treat models as ad-hoc files struggle in audits; teams that treat them as code-class artefacts have the answers ready.
Token generation happens entirely inside the enclave, on the customer's H100, A100, or MI300 cluster (or whatever the regime allows; some classified environments restrict hardware choice as part of supply-chain controls). No provider API call ever leaves the boundary. The serving stack is the same vLLM, TGI, or SGLang the rest of the world uses; what changes is that it runs in an environment where it cannot phone home for telemetry, model auto-updates, or external embedding services.
The serving engines themselves usually need patches for air-gapped operation. vLLM by default checks HuggingFace for tokenizer files if they aren't pre-staged; that check must be disabled, or the tokenizer must be on the local registry path. Some engines reach for telemetry servers on startup; those calls must be stubbed out or pointed at a local sink. The patching is one-time work but it matters: teams that skip it discover the failure modes at runtime, when a worker pod refuses to start because it can't reach the internet for a metadata check. TrueFoundry's serving stack ships with these air-gapped patches in place — tokenizer sources point at local registry paths, telemetry endpoints point at the on-prem observability stack, and auto-update is off by default in the air-gapped Helm values. The same vLLM, TGI, and SGLang backends that teams use in connected deployments run in the enclave; the difference is which values file the deployment loads.
RAG over classified documents requires that the embedding model also runs inside the enclave. Sending text to a remote embedding API, even one provided by a major cloud, is the move that breaks the air gap most often in practice. Teams discover the leak when network monitoring shows DNS queries to api.openai.com originating from the supposedly air-gapped retrieval pipeline; the embedding step was using an SDK that defaulted to the cloud provider.
The deployment uses an on-prem embedding model — typically a smaller open-source model that's fast on CPU or runs efficiently on the same GPUs as the serving workers. Common choices: a 384- or 768-dimensional embedding model like bge-small, nomic-embed, or a domain-tuned variant for specialised content. The vector index is encrypted at rest with customer-managed keys, accessed only from inside the enclave, and backed up to the same media regime the rest of the deployment uses.
The vector store choice — Milvus, Qdrant, pgvector — matters less than the deployment hygiene around it. The store needs the same versioned-artefact treatment as the model registry: the corpus snapshots are recorded, the embedding model version is recorded, the index build process is reproducible. When the corpus changes, the re-embedding job runs on a controlled cadence and the auditor can trace any retrieval result back to a specific corpus snapshot. TrueFoundry's deployment manifest pins the on-prem embedding model and the vector store as part of the same Helm install, so the team isn't sourcing them separately at staging time — the choice of embedding model and vector backend is a values-file knob; the air-gap posture is not.
TrueFoundry's AI Gateway, in air-gapped deployments, runs as a containerized workload deployed via Helm into the customer's Kubernetes cluster inside the enclave. There are no outbound network dependencies for any of its runtime operations: identity comes from the local IdP (typically Active Directory or LDAP, sometimes a customer-operated SAML provider), policy lives on local disk under version control, audit logs go to the local SIEM (Splunk on-prem in most defense deployments, sometimes a customer-built equivalent). There is no telemetry to a vendor control plane; aggregate health metrics, if exported at all, go through a one-way data diode to a separately accredited monitoring environment.
The gateway's feature set is the same in air-gapped as in connected deployments. The same tokens-per-hour rate limiting per project, team, or workflow. The same per-project budget enforcement with hard caps that block new requests when a budget is reached. The same priority-based fallback routing across local model targets. The same input and output guardrails — PII / PHI redaction on inputs before the model sees them, secrets detection on outputs before they reach the client, prompt-injection detection for agent-shaped workloads. The features run; they emit their telemetry to the on-prem stack rather than to a vendor's observability cloud. The configuration that drives them is the same YAML.
This matters in practice because a platform team that operates a connected dev environment and an air-gapped production environment isn't operating two platforms — they're operating one platform with two values files. The gateway image is the same; the chart is the same; the API surface is the same. The engineering investment in the gateway pays off across every deployment shape simultaneously.
Every container image the deployment uses has to come from somewhere. In a connected environment, that somewhere is Docker Hub or ECR. Inside the enclave, it is a local Harbor or equivalent registry, populated at staging time from external mirrors and then frozen. The same is true for PyPI, npm, apt, and any other language package manager the system depends on. Snapshots get scanned for vulnerabilities at staging, then pinned.
The discipline is that nothing the system needs at runtime can be a moving target. The world outside changes; the inside of the enclave does not, except on a controlled cadence. A CVE published yesterday in a Python dependency does not automatically propagate into the enclave; it propagates on the next scheduled update, after the security team has reviewed it. This is sometimes uncomfortable for teams used to apt-get upgrade; it is the trade the deployment posture requires.
TrueFoundry's air-gapped install workflow publishes all container images and Helm charts to an OCI-compatible registry under the customer's control. The customer either replicates from TrueFoundry's upstream registry (tfy.jfrog.io/tfy-images for the container images, tfy.jfrog.io/tfy-helm for the Helm charts) at staging time, or works from the customer's existing Harbor or Artifactory if the customer's release-engineering team already owns the upstream-mirror discipline. The container registry's catalogue becomes the dependency inventory — when an auditor asks "what software is running in this enclave?", the answer is the registry's manifest. Teams that don't keep their registry tidy fail this question; teams that treat the registry as a curated, accountable inventory pass it.
Prometheus, Grafana, and Loki cover most metrics, dashboards, and logs. All on-prem. Dashboards export to a local SOC console, not to a SaaS vendor. Alert routing goes through internal email or Slack-on-prem equivalents, not Twilio or PagerDuty. The observability stack itself is one of the larger workloads inside the enclave; it's not unusual for the monitoring infrastructure to consume more compute than the AI workloads it monitors during quiet periods.
TrueFoundry's gateway is OpenTelemetry-native; in air-gapped deployments, the OTEL pipeline emits to the local Prometheus and Loki rather than to a vendor's observability cloud. Same instrumentation, same trace schema, different destination. Per-request observability includes the identity, the workload tag, the resolved model, the policy decisions applied, the guardrail verdicts, and the trace ID — everything the audit needs to reconstruct who asked what, of which model, under which policy, and how the gateway responded. Audit log retention is configurable for the long retention periods (seven years is common in defense and regulated-finance environments) that audit regimes require.
The alert routing is the place where most teams discover their on-prem assumptions are wrong. Sending an SMS via Twilio when the gateway saturates is the right behaviour in a connected deployment and a violation of the air gap in an enclaved one. The team's incident response runbook needs to be rewritten for the enclave: the on-call gets the alert via internal channels, the SOC gets a parallel notification through internal escalation, the external vendor support escalation (if any) happens through a different, accredited channel.
Public CAs (Let's Encrypt, DigiCert) are not reachable. The deployment uses the customer's internal PKI, with trust anchors loaded at install time. mTLS between gateway and workers, between gateway and IdP, between every internal service: all verified against the internal CA. This sounds like a footnote; it is the reason most "isolated" deployments are actually not air-gapped, because somebody left certbot reaching for a public endpoint to renew a certificate.
The internal CA is the customer's responsibility, not the platform's. The platform consumes the CA's trust anchors at install time — for TrueFoundry, via Helm values that point at the trust-anchor file mounted into the gateway pods. The customer's PKI team runs the CA, issues certificates, and rotates them. The certificate lifecycle is one of the operational loads the customer's PKI team needs to plan for. Short-lived certificates (90-day or shorter) are best practice but require automation that the team needs to provision before the deployment goes live.
Updates are the operational reality that distinguishes air-gapped from theoretically air-gapped. The model gets better; the gateway gets new features; vLLM ships a critical fix. None of these can be applied via git pull.
The discipline is a signed bundle workflow. The vendor publishes a release as a signed tarball — manifests, container images, Helm chart, and (if applicable) weight artifacts, with an integrity hash. The bundle is loaded onto physical media (typically a USB stick or removable hard drive, depending on the regime's media policy), walked across the air gap, and staged on a holding server inside the enclave. Integrity is verified, signatures are checked against pre-loaded vendor public keys, and the bundle is installed under a new version label. The previous version remains available for rollback for a configurable window — typically 30 days — so that a problematic update can be reverted without another bundle import cycle.
TrueFoundry's air-gapped releases ship in exactly this shape: signed bundles containing the chart, the manifests, the gateway and worker images, and the integrity hashes. Verification happens against pre-loaded TrueFoundry public keys; the bundle is staged in the customer's registry under a new version label; rollback is a Helm rollback to the previous chart revision. The customer's accreditation review applies to the bundle, not to a continuous stream of changes — every update is a discrete accreditation event with a clear before-and-after, which is the property the bundle workflow exists to provide.
Cadence depends on the regime. Some defense environments accept quarterly updates; some healthcare environments allow monthly. Some environments accept nothing without a separate accreditation review per release — every bundle is a fresh accreditation event. The platform has to support all of these without changing shape; the configuration of "how often we update" is the customer's, not the vendor's.

The four tiers represent a continuum of trust between the deployment and the outside world. The connected tier (most workloads, most enterprises) accepts vendor connectivity as a routine part of operation. The BYOC tier accepts vendor connectivity for the control plane but not for data — payloads stay inside the customer's cloud account. The air-gapped + diode tier accepts only one-way export, typically for SOC monitoring of aggregate health metrics. The fully air-gapped tier accepts no network connectivity of any kind. Most classified defense work runs in the bottom two tiers; most healthcare and finance work runs in BYOC; most general enterprise work runs in connected.
TrueFoundry supports all four tiers from the same codebase — the same gateway image, the same Helm chart, the same configuration schema. The Helm values change between tiers; the gateway primitives do not. The control plane and the gateway data plane are deployable independently, which is what makes this work: in connected SaaS, both planes run in TrueFoundry's environment; in BYOC, the control plane is SaaS and the data plane runs in the customer's VPC; in air-gapped, both planes run inside the customer's enclave. A platform team that runs SaaS in dev and air-gapped in classified production doesn't operate two platforms — it operates one platform configured differently. Engineering investment in the gateway pays off across every deployment shape simultaneously.
Most "air-gapped" deployments that fail their first audit fail not because the architecture was wrong but because a specific dependency leaked the gap. Five patterns recur across teams' first attempts; knowing them in advance is what produces deployments that pass review.
Default SDK telemetry. Cloud-provider SDKs (boto3, google-cloud, azure-sdk) routinely emit telemetry to vendor endpoints on initialisation. The application code looks innocent — it imports a library, instantiates a client — and the library calls home before the team's code does anything. The fix is auditing every dependency's network behaviour at staging time, disabling telemetry through configuration where the SDK supports it, and patching where it doesn't. Egress monitoring during staging is what surfaces these calls before production.
Tokenizer auto-download. Many ML libraries default to downloading tokenizer files from HuggingFace on first use. The serving engine that loaded the model successfully fails three weeks later when a worker pod restarts and the cached tokenizer is gone. The fix is pre-staging tokenisers in the local registry and pointing the engine at the local path through configuration, not relying on its default download behaviour.
Container image pulls at runtime. A Kubernetes deployment that references image: vllm/vllm:latest instead of image: harbor.internal.example.mil/vllm/vllm:v0.6.3 will fail at runtime in an air-gapped environment. The fix is the registry-mirror policy: every image reference in every manifest points at the local Harbor; no manifest references an external registry, period. Admission controllers can enforce this at deploy time.
Certificate renewal reaching outside. The deployment was installed with internal certificates; renewal automation defaults to Let's Encrypt or a similar public CA. Three months later, the renewal job runs and fails — or worse, succeeds in reaching the public endpoint, breaking the audit posture. The fix is wiring certificate renewal to the customer's internal PKI from day one, not as an afterthought.
NTP and DNS over the wire. Time synchronisation defaults to public NTP pools; DNS resolution defaults to public servers. The deployment's network is "isolated" but somehow the worker pods are still talking to pool.ntp.org. The fix is the customer's internal NTP and DNS infrastructure, configured at the cluster level so that no pod can accidentally reach outside even if its application code didn't intend to.
The common pattern: the failure is in the platform layer below the AI workload, not in the AI workload itself. The team writes their RAG pipeline correctly, but a transitive dependency calls home. The defence is staged egress monitoring — running the deployment in a connected sandbox with full egress logging, treating any unexpected outbound connection as a finding, and only proceeding to the air-gapped install once the sandbox is clean. TrueFoundry's connected-mode staging environment exists precisely for this: the same gateway image and the same Helm chart that will run in the enclave run first in a sandbox where every outbound connection is observable, so the failure modes get surfaced before they reach a regulated environment. The integrity of the air-gapped deployment is largely paid for at staging time.
Air-gapped rollouts are slower than BYOC rollouts, which are slower than SaaS adoptions. The sequence below is the typical multi-month plan; rushing it produces deployments that fail accreditation review.
Months 1-2 — Accreditation engagement. The customer's security team and the accreditation authority review the platform's documentation, the data inventory, the update workflow, and the cryptographic posture. The output is an accreditation package that defines exactly what the deployment will look like and what controls apply. This is the artefact the deployment is measured against later; getting it right saves weeks of remediation. TrueFoundry's deployment engineering team typically participates in this phase, supplying the architecture documentation, FIPS 140-3 cipher posture (where the deployment runs inside AWS GovCloud or Azure Government), and the bundle signing process the accreditation authority will review.
Months 3-4 — Staging environment. The customer builds a staging enclave that mirrors the production topology but holds no classified data. The platform installs via Helm against the local registry mirror; the integrations (IdP, SIEM, internal CA, on-prem observability) are wired up; the update workflow is exercised with a sample signed bundle. The staging deployment runs for at least a month under simulated load, with full egress logging enabled so that any unexpected outbound connection surfaces as a finding before production.
Months 5-6 — Production install and accreditation. The platform installs into the production enclave. The accreditation authority conducts the formal review against the previously agreed package. Findings get remediated; the deployment is accredited under the appropriate authorisation framework (DoD IL5/IL6 for classified defense, FedRAMP High for federal civilian, sector-specific frameworks for healthcare and finance).
Months 7+ — Steady-state operation. The platform serves regulated workloads. The update workflow runs on its certified cadence (quarterly, monthly, or by accreditation event). The customer's security team owns the operational compliance posture; the customer's SRE team owns the day-to-day operation. TrueFoundry steps back to the accredited escalation channel for incident support and the quarterly release cadence — the deployment is the customer's, not the vendor's, at this point.
Air-gapped is not the same as just running on-prem. A typical on-prem deployment still reaches out to package managers, pulls container images from external registries, and sends telemetry to a SaaS observability vendor. That deployment lives in the enterprise's data centre. It is not air-gapped. The two are routinely confused, and the confusion is exactly what regulators look for during audits.
It is also not without operational cost. Maintaining mirrored registries, running an internal PKI, doing release-engineering against a quarterly cadence — these are real engineering loads that don't exist in connected deployments. The teams that operate air-gapped systems know this; the teams that are about to inherit one usually don't, and the gap between the two is where most failed deployments come from. Procurement reviews for air-gapped platforms often underestimate the customer's ongoing operational load by a factor of two or three.
And it is not a substitute for compliance practice. The architecture removes the network-borne risks; it doesn't remove the human-borne ones. Insider threat, misconfiguration, policy violation, and operational error are still risks that the customer's security team has to manage. The air gap is a strong physical control; it is not a substitute for the rest of a defence-in-depth posture.
And it is not the right answer for every team. Organisations whose workloads don't actually require an air-gapped posture pay the operational cost without getting the regulatory benefit; for those workloads, BYOC delivers most of the data-sovereignty benefit at a fraction of the operational cost, and the connected tier is materially easier still. Organisations that have already built mature air-gapped platforms with their own accreditation track record face a migration cost in an accredited environment that can be hard to justify. Air-gapped is the deployment shape for workloads where the regulatory regime demands no external connectivity; for everything else, the simpler tiers exist for a reason.
The platform's job is to make the operational load tractable, not to pretend it doesn't exist.
The customer provisions an OCI-compatible registry inside the enclave (typically Harbor, sometimes JFrog Artifactory or the cloud-equivalent). The release-engineering team mirrors TrueFoundry's container images and Helm charts — say, sourced from tfy.jfrog.io/tfy-images and tfy.jfrog.io/tfy-helm — into the registry, either by direct replication from a connected staging environment or via a signed bundle walked across the air gap on physical media. The Helm install then runs against the local registry, the local image manifests, and the customer's Kubernetes cluster. Helm values point at the customer's IdP, internal CA, SIEM, and observability stack. The same chart that installs in a connected dev environment installs in the air-gapped production environment; only the values file differs.
Through the signed bundle workflow. The model author publishes a release; the customer's release-engineering team imports it on the certified cadence (quarterly, monthly, or per accreditation event). The bundle is signature-verified, staged in the local registry, deployed to a canary subset, and promoted to production after observation. The previous version remains available for rollback within a configurable window.
No — frontier hosted models live outside the enclave by definition; calling them would break the air gap. Air-gapped deployments use self-hosted open-source models (Llama, Mistral, Qwen, Phi-3) on local GPUs. The quality is often sufficient for the workload class (extraction, summarisation, classification, RAG over internal corpora); workloads that genuinely require frontier reasoning typically don't fit the air-gapped posture and need to be designed for a less restricted tier.
Critical security updates have an out-of-band path: an emergency signed bundle, certified faster than the standard cadence, distributed through the same physical media workflow. The customer's security team decides whether a CVE qualifies as emergency; the platform's release process supports the faster cadence for the cases that need it. The trade-off is that emergency bundles bypass parts of the normal accreditation review and require post-hoc validation.
Larger than for a connected deployment of the same workload — by roughly 2-3× on average. The customer needs PKI operations, mirror maintenance, release engineering, accreditation liaison, and the usual SRE rotation. For a single workload, this can mean 3-5 dedicated engineers; for a deployment that hosts multiple workloads, the marginal cost per workload is lower because the operational infrastructure is shared.
The GPUs themselves are the same; what changes is the supply chain and the firmware policy. Classified environments may restrict which vendors' hardware is acceptable, require specific firmware versions, and require validated supply-chain provenance. The platform runs on whatever the regime's hardware policy permits; the customer's procurement team handles the hardware sourcing.
For the diode tier, yes — telemetry can be exported continuously, but only one-way. The diode is a physical guarantee that no data can enter the enclave via the export channel. What flows out is what the customer's accreditation has approved: aggregate metrics, structured operational telemetry, possibly anonymised performance data. Per-request payloads do not flow out under any condition.
Identical to a connected deployment, but with everything local. The golden set lives on local storage. The replay job runs against the local serving fleet. The judge model is one of the locally-deployed open-source models. The slicing dashboards live in the on-prem Grafana. The auto-rollback hooks into the local prompt-version registry. The eval discipline is the same; only the destinations differ.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.webp)

.webp)
.webp)
.webp)
.png)






.webp)
.webp)

