




July 11, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 27, 2026

Blazingly fast way to build, track and deploy your models!
Every major LLM provider implements prompt caching differently. Here's how the TrueFoundry AI Gateway translates cache directives across providers, handles fallback when a target doesn't support caching, and exposes unified hit metrics — with token savings benchmarks.
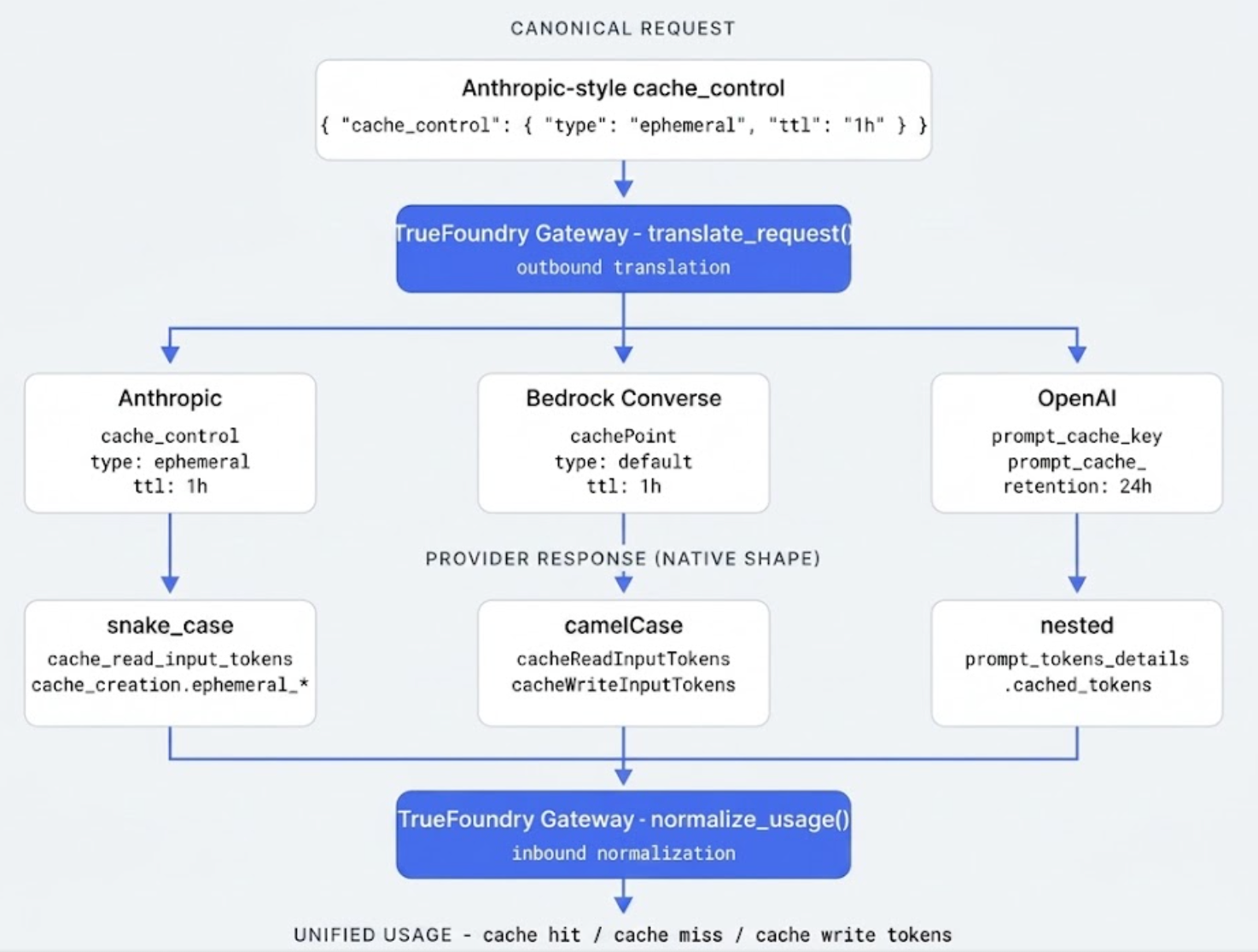
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada

.webp)





.webp)
.webp)
.webp)


.png)


