.webp)
June 5, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Actualizado: September 11, 2025

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Las empresas se apresuran a poner en práctica la IA, pero el proceso desde la prueba de concepto hasta la producción a menudo se queda atrapado entre dos extremos: rendimiento bruto y disciplina operativa. Por un lado, se necesita una infraestructura que pueda gestionar las demandas de escala y latencia de las aplicaciones de IA modernas. Por otro lado, se necesitan controles de gobernanza, seguridad y costes para que sea viable en la empresa.
La nueva asociación entre Sistemas Cerebras y True Foundry cierra esta brecha. Juntos, ofrecen una plataforma en la que las organizaciones pueden ejecutar los modelos más avanzados del mundo a una velocidad sin precedentes y, al mismo tiempo, garantizar la observabilidad, la gobernanza y la flexibilidad.
Cerebras se ha hecho conocido por superar los límites del hardware y la inferencia de inteligencia artificial. Con su tecnología a escala de oblea y Inferencia cerebral servicio, las empresas obtienen:
Para las empresas, esto significa la capacidad de cumplir finalmente productos de IA de baja latencia—desde agentes conversacionales hasta resúmenes en tiempo real— sin que el hardware los obstruya.
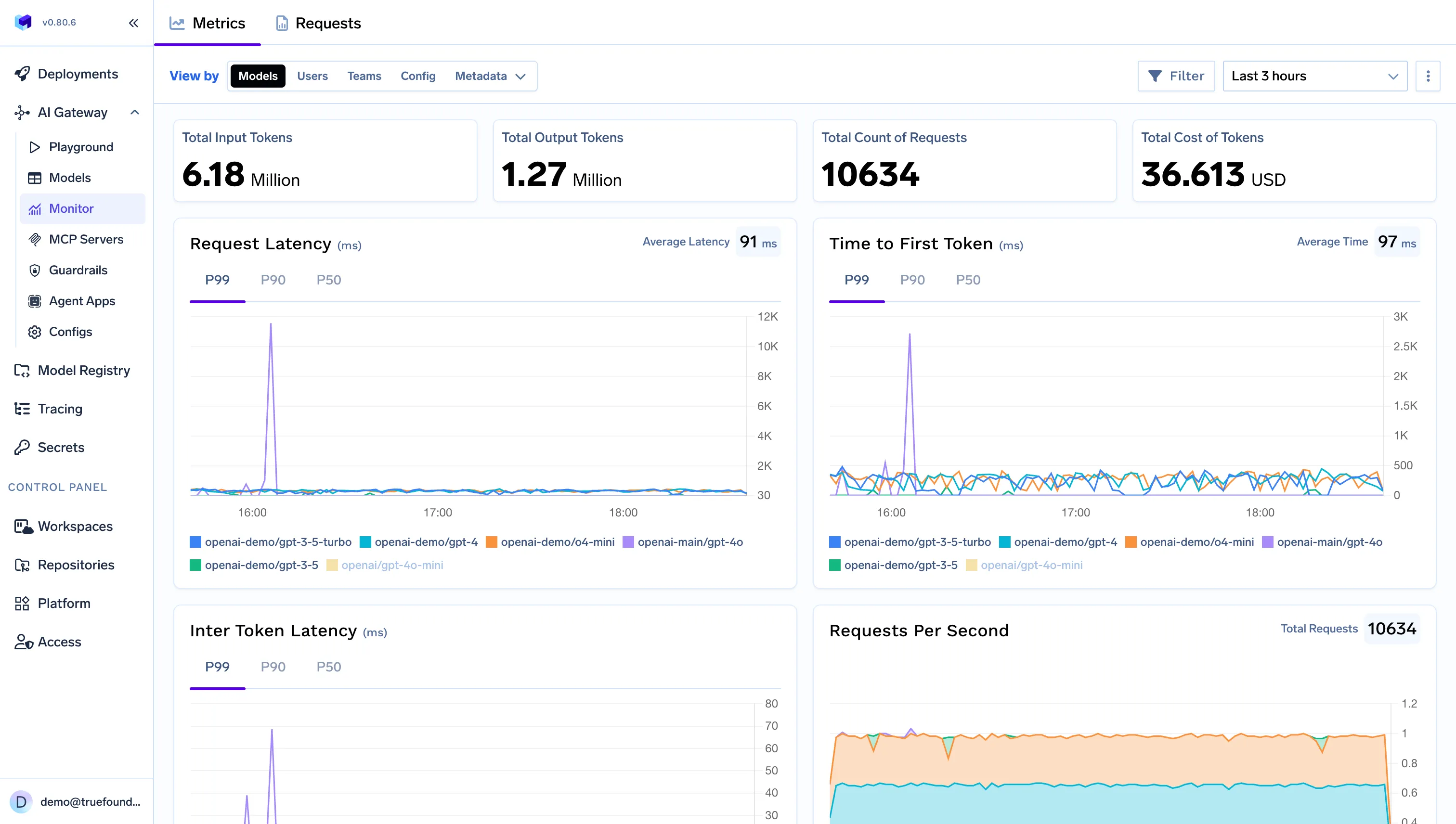
Mientras Cerebras resuelve el rendimiento problema, TrueFoundry resuelve el operacional uno. Es Puerta de enlace de IA actúa como el plano de control para el uso de la IA empresarial:
En resumen, TrueFoundry garantiza que las empresas puedan escalar el uso de la IA de forma segura, visible y predecible.
La unión de Cerebras y TrueFoundry crea un solución integral para el despliegue de IA empresarial:
Esta asociación marca un cambio en la forma en que las empresas abordan la IA. Ya no basta con realizar pruebas comparativas en laboratorios o pruebas piloto en equipos aislados. Las empresas necesitan:
Cerebras × TrueFoundry cumple con los tres.
La asociación entre Cerebras y TrueFoundry representa más que una simple integración: es un modelo para la siguiente fase de la adopción de la IA empresarial. Combinando Rendimiento de inferencia sin precedentes de Cerebras con La puerta de enlace de IA de TrueFoundry para la gobernanza y el control, las empresas pueden por fin ejecutar cargas de trabajo de IA que no solo son potentes, sino que también están listas para la producción.
Para las empresas que desean sacar la IA de los prototipos y llevarla a los flujos de trabajo de misión crítica, esta colaboración desbloquea la pieza que faltaba: una plataforma rápida, gobernada y preparada para el futuro.true
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.








Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.



.webp)
.webp)
.webp)
.webp)




.webp)
.webp)