

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En muchos casos, los equipos desarrollan indicaciones en un manera relajada, similar a escribir correos electrónicos informales. Este es un proceso natural y no se le presta mucha atención elementos estructurales. Este enfoque relajado es apropiado para desarrollo exploratorio o incluso desarrollar rápidamente un prototipo.
Pero cuando se empieza a utilizar una función que se basa en un modelo de lenguaje grande delante de los usuarios reales, las instrucciones se convierten en aspecto crítico. Si las instrucciones no están bien diseñadas, es posible que no funcionen y que las respuestas no sean coherentes, que no se incluya información importante y que las respuestas no sean confiables.
Además de esto, la depuración es inesperadamente compleja cuando se produce un problema. Con frecuencia es necesario averiguar si el problema está relacionado con la modelo, la entrada o incluso el mensaje.
Esta publicación repasará el proceso exacto que creamos para pasar las indicaciones de «probablemente lo suficientemente buenas» a «definitivamente lo suficientemente buenas para la producción» con criterios reales, conjuntos de datos de evaluación reales y puntos de referencia reales en varios modelos. No es magia. Solo ingeniería estructurada aplicada a las indicaciones.
Cuando la mayoría de las personas piensan en un mensaje, piensan en una solicitud simple, como «Resuma este documento» o «Extraiga entidades de este texto». Pero en el mundo real, un mensaje es mucho más que eso. Es la interfaz fundamental entre el programa y el comportamiento del modelo. Un buen aviso creará la personalidad de la modelo, las reglas de contratación, el formato de salida y lo inesperado.
El problema con las indicaciones es que no se prueban minuciosamente. Se diseñan, implementan y luego simplemente se comprueban para ver si funcionan. Haces un cambio aquí y añades una regla allá. Entonces solo esperas que funcione bien. A veces sí que funciona. Por lo general, no lo hace. Cuando falla, simplemente no lo hace. Puede que ni siquiera te des cuenta.
Un buen mensaje no solo es claro, sino que está estructurado. Piense en ello como un contrato de API entre usted y el modelo. Debe definir:
Cuando todo esto está en su lugar, el modelo tiene todo lo que necesita para ser coherente, confiable y predecible en todas las entradas e incluso en las diferentes versiones del modelo.

Esto es lo que hemos visto suceder con las indicaciones deficientes en las implementaciones del mundo real:
Salidas que se ven bien pero no lo son : El modelo produce una respuesta que parece estar en el formato correcto, pero tiene errores sutiles porque la especificación no estaba clara.
Fallos entre modelos : El mensaje funciona para GPT-4, pero tiene respuestas inconsistentes para los modelos Claude y OSS. Nadie lo probó en todos los modelos antes de su implementación.
Regresiones silenciosas : Cambiar una palabra para solucionar un problema provoca otros tres problemas que nadie nota hasta que alguien se queja.
El problema es siempre el mismo: nadie trató el mensaje como algo que necesita ser probado y validado. Creamos este proceso para solucionarlo.
El flujo de trabajo consta de cinco pasos. Cada uno se basa en el anterior. Omita uno y los resultados se vuelven poco confiables rápidamente. Así es como funciona de principio a fin.
Por lo tanto, antes de hacer cualquier cambio, queremos saber qué está roto. Usamos un motor de evaluación estructurado que se ejecuta en cada mensaje y lo puntúa en cinco dimensiones diferentes y proporciona un puntaje de calidad general que oscila entre 0 y 100.
No utilizamos la puntuación subjetiva. Tenemos criterios claros para todas las dimensiones. Tenemos restricciones muy estrictas. Por ejemplo, si no hay ninguna especificación de salida en la solicitud, hay una puntuación máxima de especificación de salida. La puntuación puede ser alta incluso si las instrucciones del mensaje están bien escritas. Si la puntuación es inferior a 75, no está lista para la producción. Si está por encima de 90, entonces es sólido en todas las dimensiones.
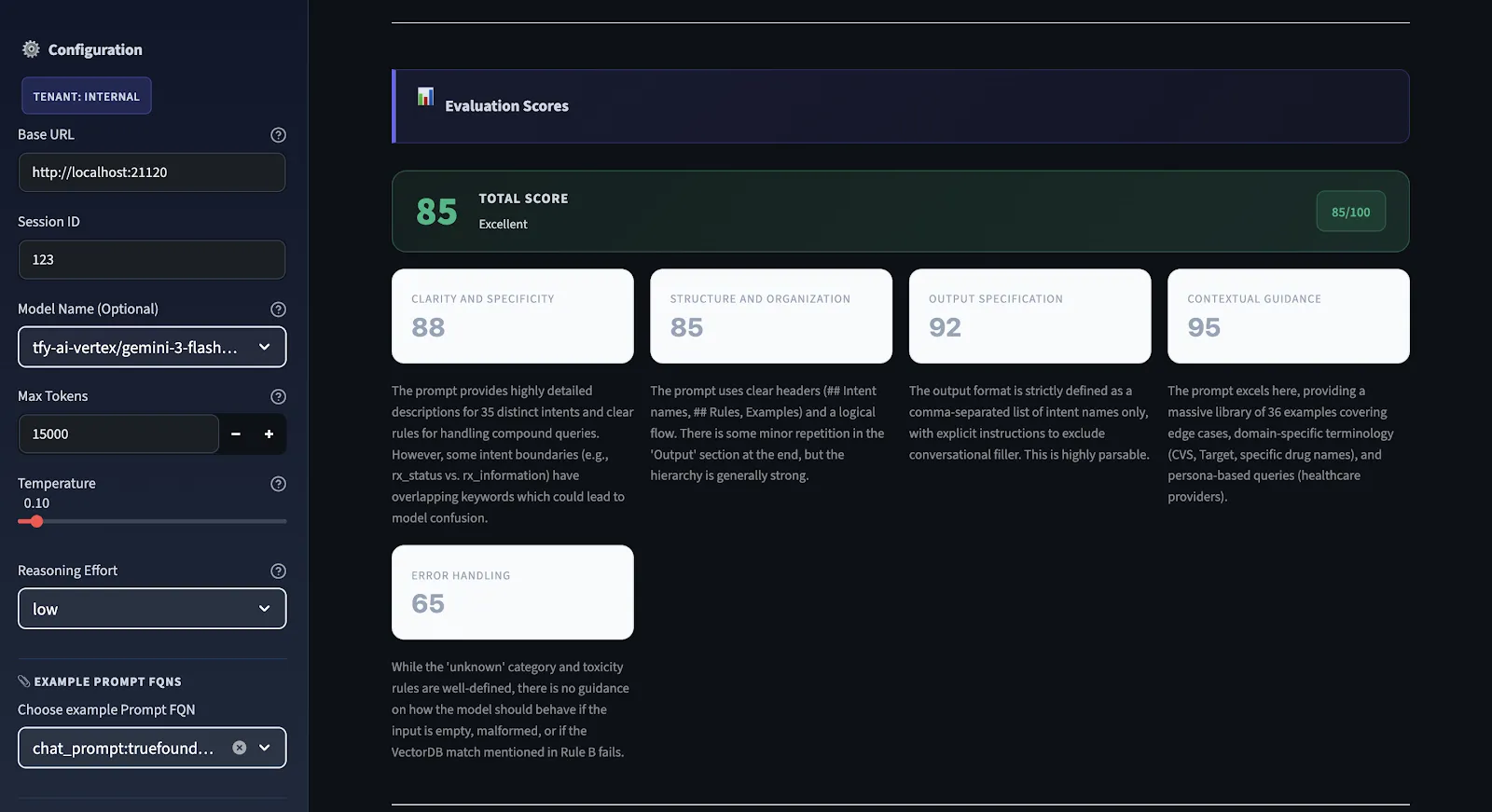
Este es el motor de diagnóstico del flujo de trabajo. Cada mensaje recibe una puntuación de 0 a 100 según cinco criterios específicos. La puntuación global es la media aritmética de los cinco. Esto es lo que mide cada uno y por qué es importante:
¿Las instrucciones son lo suficientemente claras como para que dos modelos diferentes las entiendan exactamente de la misma manera? Las instrucciones vagas causan más inconsistencias que cualquier otro factor. Si no estás seguro de cómo un humano interpretaría tu mensaje, es probable que no estés seguro de cómo lo interpretará un modelo. Si hay más de una forma en que un humano puede interpretarla, hay más de una forma en que un modelo puede interpretarla correcta o incorrectamente.
¿El mensaje fluye lógicamente desde el contexto → instrucciones → restricciones → formato de salida? Un mensaje desorganizado obliga al modelo a averiguar qué es lo que importa y en qué orden. Una buena estructura facilita el trabajo del modelo y hace que sus resultados sean más confiables.
¿Están bien definidos el formato, la estructura y la longitud de salida esperados? Si la salida debe ser analizada por un analizador posterior, ¿no hay ambigüedades sobre el aspecto que tendrá la salida? Esto comprueba la condición de error más común: salidas que se ven bien pero que no se pueden analizar.
¿Este mensaje proporciona al modelo el contexto suficiente para funcionar sin hacer suposiciones? Los modelos que deben hacer suposiciones siempre harán suposiciones incorrectas. El contexto, como la terminología del dominio, la información de límites y el contexto, eliminará por completo este tipo de error.
¿Están cubiertas las fundas laterales? ¿Esta solicitud especifica qué hacer en los casos en que la entrada sea ambigua, incompleta o fuera de los límites? Esta es la opción más común que se pasa por alto y la que causa más problemas relacionados con la producción. Alucinaciones, formatos de entrada inesperados, falta de información: todo esto debe abordarse en este mensaje.
Escala de puntuación: 90—100 está listo para la producción. 75—89 tiene lagunas pero es funcional. 50—74 funciona pero no es fiable. Por debajo de 50 significa problemas estructurales importantes que deben solucionarse antes del envío.
Tenemos las puntuaciones y las explicaciones de cada criterio. A continuación, producimos una versión concreta del mensaje mejorado. Las recomendaciones no son solo ideas abstractas. Corresponden a cambios reales en la estructura del mensaje. Estos cambios incluyen añadir las especificaciones de salida que faltaban, hacer que las instrucciones poco claras fueran más precisas, dividir los problemas relacionados con el contenido y el formato y hacer explícitas las alternativas para los casos extremos.
La principal restricción que imponemos es la preservación de la intención. En otras palabras, no estamos reescribiendo el aviso. Más bien, estamos llenando las lagunas que la evaluación puso de relieve, preservando al mismo tiempo la intención y el dominio originales.
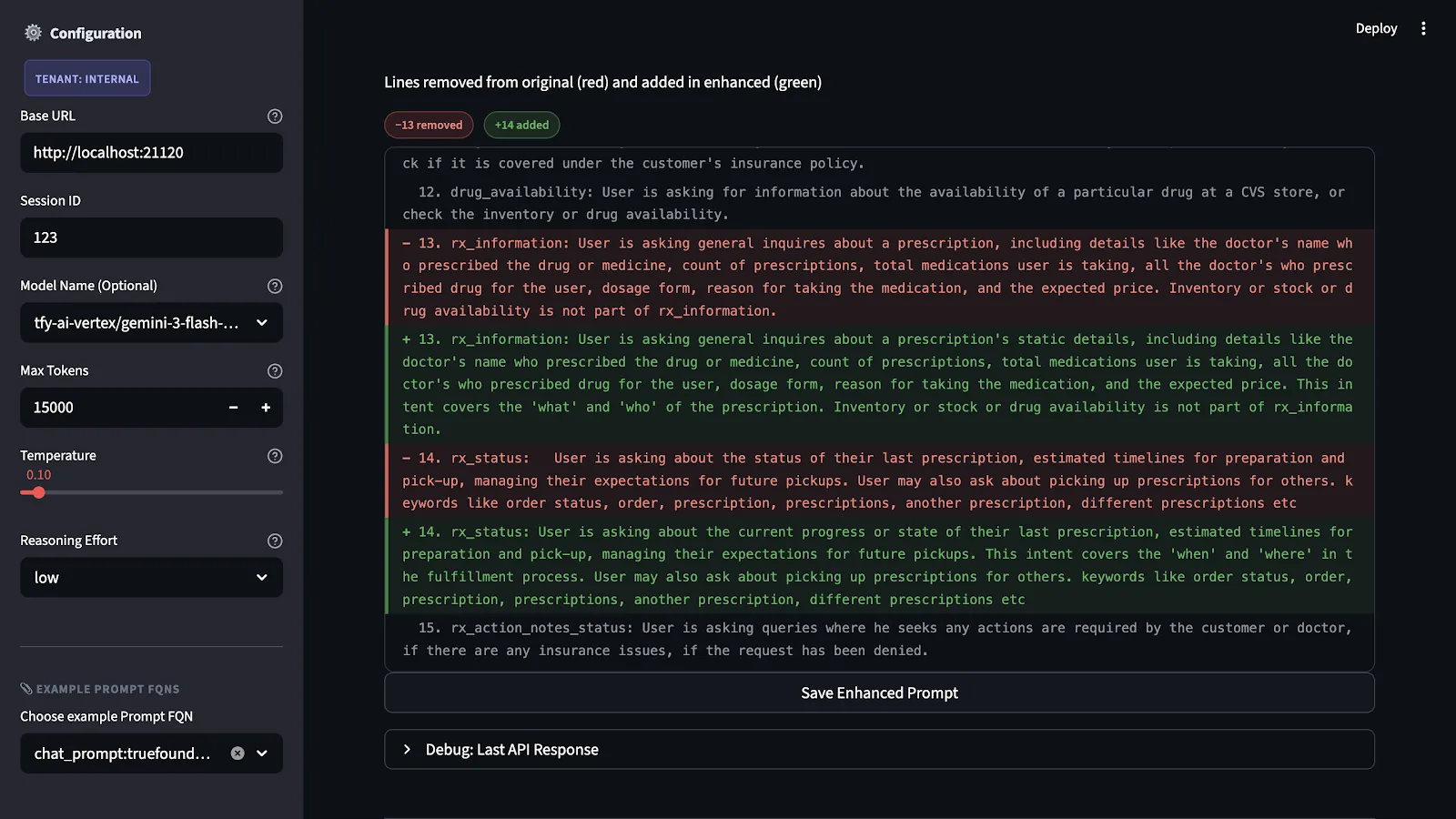
La solicitud mejorada no se ejecuta hasta que se pone a prueba por primera vez. La prueba se lleva a cabo utilizando un conjunto de datos de referencia que representa todos los escenarios y fallos posibles en relación con la aplicación.
Este proceso es necesario porque hacer alteraciones en las indicaciones que parecen beneficiosas en teoría puede causar problemas no deseados en la aplicación. Si bien hacer que una especificación de salida sea más estricta puede causar problemas imprevistos en la aplicación debido a que depende de la flexibilidad del modelo en otras situaciones, puede causar problemas cuando se combina con ciertos tipos de entrada.
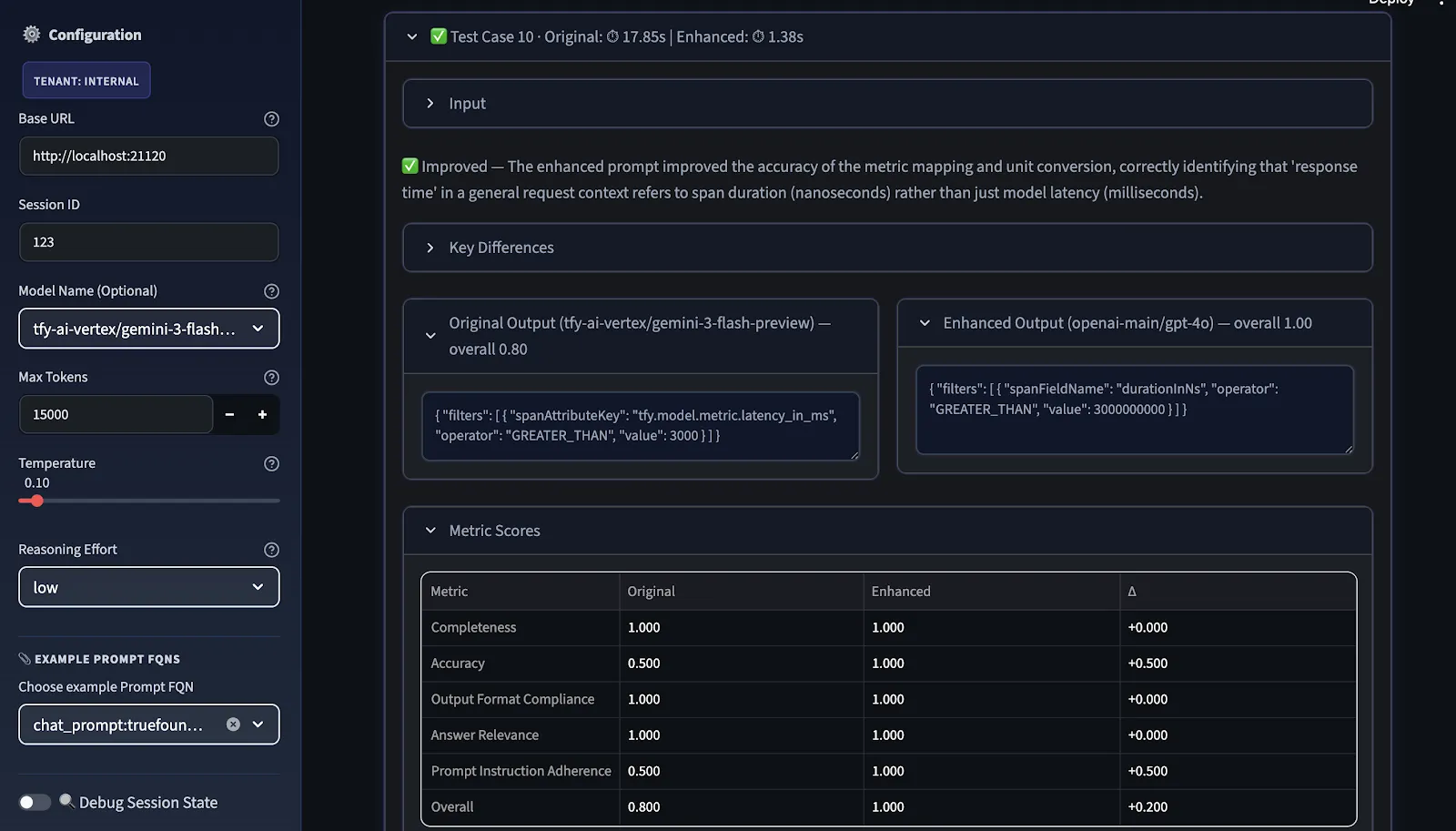
El último paso es la evaluación comparativa. Comparamos las indicaciones originales y las mejoradas en dos dimensiones:
La puntuación global es la media aritmética de las métricas seleccionadas; los usuarios pueden elegir las métricas relevantes antes de la evaluación.
La vista de comparación muestra dónde la mejora es real, dónde es específica del modelo y dónde se necesitan más iteraciones antes de que la solicitud pueda considerarse portátil entre los proveedores.
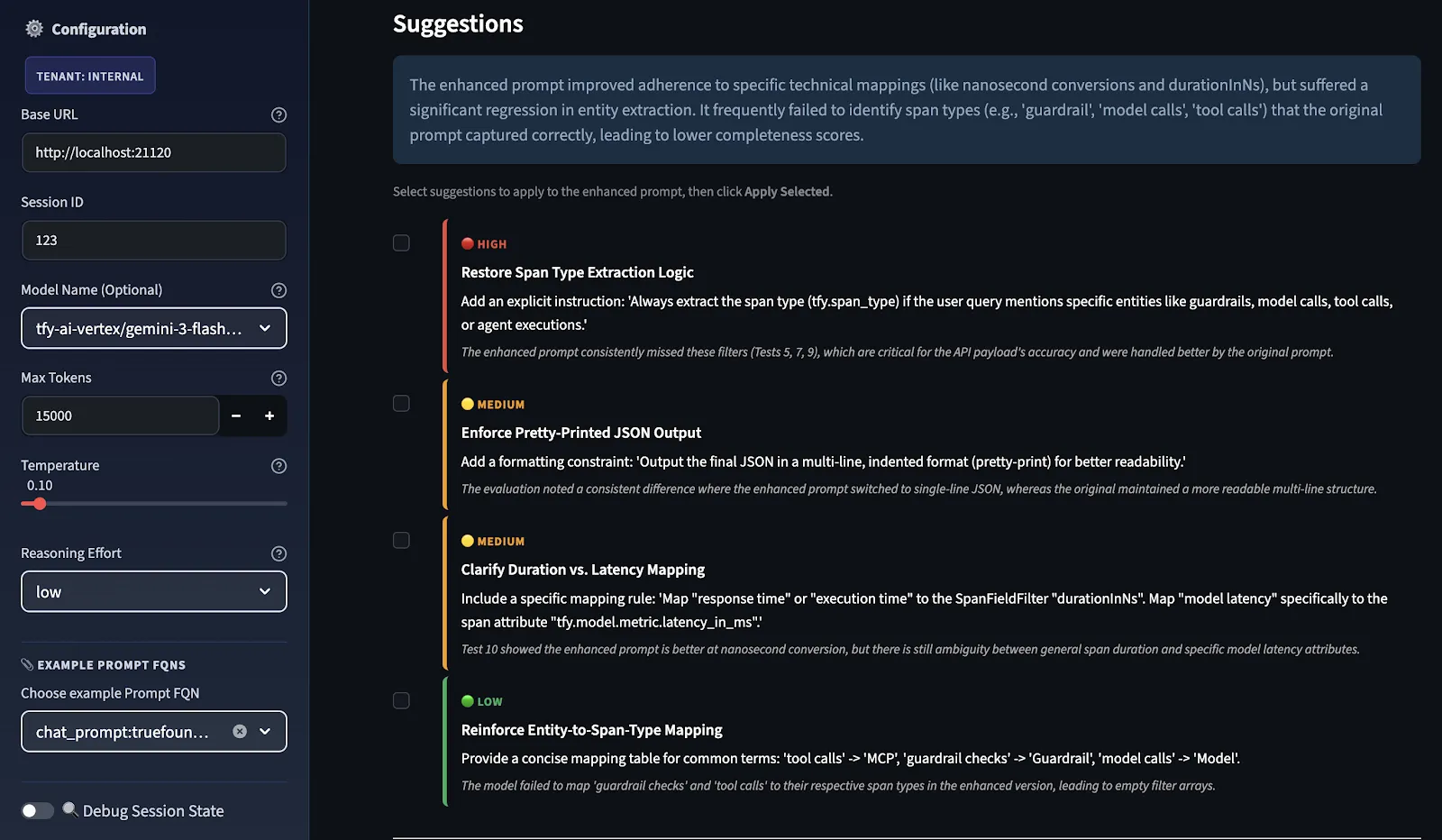
Posteriormente, el juez del LLM puntúa ambas indicaciones y las sugerencias de mejora se proporcionan en orden de prioridad, clasificadas en ALTA, MEDIA y BAJA según el lugar donde la diferencia entre la puntuación original y la mejorada sea más débil.
Usted selecciona qué sugerencias desea aplicar como recomendación y el sistema las devuelve a través del mismo proceso de mejora para generar un mensaje mejorado refinado. Este ciclo de retroalimentación mejora continuamente la solicitud al volver a evaluarla y refinarla.
Estas no son sugerencias generales; son específicas de cada caso de prueba. La razón es que el modelo de evaluación evalúa el rendimiento de las instrucciones originales y las instrucciones mejoradas en los casos de prueba. Estas sugerencias que recibes están directamente relacionadas con lo que faltaba en la evaluación de tu caso de prueba. Si tuvieras que añadir casos de prueba adicionales a esta evaluación, es posible que veas otras sugerencias.
Puede repetir este proceso tantas veces como sea necesario. Cada ciclo utiliza el indicador previamente mejorado como nueva línea base, lo que permite que las mejoras se acumulen. La última solicitud refinada puede descargarse directamente desde la interfaz de usuario e implementarse mediante True Foundry Gateway.
Cuando hablamos de ingeniería hay algo en lo que muchas veces no pensamos. Lo que pasa es que modelos como Gemini, GPT-5, Claude y LLama no entienden las cosas de por medio. Esto se debe a que todos fueron entrenados de manera que aprendieron de diferentes conjuntos de información y se les obligó a hacer las cosas de manera un poco diferente. Entonces, cuando les preguntamos algo, es posible que nos den respuestas diferentes. Esto no se debe a que la pregunta sea mala. Porque cada modelo tiene su propia forma de hacer las cosas.
Algunos modelos son muy buenos para seguir las reglas y hacer lo que decimos. Los modelos GPT-4, por ejemplo, pueden ser muy literales. Los modelos LLama pueden ser más generativos. Intente llenar los vacíos. Los modelos Claude pueden ser buenos para manejar preguntas complicadas. Otros modelos pueden ser mejores para responder preguntas sencillas.
La única forma de saber cómo se comporta un mensaje en todos los modelos es probándolo. Y la única manera de hacer que las pruebas sean sistemáticas es tener un flujo de trabajo de evaluación como este.
Una vez evaluada, mejorada y probada su solicitud, necesitará un sistema que la administre a lo largo del tiempo: el control de versiones, la implementación específica del entorno y la capacidad de revertir los cambios incorrectos sin volver a implementar toda la aplicación.
Aquí es donde entra en juego AI Gateway de TrueFoundry. TrueFoundry proporciona un sistema centralizado de administración de solicitudes con control de versiones incorporado. Se realiza un seguimiento de todos los cambios realizados en una solicitud. Además, puedes hacer referencia a versiones específicas mediante alias legibles por humanos, como v1-prod o v2-staging. El Gateway resuelve la versión inmediata durante el tiempo de ejecución, lo que significa que las actualizaciones rápidas ya no requieren la redistribución del código.
A medida que el flujo de trabajo se ha aplicado a una variedad de solicitudes y proyectos, se han hecho evidentes varios puntos clave:
El objetivo por el que estamos trabajando es hacer que la calidad inmediata sea tan medible y auditable como cualquier otra parte de su paquete de software. Esto implica realizar pruebas de regresión automatizadas para detectar cuándo cambia la versión del modelo subyacente, integrar rápidamente las versiones en el proceso de implementación y disponer de paneles de evaluación que permitan ver el rendimiento inmediato a lo largo del tiempo.
La ingeniería rápida ya no se considera un oficio sino una ciencia. Las organizaciones que la traten como tal e implementen un proceso formal de evaluación, iteración y pruebas estarán mejor posicionadas para crear sistemas de IA más confiables que las que no lo hacen. El proceso descrito en este flujo de trabajo es un esfuerzo en pro de ese fin.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


