




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
الجزء الأول شخّصت الأمر بأن: تعظيم الرموز (tokenmaxxing) ليس مشكلة في استخدام الذكاء الاصطناعي؛ بل هو مشكلة في مستوى التحكم. إذا أصبحت الرموز الخام هدفًا، فسيعمل الناس على تحسينها. وإذا أصبح الاستخدام المُحكَم للذكاء الاصطناعي هو نموذج التشغيل، يمكن للمنصة تشجيع التبني مع تحديد التكلفة والمخاطر والضوضاء التشغيلية. هذا الجزء يجعل تلك الهندسة ملموسة.
الفرضية بسيطة. كل طلب ذكاء اصطناعي يغادر تطبيق مؤسسي هو، سواء تعاملت معه بهذه الطريقة أم لا، حدث وقت تشغيل له تبعات تتعلق بالتكلفة والأمان والتدقيق. المكان الوحيد الأكثر فاعلية لربط الضوابط بهذه الأحداث هو البوابة — الطبقة التي تقع بين كل تطبيق وكل نموذج وواجهة خلفية للأدوات. يمكن للوحة معلومات مبنية في المراحل اللاحقة أن تصف ما حدث. البوابة وحدها هي التي يمكنها تحديد ما سيحدث بعد ذلك.
لوحة المعلومات تبلغ عن مشكلة. البوابة تمنع المشكلة التالية. الهندسة المعمارية أدناه هي ما يجعل هذا التمييز عمليًا.
يحتاج طلب الذكاء الاصطناعي المُحكَم إلى أربعة أغلفة تحيط به قبل أن يغادر التطبيق. فكر في هذا كنموذج OSI للذكاء الاصطناعي المؤسسي — كل طبقة لها مسؤولية محددة ونمط فشل محدد عند غيابها.
يجب أن تكون هذه الأغلفة على مسار الطلب، وليس في تقرير يقرأه أحدهم يوم الجمعة. يمكن للوحة معلومات مبنية بعد وقوع الحدث أن تصف مشكلة؛ فقط الغلاف الموجود على الطلب المباشر يمكنه تشكيل المكالمة التالية. هذا هو المبدأ المعماري الذي يفصل منصة الذكاء الاصطناعي المُحكَم عن إضافة التحليلات.
أول معيار للتنفيذ هو عقد بيانات وصفية صارم. استخدم مفاتيح ذات قيم نصية، وأرسلها مع كل طلب، واجعلها إلزامية في أغلفة SDK الخاصة بك، ومكتبات العملاء الداخلية، وأطر عمل الروبوتات، وقوالب الوكلاء. تظهر تكلفة حقل واحد مفقود لاحقًا كبند فاتورة مفقود، أو ارتفاع غير قابل للنسبة، أو حدث حماية لا يمكن لأحد توجيهه إلى مالك.
// JSON — minimum metadata contract
// Treat as a strict schema, not a suggestion.
{
"team": "payments-platform", // maps to FinOps cost center
"project_id": "proj-agentic-refactor", // rate/budget scoping key
"workflow": "repo-understanding", // routing and policy selector
"surface": "ide-agent", // hourly rate-limit selector
"environment": "production", // budget tier selector
"cost_center": "eng-core", // accounting integration
"ticket_id": "ENG-18472", // outcome join key — THE most important field
"policy_version": "ai-leverage-v1" // audit trail
}
// Python SDK — never skip the metadata header:
// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}الوسم هو أرخص عمل هندسي في هذه الهندسة المعمارية بأكملها وأول ما يتعطل عندما تتجاهله الفرق.
في بوابة TrueFoundry، ينتقل هذا كعنوان X-TFY-METADATA. ثم يقوم نفس نطاق اسم المفتاح بتشغيل كل شيء في المراحل اللاحقة: تُطبق الميزانيات لكل مشروع، وتُطبق حدود المعدل لكل سير عمل، وتُجمع لوحات المعلومات حسب الفريق، وتُربط التتبعات بالتذاكر، ويخصص التمويل الإنفاق حسب مركز التكلفة. لا يوجد مصدر ثانٍ للحقيقة.

الهدف المعماري ليس إضافة تعقيدات. بل هو الحفاظ على ربط وثيق بين كل نمط فشل واقعي والتحكم المحدد الذي يمنعه. إليك التصنيف الكامل:
إذا سمى كود التطبيق نموذج مزود خدمة معينًا، فقد فقدت القدرة على الترحيل أو الاختبار أو إجراء اختبارات A/B أو تجاوز الفشل دون تغييرات في الكود. النمط الصحيح هو إظهار الإمكانيات المنطقية — أسماء مثل prod/engineering-assistant أو prod/frontier-reasoning — والسماح للبوابة بتحويلها إلى أهداف مادية بناءً على البيانات الوصفية أو الأولوية أو الوزن أو زمن الاستجابة المقاس.
في TrueFoundry، هذا هو الغرض من النماذج الافتراضية وتكوين التوجيه. تغطي نفس القواعد عمليات النشر التدريجي، والتفضيل الإقليمي، والتشغيل المحلي مع تجاوز الفشل السحابي، وتجاوزات المطالبة الخاصة بالمزود. هذه هي القدرة الأكثر استهانة بها في مكدس الحوكمة — فهي تجعل الامتثال، وتحسين التكلفة، وترحيل النماذج غير مرئية لمطوري التطبيقات.
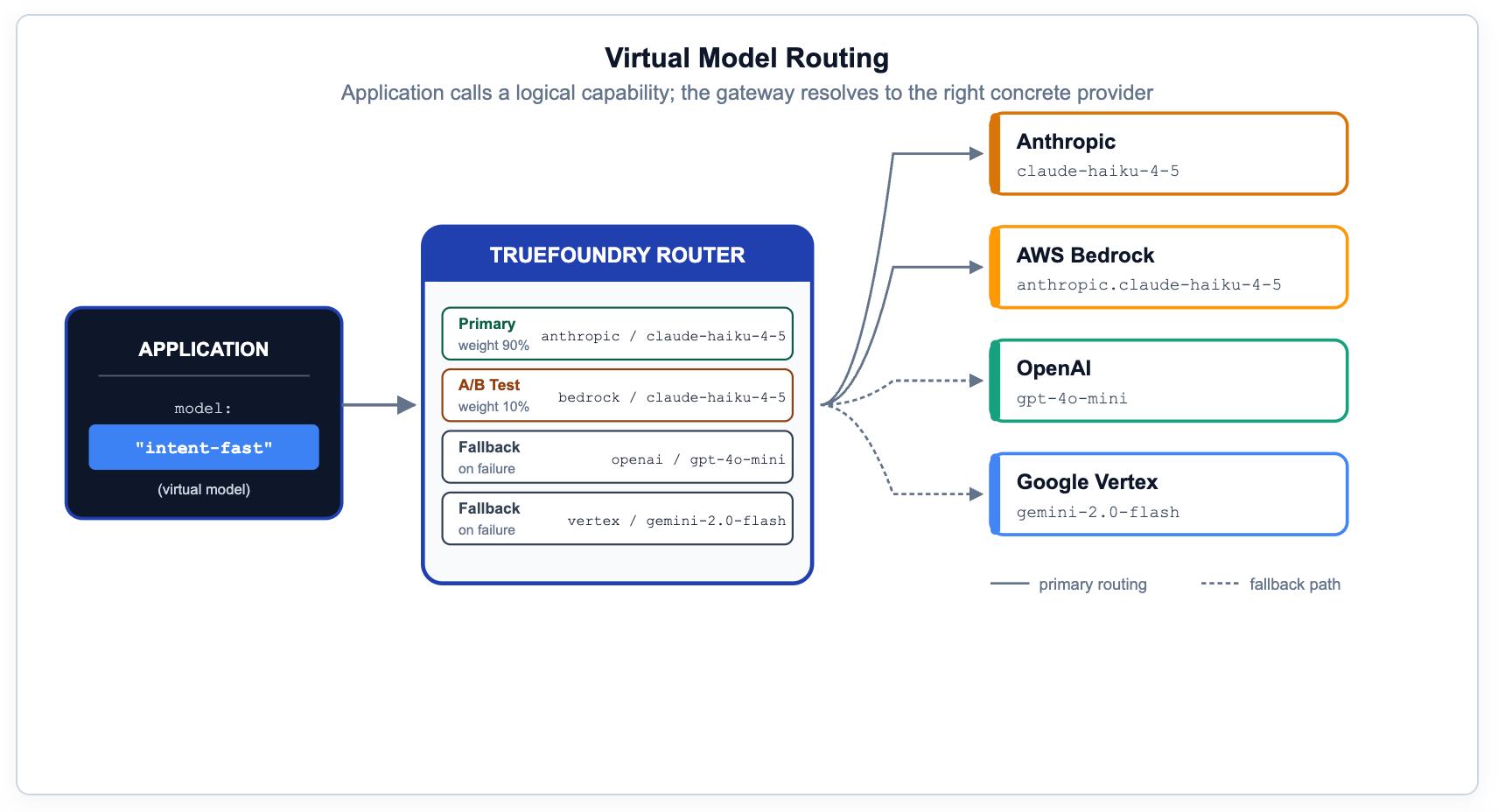
# YAML — gateway-load-balancing-config
# Evaluated top-to-bottom; first match wins.
name: engineering-agent-routing
type: gateway-load-balancing-config
rules:
# Simple repo questions: cheap-first with frontier fallback.
- id: 'simple-repo-questions'
type: priority-based-routing
when:
models: ['prod/engineering-assistant']
metadata:
workflow: 'repo-understanding'
load_balance_targets:
- target: openai-main/gpt-4o-mini
priority: 0
retry_config: {attempts: 2, delay: 100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
- target: anthropic-main/claude-sonnet
priority: 1
# Security-critical: strongest reasoner first.
- id: 'security-critical-review'
type: priority-based-routing
when:
metadata:
workflow: 'security-review'
load_balance_targets:
- target: anthropic-main/claude-opus
priority: 0
- target: openai-main/gpt-4.1
priority: 1
# Cost-sensitive batch: on-prem first, cloud as overflow.
- id: 'batch-processing-jobs'
type: priority-based-routing
when:
metadata:
surface: 'batch-pipeline'
load_balance_targets:
- target: on-prem/llama-3.1-70b
priority: 0
- target: openai-main/gpt-4o-mini
priority: 1
وثائق التوجيه: truefoundry.com/docs/ai-gateway/load-balancing-overview
بمجرد أن تصل تطبيقات الذكاء الاصطناعي إلى مرحلة الإنتاج، فإنها تتعامل مع بيانات مستخدم حقيقية، وفي الإعدادات الوكيلة، تتخذ إجراءات حقيقية عبر الأدوات. محيط الأمان ليس شيئًا واحدًا. بل هو أربع نقاط ربط، تقع في اللحظات الأربع التي يمكن للبوابة أن تتدخل فيها قبل أن يتسبب الطلب في ضرر.
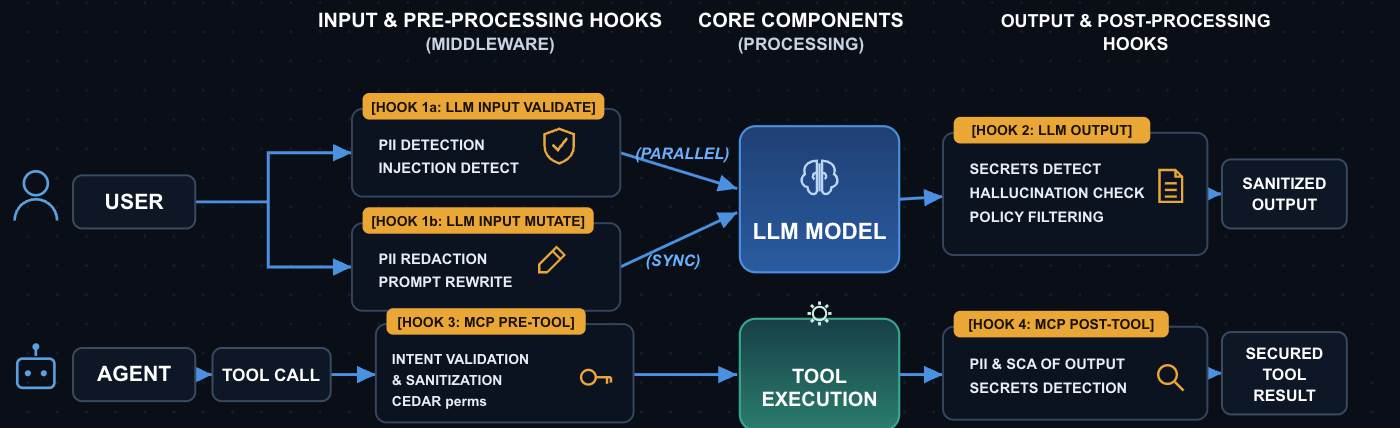
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.
# For org-wide enforcement: AI Gateway → Controls → Guardrails.
X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection"
],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check"
],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions"
],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction"
]
}
# Rollout strategy — never go straight to blocking in production:
# Phase 1: mode=audit (log violations, let requests through)
# Phase 2: mode=enforce (block on fail, fail-open on provider errors)
# Phase 3: mode=strict (block on fail AND on provider errors)
طبق الضوابط الوقائية على ثلاث خطوات: تدقيق ← فرض-مع-تجاهل-الخطأ ← صارم. الإعداد الأوسط هو الذي سينقذك في اليوم الذي يتعرض فيه مزود أمان خارجي لانقطاع.
نظرة عامة على الضوابط الوقائية: truefoundry.com/docs/ai-gateway/guardrails-overview
اكتشاف PII/PHI: truefoundry.com/docs/ai-gateway/tfy-pii
اكتشاف الأسرار: truefoundry.com/docs/ai-gateway/secrets-detection
يهيمن سؤالان على العمليات بمجرد أن يصبح استخدام الذكاء الاصطناعي الخاضع للحوكمة في مرحلة الإنتاج: 'لماذا تصرف هذا الطلب بهذه الطريقة؟' و'هل تتناسب التكلفة التي ندفعها مع العمل الذي نحصل عليه؟' لا يمكن الإجابة على أي منهما من مخطط عدد الرموز.
الحد الأدنى من المعلومات المطلوبة للإجابة عليها — والمعلومات التي توفرها بوابة TrueFoundry جاهزة للاستخدام:
وثائق التحليلات: truefoundry.com/docs/ai-gateway/analytics
تصدير OpenTelemetry: truefoundry.com/docs/ai-gateway/export-opentelemetry-data
تم تصميم الأغلفة الأربعة المذكورة أعلاه بافتراض طلبات على غرار الدردشة: يرسل تطبيقٌ موجهًا، ويعيد النموذج نصًا. لقد تجاوزت أعباء عمل الذكاء الاصطناعي الحديثة هذا الافتراض. تستدعي الوكلاء الأدوات. وتستدعي الأدوات أدوات أخرى. يمكن لطلب مستخدم واحد أن يولد مسار وكيل من 50 خطوة يلامس نصف دزينة من خوادم MCP. لقد انتقل سطح التكلفة، وسطح الأمان، وسطح التدقيق جميعها من الموجه إلى استدعاء الأداة.
لهذا السبب، تدعم بوابة TrueFoundry كلاً من واجهة برمجة تطبيقات LLM وبروتوكول سياق النموذج (MCP) بشكل أصلي. ينطبق نفس غلاف الهوية، ونفس قواطع الدائرة، ونفس آليات المراقبة على استدعاء الأداة كما ينطبق على إكمال الدردشة. يتم حقن هوية OAuth 2.0 في استدعاءات أدوات MCP بحيث يتصرف الوكيل كمستخدم محدد، وليس كحساب خدمة، عند استعلام قاعدة بيانات أو تقديم تذكرة Jira. تتيح لك خوادم MCP الافتراضية إنشاء "خادم وكيل مالي" منطقي من أدوات موزعة عبر ثلاثة خوادم MCP حقيقية، مع تطبيق التحكم في الوصول وحدود المعدل على هذا التكوين.
بروتوكول سياق النموذج مهم للتكلفة، وليس للهندسة المعمارية فحسب. تفيد TrueFoundry بتوفير يصل إلى 99% من رموز الاستدلال عند استخدام الوكلاء لاسترجاع الأدوات النشط بدلاً من حشو السياق في الموجهات — مع قياس الحمل الزائد لاستدعاء الأداة بحوالي 10 مللي ثانية.
من المغري دفع هذه الضوابط إلى رمز التطبيق: غلاف هنا، ومُزخرف بايثون هناك، وفئة مساعدة في إطار عمل الوكيل. يعمل ذلك حتى يكون لديك ثلاثة فرق تطبيقات، ومزودان للنماذج، وعملية استحواذ واحدة، وتدقيق PCI، وحادث حد معدل في يوم ثلاثاء.
عند هذه النقطة تكتشف أنك قد بنيت أربع مستويات تحكم مختلفة قليلاً وغير متوافقة، وأن أياً منها لا يمكنه إيقاف طلب من فريق لم يستورد الغلاف. توجد البوابة لنفس السبب الذي وجدت من أجله بوابات API قبل عقد من الزمان: فهي المكان الوحيد الذي يمكن فيه مراقبة وتشكيل كل طلب، من كل تطبيق، في كل بيئة، بشكل موحد.
الاعتراض على البوابة هو دائمًا "قفزة إضافية في مسار الطلب". تضيف بوابة TrueFoundry AI حوالي 5 مللي ثانية من الحمل الزائد p50 وتتعامل مع أكثر من 350 طلبًا في الثانية على وحدة معالجة مركزية افتراضية واحدة. لا يصمد هذا الاعتراض أمام الأرقام.
البوابة هي أيضاً المكان الوحيد الذي يمكنه التعامل مع النطاق الكامل للبنية التحتية الحديثة للذكاء الاصطناعي: أكثر من 1000 نموذج لغوي كبير (LLM) عبر أكثر من 19 مزودًا، بالإضافة إلى خوادم MCP التي تستدعيها وكلاؤك، بالإضافة إلى النماذج المستضافة ذاتيًا خلف شبكتك الافتراضية الخاصة (VPC). تم ذكر TrueFoundry في تقرير غارتنر "10 أفضل الممارسات لتحسين تكاليف الذكاء الاصطناعي التوليدي والوكيل 2026" — لأن الطريقة الوحيدة التي يمكن للمؤسسات من خلالها تحقيق التحسين الفعلي في هذا النطاق هي بتشغيل كل طلب عبر طبقة واحدة محكومة.
زيادة الرموز (Tokenmaxxing) هي عرض لتبني الذكاء الاصطناعي غير المدار. الهندسة المعمارية المذكورة أعلاه هي العلاج. تحدد الهوية من يطلب. تحدد السياسة ما هو مسموح به. يحدد الأمان ما هو مقبول. تحدد المراقبة ما حدث بالفعل. معًا، يحولون نشاط الرموز الخام إلى دورة حياة طلب محكومة — مسؤولة، مفيدة، آمنة، قابلة للضبط.
الهدف ليس تقليل استخدام الذكاء الاصطناعي. الهدف هو جعل كل سطر منه قابلاً للتفسير.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
