



.webp)
July 10, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 26, 2026

Blazingly fast way to build, track and deploy your models!
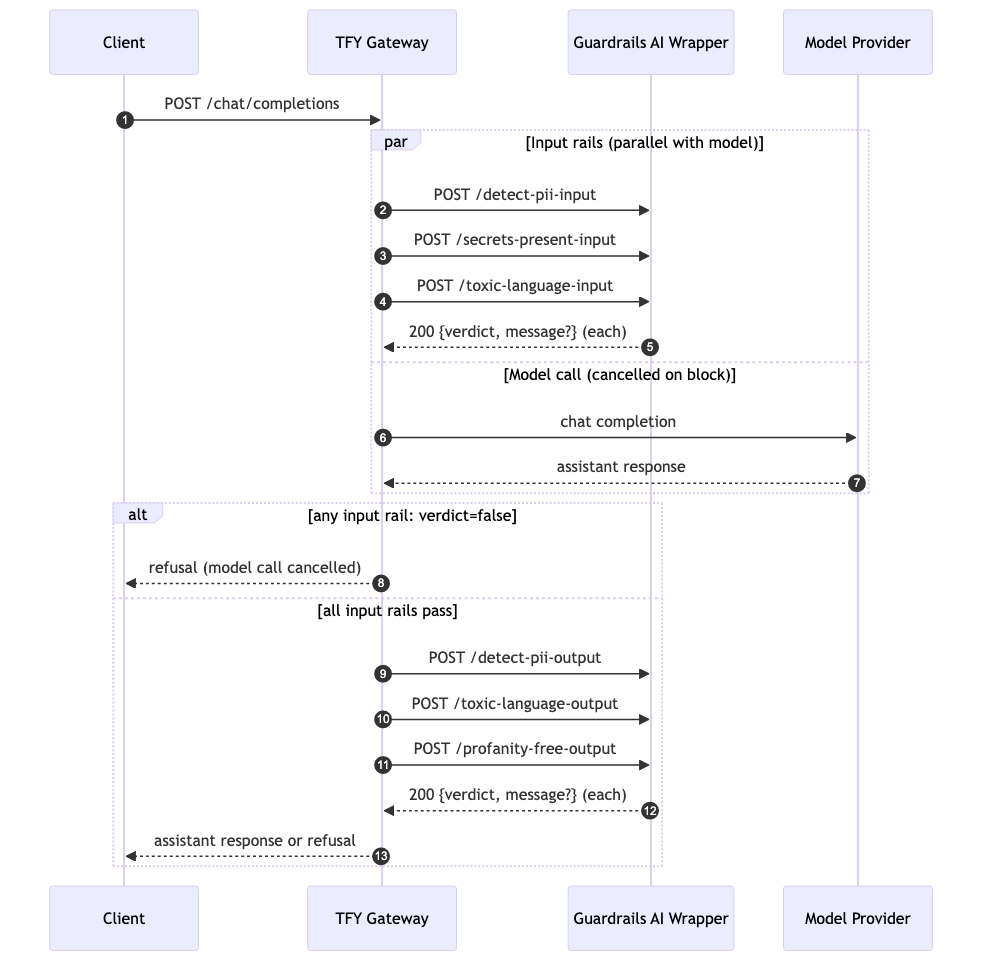
Customer support chats leak SSNs into prompts. Internal developers paste AWS access keys into a coding assistant. A toxic reply slips back to an end user. Every one of these is a real-world LLM operations failure — and every one can be caught by a small local classifier in a few milliseconds, with no LLM round-trip. The harder question is how to wire those checks across hundreds of applications and dozens of model providers, in line with every request, without inventing a different validation stack for each app. The integration between Guardrails AI and TrueFoundry AI Gateway puts the answer in one place.
Every LLM-powered application inside an organization eventually runs into the same question: where should the safety checks live? Bolted into each app, they fragment with every deploy and drift between teams. Pushed in front of each model provider, they multiply across vendors and miss the apps that route around them. TrueFoundry AI Gateway resolves the question by being the single execution layer all LLM traffic passes through — it speaks the OpenAI-compatible API on the front, fans out to every model provider on the back, and runs every cross-cutting concern (auth, rate limits, observability, policy) in the middle. A single pod handles 250+ RPS on 1 vCPU with about 3 ms of added latency, stateless and CPU-bound, with configuration synced through NATS so the request path makes zero external calls.
Centralizing the request path is what makes guardrails fit naturally. The gateway exposes four hooks — llm_input, llm_output, mcp_pre_tool, mcp_post_tool — and any number of guardrails can attach to each. The gateway fans them out in parallel on the same request, so a PII detector, a secret scanner, and a toxicity classifier all evaluate the same prompt at the same time without piling up serial latency. Input rails run concurrently with the model call, and if any of them blocks, the in-flight model call is cancelled before tokens are billed — a real cost-savings property when validators are catching genuine policy violations on customer traffic. A custom HTTP plugin lets any vendor or in-house service participate as long as it speaks the gateway's verdict contract, which is exactly the surface Guardrails AI plugs into.
Guardrails AI is an open-source Python framework for validating LLM inputs and outputs. Its primary abstraction is the Guard — a wrapper around one or more validators pulled from the Guardrails Hub, a registry of pre-built check implementations. The Hub catalog spans PII detection, secret detection, toxicity classification, profanity filters, topic restriction, hallucination grounding, and more. Most validators are local heuristics or small classifiers; a subset call an external LLM at validation time.
The v1 bundle for this integration uses four local validators: DetectPII (a Microsoft Presidio wrapper for emails, phone numbers, US SSN, credit cards, IBAN, US passport / driver license / ITIN), SecretsPresent (Yelp's detect-secrets for AWS keys, OpenAI tokens, GitHub tokens, JWTs, private keys), ToxicLanguage (Unitary's Detoxify classifier from Hugging Face), and ProfanityFree (a word-list filter for assistant responses). None of them require an LLM call. Median validation latency on a warm pod is under 100 ms per validator.
The integration treats Guardrails AI as a library, wraps it in a FastAPI service, and registers the service as a custom HTTP guardrail in TrueFoundry. To avoid a known v0.9.3 quirk where chained Guard.use() calls overwrite each other, the wrapper exposes one POST endpoint per validator per direction — /detect-pii-input, /secrets-present-output, /toxic-language-input, and so on — and runs each Guard in isolation. Operators pick which validators to attach to which model in the dashboard.

Hub validators install at Docker build time via a build arg that carries the Hub token. The token is consumed in the build layer and is not present in the runtime environment. Validator versions are pinned to whatever the Hub served at build time; refreshing the bundle is a Dockerfile edit and a redeploy.
The wrapper response shape is:
Wrapper saysGateway interpretsHTTP 200 + {"verdict": true}Allow — validator did not fireHTTP 200 + {"verdict": false, "message": "<validator>: ..."}Block — gateway propagates the messageHTTP 5xxReal failure — routed through the dashboard's Fail on error policy
HTTP status signals "completed vs errored"; the verdict lives in the JSON. Rail blocks and transient outages are distinguishable, so Fail on error: false is the safe default.
X-TFY-GUARDRAILS header).{"verdict": false, "message": "<validator>: <reason>"}; any that pass return {"verdict": true}.Because no validator calls out to an LLM, the added latency per rail is dominated by Python execution and classifier inference — typically well under 100 ms on a warm pod, with no external dependencies to fail.
The wrapper ships as a single FastAPI service deployable through the standard TrueFoundry Python SDK. Configure the wrapper's URL and bearer key as a Custom Guardrail per validator in the dashboard, attach the rails to a model or select per request, and the validators run inline on every call. The reference implementation lives at integrations/guardrails-ai/ in the integrations-custom-guardrails repo; see the TrueFoundry custom guardrail docs for the dashboard flow and the Guardrails Hub catalog for additional validators.
The architectural principle is the clean separation of validator complexity from gateway execution. The gateway stays stateless, CPU-bound, and free of external dependencies in the request path. Presidio analyzers, detect-secrets plugins, and Hugging Face inference all live behind one HTTP boundary. Swapping in a different validator engine in the future is a wrapper change — the dashboard config, the contract, and the calling apps stay exactly as they are.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
.webp)
.webp)
.webp)







.png)
.webp)




