

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Todos los viernes escribo lo mismo:
«Soy Prathamesh. Ingeniero sénior de software en TrueFoundry. Trabajando en el servicio de memoria. Formato: lo que he enviado, lo que está en curso, los bloqueadores. Manténgalo conciso».
Luego solicito mi actualización semanal.
La IA lo escribe a la perfección. ¿Pero el viernes que viene? El mismo ritual. No recordará mi nombre, mi puesto, mi proyecto ni que mencioné el mismo bloqueador tres semanas seguidas.
Yo mismo creé este asistente: una interfaz de chat sencilla, AI Gateway de TrueFoundry en el backend. Gestiona los correos electrónicos, los correos electrónicos, los mensajes de Slack y los borradores de documentación. Es realmente útil. Pero cada sesión comienza desde cero. No estoy usando la memoria de la IA. YO soy la memoria de la IA.
ChatGPT resolvió esto con una memoria integrada. Pero cuando creas tu propia aplicación LLM, esa infraestructura no existe. Estás solo. A menos que lo construyas tú mismo.
Así lo hice. Mem verdadero es una capa de memoria persistente para aplicaciones de IA. Proporciona a cualquier LLM una memoria a largo plazo que funciona en todas las sesiones e incluso en diferentes modelos. No más repeticiones. La IA realmente recuerda.
Las soluciones obvias tienen problemas obvios.
La memoria integrada de ChatGPT está bloqueada dentro del ecosistema de OpenAI. No puedes acceder a ella mediante programación, usarla con otros modelos ni auditar lo que se almacena. La puerta de enlace de IA de Truefoundry nos ayuda a acceder a varios modelos y auditar lo que se almacena. Para cualquiera que cree sus propias aplicaciones, no es nada fácil.
Generación aumentada de recuperación (RAG) resuelve un problema diferente. RAG recupera información de los documentos. Responde a «¿qué dice este PDF?» La memoria del usuario es fundamentalmente diferente. Es personal, evolutivo y se basa en las relaciones. Los datos que comparto en una conversación no son documentos que se puedan indexar; son el contexto que debería dar forma a cada interacción futura.
Ampliar las ventanas de contexto es el enfoque de fuerza bruta: incluye todo el historial de conversaciones. Los modelos modernos admiten 128 000 fichas o más, así que ¿por qué no? Como los tokens son caros, más contexto implica inferencias más lentas y todo desaparece cuando finaliza la sesión. Estás pagando una prima por la amnesia con pasos adicionales.
Lo que necesitamos es una capa dedicada que almacene datos resumidos sobre los usuarios de forma permanente y recupere solo lo que es relevante para cada consulta. Esa es la brecha Mem verdadero llena.
La memoria humana no funciona almacenando cada conversación textualmente. Tenemos una memoria de trabajo para la tarea actual y una memoria a largo plazo para el conocimiento persistente. Los dos sistemas interactúan constantemente: los recuerdos a largo plazo nos informan sobre cómo interpretamos la nueva información, mientras que las nuevas experiencias importantes se consolidan en un almacenamiento a largo plazo.
Mem verdadero refleja esta arquitectura con dos componentes distintos: Memoria a corto plazo (STM) para el contexto de la conversación y Memoria a largo plazo (LTM) para obtener datos de usuario persistentes.
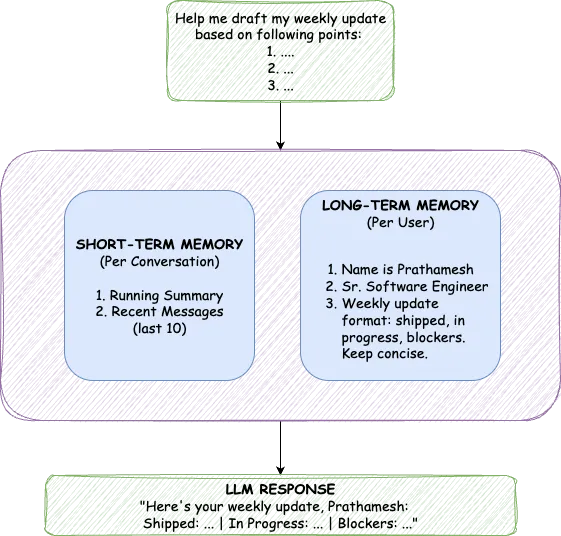
La separación es importante porque estos tipos de memoria tienen diferentes propósitos. STM captura lo que está sucediendo en este momento, el flujo total de la conversación actual. LTM almacena datos destilados que persisten en todas las conversaciones. El STM siempre se incluye en el contexto; el LTM se recupera en función de la relevancia semántica. Intentar resolver ambas cosas con un solo mecanismo obliga a llegar a un compromiso. El enfoque dual lo evita por completo.
En una sola sesión de chat, la IA necesita recordar lo que comentaste hace cinco minutos. Este es el trabajo de STM y mantiene dos componentes: un resumen continuo de los mensajes más antiguos y los últimos veinte mensajes con total fidelidad.
A medida que crece la conversación, hacemos un seguimiento continuo del recuento total de fichas. Cuando supera un umbral, una persona que trabaja en segundo plano comprime los mensajes más antiguos en el resumen que se está ejecutando mientras mantiene intactos los mensajes recientes.

El resumen es asincrónico, por lo que los usuarios nunca lo esperan. Cuando se supera el umbral, un trabajo en segundo plano obtiene los mensajes sin resumir, los combina con cualquier resumen existente y genera un resumen completo actualizado. Esos mensajes se marcan como «resumidos» y el ciclo continúa. La compresión progresiva significa que incluso las conversaciones de una hora se mantienen dentro de límites de contexto razonables.
Pero el contexto de la conversación por sí solo no es suficiente. ¿Qué pasará cuando el usuario regrese mañana? Ahí es donde entra en juego la memoria a largo plazo.
LTM almacena datos sobre los usuarios que persisten indefinidamente: su nombre, profesión, preferencias, estilo de comunicación y cualquier otra cosa que valga la pena recordar en las conversaciones. No se almacenan como texto sin procesar. Se convierten en incrustaciones vectoriales, lo que permite la semántica búsqueda de similitud.
Cuando un usuario pregunta «¿Qué lenguaje de programación debo usar?» , no comparamos las palabras clave con las memorias almacenadas. Incrustamos la consulta y encontramos recuerdos que están relacionados semánticamente. Recuerdos como «El usuario prefiere Python» y «Funciona en una infraestructura de aprendizaje automático» aparecen porque son conceptualmente relevantes, incluso sin palabras clave compartidas.
El sistema rellena el LTM a través de dos canales. Los recuerdos explícitos provienen de peticiones directas: «Recuerda que prefiero las viñetas» o «No olvides que soy alérgico a los cacahuetes». Detectamos las frases desencadenantes, extraemos el dato central y lo almacenamos con la máxima importancia. Estos recuerdos nunca se borran automáticamente.
Los recuerdos automáticos provienen del análisis de conversaciones. Cuando un usuario menciona: «He estado al frente del equipo de la plataforma de aprendizaje automático», se trata de un contexto valioso, incluso sin una solicitud de guardado explícita. Después de cada interacción, un trabajador en segundo plano examina la conversación y extrae datos que vale la pena almacenar, cada uno etiquetado con una puntuación de importancia.
Los puntajes de importancia oscilan entre uno y cinco. Un cinco significa información fundamental que nunca debe olvidarse: instrucciones explícitas para el usuario, preferencias firmes, alergias. Un cuatro representa datos personales clave, como la profesión o la ubicación. Los tres son un contexto general como pasatiempos e intereses. Los de dos en dos cubren información temporal, como los proyectos actuales. Unos son detalles menores. Los recuerdos explícitos obtienen automáticamente un cinco; las extracciones automáticas suelen puntuar entre uno y cuatro según la importancia que parezca el hecho.
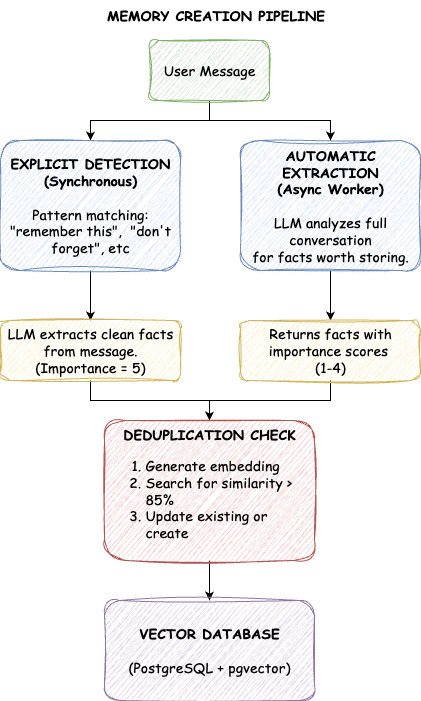
La extracción automática plantea un desafío: ¿qué pasa si un usuario dice «Me gusta Python» en una sesión y «Prefiero Python a JavaScript» en otra? El almacenamiento ingenuo crea duplicados. TrueMEM resuelve este problema con la deduplicación semántica. Antes de almacenarlas, buscamos las memorias existentes con una similitud superior al 85%. Si existe una copia casi duplicada, la actualizamos en lugar de crear una nueva entrada. La base de datos permanece limpia y cada hecho aparece exactamente una vez en su forma más completa.
La privacidad se gestiona mediante la transparencia. Los usuarios pueden ver, editar y borrar cualquier memoria almacenada. Todas las memorias están estrictamente aisladas por usuario. Para las implementaciones empresariales, todo el sistema se ejecuta en su infraestructura. Nada sale de su entorno.
¿Qué pasa con la precisión de extracción? Hay varios mecanismos que abordan este problema: la puntuación de importancia significa eliminar las extracciones automáticas antes que los recuerdos explícitos; los usuarios pueden revisar y corregir los errores; y la información correcta que se refuerza a lo largo de las conversaciones adquiere mayor importancia, mientras que las extracciones erróneas puntuales se desvanecen debido a la poda natural.
Tener recuerdos almacenados es solo la mitad del problema. Cuando un usuario envía un mensaje, necesitamos el subconjunto correcto: no todo, solo lo que es relevante. Un usuario avanzado puede tener 150 datos almacenados; incluirlos todos desbordaría la ventana de contexto.
El proceso incrusta el mensaje del usuario, realiza una búsqueda de similitud de cosenos y devuelve las diez mejores coincidencias. Esto lleva menos de 10 milisegundos con la indexación adecuada.
Una excepción: nuevos usuarios. Si alguien tiene menos de diez recuerdos, los incluimos todos independientemente de la similitud. Al principio de una relación, cada parte del contexto importa. Una vez que el recuento supera los diez, pasamos a la recuperación basada únicamente en la similitud.
Esta recuperación forma parte de un flujo de preparación del contexto más amplio y debe ser rápida.
Una capa de memoria solo es útil si no añade una latencia perceptible. Los usuarios son sensibles a los retrasos; incluso 200 milisegundos parecen lentos. Nuestro objetivo era reducir los 80 ms a la hora de preparar el contexto.
La clave es la paralelización. La preparación del contexto implica varias operaciones independientes: generar una incrustación, buscar mensajes recientes, comprobar si hay factores desencadenantes explícitos y buscar recuerdos a largo plazo. En lugar de ejecutarse de forma secuencial, las activamos en paralelo.
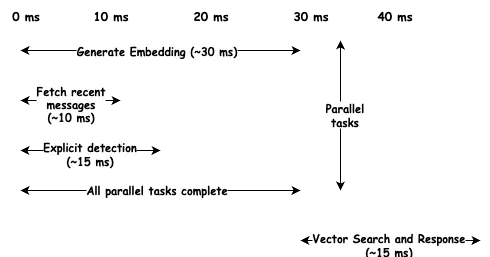
La generación de incrustaciones es más lenta, alrededor de 30 milisegundos, pero se ejecuta junto con las consultas a la base de datos que se completan en 10 ms. Pagamos por la operación más larga, no por la suma. La latencia total se sitúa en torno a los 45 ms, muy por debajo del objetivo.
Las operaciones pesadas, como el resumen y la extracción de memoria, se ejecutan de forma asincrónica después de enviar la respuesta. El usuario nunca espera; el procesamiento se realiza en segundo plano. Esta separación entre la ruta sincrónica rápida y la ruta asincrónica lenta es esencial para el uso en producción.
Como la memoria funcionaba de forma fiable, surgió una ventaja inesperada: habíamos construido accidentalmente algo independiente del modelo.
Esto es lo que no esperábamos. Una vez que la memoria quede fuera del modelo, ya no estarás limitado a un solo proveedor.
¿Cambiar de GPT-4 a Claude? Tu memoria persiste. ¿Usa diferentes modelos para diferentes tareas, como el razonamiento complejo con una y la escritura creativa con otra? Todos comparten la misma comprensión de ti. ¿Ajustar un modelo personalizado? Hereda las relaciones de usuario existentes desde el primer día.
La capa de memoria se convierte en tu constante; los modelos se vuelven intercambiables.
La integración es mínima: busca el contexto antes de la llamada de LLM y registra la interacción después. Dos llamadas a la API transforman cualquier modelo sin estado en uno con memoria persistente. Sin dependencia del SDK ni integración compleja. Solo terminales HTTP que se adaptan a cualquier arquitectura.
Por supuesto, los recuerdos no pueden crecer para siempre. Un sistema sin gestión del ciclo de vida se ahogaría en hechos obsoletos.
Cada recuerdo tiene una puntuación de importancia del uno al cinco. Las instrucciones explícitas reciben un cinco. Los datos personales clave obtienen un cuatro. El contexto general obtiene un tres. La información temporal recibe un dos. Los detalles menores obtienen un uno.
Cuando el recuento supera un límite flexible (150 por defecto), se inicia la poda. El sistema nunca toca la importancia cuatro o superior. Entre los recuerdos de menor importancia, elimina primero los que tienen la puntuación más baja, utilizando la edad como factor de desempate.
Las instrucciones de usuario explícitas sobreviven indefinidamente. Las extracciones automáticas de bajo valor se reciclan para dejar espacio para la nueva información. La memoria sigue siendo relevante sin una selección manual.
Un usuario abre un chat y escribe: «Ayúdame a redactar mi actualización semanal, basándome en los siguientes puntos...»
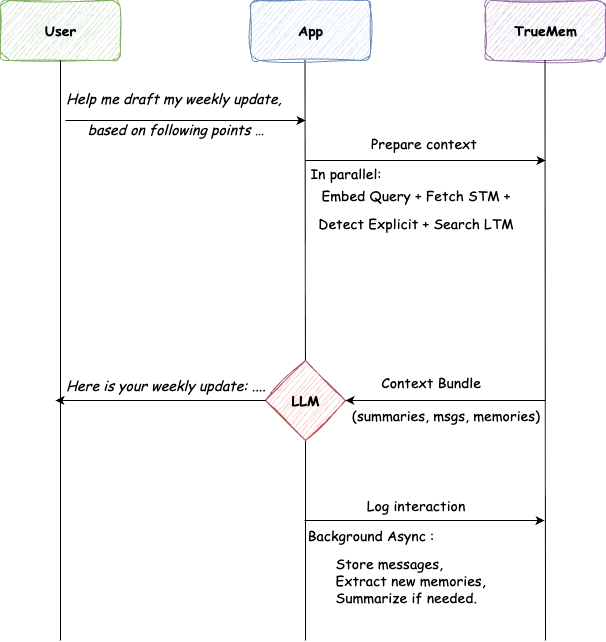
La aplicación llama a TrueMEM para obtener contexto. TrueMem ensambla el STM y el LTM correspondiente, como «Me llamo Prathamesh», «Ingeniero sénior de aprendizaje automático» y «Trabajando en un servicio de memoria». Esto lleva 45 milisegundos.
El LLM genera una respuesta personalizada: «Aquí tienes tu actualización semanal, Prathamesh...» Sin ritual. Sin reintroducción. La IA sabe quién pregunta.
Tras responder, la aplicación registra la interacción. Los trabajadores en segundo plano almacenan los mensajes, extraen cualquier dato nuevo y actualizan los resúmenes según sea necesario. El levantamiento de objetos pesados ocurre de manera invisible.
Elegimos PostgreSQL con pgvector en lugar de bases de datos vectoriales dedicadas por motivos pragmáticos. La mayoría de los equipos ya utilizan Postgres. Los recuerdos se guardan junto a los datos de los usuarios con todas las garantías de ACID. Para colecciones de 100 a 200 vectores por usuario, pgvector ofrece una búsqueda por similitud inferior a 10 ms. Para la memoria con ámbito de usuario, es la elección correcta.
Los trabajadores en segundo plano trabajan en colas respaldadas por Redis porque las llamadas de LLM tardan segundos, demasiado tiempo para bloquear las solicitudes. Los trabajadores pueden volver a intentar los errores, realizar operaciones por lotes y escalar de forma independiente sin afectar a la latencia de los usuarios.
¿Recuerdas el ritual del viernes? «Soy Prathamesh. Ingeniero de software sénior. Trabajando en el servicio de memoria».
Con TrueMEM, ocurre una vez. La IA recuerda. La actualización del próximo viernes simplemente funciona. El borrador del correo electrónico del mes que viene sabe mi firma. El contexto siempre está ahí.
Aún mejor: cambia a un modelo diferente y la memoria se conserva. El asistente diario se vuelve independiente del modelo sin necesidad de trabajar más.
Ese es el objetivo. IA que te recuerda. No porque lo recuerdes todo el tiempo, sino porque realmente lo hace.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


