

May 23, 2024
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 8, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los modelos lingüísticos grandes (LLM) se han convertido en la columna vertebral de las aplicaciones modernas de inteligencia artificial, ya que impulsan todo, desde chatbots y asistentes virtuales hasta herramientas de investigación y soluciones empresariales. Sin embargo, no todos los LLM se crean de la misma manera: cada uno tiene puntos fuertes, limitaciones y factores de costo únicos. Algunos se destacan en el razonamiento, mientras que otros son mejores en la escritura creativa, la codificación o la gestión de consultas estructuradas. Aquí es donde un Enrutador LLM entra.
Un router LLM actúa como un controlador de tráfico inteligente, que dirige automáticamente las instrucciones del usuario al modelo más adecuado en función de la tarea en cuestión. En lugar de confiar en un solo modelo, las empresas y los desarrolladores pueden optimizar el rendimiento, la precisión y los costos al dirigir las consultas al LLM correcto en tiempo real. A medida que crece la adopción de la IA, el enrutamiento del LLM se está convirtiendo en una capa esencial para crear sistemas de IA escalables, confiables y eficientes.
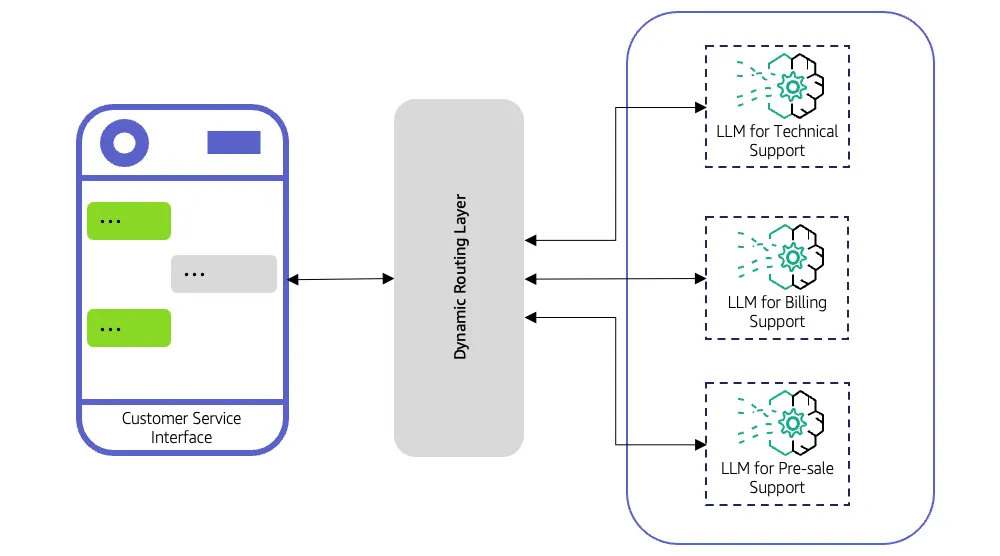
Un router LLM decide qué modelo de lenguaje grande debe gestionar cada solicitud. En lugar de enviar cada consulta a un único modelo, evalúa la entrada, aplica la lógica de enrutamiento y la reenvía al modelo más adecuado.
El router puede seguir reglas simples, como dirigir las consultas relacionadas con el código a un modelo centrado en la programación, o utilizar estrategias avanzadas como clasificadores, incrustaciones o modelos predictivos ligeros para determinar qué LLM ofrecerá la mejor respuesta.
Cómo funciona
Este enfoque elimina el problema de la «talla única». Los modelos livianos gestionan las consultas rutinarias de manera eficiente, mientras que las tareas complejas o que requieren mucho razonamiento se asignan a LLM más capaces.
En la práctica, el router se encuentra entre las aplicaciones y varios LLM, lo que optimiza el rendimiento, reduce los costos y minimiza la dependencia de un solo proveedor. Esta configuración garantiza que cada solicitud llegue al modelo correcto y, al mismo tiempo, mantiene la fiabilidad y la flexibilidad de los sistemas de IA.
Las empresas confían cada vez más en los modelos de grandes lenguajes para tareas que van desde los chatbots y los asistentes virtuales hasta la creación de contenido y el análisis de datos.
Sin embargo, el uso de un único LLM para todas las tareas crea desafíos. Algunos modelos responden rápidamente pero carecen de profundidad, mientras que otros proporcionan resultados precisos con una latencia y un coste elevados. Sin una forma de gestionar estas diferencias, los equipos sacrifican constantemente el rendimiento, la precisión y el presupuesto.
Un router LLM resuelve este problema dirigiendo de forma inteligente las solicitudes al modelo más adecuado para la tarea.
Considera este escenario:
Un sistema de atención al cliente recibe dos tipos de consultas.
Una solicitud sencilla como «¿Cuál es su horario de trabajo?» no necesita un modelo muy avanzado, mientras que una pregunta técnica compleja sobre la solución de problemas del producto sí lo necesita. Sin un router LLM, todas las consultas podrían dirigirse a un modelo caro y de alta potencia. Esto aumenta los costos y ralentiza los tiempos de respuesta. Con un router, la consulta simple pasa a un modelo rápido y ligero, mientras que la consulta compleja se dirige a un LLM más capaz, lo que optimiza la velocidad, el costo y la precisión.
Beneficios para las empresas
Al enrutar las consultas de forma inteligente, las empresas ofrecen servicios de IA más rápidos, precisos y rentables. Los enrutadores LLM transforman la implementación de la IA de un enfoque único para todos en un sistema flexible, confiable y eficiente, lo que los convierte en esenciales para la infraestructura de IA moderna.
Un router LLM es más que un director de tráfico, proporciona varias funciones básicas que hacen que los sistemas de IA sean más inteligentes, rápidos y confiables. Comprender estas funciones ayuda a las organizaciones a diseñar flujos de trabajo de IA que se escalen de manera eficiente y, al mismo tiempo, mantengan la calidad.
Antes de que se produzca cualquier enrutamiento, el router analiza las consultas entrantes. Examina los metadatos, las etiquetas, el tipo de consulta, la complejidad y, a veces, la intención o el sentimiento. Este análisis proporciona el contexto para que el router pueda decidir qué modelo es el más adecuado para gestionar la solicitud. Por ejemplo, la pregunta de un cliente sobre la facturación se puede enviar a un LLM ligero de uso general, mientras que una consulta de solución de problemas técnicos se puede enviar a un modelo de dominio específico.
El router selecciona el modelo más adecuado en función de varios criterios, entre los que se incluyen:
Al considerar estos factores, el router garantiza que cada solicitud obtenga el mejor equilibrio entre velocidad, precisión y costo.
Cuando varios modelos pueden realizar la misma tarea, el router distribuye las solicitudes de manera inteligente para evitar sobrecargar un solo modelo. Esto mejora la capacidad de respuesta general del sistema y garantiza un rendimiento constante durante los picos de uso.
Incluso los mejores modelos pueden fallar, perder el tiempo de espera o arrojar respuestas con poca confianza. El router implementa mecanismos de respaldo y redirige automáticamente las consultas a los modelos de respaldo. Esto garantiza la continuidad y la confiabilidad sin interrumpir al usuario.
Los enrutadores avanzados rastrean los patrones de uso, el rendimiento de los modelos y los resultados de las consultas. Esta información ayuda a los equipos a optimizar las estrategias de enrutamiento, seleccionar mejores modelos y reducir los costos con el tiempo.
Un router LLM actúa como el centro de toma de decisiones de los sistemas de IA multimodelo. Al analizar las solicitudes, seleccionar el modelo correcto, equilibrar la carga, gestionar las fallas y proporcionar información, garantiza que cada consulta se procese de manera eficiente, precisa y confiable. Esta combinación de funciones convierte a LLM Routers en un componente fundamental para crear soluciones de IA sólidas, escalables y rentables.
Los enrutadores LLM utilizan diferentes estrategias para dirigir las consultas al modelo de lenguaje más adecuado de manera eficiente. Estas estrategias generalmente se dividen en tres categorías: estáticas, dinámicas e híbridas, y los sistemas avanzados a veces incorporan el aprendizaje por refuerzo.
El enrutamiento estático se basa en reglas predefinidas para decidir qué modelo gestiona una consulta. Garantiza un comportamiento de enrutamiento uniforme y es fácil de implementar.
El enrutamiento dinámico se adapta en tiempo real y selecciona modelos según el rendimiento actual del sistema y el contexto de consulta.
Las estrategias híbridas combinan enfoques estáticos y dinámicos para lograr una mayor flexibilidad y eficiencia.
Algunos sistemas avanzados utilizan el aprendizaje por refuerzo para mejorar continuamente las decisiones de enrutamiento. Estos enrutadores aprenden de las consultas anteriores y modelan el rendimiento, lo que optimiza el enrutamiento a lo largo del tiempo para cargas de trabajo complejas o en evolución.
Un router LLM ofrece varios beneficios clave que hacen que los sistemas de IA sean más eficientes, confiables y rentables. Una de las principales ventajas es la optimización del rendimiento.
Al enrutar de forma inteligente cada consulta al modelo más adecuado para la tarea, el router garantiza que los modelos potentes y capaces de razonar gestionen preguntas complejas, mientras que los modelos ligeros y rápidos procesan las solicitudes más sencillas. Este enfoque equilibra la velocidad y la precisión, lo que mejora la experiencia general del usuario.
Otro beneficio importante es la rentabilidad. Sin un router, las empresas pueden ejecutar todas las consultas mediante modelos de alta potencia, lo que aumenta los costos operativos de forma innecesaria. El router garantiza que los modelos caros se reserven para consultas complejas o de alto valor, mientras que las tareas rutinarias o repetitivas se gestionan mediante modelos que consumen menos recursos, lo que reduce los gastos de procesamiento y maximiza el ROI.
La confiabilidad también mejora con un router LLM. Los enrutadores avanzados incluyen mecanismos alternativos que redirigen automáticamente las consultas si un modelo falla, se agota el tiempo de espera o arroja resultados poco confiables. Esto garantiza un rendimiento constante y confiable, evitando interrupciones en las aplicaciones en tiempo real, como la atención al cliente o los asistentes virtuales.
Además, los enrutadores LLM brindan flexibilidad. Las organizaciones pueden integrar varios modelos de diferentes proveedores y elegir el mejor para cada tarea.
Esto reduce la dependencia de un solo proveedor y permite a los equipos experimentar con diferentes modelos a medida que surgen nuevas capacidades.
Por último, los enrutadores admiten la escalabilidad. A medida que aumentan los volúmenes de consultas, el router distribuye las solicitudes de forma inteligente entre los modelos, lo que evita la sobrecarga y mantiene un rendimiento fluido del sistema.
Al combinar el enrutamiento optimizado, el ahorro de costos, la confiabilidad, la flexibilidad y la escalabilidad, un enrutador LLM transforma las implementaciones de IA de un enfoque rígido de modelo único a un sistema dinámico, eficiente y resiliente.
Los enrutadores LLM se utilizan cada vez más en las empresas para optimizar el rendimiento, la confiabilidad y la eficiencia de la IA. Permiten el enrutamiento inteligente de consultas, lo que garantiza que el modelo correcto gestione cada tarea en función de la complejidad, el dominio y el contexto.
Automatización de la atención al cliente
Las empresas gestionan miles de consultas de los clientes a diario, desde simples preguntas frecuentes hasta problemas técnicos complejos. Los enrutadores LLM dirigen las preguntas rutinarias a modelos rápidos y livianos, mientras que los problemas complicados se dirigen a modelos más capaces. Esto garantiza respuestas rápidas, precisas y consistentes, lo que mejora la satisfacción del cliente y reduce la carga operativa.
Gestión del conocimiento y búsqueda empresarial
Las empresas mantienen grandes repositorios de documentos internos, manuales y políticas. Los enrutadores analizan las consultas y las dirigen a modelos optimizados para el razonamiento, el resumen o el conocimiento de un dominio específico. Los empleados reciben información precisa y relevante desde el punto de vista del contexto sin sobrecargar los modelos de alto costo.
Automatización de flujos de trabajo y tareas
Los LLM se utilizan ampliamente para la generación de informes, el análisis de datos y las tareas de apoyo a la toma de decisiones. Los enrutadores asignan dinámicamente consultas de alta complejidad a modelos potentes y tareas rutinarias a modelos más livianos, equilibrando la velocidad, la precisión y los costos de procesamiento en los flujos de trabajo empresariales.
Orquestación multimodelo
Las organizaciones suelen implementar varios LLM en todos los proveedores o dominios. Los enrutadores gestionan la selección de modelos, el equilibrio de carga y los mecanismos de respaldo, lo que garantiza la confiabilidad, la flexibilidad y la escalabilidad en los sistemas de IA a gran escala.
Recomendaciones y personalización de productos
Para las plataformas de comercio electrónico o SaaS, los enrutadores LLM pueden asignar tareas de personalización a modelos entrenados en el comportamiento y el contexto del usuario, al tiempo que delegan recomendaciones genéricas a modelos más simples. Esto mejora la precisión y el rendimiento de las recomendaciones y, al mismo tiempo, controla los costos.
Análisis de riesgos y cumplimiento
En las empresas financieras, legales o de atención médica, las consultas pueden requerir el cumplimiento estricto de las regulaciones o las pautas específicas del dominio. Los enrutadores pueden dirigir las consultas delicadas o de alto riesgo a modelos con experiencia en la materia, lo que garantiza el cumplimiento de las normas, mientras que las tareas generales se gestionan mediante modelos estándar.
Generación y resumen de contenido
Para el marketing, el intercambio de conocimientos o la documentación, LLM Routers puede asignar tareas complejas de creación de contenido a modelos de alta calidad y tareas de resumen o redacción más sencillas a modelos más rápidos, optimizando la eficiencia sin comprometer la calidad de los resultados.
Al aplicar los enrutadores LLM en estos diversos escenarios, las empresas pueden escalar la IA de manera inteligente, manteniendo el rendimiento, la confiabilidad y la rentabilidad en múltiples flujos de trabajo y aplicaciones.
Tras explorar cómo los routers LLM impulsan una amplia gama de aplicaciones empresariales, es importante entender en qué se diferencian de otro componente clave de los sistemas de IA multimodelo.
Un Enrutador LLM se centra en el enrutamiento inteligente de solicitudes. Su función principal es analizar las consultas entrantes, evaluar el contexto, la complejidad y los metadatos y, a continuación, dirigir cada solicitud al modelo más adecuado. Los enrutadores suelen incorporar estrategias avanzadas, como el enrutamiento dinámico, la toma de decisiones teniendo en cuenta el contexto y los mecanismos alternativos para optimizar la precisión, la velocidad y el costo.
Son particularmente importantes en entornos en los que las consultas varían mucho en cuanto a tipo, dominio o requisitos computacionales, lo que permite a las empresas equilibrar la carga y mantener un alto rendimiento.
Un Puerta de enlace LLM, por otro lado, actúa como un punto de acceso centralizado para interactuar con uno o varios LLM. Su función principal es simplificar la integración, proporcionar API estandarizadas, gestionar la autenticación, gestionar la limitación de velocidad y supervisar el uso.
A diferencia de los enrutadores, las puertas de enlace no suelen tomar decisiones inteligentes de selección de modelos; proporcionan controles operativos y de acceso uniformes para facilitar las implementaciones de varios modelos. Las pasarelas se centran más en la administración, la seguridad y la escalabilidad a nivel de infraestructura que en la optimización a nivel de consulta.
Diferencias clave
Los enrutadores y las puertas de enlace suelen trabajar juntos en arquitecturas en capas. La puerta de enlace proporciona un punto de entrada seguro y estandarizado para las aplicaciones, mientras que el enrutador se encuentra detrás de ella, lo que permite tomar decisiones inteligentes sobre la selección del modelo. Esta combinación permite a las empresas lograr tanto el control operativo como la gestión optimizada de las consultas.
Comprender la distinción entre los enrutadores LLM y las pasarelas LLM ayuda a las organizaciones a implementar sistemas de IA multimodelo de manera efectiva.
Los enrutadores impulsan un rendimiento inteligente y sensible al contexto, mientras que las pasarelas garantizan un acceso seguro, escalable y confiable, creando una base sólida para la IA empresarial.
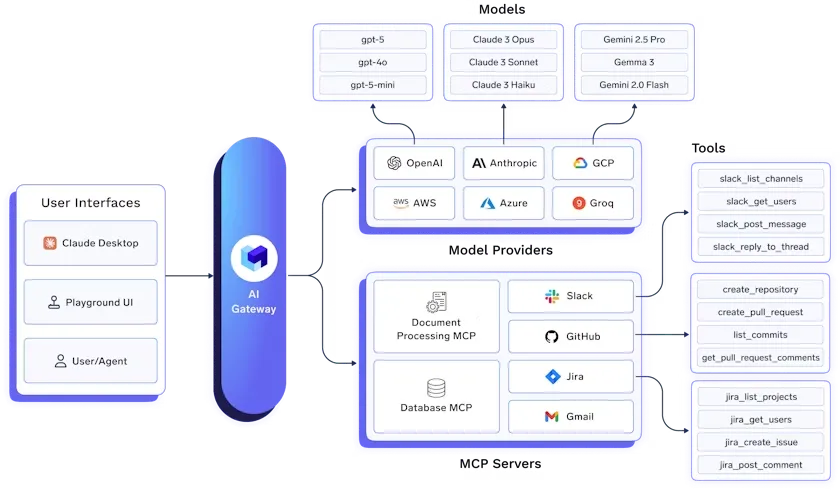
El TrueFoundry LLM Gateway es una plataforma preparada para la empresa que unifica el acceso a todos los principales modelos lingüísticos (LLM) a través de una API única, segura y de alto rendimiento.
Simplifica la infraestructura de GenAI al integrar más de 250 modelos, incluidos OpenAI, Anthropic Claude, Gemini, Groq, Mistral y marcos de código abierto, sin necesidad de cambiar el código. Los equipos pueden usar una API uniforme para chatear, completar, incrustar y volver a clasificar las cargas de trabajo, a la vez que centralizan la autenticación y la administración de las claves de API.
Características principales:
A medida que las empresas confían cada vez más en varios modelos de grandes lenguajes, herramientas como los enrutadores LLM y las pasarelas LLM se han vuelto indispensables para gestionar la IA a escala. Los enrutadores LLM aportan inteligencia al sistema, ya que analizan cada consulta y garantizan que llegue al modelo más adecuado para la tarea. Esto mejora el rendimiento, reduce los costos y mejora la confiabilidad, especialmente en flujos de trabajo complejos y de gran volumen.
Mientras tanto, las pasarelas proporcionan la columna vertebral para un acceso seguro y estandarizado a los modelos, lo que simplifica la integración, monitorea el uso y aplica los controles operativos.
Juntos, estos componentes forman una arquitectura de IA en capas que equilibra la inteligencia con la eficiencia operativa. Al combinar las capacidades de toma de decisiones de los enrutadores con la confiabilidad estructural de las puertas de enlace, las organizaciones pueden maximizar el valor de varios LLM y, al mismo tiempo, mantener la escalabilidad y el control.
La adopción de los enrutadores LLM ya no es opcional; es una necesidad para las empresas que desean ofrecer servicios de IA rápidos, precisos y rentables. Comprender su función, junto con las pasarelas, permite a los equipos diseñar infraestructuras de IA sólidas que satisfagan las diversas necesidades empresariales.
A medida que los modelos de IA sigan evolucionando y multiplicándose, dominar el enrutamiento inteligente y el acceso estructurado será fundamental para las empresas que buscan mantenerse competitivas en el panorama de la IA que avanza rápidamente.
El enrutamiento de LLM funciona mediante la evaluación de las solicitudes entrantes comparándolas con la lógica predefinida, las incrustaciones semánticas o las reglas de clasificación. El sistema dirige el tráfico en función del contexto, la precisión requerida o la latencia ascendente del proveedor. Una puerta de enlace centralizada administra estas configuraciones complejas para automatizar la selección de modelos y la conmutación por error sin necesidad de cambiar el código manualmente en cada actualización del modelo.
La clasificación de enrutamiento de LLM utiliza un modelo altamente eficiente para categorizar las solicitudes antes de la ejecución de la inferencia. Este paso identifica la intención, como los saludos simples frente a las tareas de codificación complejas. La clasificación automatizada evita la sobreutilización de costosos modelos fronterizos al filtrar las consultas de baja complejidad y buscarlas en alternativas más pequeñas, rápidas y rentables.
TrueFoundry unifica las capacidades de enrutamiento de LLM y AI Gateway al combinar la orquestación del tráfico con la gobernanza y la seguridad. La plataforma gestiona los modelos de conmutación por error, limitación de velocidad y enrutamiento rentable dentro de un único plano de control centralizado. Esta infraestructura garantiza que las implementaciones de IA empresarial sean altamente resilientes y rentables para los entornos de producción a gran escala.
Los principales enrutadores LLM incluyen TrueFoundry para la orquestación de nivel empresarial, LitellM para una API de proxy unificada y Martian para la selección automatizada de modelos. Otras de las principales opciones del sector son Portkey para sistemas de protección avanzados, Helicone para una observabilidad increíblemente rápida y OpenRouter para un acceso sencillo a cientos de modelos de código abierto y cerrado.
Los enrutadores LLM examinan los metadatos, el tipo y el contexto de las consultas para elegir un modelo. Los factores de selección incluyen la experiencia en el campo, la capacidad de razonamiento, la latencia y el costo. Las consultas simples se destinan a modelos ligeros, las tareas complejas a modelos de alta capacidad. Los enrutadores avanzados pueden usar incrustaciones o clasificadores predictivos para un modelo de enrutamiento inteligente y en tiempo real.
Las funciones principales de un router LLM incluyen el análisis de solicitudes, la selección inteligente de modelos, el equilibrio de carga, el manejo de alternativas y la supervisión. Los enrutadores distribuyen las consultas entre varios LLM, redireccionan las solicitudes fallidas y rastrean el rendimiento. Esto garantiza que las tareas se procesen de manera eficiente, que los modelos se utilicen de manera óptima y que el sistema siga siendo confiable y escalable en los flujos de trabajo de inteligencia artificial empresariales.
Los tipos comunes de enrutadores LLM incluyen el enrutamiento basado en reglas, el enrutamiento basado en costos, el enrutamiento basado en el rendimiento y el enrutamiento basado en tareas. Los enrutadores basados en reglas siguen condiciones predefinidas, los enrutadores basados en costos eligen modelos más económicos, los enrutadores basados en el rendimiento seleccionan los modelos con mayor precisión o velocidad y los enrutadores basados en tareas envían solicitudes a modelos especializados para tareas como la codificación, el chat o el resumen.
El enrutamiento de LLM se realiza analizando la solicitud del usuario y dirigiéndola al modelo más adecuado. Los desarrolladores definen reglas o usan algoritmos que tienen en cuenta factores como el tipo de tarea, el costo, la latencia y la capacidad del modelo. Una capa de enrutamiento evalúa la entrada y envía automáticamente la consulta al LLM correspondiente.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


