

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Resulta tentador creer que el mayor desafío de los agentes de IA es la inteligencia. Durante mucho tiempo, eso fue cierto. A los modelos les costaba razonar, las herramientas eran frágiles y las tareas de varios pasos fracasaban con facilidad. Sin embargo, esa fase ha quedado en gran medida atrás.
Los agentes modernos ya pueden hacer mucho. Pueden razonar siguiendo varios pasos, llamar a las herramientas, invocar servidores MCP e incluso coordinarse con otros agentes. Con las instrucciones y los modelos correctos, muchos equipos pueden crear prototipos de agentes impresionantes en un tiempo sorprendentemente corto. Las demostraciones parecen convincentes. Los primeros resultados parecen mágicos.
Sin embargo, cuando estos mismos sistemas son empujados hacia un uso real, comienzan a fallar de manera silenciosa y confusa.
Esta es la brecha que define la economía emergente de agente a agente. No por falta de inteligencia, sino por falta de infraestructura.
La mayoría de las implementaciones iniciales de los agentes siguen un patrón engañosamente simple. Un usuario envía una entrada, el agente razona sobre ella, si lo desea, llama a una herramienta y devuelve una respuesta. Este flujo lineal es fácil de entender y depurar. También refleja bien la forma en que los desarrolladores están acostumbrados a pensar en las aplicaciones.
Pero este modelo oculta una suposición que no sobrevive al contacto con la realidad: que la ejecución de un agente es efímera, aislada y autónoma.
Tan pronto como los agentes comienzan a interactuar con otros agentes, esa suposición se rompe. Un agente delega el trabajo en otro. Una acción de seguimiento se activa más adelante. La invocación de una herramienta conduce a una decisión secundaria. Las rutas de ejecución se bifurcan, vuelven a unirse y, a veces, se detienen por completo.
En este punto, el sistema deja de comportarse como una función de la aplicación y comienza a comportarse como un sistema distribuido compuesto por componentes autónomos.
Esta transición es sutil, pero crítica. Con frecuencia, los equipos no se dan cuenta de lo que ha sucedido hasta que las cosas empiezan a ir mal.
Cuando los sistemas de agentes tienen dificultades en la producción, las fallas rara vez son dramáticas. El sistema no se bloquea de forma inmediata. En cambio, la confianza se erosiona lentamente.
Se desencadena una acción, pero nadie sabe con certeza por qué.
Se ejecuta un agente descendente, pero con permisos poco claros.
Los costos suben sin una causa obvia.
Un flujo de trabajo se detiene a mitad de camino y no hay ningún rastro claro que explique dónde o por qué.
No se trata de errores de razonamiento. El agente puede haber tomado una decisión perfectamente razonable dada la información que tenía. El problema es que nadie puede explicar o gobernar de manera confiable lo que ocurrió en todo el sistema.
Este es el punto en el que muchos equipos intentan instintivamente «arreglar» al propio agente, ajustando las instrucciones, intercambiando modelos o añadiendo más lógica. Sin embargo, esos cambios rara vez abordan la causa principal, porque el problema no reside en el agente.
Vive entre agentes.
Si la inteligencia fuera el verdadero obstáculo, esperaríamos un patrón simple: mejores modelos conducirían a sistemas de producción estables. Eso no es lo que vemos.
Lo que vemos, en cambio, es que a medida que los agentes se vuelven más capaces, los sistemas que los rodean se vuelven más difíciles de administrar. Una mayor inteligencia conduce a una mayor autonomía, a un comportamiento más ramificado y a más efectos secundarios. Sin la infraestructura adecuada, esta capacidad adicional en realidad aumenta el riesgo.
La economía de agente a agente amplifica este efecto. A medida que los agentes comienzan a llamar a otros agentes y a operar en herramientas y entornos compartidos, el costo de la infraestructura faltante aumenta rápidamente. La identidad, la coordinación, la aplicación de políticas y la observabilidad dejan de ser preocupaciones opcionales para convertirse en requisitos fundamentales.
Aquí es donde se hace necesario un cambio de mentalidad. Los agentes no pueden tratarse como una pieza más de la lógica de la aplicación. En un ecosistema de agentes real, los agentes son actores de larga data que participan en los flujos de trabajo, delegan el trabajo y operan bajo diferentes autoridades.
Plataformas como Centro de agentes de TrueFoundry reflejan este cambio. En lugar de asumir que los agentes son privados y tienen una lógica integrada, Agent Hub los trata como componentes registrados y detectables con interfaces y propiedad explícitas. Los agentes se publican, versionan e invocan a través de una superficie de control compartida, en lugar de que se llamen entre sí directamente a través de rutas de código ad hoc.
Este replanteamiento no hace que los agentes sean más inteligentes. Hace que el sistema que los rodea funcione.
La economía de agente a agente no espera un gran avance en el razonamiento. Está esperando una infraestructura que pueda respaldar la autonomía sin perder el control.
El primer paso es comprender cómo cambian los sistemas de agentes una vez que llegan a la fase de producción y por qué fallan los enfoques tradicionales. A partir de ahí, el papel de los planos de control, las pasarelas y las API de ejecución explícita se vuelve inevitable. Ahí es donde comienza el verdadero trabajo.
Cuando un sistema de agentes llega a la fase de producción, la mayoría de los equipos ya han resuelto los problemas obvios.
Saben cómo enviar solicitudes a un LLM.
Saben cómo conectar herramientas o servidores MCP.
Saben cómo contratar a un agente y obtener una respuesta.
Estas capacidades ya no son experimentales. Son estables, están bien documentadas y son fáciles de reproducir. De hecho, esta es precisamente la razón por la que los equipos ganan confianza tan rápido. El éxito inicial crea la impresión de que el sistema está «casi terminado».
La producción es donde se rompe esa ilusión.
Lo que realmente hace la producción es exponer todo lo que los prototipos ocultan convenientemente.
En una demostración, un agente normalmente se ejecuta de forma aislada. Gestiona una sola solicitud, realiza un número reducido de acciones y se cierra. Hay una ruta de ejecución y un resultado. La depuración es sencilla porque todo el contexto cabe en la cabeza del desarrollador.
En producción, los agentes no se comportan de esta manera.
Funcionan de forma continua.
Desencadenan acciones de seguimiento.
Llaman a otros agentes.
Operan en todos los entornos, equipos y permisos.
La ejecución deja de ser una interacción única y se convierte en flujo de trabajo, a menudo uno que se desarrolla con el tiempo.
Aquí es donde los sistemas de agentes comienzan a parecerse a los sistemas distribuidos, no porque usen microservicios o colas, sino porque el comportamiento ahora se distribuye entre varios actores autónomos.
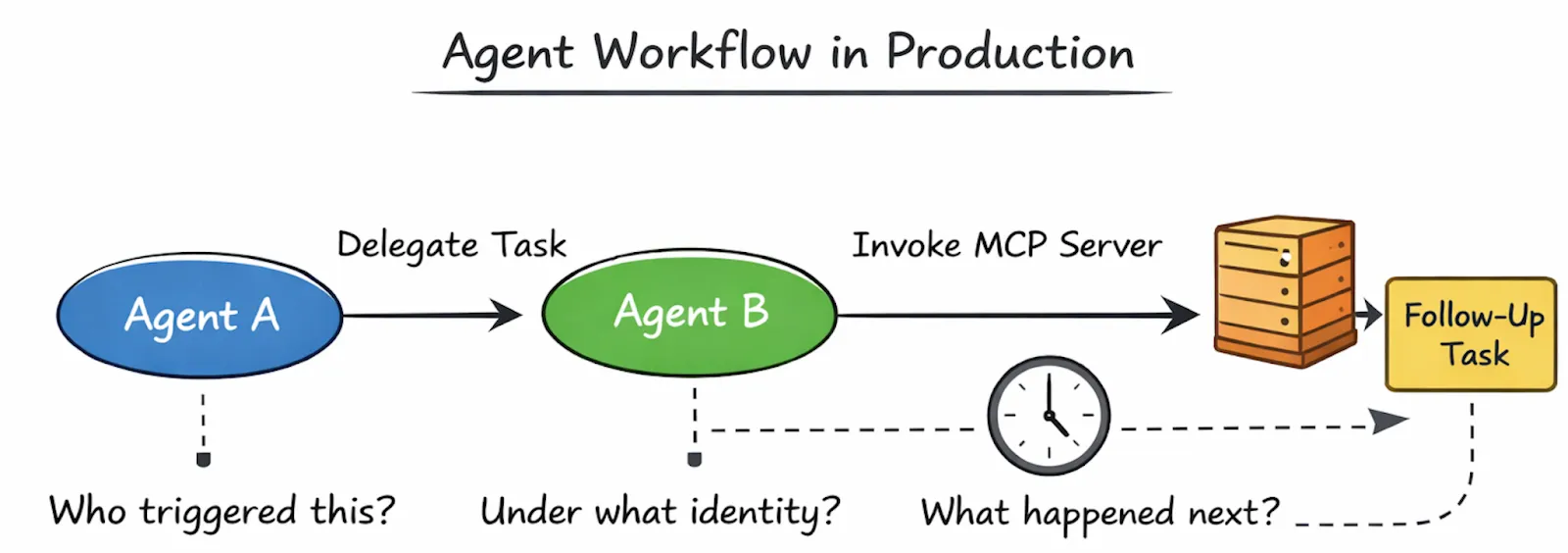
Cuando algo va mal en la producción, los equipos no se preguntan si el agente fue «lo suficientemente inteligente». En su lugar, formulan preguntas que resultan muy familiares para cualquiera que haya operado sistemas distribuidos:
¿Qué desencadenó esta acción?
¿Qué agente tomó la decisión?
¿Bajo qué identidad corría?
¿Por qué está aquí la rama de ejecución?
¿Por qué se detuvo por completo?
Estas preguntas son engañosamente simples y es imposible responderlas de manera confiable sin el soporte de infraestructura.
En la mayoría de las primeras configuraciones de agentes, el contexto de ejecución reside en el propio agente. Una vez que un agente llama a otro agente o invoca una herramienta, ese contexto suele desaparecer a menos que todos los desarrolladores lo propaguen con cuidado. Con el tiempo, los registros se fragmentan, el rastreo se interrumpe y el sistema se vuelve opaco.
Es posible que el agente siga produciendo resultados, pero resulta difícil razonar sobre el sistema en su conjunto.
La reacción natural en esta etapa es solucionar el problema localmente. Un equipo añade el registro de llamadas a herramientas. Otro vincula a los agentes con comprobaciones de autenticación. Alguien añade reintentos en algunos lugares. Ninguno de estos cambios es incorrecto por sí solo.
Pero en conjunto, crean una frágil red de códigos adhesivos en la que:
Este es el punto en el que los equipos comienzan a sentirse ralentizados, no porque los agentes no puedan hacer más, sino porque cambiar algo tiene consecuencias imprevistas.
Lo que está surgiendo aquí, ya sea que los equipos se den cuenta o no, es un plano de control. Resulta que es accidental y está mal definido.
Aquí es donde plataformas como True Foundry trazar una línea clara entre la lógica del agente y la responsabilidad del sistema.
Con el Centro de agentes, los agentes ya no se invocan de forma implícita mediante llamadas a funciones locales o dependencias ocultas. Se registran, se pueden detectar y se ejecutan a través de una interfaz compartida. Con el API de agente, la ejecución del agente pasa a ser explícita, contextual y observable.
En lugar de que un agente llame discretamente a otro agente, la ejecución se presenta como una operación gestionada.
# Using TrueFoundry's Agent API with registered MCP servers
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Evaluate risk for transaction txn_123"}],
"mcp_servers": [{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}, {"name": "sequential_thinking"}]}],
"stream": True
}
)# Connecting to MCP server through TrueFoundry Gateway
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
async def main():
url = "https://{controlPlaneURL}/api/llm/mcp/common-tools/server"
transport = StreamableHttpTransport(
url=url,
auth="<tfy-api-token>",
)
async with Client(transport=transport) as client:
tools = await client.list_tools()
result = await client.call_tool("web_search", {"query": "What is Python?"})
return result
Nota: El contrato de la API de Agent Hub se encuentra actualmente en desarrollo activo. Para obtener información sobre la sintaxis y las capacidades más recientes, consulte Documentación de la API del agente.
Esto puede parecer un cambio pequeño, pero tiene consecuencias importantes. La identidad viaja con la solicitud. Los límites de ejecución son claros. Las acciones posteriores se pueden rastrear hasta su origen. Las políticas se pueden evaluar antes de que se ejecute el agente, no después de que algo vaya mal.
El agente sigue razonando y decide qué hacer. La plataforma gestiona la forma en que esa decisión se ejecuta de forma segura.
Una vez que los agentes llegan a la producción, los problemas difíciles ya no tienen que ver con la inteligencia. Tienen que ver con la coordinación, la identidad, la visibilidad y el control. Estas preocupaciones no pertenecen al código de los agentes, porque se aplican a todos los agentes, flujos de trabajo y equipos.
Esta es la razón por la que muchos equipos optan por un atajo: poner un router delante de sus agentes con la esperanza de que sea suficiente.
Rara vez lo es.
Entender por qué falla ese enfoque es el siguiente paso para entender cómo debe ser la verdadera infraestructura de agentes.
Una vez que los equipos se dan cuenta de que su sistema de agentes es cada vez más difícil de administrar, el primer instinto suele ser pragmático: añadir un router delante de los agentes.
Este enfoque me resulta familiar. Las puertas de enlace y los enrutadores de API se conocen bien. Han funcionado para los microservicios, así que ¿por qué no reutilizar el mismo patrón para los agentes? Pon primero una capa de enrutamiento, decide a qué agente llamar y continúa.
Por un corto tiempo, esto funciona. Luego, el sistema comienza a torcerse de maneras para las que el router nunca fue diseñado.
Los routers están diseñados para un mundo muy específico. Suponen que las solicitudes duran poco, que las rutas de ejecución son en su mayoría lineales y que la identidad es uniforme o se resuelve una vez en el borde. Reenvían el tráfico de manera eficiente, pero no entienden la intención.
Los sistemas de agente a agente infringen estas suposiciones casi de inmediato.
Los agentes no solo responden a las solicitudes. Inician acciones, delegan el trabajo a otros agentes y provocan efectos secundarios que se desarrollan con el tiempo. Una sola decisión puede desembocar en múltiples ejecuciones posteriores, algunas inmediatas y otras retrasadas. La identidad ya no es un encabezado único; es algo que hay que preservar y razonar sobre ello en todos los saltos.
Un router puede reenviar una solicitud. No puede explicarlo por qué esa solicitud existe.
A medida que crecen los sistemas de agentes, los equipos comienzan a asignar más responsabilidades al router. Se añaden reglas de autenticación. La selección del modelo se codifica en rutas. Las comprobaciones de políticas están codificadas de forma rígida en la lógica de enrutamiento. El contexto se combina mediante encabezados y convenciones.
Nada de esto se siente mal de forma aislada. Sin embargo, con el tiempo, el router se convierte en un vertedero de problemas que no estaba destinado a resolver. Se convierte en un punto de estrangulamiento quebradizo en el que:
Irónicamente, el router que pretendía simplificar el sistema se convierte en lo que ralentiza a todos.
El problema más profundo es que los sistemas de agentes no solo necesitan administrar el tráfico. Necesitan gobernabilidad.
Los equipos de seguridad y cumplimiento no preguntan qué ruta fue atacada. Preguntan quién accedió a qué, con qué autoridad y por qué. Los equipos de producto no solo quieren saber a dónde se envió una solicitud, sino que también quieren entender cómo se propagó una decisión entre los agentes y las herramientas. Los operadores necesitan ver cómo evolucionan los costos y el comportamiento a lo largo de todo el flujo de trabajo, no solo en la periferia.
Estas preguntas no se pueden responder únicamente con el enrutamiento, ya que dependen de la intención, la delegación y las acciones derivadas. Esos conceptos no se encuentran de forma natural en un router.
Aquí es donde se hace evidente la distinción entre un router y un plano de control.
Con Centro de agentes de TrueFoundry, los agentes no son puntos finales anónimos detrás de una tabla de enrutamiento. Son entidades nombradas y registradas con interfaces y propiedad explícitas. Cuando un agente invoca a otro, lo hace a través de una capa de ejecución gestionada en lugar de mediante un salto de red opaco.
El API de agente refuerza esta separación. La ejecución no se oculta detrás de una ruta; es una operación explícita con la identidad, los metadatos y la evaluación de políticas integradas. La pasarela aplica las reglas de forma coherente y, al mismo tiempo, preserva el contexto en las interacciones entre agentes.
Esto no elimina la flexibilidad. La restaura. Al mantener el enrutamiento centrado en el tráfico y trasladar la gobernanza a una infraestructura dedicada, los equipos pueden evolucionar el comportamiento de los agentes sin convertir su capa de enrutamiento en un frágil monolito.
«Solo un router» falla no porque esté mal implementado, sino porque resuelve un problema incorrecto. Los sistemas de agente a agente no son enrutadores de solicitudes con terminales más inteligentes. Son sistemas distribuidos con un comportamiento autónomo.
Una vez que los equipos lo aceptan, la siguiente conclusión es natural: los sistemas de agentes se comportan como sistemas distribuidos, pero con riesgos más altos.
Cuando los equipos se dan cuenta de que un router no es suficiente, por lo general comienza a surgir otro patrón por sí solo. Empiezan a aparecer pequeños fragmentos de lógica de coordinación por todas partes. Un agente comprueba los permisos antes de llamar a una herramienta. Otro incorpora la lógica de reintento al invocar a un agente intermedio. Un tercer equipo agrega un registro personalizado para rastrear lo que ocurrió después de que se activara una acción.
Ninguno de estos cambios es incorrecto. De hecho, son respuestas prácticas a problemas reales. Pero en conjunto, apuntan a algo más profundo: al sistema le falta un plano de control.
Un plano de control no consiste en hacer el trabajo. Se trata de decidir cómo se permite que el trabajo se lleve a cabo.
En un sistema de agente a agente, hay preguntas que simplemente no pertenecen a la lógica de los agentes:
¿Quién puede invocar a este agente?
¿En qué condiciones?
¿Qué herramientas o servidores MCP utilizan?
¿Con qué nivel de visibilidad y auditabilidad?
Cuando estas decisiones se incorporan directamente a los agentes, se duplican y varían con el tiempo. Dos agentes que deberían comportarse de la misma manera divergen lentamente. Las políticas se aplican de manera incoherente. La depuración se convierte en una conjetura porque ningún lugar refleja la forma en que realmente se gobierna el sistema.
Este es exactamente el problema Centro de agentes de TrueFoundry está diseñado para resolver.
Agent Hub trata a los agentes no como detalles de implementación privados, sino como entidades registradas y detectables dentro de un sistema compartido. Proporciona capacidades que incluyen:
Cada agente se publica con una interfaz, propiedad y límites de ejecución claros. Otros agentes no «acceden» a él a través de rutas de código ad hoc. Lo invocan de forma explícita.
Esto cambia la naturaleza de las interacciones entre agentes. En lugar de dependencias ocultas, las relaciones se hacen visibles. En lugar de una confianza implícita, la ejecución fluye a través de una capa gestionada.
Una forma útil de visualizar esto es colocar Agent Hub en el centro del sistema:
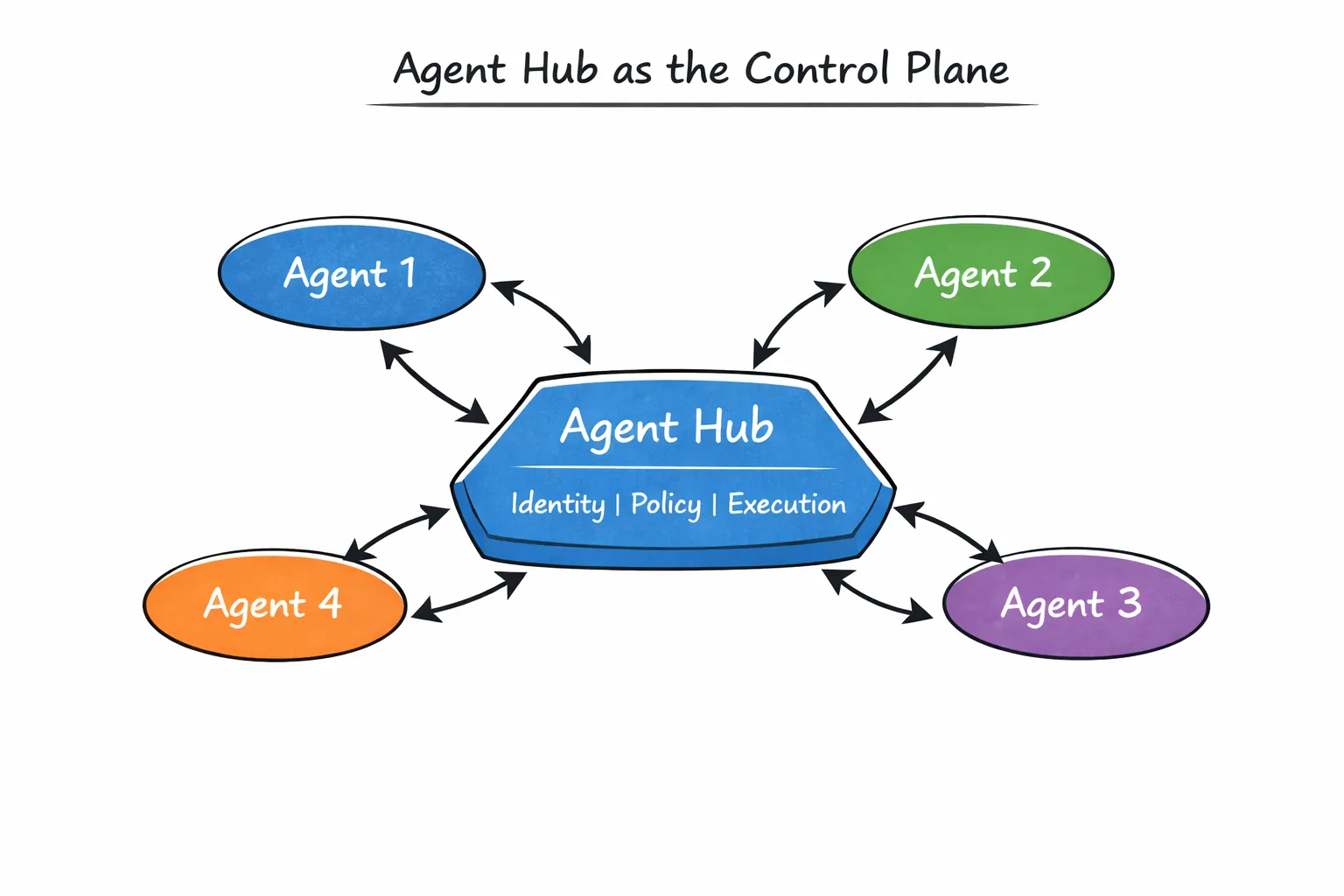
A medida que los sistemas crecen, los flujos de trabajo rara vez son sencillos. Un agente puede especializarse en la recuperación, otro en la evaluación y otro en la toma de decisiones. Estos agentes no se reemplazan entre sí, sino que colaboran.
Agent Hub admite esto de forma explícita a través de flujos de trabajo de subagentes y múltiples agentes. En lugar de programar la lógica de orquestación dentro de un único «megaagente», los equipos pueden crear flujos de trabajo encadenando a los agentes de forma controlada.
Esto tiene dos efectos importantes. En primer lugar, mantiene a los agentes individuales concentrados y comprensibles. En segundo lugar, centraliza la lógica de coordinación para que los cambios en la forma en que los agentes interactúan no requieran reescribir a todos los agentes involucrados.
El sistema se vuelve más fácil de desarrollar, no más difícil.
Otro beneficio silencioso de un plano de control centralizado es la visibilidad. En muchas organizaciones, los agentes proliferan más rápido que la gobernanza. Los equipos crean lo que necesitan, copian las credenciales e implementan agentes siempre que pueden. Con el tiempo, nadie sabe con certeza cuántos agentes existen, a qué datos acceden o quién es su propietario.
Agent Hub proporciona una superficie compartida donde los agentes se registran y descubren. Esto no ralentiza a los equipos, sino que les proporciona una configuración predeterminada segura. Cuando el camino oficial es fácil y visible, hay muchos menos incentivos para crear agentes en la sombra.
Es importante tener claro lo que no es un plano de control. No es un lugar en el que impere toda la lógica, ni tampoco es un obstáculo que los equipos deban negociar para cada cambio. Agent Hub no les dice a los agentes qué pensar. Define cómo los agentes participan en el sistema.
Los agentes siguen razonando de forma independiente. Los equipos siguen enviando rápidamente. Sin embargo, las reglas de participación, identidad, invocación y coordinación se manejan de manera uniforme en todo el ecosistema.
Esta separación es lo que hace que los sistemas de agentes sean sostenibles a medida que crecen.
Una vez que existe un plano de control, la pieza final del rompecabezas se vuelve obvia: la ejecución debe aplicarse y observarse en tiempo de ejecución. Ahí es donde entran en juego las pasarelas y las API de agentes explícitas, y eso es lo que veremos a continuación.
Una vez que existe un plano de control, una pregunta se hace inevitable: ¿dónde se aplica realmente ese control?
En los sistemas de agentes, las decisiones sobre la identidad, las políticas y el enrutamiento no importan a menos que se apliquen en tiempo de ejecución, justo en el momento en que un agente intenta actuar. Aquí es donde las pasarelas y las API de agente explícitas se vuelven fundamentales. Sin ellas, un plano de control es solo consultivo. Con ellos, se hace realidad.
Uno de los modos de fallo más comunes en los sistemas de agentes es la ejecución invisible. Un agente llama a otro agente como función local. Ese agente invoca una herramienta. Se produce un efecto secundario. Todo «funciona», pero nadie puede ver claramente qué pasó ni por qué.
El problema no es que la ejecución esté mal. El problema es que está oculto.
True Foundry API de agente obliga a que la ejecución del agente sea explícita. En lugar de llamadas implícitas ocultas en código, las interacciones entre los agentes se convierten en operaciones de primera clase. Cada invocación lleva consigo la identidad, el contexto y la intención, y siempre fluye por la misma infraestructura.
# TrueFoundry Agent API - explicit, governed agent execution
import httpx
response = httpx.post(
"https://{controlPlaneURL}/api/llm/agent/chat/completions",
headers={
"Authorization": "Bearer {TFY_API_TOKEN}",
"Content-Type": "application/json"
},
json={
"model": "openai/gpt-4o",
"messages": [{"role": "user", "content": "Search for information about Python"}],
"mcp_servers": [
{"integration_fqn": "common-tools", "tools": [{"name": "web_search"}]}
]
}
)Nota: El contrato de la API de Agent Hub se encuentra actualmente en desarrollo activo. Para obtener información sobre la sintaxis y las capacidades más recientes, consulte Documentación de la API del agente.
Esta convocatoria puede parecer simple, pero representa un cambio arquitectónico importante. El agente ya no actúa de forma aislada. Su ejecución está mediada, rastreada y gobernada.
En los sistemas tradicionales, las puertas de enlace suelen tratarse como enrutadores de tráfico. En los sistemas de agentes, ese marco es demasiado estrecho. Las pasarelas no solo reenvían solicitudes, sino hacer cumplir la intención.
La puerta de enlace de IA de TrueFoundry se encuentra entre los agentes, los modelos y los servidores MCP. Todas las ejecuciones de los agentes pasan por él. Esto permite al sistema evaluar las políticas antes de que ocurra nada: si un agente puede ejecutarse, a qué herramientas puede acceder, qué modelo debe usar y qué debe registrarse o restringirse.
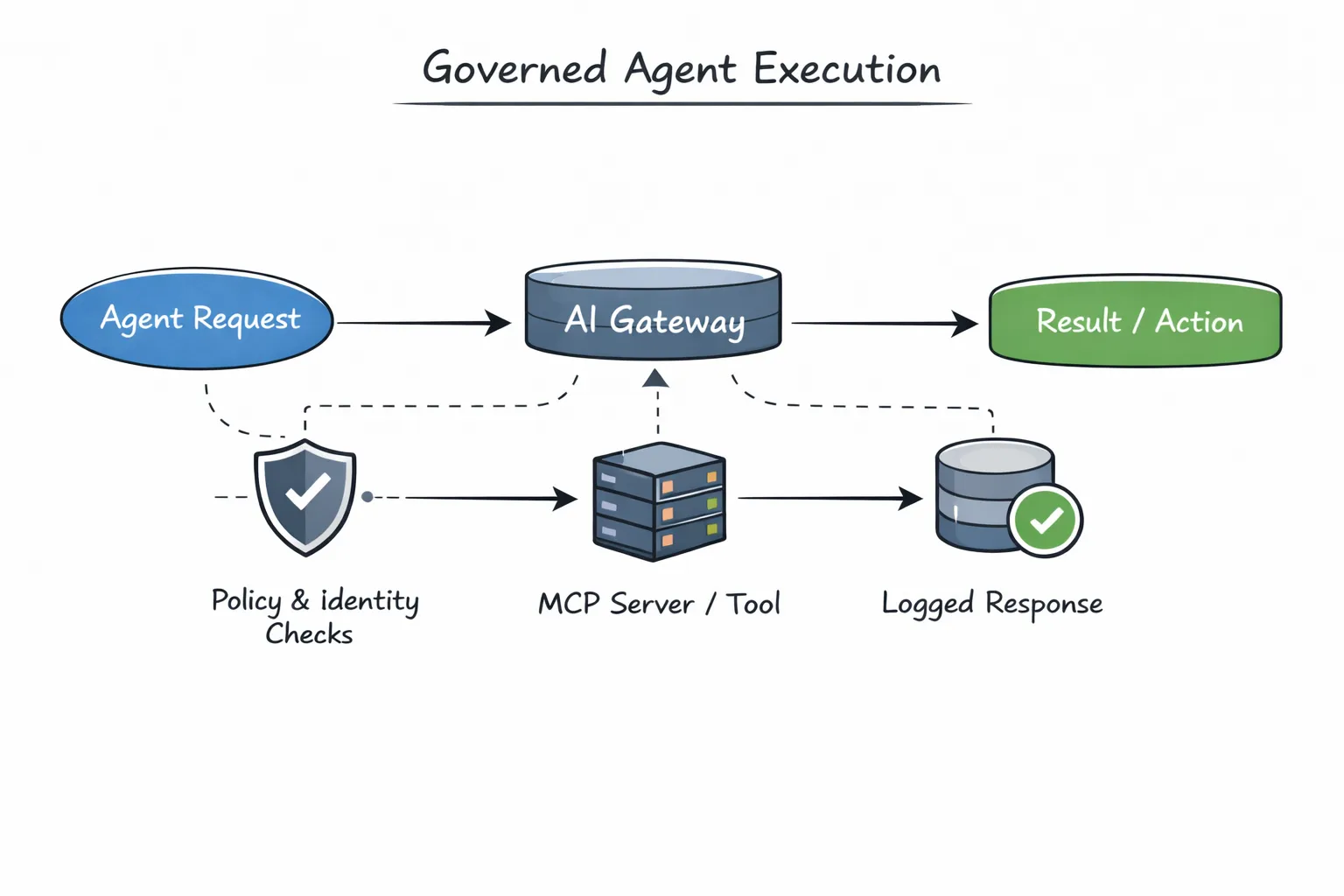
Como toda la ejecución fluye a través de una puerta de enlace compartida, la aplicación pasa a ser coherente de forma predeterminada. No es necesario que todos los agentes vuelvan a implementar las comprobaciones de acceso, los reintentos o el registro. Esas preocupaciones viven donde pertenecen, fuera de la lógica de los agentes.
El acceso a las herramientas es donde los sistemas de agentes suelen volverse peligrosos. Las herramientas pueden escribir datos, activar sistemas externos o realizar acciones irreversibles. Cuando los agentes recurren directamente a las herramientas, las credenciales y la lógica de acceso tienden a copiarse, lo que genera riesgos de seguridad y cumplimiento.
La API del agente integra los servidores MCP a través de la puerta de enlace, lo que significa que las herramientas se invocan en condiciones controladas. Ya sea que un servidor MCP esté registrado en la plataforma o se proporcione externamente, el acceso es mediado, autenticado y observable. Los agentes obtienen las capacidades que necesitan sin guardar secretos ni eludir las políticas.
Esto es especialmente importante en los flujos de trabajo de agente a agente, donde la decisión de un agente puede derivar en múltiples invocaciones de herramientas posteriores.
Otro beneficio de la ejecución explícita es la visibilidad. Como las invocaciones de los agentes fluyen a través de una API y una puerta de enlace compartidas, es posible rastrear el comportamiento de principio a fin. Los equipos pueden ver qué agente inició una acción, qué agentes y herramientas posteriores estuvieron involucrados, cuánto tiempo llevó la ejecución y dónde se acumularon los costos.
En los sistemas de agentes, el costo no es solo un problema de facturación, es una señal de comportamiento. Un pequeño cambio en el razonamiento puede desembocar en muchas llamadas. Sin la observabilidad, los equipos pierden la capacidad de comprender o controlar esa amplificación.
La ejecución explícita restaura esa comprensión.
El objetivo de las API y puertas de enlace de los agentes no es limitar lo que pueden hacer los agentes. Se trata de crear un comportamiento autónomo operable.
Los agentes siguen razonando de forma independiente. Siguen colaborando y delegando. Pero lo hacen dentro de un sistema que puede hacer cumplir las reglas, explicar los resultados y evolucionar de forma segura con el tiempo.
En este punto, el patrón central queda claro. Los sistemas de agente a agente no se basan únicamente en la inteligencia. Se escalan cuando la autonomía se combina con la infraestructura que puede gobernarla.
Esto nos lleva a la pregunta final: ¿qué es lo que realmente determina el éxito en una economía de agente a agente a largo plazo?
A medida que las capacidades de los agentes sigan mejorando, la inteligencia se convertirá en la parte menos interesante del sistema. Será más fácil acceder a modelos mejores. Las técnicas de incitación se difundirán rápidamente. Lo que parece avanzado hoy se convertirá en la línea de base mañana.
El verdadero diferenciador no será lo inteligentes que sean los agentes individuales. Será si los sistemas que los rodean pueden apoyar la autonomía sin perder el control.
Las economías de agente a agente introducen una nueva clase de complejidad. Las decisiones se propagan entre los agentes. Las acciones desencadenan efectos posteriores. Los costos y los riesgos se amplifican más rápido de lo que los humanos pueden intervenir. Sin infraestructura, estos sistemas se vuelven opacos, frágiles y difíciles de confiar.
Lo que hace que los sistemas de agentes sean sostenibles no es más lógica dentro de los agentes, sino clara separación de preocupaciones:
Aquí es donde importan las plataformas.
El Agent Hub y la API Agent de TrueFoundry no intentan hacer que los agentes sean más inteligentes. Proporcionan la capa de infraestructura que falta y permite que los sistemas de agentes se comporten como sistemas distribuidos bien gobernados en lugar de como colecciones impredecibles de scripts. Los agentes pasan a ser detectables, componibles y operables. La autonomía se convierte en algo en lo que los equipos pueden confiar.
La economía de agente a agente no se ganará con soluciones puntuales o demostraciones inteligentes. Se basará en plataformas que hagan que la autonomía sea fiable a escala. La inteligencia se convertirá en mercancía. La infraestructura se diferenciará.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


