

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 29, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Érase una vez, hace aproximadamente seis meses, en los años de una empresa emergente, Jason, un brillante ingeniero de aprendizaje automático en una empresa de tecnología financiera en rápido crecimiento. Jason era el «experto en inteligencia artificial» residente. Cuando el equipo de producto necesitó su nuevo chatbot con tecnología de LLM para mostrarse más empático pero menos propenso a las alucinaciones sobre los tipos de interés, llamaron a Jason.
El conjunto de herramientas de Jason era enorme: bases de datos vectoriales de última generación, clústeres de Kubernetes altamente optimizados y canalizaciones de CI/CD sofisticadas. Sin embargo, el meollo de la operación, las verdaderas motivaciones que impulsaron estas funciones multimillonarias, residía en un ecosistema precario.
Algunas instrucciones estaban codificadas en cadenas f de Python, enterradas en lo profundo de la lógica condicional como artefactos antiguos. Otras estaban en un documento compartido de Google de 40 páginas titulado «Final_Prompts_v3_real_final (2) .docx», mantenido por tres jefes de producto diferentes. Actualmente, el director ejecutivo le dio a Jason las instrucciones experimentales más recientes a las 23:30 horas.
Cuando un cliente se quejó de que el chatbot le había ofrecido una hipoteca en klingon de manera confusa, Jason no depuró el código. Jason realizó una excavación arqueológica para revisar la historia de Slack y git se compromete a averiguarlo qué versión del «mensaje de empatía» que estaba en producción y quién lo cambió por última vez.
Jason ya no se dedicaba a la ingeniería. Jason estaba haciendo trabajos de limpieza digital. El equipo había construido un motor Ferrari, pero lo manejaba con cuerdas sueltas.
El dolor detrás de la historia anterior es en realidad agudo y universal. La transición de la IA generativa de un prototipo de hackatón a un sistema de producción fiable revela una pieza fundamental que falta en la gama tradicional de MLOps.
Al principio, tratar las indicaciones como código parecía lógico. Las versionas en Git y las despliegas con la aplicación. Sin embargo, a medida que los equipos crecen, este modelo se derrumba. Las instrucciones no son código tradicional; son la configuración, la lógica empresarial y la interfaz de usuario, todo en un paquete de lenguaje natural.
Cuando las solicitudes se combinan estrechamente con las bases de código, surgen varios problemas críticos:
Para cruzar el abismo entre el prototipo y la producción, debemos dejar de tratar las indicaciones como «cadenas mágicas» dispersas por toda nuestra infraestructura. Tenemos que tratarlos como ciudadanos de primera clase.
Antes de implementar un enfoque estructurado, el flujo de trabajo suele parecer una maraña de falta de comunicación y esfuerzo manual.
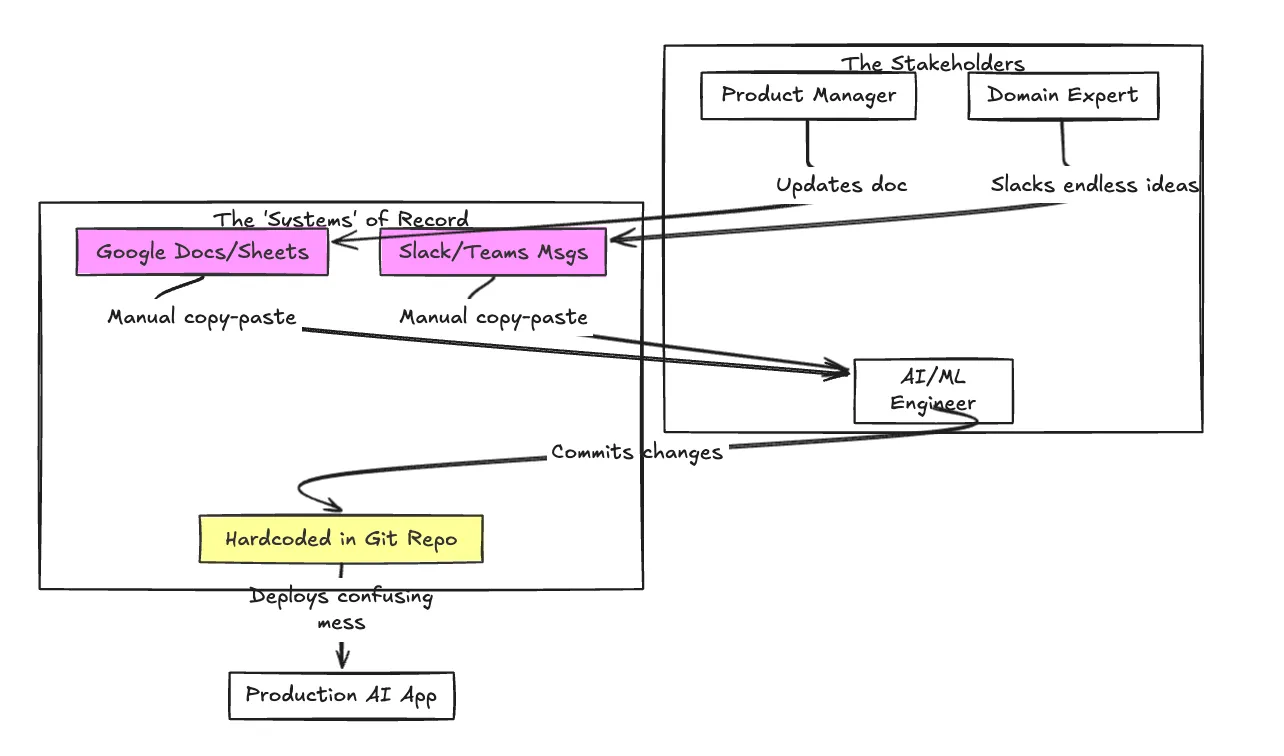
Aquí es donde un sistema de gestión rápida dedicado se vuelve esencial. Es el puente entre el arte experimental de la ingeniería rápida y la rigurosa disciplina de la ingeniería de software de producción.
TrueFoundry actúa como este sistema de control central. Está diseñado para desvincular la administración de solicitudes de la lógica de las aplicaciones, lo que permite a los equipos colaborar, versionar, evaluar e implementar las solicitudes con el mismo rigor con el que se aplica al código tradicional, pero con interfaces diseñadas para las necesidades específicas de los flujos de trabajo de LLM.
TrueFoundry transforma la gestión rápida de una tarea ad hoc en una capa de infraestructura estructurada y auditable.
TrueFoundry proporciona un registro rápido centralizado. Se acabó la búsqueda en Google Docs o bases de código. Cada mensaje, para cada caso de uso, reside en una ubicación segura y accesible.
Este es el cambio de velocidad más significativo. En TrueFoundry, el código de la aplicación no contiene el texto de la solicitud. En su lugar, contiene una llamada sencilla al SDK que obtiene la versión activa del mensaje deseado.
Esto significa que un gerente de producto puede repetir una solicitud, probarla en el área de producción de TrueFoundry y «promoverla» a producción sin que un ingeniero tenga que tocar el código de la aplicación o activar una reimplementación.
Con TrueFoundry, el caos se transforma en un ciclo de vida simplificado. Las partes interesadas colaboran en el centro, las versiones se controlan rigurosamente y las aplicaciones consumen las solicitudes de forma fiable a través de la API, con limitación de velocidad en AI Gateway garantizar un comportamiento de producción estable en condiciones de uso intensivo.
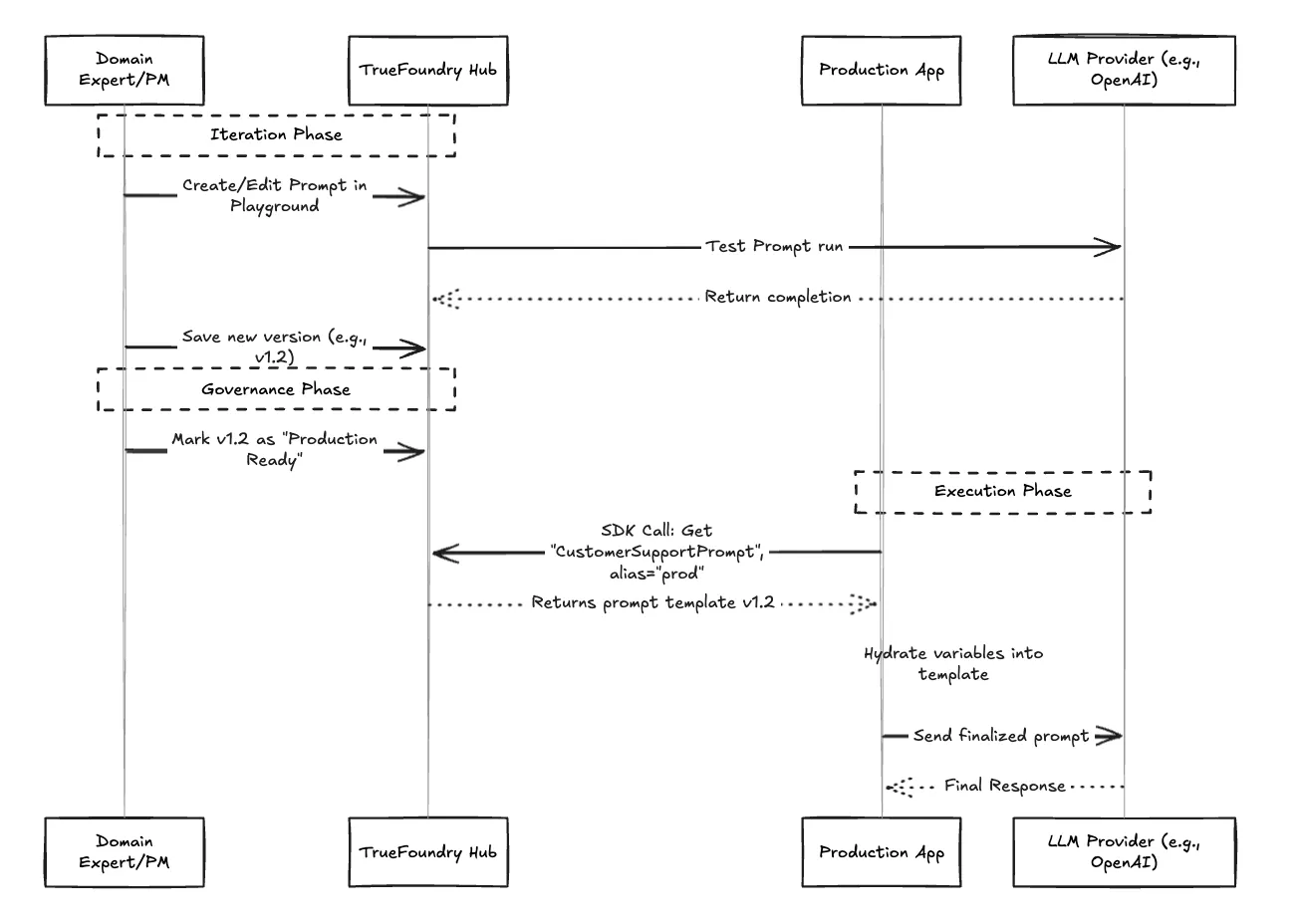
Gestionar el mensaje de texto es solo la mitad de la batalla. ¿Cómo sabes si la versión 2.0 es realmente mejor que la 1.5? TrueFoundry integra la evaluación junto con la gestión. Antes de pasar un mensaje a producción, puede compararlo con los conjuntos de datos más importantes para garantizar que la precisión, el tono y la seguridad no hayan disminuido.
Para obtener más información, visite https://truefoundry.com/docs/ai-gateway/prompt-management
Volviendo a nuestra historia, Jason implementó TrueFoundry. Los documentos de Google se archivaron. Las cadenas codificadas se sustituyeron por llamadas al SDK.
Ahora, cuando el CEO quiere cambiar el tono del chatbot, inicia sesión en TrueFoundry, redacta una nueva versión, la prueba con algunos ejemplos y etiqueta a Jason para que la revise. Jason puede ver la diferencia exacta, ejecutar una evaluación basada en ella y aprobar su implementación en cuestión de minutos, todo ello sin escribir ni una sola línea de Python.
El cambio a la IA de producción requiere reconocer que las indicaciones son una nueva clase de artefacto de software. Necesitan su propia infraestructura dedicada. TrueFoundry proporciona las herramientas necesarias para convertir el arte de la ingeniería rápida en una disciplina de ingeniería escalable y manejable, garantizando que tus aplicaciones de IA generativa sean tan sólidas como el resto de tu gama.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


