














July 29, 2026
|
5 min read

Published: June 14, 2026

Blazingly fast way to build, track and deploy your models!
In 2026, enterprises can no longer afford to modify an LLM Gateway into a makeshift AI Gateway. AI is only going to get more embedded in customer-facing workflows, making a dedicated gateway layer non-negotiable for reliable AI-powered applications. The typical enterprise AI infrastructure is often multi-model, multi-team, and multi-cloud, leading to complex compliance and cost accountability.
Gartner defines an AI gateway as a technology or platform that acts as an intermediary between applications and various artificial intelligence (AI) services or models. Its purpose is to simplify and manage access to AI capabilities, providing a central point to enable security, governance and observability of AI workloads. Read the full Gartner Market Guide for AI Gateways 2025 to learn more.
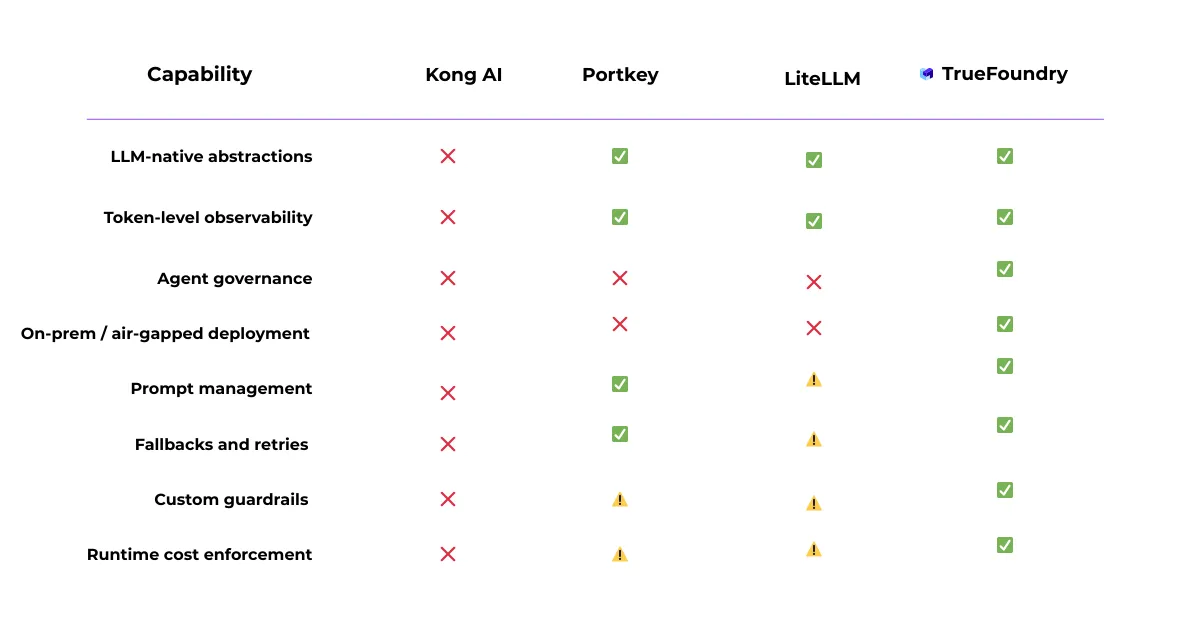
Over the last year, we’ve seen three broad categories emerge to tackle the problem of governance and resilience of GenAI:
Each category optimizes for a different phase of AI adoption. Problems arise when tools optimized for one phase are stretched to handle another.
In this blog, we bring together all competitive research into one definitive landscape, explaining where each platform fits, where they break down, and what enterprises need to take into consideration when choosing a vendor that best fits their requirements.
1. Kong AI: Traditional API Gateway Adapted for AI
Kong is an API gateway, often used in Kubernetes‑based microservice architectures. Kong AI builds on this foundation by introducing plugins and integrations designed to route traffic to large language models.
What Kong AI Does Well
Where Kong AI Breaks Down
As AI usage grows, these gaps become more visible. Cost attribution, model selection strategies, and AI‑specific governance must be handled outside the gateway, often inside application code.
Bottom line: Kong AI is effective as an API gateway, but AI remains a secondary concern rather than a native abstraction.
2. Portkey: Application-Level LLM Gateway
Portkey is an AI gateway designed specifically for LLM applications. Instead of treating AI requests as generic HTTP calls, Portkey introduces prompt‑ and model‑aware routing and observability.
What Portkey Does Well
Where Portkey Falls Short
Portkey’s design is intentionally application‑focused, which introduces constraints at enterprise scale
As AI becomes a shared internal capability rather than a single application feature, these limitations often require additional infrastructure layers.
Best for: Single-team LLM applications moving into early production.
3. LiteLLM: Developer-First Open-Source Gateway
LiteLLM is an open‑source LLM gateway that provides a unified, OpenAI‑compatible API for accessing dozens of model providers.
What LiteLLM Does Well
Where LiteLLM Falls Short
Best for: LiteLLM is an effective entry point but requires significant augmentation for regulated or multi‑team environments.
Also Read: Portkey vs LiteLLM
4. AWS Bedrock: Serverless Model APIs
AWS Bedrock offers managed, serverless access to foundation models from providers such as Anthropic and Amazon. It abstracts infrastructure entirely and bills purely on token usage.
What AWS Bedrock Does Well
Hidden Trade-Offs of AWS Bedrock
These trade‑offs often catch teams by surprise as workloads move from experimentation to sustained production use.
Bottom line: Bedrock optimizes for speed and simplicity, not long‑term cost efficiency or control.
5. AWS SageMaker: Managed ML Infrastructure
SageMaker provides a comprehensive suite for training, tuning, and deploying machine learning models. Unlike Bedrock, it exposes infrastructure choices directly to users.
What AWS Sagemaker Does Well
Drawbacks of AWS Sagemaker
Bottom line: SageMaker offers control but at the cost of operational simplicity.
6. Databricks: The Lakehouse ML Platform
Databricks approaches AI from a data‑first perspective, integrating ML and GenAI capabilities into its Lakehouse architecture.
What Databricks Does Well
Where Databricks Falls Short
Bottom line: Databricks excels at data engineering, not AI serving.
The Common Thread: Gateways Without Governance
Across Kong vs LiteLLM, Portkey, and even Bedrock, the same issue emerges: they manage requests, not AI systems.
Across gateways and managed services, a recurring issue appears: most tools focus on requests, not systems.
They answer questions like:
They struggle with:
These are infrastructure‑level concerns.
TrueFoundry occupies a different layer in the stack. Instead of focusing solely on API routing or managed services, it treats AI workloads—models, agents, services, and jobs—as first‑class infrastructure objects. This shifts the responsibility from application code to the platform itself.
The TrueFoundry AI Gateway is built with the following core principles:
This means that the AI Gateway is a component of a larger system, allowing enterprises to scale their AI use cases seamlessly.
Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Unified API & Routing | |||
| Unified OpenAI-compatible endpoint | Is the gateway API compatible with OpenAI's /v1/chat/completions and /v1/responses formats, allowing consistent access across different models through a standardized interface? | Must have | ✅ Supported: OpenAI-compatible endpoint across all providers. |
| Provider and model coverage | Does it support leading providers like OpenAI, Azure OpenAI, Amazon Bedrock, Anthropic, Gemini, Groq, plus self-hosted models? | Must have | ✅ Supported: 1000+ LLMs across hosted and self-hosted providers. |
| Model onboarding speed | How quickly can new models (OpenAI-compatible and non-standard APIs) be added without code changes? | Must have | ✅ Supported: config-driven onboarding within minutes. |
| Multimodal support | Does the gateway support text, vision, audio, image generation, and embeddings through a single interface? | Depends on use case | ✅ Supported: chat, embeddings, images, audio, rerank, and realtime APIs. |
| Routing, load balancing, fallback | Can requests be routed by model, provider, latency, priority, weight, region, and failure state with automatic retries? | Must have | ✅ Supported: load balancing, fallbacks, weighted and latency-based routing. |
| Model switching without code change | Is model switching supported via headers or config without changing client code? | Must have | ✅ Supported: header-based and config-based model switching. |

The TrueFoundry AI Gateway becomes critical when AI usage moves beyond isolated applications and becomes a shared, production-critical capability. At that stage, challenges are often less about individual model calls and more about operational consistency across teams and environments.
Here’s how TrueFoundry's AI Gateway differs from other solutions:
Many AI tools focus on request-level concerns such as routing, retries, and basic observability. This is usually sufficient in early stages.
As usage expands, however, models and agents begin to behave more like long-lived services. Teams need clearer ownership, lifecycle management, and operational boundaries. TrueFoundry is designed to manage AI workloads—models, services, and jobs—as infrastructure components with defined deployment and runtime characteristics.
In many stacks, access controls and usage policies are configured at the application or SDK level. Over time, this can lead to inconsistency as the number of services grows.
TrueFoundry applies controls at the environment level, separating development, staging, and production by default. Policies defined at this layer apply uniformly to all workloads deployed within an environment, reducing reliance on per-application configuration.
AI costs often increase due to concurrency, retries, or background workloads rather than individual requests. TrueFoundry addresses this by enforcing limits on concurrency, throughput, and resource usage during execution.
This allows organizations to manage shared infrastructure more predictably as usage scales.
While token-level metrics are useful, they do not fully explain system behavior in production. TrueFoundry correlates request-level signals with infrastructure metrics such as CPU/GPU utilization and autoscaling behavior, helping teams understand performance and cost drivers in context.
Some organizations operate under constraints that require private networking, on-prem deployments, or strict data residency. TrueFoundry is designed to run in these environments, allowing AI workloads to be governed using the same infrastructure standards applied elsewhere in the organization.
Conclusion
The current AI platform landscape reflects the speed at which generative AI has evolved. Many tools address real problems—routing, model access, observability, or training—but they do so from different starting points. As a result, no single category naturally covers the full set of operational requirements that emerge once AI becomes production-critical.
TrueFoundry offers the most value when AI workloads need to be operated with the same discipline as other production systems—across environments, under shared policies, and with predictable resource behavior.
Enterprises comparing vendors often start by searching for the best LLM gateway, but the real differentiator lies in how well the platform governs AI systems at scale. Understanding where each platform fits, and where its design assumptions begin to break down, is essential when evaluating the best AI gateway for enterprise-scale deployments. The right choice depends less on individual features and more on how an organization expects its AI usage to evolve over time.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


The best AI gateway depends on the organization's specific requirements. TrueFoundry's AI Gateway stands out for enterprises needing multi-provider routing, centralized governance, cost tracking, and MCP integration in a single platform. Other strong options include LiteLLM for open-source flexibility and Kong AI Gateway for teams already invested in Kong's API management ecosystem.
An AI gateway is a middleware layer that sits between applications and LLM providers (such as OpenAI, Anthropic, or Google). Its architecture typically includes a routing engine that directs requests to the appropriate model, a policy layer for enforcing rate limits and access controls, an observability stack for logging and cost tracking, and a caching layer to reduce redundant API calls. This architecture allows organizations to manage multi-model deployments from a single control plane.
TrueFoundry differentiates itself by combining AI gateway capabilities with a full ML infrastructure platform including model serving, fine-tuning, and MCP server management in a unified solution. Its AI Gateway offers enterprise-grade features such as per-team budget controls, audit logging, model fallback routing, and native MCP support, making it particularly well-suited for organizations looking to govern and scale Claude Code and other agentic AI deployments






The latest news, articles, and resources sent to your inbox
.webp)

.webp)


.webp)
.png)
.webp)
.webp)



.webp)



