














November 13, 2025
|
5 min read

Published: March 16, 2026

Blazingly fast way to build, track and deploy your models!
The proliferation of Large Language Models (LLMs) and agentic systems marks a pivotal moment for enterprise technology. The innovation potential is vast—but so are the pitfalls. In many organizations, early adoption has been chaotic: fragmented, unmanaged, and insecure. Individual teams spin up their own connections to various model providers, resulting in siloed experiments with no central oversight, cost controls, or security standards.
To evolve from this ad-hoc experimentation to a cohesive, enterprise-wide AI strategy, we need a deliberate architectural paradigm—one that bakes in safety, governance, and scalability from day one.
An ideal agentic application stack in today’s environment must deliver:
Rapid application development — low-latency federated execution across heterogeneous agents and environments shortens time to value (TTV), enabling teams to deliver production-ready capabilities quickly without centralizing all data or compute.
Future-proof flexibility — a modular, interoperable stack that can adapt to emerging models, protocols, and agent patterns as the AI landscape evolves.
Safety & compliance by default — PII masking, policy enforcement, and full auditability.
Deterministic operations on non-deterministic systems — guardrails, evaluation frameworks, and rollback paths when outputs drift.
Cost governance at token granularity — budgets, showback/chargeback, and usage caps.
Reliability & portability — multi-model failover, hybrid/on-prem deployment, and zero vendor lock-in via provider-agnostic interfaces, exportable artifacts, and replay-to-switch migration plans.
Deep observability — traces, token-level metrics (TTFT, TPS), cache hit rates, and usage trends.
Composable capabilities — models, tools, and agents connected through prompts, not brittle glue code.
Velocity with control — CI/CD for models, agents, and tools; staged rollouts with canary or A/B testing.
And we must design with real-world constraints in mind such as:
This is where architecture becomes the difference between an inspiring demo and a production-grade system. The blueprint should comprise of four critical layers: Models, MCP Servers, Agents, and Prompts.
1. Models — Powering the Core Intelligence
At the heart of any Gen-AI application is the model itself—your system’s reasoning engine. The challenge isn’t simply picking the “best” model; it’s designing for a world where models are numerous, constantly evolving, and fit for different purposes.
A solid stack treats models like regular software assets: they’re versioned, tracked for data and code changes, and moved through dev, staging, and production. Routing should also factor in cost and performance — sometimes a smaller, cheaper model is the better choice for a specific task than running everything on a large, expensive one.
The trap many fall into is model sprawl: too many untracked models, opaque upgrades, and no rollback path when performance regresses. Architecture here means discipline—treating models with the same rigor as core application code.
2. MCP Servers — Standardizing Capabilities
If models are the brain, MCP (Model Context Protocol) servers are the toolbelt. They give your agents standardized, enterprise-ready access to systems like Jira, GitHub, Postgres, or proprietary APIs.
Rather than bespoke, per-team integrations—each with their own quirks, security gaps, and duplicated logic—a single certified MCP server per system can be reused across the enterprise. Typed I/O, authentication, and quotas become consistent, predictable, and secure.
When teams skip this step, chaos follows: inconsistent security policies, redundant work, and brittle integrations that can’t be shared or maintained. MCP servers make capabilities composable, not accidental.
3. Agents — The Digital Workforce
Agents are where models become operational. They’re not just pipelines—they’re the digital counterparts to human employees, capable of taking actions, coordinating tasks, and using tools.
Good agent design means giving each one an identity, permissions based on least privilege, and a clear sandbox-to-production lifecycle. They should be orchestrated, capable of multi-agent collaboration, and portable across environments.
The biggest operational risk here is uncontrolled access: credentials baked into UI layers, tools accessible without boundaries, and no ownership or SLAs. Well-designed agents carry their credentials and scopes with them—not tied to where they’re invoked.
4. Prompts — The Operational Interface
Prompts are how we tell models and agents what to do. They’re not just plain text, they can be structured templates, include evaluation steps, and have built-in policy checks.
In a solid setup, prompts are treated like code: they’re version-controlled, tested, and protected against prompt injection or unintentional changes. Using semantic caching can save time and cost by reusing responses for similar queries instead of running the whole process again.
If you don’t manage prompts properly, you risk security issues, leaking sensitive data, or having your prompts slowly change over time in ways you didn’t plan. Managing them well ensures consistent, safe, and reliable behavior.
When the main layers — Models, MCP Servers, Agents, and Prompts — are built and managed carefully, the system becomes more reliable, scalable, and easier to maintain. But in big organizations, problems often come up in how all these parts are coordinated, not just in the parts themselves.
Centralised registries are the connective tissue of the Gen-AI stack: the institutional memory that keeps all components discoverable, compliant, and interoperable. Without them, you risk sliding back into the very chaos this architecture was meant to prevent—duplicate work, security gaps, and invisible drift from standards.
A robust registry layer provides:
In practice, this layer spans multiple specialized registries:
The system of record for your models—tracking versions, lineage (data, code, metrics), deployment status (dev/shadow/prod), and who can promote or use a model. It’s wired into CI/CD pipelines so that new versions register automatically and can be rolled out safely via canary or A/B testing. Beyond discoverability, it enforces discipline: no “mystery models” in production, no untracked changes.
The catalogue of certified tools available to agents, documenting their functions, arguments, and schemas. It also encodes usage permissions—not every agent should have access to your finance systems or sensitive databases. Built once, an MCP server can be reused across teams, with the gateway enforcing role-based access control at the tool level.
A directory of your digital workforce—tracking each agent’s identity (UUID), owner, purpose, skills, allowed models/tools, and credentials. It records the full lifecycle from creation to retirement, and ensures least-privilege access is applied in real time at the gateway. This prevents the common failure mode of agents retaining excessive or outdated privileges.
A versioned repository of input/output safety policies—covering PII masking, prompt injection detection, topical limits, toxicity filters, and fact-checking rules. Policies are managed as code, meaning they can be rolled out incrementally via canaries or A/B tests. Bundled policies (e.g., “HIPAA-Compliant Chatbot”) can be applied consistently across models, agents, and tools.
Registries give us the memory and governance scaffolding. But governance on paper means nothing if it’s not enforced at runtime—where prompts are sent, tokens are consumed, and responses are delivered.
Even with the right components and well-governed registries, a modern AI system doesn’t run in a vacuum. In production, the real test isn’t whether your architecture looks good on paper—it’s whether it keeps delivering under failure conditions, variable demand, and unpredictable costs.
This is where the “operational nuances” come in. They’re not standalone components, but rather cross-cutting patterns that add durability, efficiency, and responsiveness to the whole stack.
High Availability Patterns
In a live AI system, failure is not a possibility—it’s a certainty. Models will go down, endpoints will change, and networks will misbehave. An architect’s job is to make sure these events don’t translate into outages for the user.
Lock-in is avoided by practice, not promise. Treat exit as a run-time discipline, not a last-mile project.
Provider-agnostic gateway — normalize request/response schemas and capability tags so apps never bind to a vendor SDK.
Replay-to-switch — routinely shadow a representative slice of production traces to an alternate provider or self-hosted model; track deltas on latency, cost, and quality to keep the escape hatch warm.
Open artifacts — store prompts, traces, evals, embeddings, and fine-tuning datasets in exportable formats; keep vector indexes rebuildable from source.
Compatibility matrix — maintain a vendor/model scorecard (latency/cost/quality/features) so routing policies stay data-driven.
Contract & data rights — prefer terms that allow weight replacement and re-training; track dataset lineage in the Model Registry so exit doesn’t stall on provenance.
Exit checklist — keys/config decoupled from code, secondary endpoints pre-vetted, minimum replay dataset defined, known gaps documented.
AI workloads are inherently variable-cost, and without active management, costs can spiral. The challenge is to enforce cost discipline without introducing bottlenecks that frustrate developers or users.
These nuances ensure the system keeps running smoothly when something goes wrong. They also help in keeping costs under control. Combining the nuances of fallback, redundancy and cost requires a unified control plane; that’s what the AI Gateway does: it brings all these pieces together into a single, central part of the modern GenAI architecture.
AI Gateways govern models, agents, tools, prompts, and tokens. It’s a specialized middleware control plane for AI traffic—egress/reverse proxy that understands tokens, semantics, and tools.
What It Does
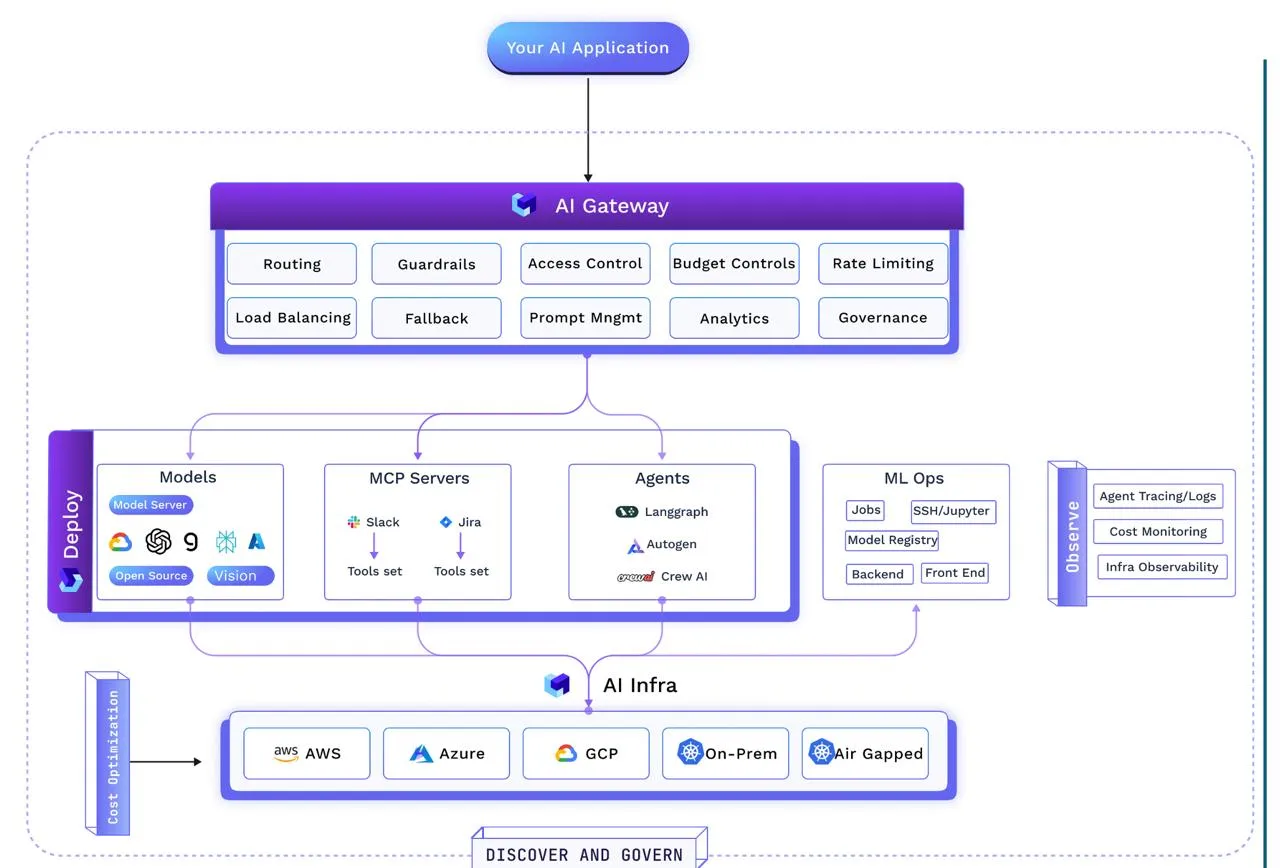
Once the blueprint is defined, the registries are in place, the operational safeguards are baked in, and the AI Gateway is enforcing them in real time, the question becomes: how do we actually run this thing?
This is where the conversation shifts from architecture and governance to execution — the deployment layer that can move code and models into production fast, keep them reliable, and run them cost-effectively—all without breaking operational discipline.
Here, speed doesn’t mean cutting corners. A modern pipeline moves from commit to cluster in minutes: automated tests validate changes, containers package models, agents, and MCP servers into immutable images, and manifests roll them out to dev, staging, or production with configurable strategies. Registry updates ensure the Gateway can immediately discover and govern new versions. Entire applications—model, backend, frontend, and tools—can be deployed as pre-configured stacks, or even spun up by conversational deployment agents.
Reliability is embedded through SRE best practices: instant auto-scaling and failover, proactive monitoring, rollback/versioning on demand, immutable audit logs, and automatic shutdown of idle environments or IDEs.
Policies here also enforce operational rules like “no production deployment without at least two replicas” or “GPU workloads must auto-shutdown when idle.”
Cost efficiency is also something that has to be factored in, the layer seamlessly uses spot instances with on-demand fallback for cost savings, scales workloads with HPA/VPA and cluster autoscaling, and leverages event-driven scaling (e.g., KEDA) to bring workers online instantly when needed and back to zero when idle. An AutoPilot-style feature would apply scaling or placement changes in real time, balancing cost savings with SLA protection.
The standard deployment pipeline for an agentic AI stack looks like this:
Artifacts are OCI images and manifests are plain IaC; endpoints and regions are parameterized. That keeps workloads cloud-agnostic and enables fast, policy-driven relocation without touching application code.
With the system live—models deployed on Kubernetes, agents registered, and the Gateway applying runtime rules—the architecture is operational. But keeping it safe, efficient, and aligned with organizational priorities isn’t a one-time exercise. Workloads will move between environments, scale up and down, and evolve with new tools and models.
If governance doesn’t move with them, you end up with shadow behavior: agents running without guardrails, workloads deployed without redundancy, or GPUs left idling and burning cost. The answer is simple in principle but powerful in practice—policies that travel with the workload.
Moreover, guardrails can’t live as ad-hoc scripts buried in one team’s codebase. They should be policy-as-code—versioned, reviewed, and deployed like any other core artifact:
Policies aren’t just about AI safety. They can encode organization-wide operational standards:
These rules ensure your systems meet baseline reliability and efficiency standards by default, without relying on manual checks or team memory.
In many regulated or high-security industries, running large proprietary models in production becomes a challenge. Fine-tuning a smaller self-hosted model sidesteps that barrier while preserving quality. And because the Gateway already sits in the flow of traffic, it can manage the migration—shadowing the new model against the old one, A/B testing outputs, and routing traffic accordingly once performance converges. Using fine-tuned open source LLMs for Gen AI use cases at scale is also cost effective for enterprises.
The Gateway isn’t only about enforcement—it’s also a model evolution engine. By logging high-quality interactions from a large, expensive model like GPT-4o, it builds a fine-tuning dataset for a smaller, efficient model like LLaMA.
This approach allows you to:
From the architect’s point of view, this turns the AI Gateway into more than an enforcement layer—it becomes a model evolution engine, quietly transforming runtime data into the foundation of your next-generation, cost-optimized, production-ready AI.
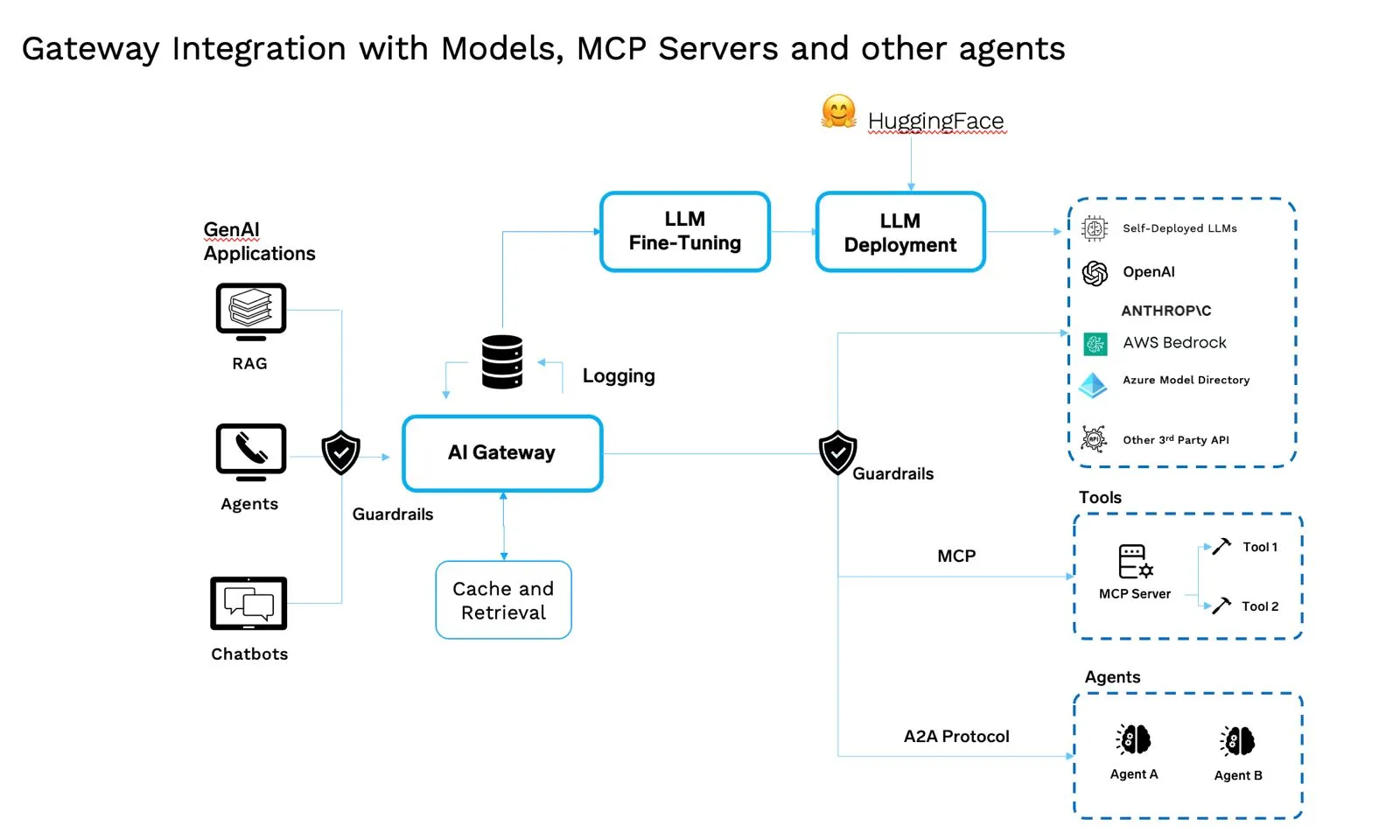
When you look at the stack as a whole, the value isn’t in the individual pieces but in how they work together. Models need to be tracked and versioned. MCP servers expose them in a consistent way. Agents bring reasoning and decision-making. Prompts give them clear instructions. Registries make sure you know what’s running and where. Operational policies keep things safe and cost-effective. Kubernetes gives you the scale and reliability to run it all.
The AI Gateway sits on top to coordinate these moving parts, but the real strength comes from the integration — every layer is connected, managed, and observable. That’s what turns a collection of tools into a system that enterprises can actually trust and build on.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.







.webp)


.webp)
.webp)
.webp)
.png)






.webp)
.webp)