
TrueFoundry annonce l'acquisition de Seldon AI, élargissant ainsi sa plateforme de contrôle pour l'IA d'entreprise. Lire le rapport complet →

Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.










Solution d'IA pour évaluer et améliorer les compétences en lecture des enfants des communautés mal desservies
Wadhwani AI est une organisation à but non lucratif qui travaille sur de multiples solutions d'IA clés en main pour les populations mal desservies des pays en développement.
Dans le cadre du projet Vachan Samiksha, l'équipe développe une solution d'IA personnalisée que les enseignants des zones rurales de l'Inde peuvent utiliser pour évaluer la maîtrise de la lecture des élèves et élaborer un plan d'urgence personnalisé pour améliorer les compétences en lecture de chaque élève.
L'équipe avait déployé la solution dans les écoles primaires pour mener des projets pilotes. Cependant, l'équipe était confrontée aux problèmes suivants qui devaient être résolus avant que la portée du projet ne soit étendue à un plus grand nombre d'écoles et d'élèves :
L'équipe TrueFoundry s'est associée à l'équipe pour résoudre ces problèmes. Grâce à la plateforme TrueFoundry, l'équipe a pu :
Wadhwani AI a été fondée par Romesh et Sunil Wadhwani (Fait partie de la liste Times100 AI) pour exploiter l'IA pour résoudre les problèmes auxquels sont confrontées les communautés mal desservies des pays en développement. Ils collaborent avec des gouvernements et des organismes mondiaux à but non lucratif du monde entier pour apporter de la valeur grâce à cette solution. En tant qu'organisation à but non lucratif, Wadhwani AI utilise l'intelligence artificielle pour résoudre des problèmes sociaux dans les domaines de l'agriculture, de l'éducation et de la santé, entre autres. Certains de leurs projets incluent :
Wadhwani AI travaille également avec des organisations partenaires pour évaluer leur niveau de préparation à l'IA, c'est-à-dire leur capacité à créer et à utiliser des solutions d'IA de manière efficace et durable. Le travail de Wadhwani AI vise à utiliser l'IA pour le bien et à améliorer la vie de milliards de personnes dans les pays en développement.
Les compétences en lecture sont fondamentales pour les bases éducatives de tout enfant. Malheureusement, de nombreux étudiants des régions rurales et défavorisées de l'Inde et d'autres pays en développement n'ont pas ces compétences. Pour résoudre ce problème à un niveau fondamental, l'équipe d'IA de Wadhwani a développé un outil de fréquence de lecture orale basé sur l'IA appelé Vachan Samiksha.
L'outil déploie l'IA pour analyser les performances de lecture de chaque enfant. Il cible principalement les régions rurales et semi-urbaines du pays à l'heure actuelle et est utilisé pour tous les groupes d'âge. Pour rendre la solution généralisable dans la majeure partie du pays, l'équipe a élaboré un modèle intégrant l'accent pour évaluer les langues régionales et l'anglais. L'évaluation manuelle de ces compétences comporte des biais et est souvent inexacte.
La solution est proposée aux utilisateurs (enseignants des écoles cibles) via une application qui invoque le modèle déployé sur le cloud. L'étudiant est amené à lire un paragraphe, qui est enregistré par l'application et envoyé dans le cloud. Sur le cloud, le modèle évalue la précision de lecture, la vitesse, la compréhension et d'autres retards d'apprentissage complexes qui pourraient ne pas être pris en compte lors d'une évaluation normale. Outre l'évaluation de ces compétences, l'application crée également un plan d'apprentissage personnalisé pour chaque étudiant afin de faciliter son apprentissage et crée également des rapports démographiques pour les actions macroéconomiques des autorités gouvernementales. L'équipe avait déployé le modèle pour le projet pilote avec le service de machine learning géré du fournisseur de cloud.
Lorsque nous avons commencé notre collaboration avec l'équipe de Vachan Samiksha au sein de Wadhwani AI, l'équipe tirait parti de la pile MLOps native de son fournisseur de cloud pour déployer le modèle de son projet pilote auprès du ministère de l'Éducation du Gujarat.
La configuration de leur infrastructure était la suivante :
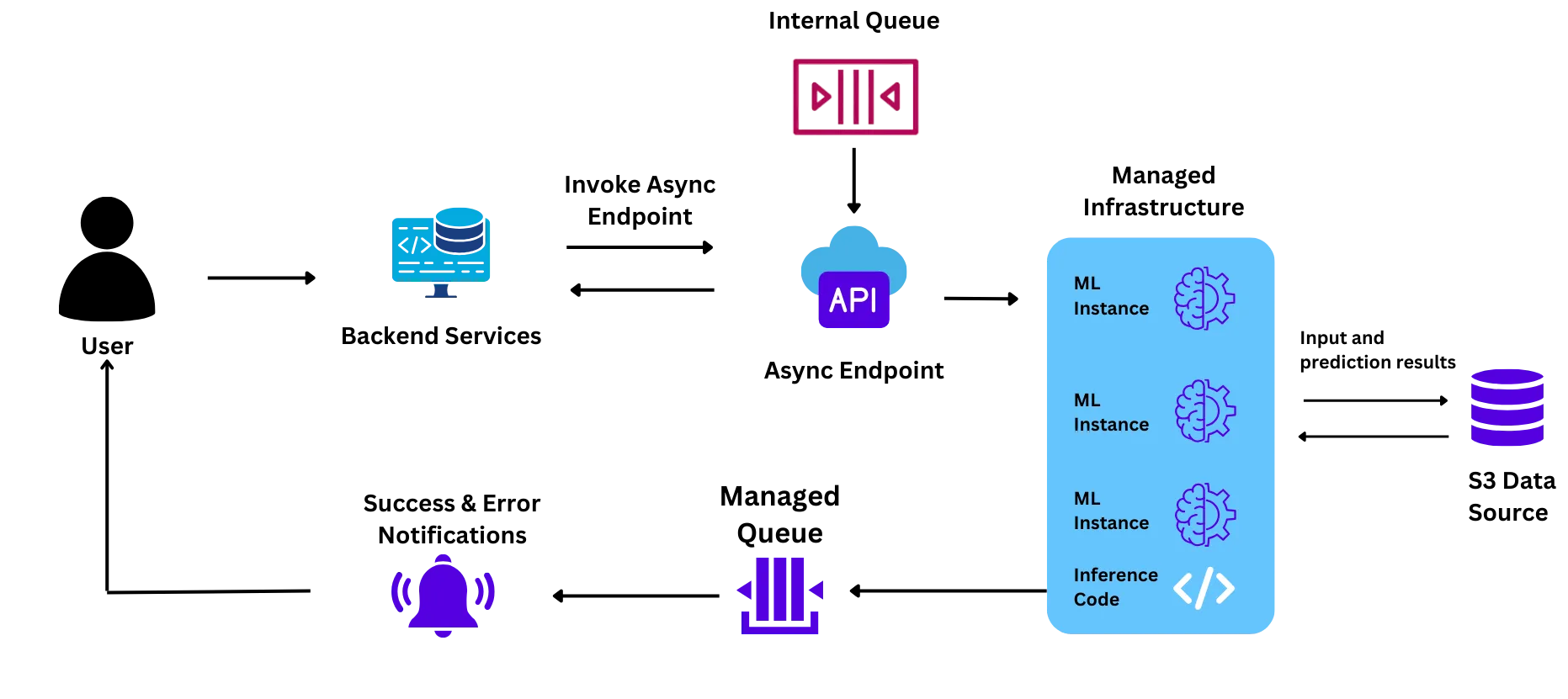
L'équipe a dû faire face à des défis liés à cette configuration lors de la réalisation du premier projet pilote, ce qui l'a motivée à essayer d'autres solutions :
Le projet pilote devait se dérouler à grande échelle (~6 millions d'étudiants en un mois). Cependant, l'équipe n'était pas convaincue que le service de machine learning géré serait en mesure de prendre en charge cette échelle pour les raisons suivantes :
Au cours du projet pilote, l'équipe a rencontré des problèmes de vitesse de mise à l'échelle, et certains modules ne se sont pas présentés comme prévu. Cependant, pour résoudre le problème, l'équipe a contacté les représentants du fournisseur de cloud, qui ont ensuite contacté l'équipe technique. Cela a provoqué un retard dans le système et a retardé le pilote.
Lorsque le trafic de demandes a augmenté pendant le projet pilote, les modules ont dû évoluer horizontalement (créer de nouveaux nœuds capables de récupérer et de traiter certaines des demandes de la file d'attente). Ce processus prenait environ 9 à 10 minutes pour chaque nouveau module lancé, ce qui entraînait des retards de réponse et une mauvaise expérience pour l'utilisateur final.
Les instances GPU sont très coûteuses en raison de la pénurie mondiale de puces. Ajoutez à cela la majoration de 20 à 40 % pour les instances de ML que le fournisseur de cloud place. Cela a rendu le coût des instances très élevé et irréalisable pour l'équipe à l'échelle qu'elle souhaitait gérer le projet.
Lorsque nous avons rencontré l'équipe de Vachan Samiksha, ils se trouvaient entre leur premier projet pilote et le second. Le projet pilote était dans moins d'une semaine et nous avons dû :

Pendant la période qui a précédé le projet pilote :
Notre équipe a aidé l'équipe d'intelligence artificielle de Wadhwan à installer la plateforme sur son propre Kubernetes brut. Le plan de contrôle et le cluster de charge de travail ont tous deux été installés sur leur propre infrastructure. Toutes les données, les éléments de l'interface utilisateur permettant d'interagir avec la plateforme et les processus de charge de travail pour la formation/le déploiement des modèles sont restés dans leur propre VPC. La plateforme était également conforme à toutes les règles et pratiques de sécurité de l'entreprise.
Nous avons aidé l'équipe à comprendre comment les différents composants interagissent pendant le processus de formation et d'intégration. Nous leur avons expliqué comment configurer les ressources, configurer la mise à l'échelle automatique et déployer le modèle.
L'équipe d'IA de Wadhwani a pu migrer l'application elle-même avec un minimum d'aide de la part de l'équipe TrueFoundry. Cela a été fait en une heure d'appel avec l'équipe.
Une fois l'application déployée, l'équipe a commencé à tester la charge au niveau de production. L'équipe a étendu indépendamment l'application à plus de 100 nœuds grâce à un simple argument sur l'interface utilisateur TrueFoundry, soit 5 fois l'échelle la plus élevée jamais atteinte. Ils ont également essayé d'évaluer la vitesse de mise à l'échelle des nœuds, qui était beaucoup (3 à 4 fois) plus rapide que celle fournie par leur.
Une fois les tests de charge terminés, l'équipe a déployé l'application pilote et était prête à la déployer dans la deuxième phase du projet pilote, qui a été déployé dans 1 000 écoles, 9 000 enseignants et plus de 2 lakh d'élèves.
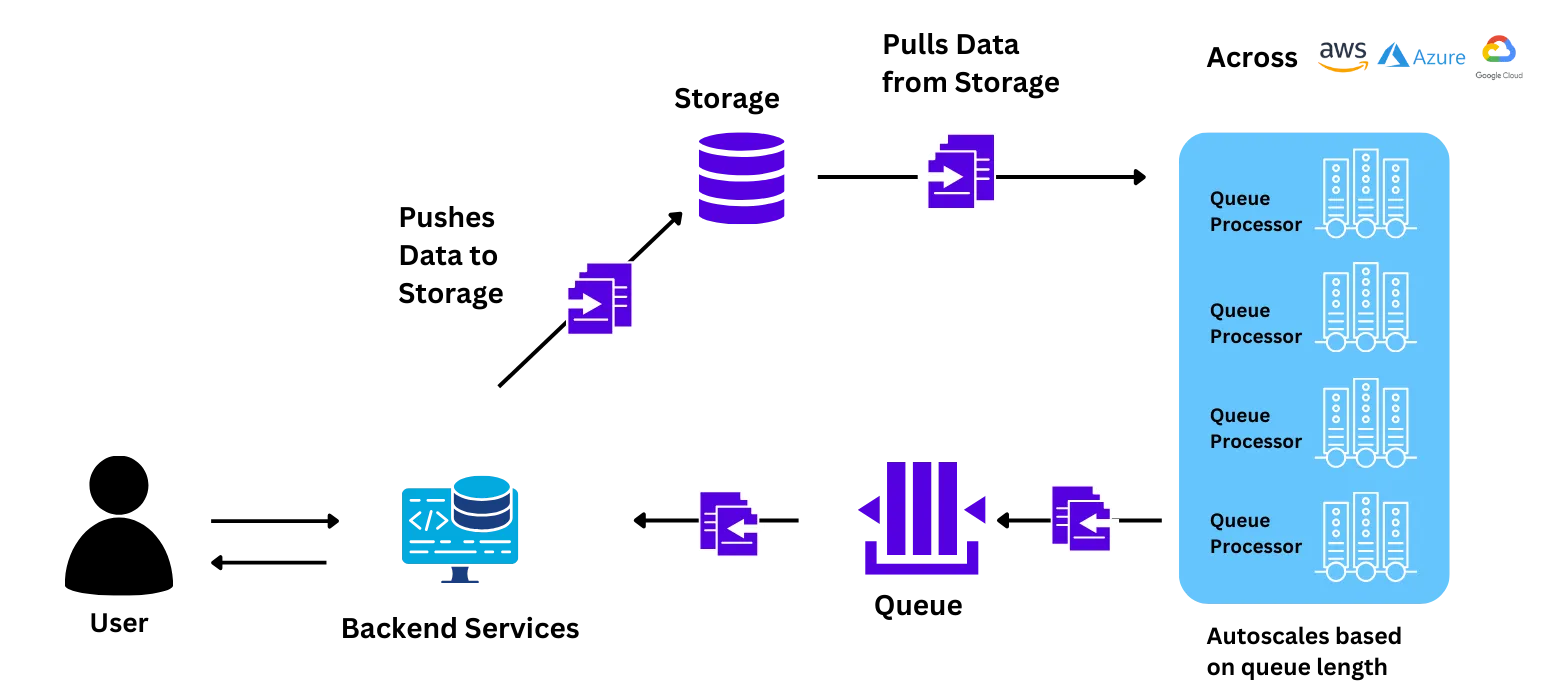
Avec un effort minimal de moins de 10 heures, l'équipe d'IA de Wadhwani a pu réaliser une amélioration significative en termes de vitesse, de contrôle et de coûts. Certains des principaux changements qu'ils ont constatés étaient les suivants :
Les data scientists et les ingénieurs en machine learning ont pu configurer plusieurs éléments, ce qui leur a été difficile à réaliser via la console du fournisseur de cloud ou ils ont dû faire appel à l'équipe d'ingénierie :
Sur la base de la longueur de la file d'attente et en augmentant le nombre maximum de réplicas/nœuds à 70 au lieu de la limite précédente de 20
Étant donné que la majeure partie de la circulation des pilotes se faisait pendant les heures de classe, lorsque les professeurs interagissaient avec les élèves, les demandes ont été minimes, voire aucune, en soirée et en soirée. L'équipe constante a pu mettre en place un calendrier de dimensionnement grâce auquel les modules ont été réduits au minimum pendant les heures d'arrêt (soir et nuit). Cela a permis d'économiser environ 15 à 20 % du coût du projet pilote.
L'équipe a pu facilement surveiller le trafic, l'utilisation des ressources et les réponses directement depuis l'interface utilisateur TrueFoundry. Ils ont également reçu des suggestions via la plateforme chaque fois qu'il y avait un surapprovisionnement ou un sous-approvisionnement des ressources
Pour tester la mise à l'échelle avec TrueFoundry, l'équipe a envoyé une rafale de 88 requêtes à l'application et a comparé les performances du service ML géré du fournisseur de cloud à celles de TrueFoundry. Toutes les configurations du système ont été conservées conformément à la logique de dimensionnement (en fonction de la longueur de la file d'attente, du nombre initial de nœuds, du type d'instance, etc.)
Nous avons réalisé que TrueFoundry pouvait évoluer 78 % plus rapidement que le service de ML géré, qui permettait à l'utilisateur de répondre beaucoup plus rapidement. Le temps nécessaire pour répondre à la requête de bout en bout a été réduit de 40 % avec TrueFoundry.
Les coûts engagés par l'équipe pour le projet pilote ont été réduits d'environ 50 % en passant à TrueFoundry, grâce aux facteurs suivants :
Alors que Managed ML Service était limité par la disponibilité d'instances GPU dans la même région du fournisseur de cloud, TrueFoundry peut ajouter des nœuds de travail au système qui peuvent se trouver dans n'importe quelle région ou fournisseur de cloud.
Cela signifie que :
TrueFoundry s'intègre parfaitement à tous les outils que l'équipe souhaite utiliser. En ce qui concerne le fournisseur de cloud, cela était limité par les choix de conception choisis par le fournisseur et ses intégrations natives. Par exemple, l'équipe souhaitait utiliser le NATS pour publier des messages, ce que le service natif du fournisseur de cloud ne proposait pas actuellement. TrueFoundry a simplifié ce type de choix pour l'équipe d'IA de Wadhwani.







Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception



