

May 23, 2024
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En el mundo actual basado en los datos, la búsqueda en grandes cantidades de datos para encontrar elementos similares es una operación fundamental que se utiliza en diversas aplicaciones, desde bases de datos hasta motores de búsqueda y sistemas de recomendación. Este proceso, conocido como búsqueda por similitud, implica identificar los elementos que son similares en función de ciertos criterios.
Si bien las búsquedas tradicionales en bases de datos basadas en criterios numéricos fijos (como encontrar empleados dentro de un rango salarial específico) son sencillas, la búsqueda por similitud aborda consultas más complejas. Por ejemplo, un usuario puede buscar «zapatos», «zapatos negros» o un modelo específico como «Nike AF-1 LV8». Estas consultas pueden ser vagas y variadas, y requieren que el sistema comprenda y diferencie conceptos como los diferentes tipos de zapatos.
La búsqueda por similitud es crucial en muchos campos, entre ellos:
El desafío clave en la búsqueda por similitud es tratar con datos a gran escala y, al mismo tiempo, comprender con precisión los significados conceptuales más profundos de los elementos que se buscan. Las bases de datos tradicionales, que se basan en representaciones simbólicas de objetos, son insuficientes en estos escenarios. En cambio, necesitamos técnicas más avanzadas que puedan gestionar las representaciones semánticas de los datos y realizar búsquedas de manera eficiente, incluso a escala: representaciones, métricas de distancia y diferentes algoritmos de búsqueda.
Al aprovechar la búsqueda por similitud, podemos transformar las consultas complejas y abstractas en información procesable, lo que la convierte en una herramienta poderosa en varios dominios. En las siguientes secciones, profundizaremos en el funcionamiento de la búsqueda por similitud, centrándonos en el papel de las representaciones vectoriales, las métricas de distancia y los diferentes algoritmos de búsqueda.
.webp)
En el aprendizaje automático, representamos objetos y conceptos del mundo real como vectores, que son conjuntos de números continuos conocidos como incrustaciones. Este enfoque nos permite captar los significados semánticos más profundos de los elementos. Cuando objetos como imágenes o texto se convierten en incrustaciones vectoriales, su similitud se puede evaluar midiendo la distancia entre estos vectores en un espacio de alta dimensión.
Por ejemplo, en un espacio vectorial, las imágenes similares tendrán vectores que están cerca unos de otros, mientras que las imágenes diferentes estarán más alejadas. Esto permite realizar operaciones matemáticas para buscar y comparar elementos similares de manera eficiente.
.webp)
Se utilizan varios modelos para generar estas incrustaciones vectoriales:
Estos modelos se entrenan en grandes conjuntos de datos y tareas, lo que les permite producir incrustaciones que representan de manera efectiva el contenido semántico de los elementos.
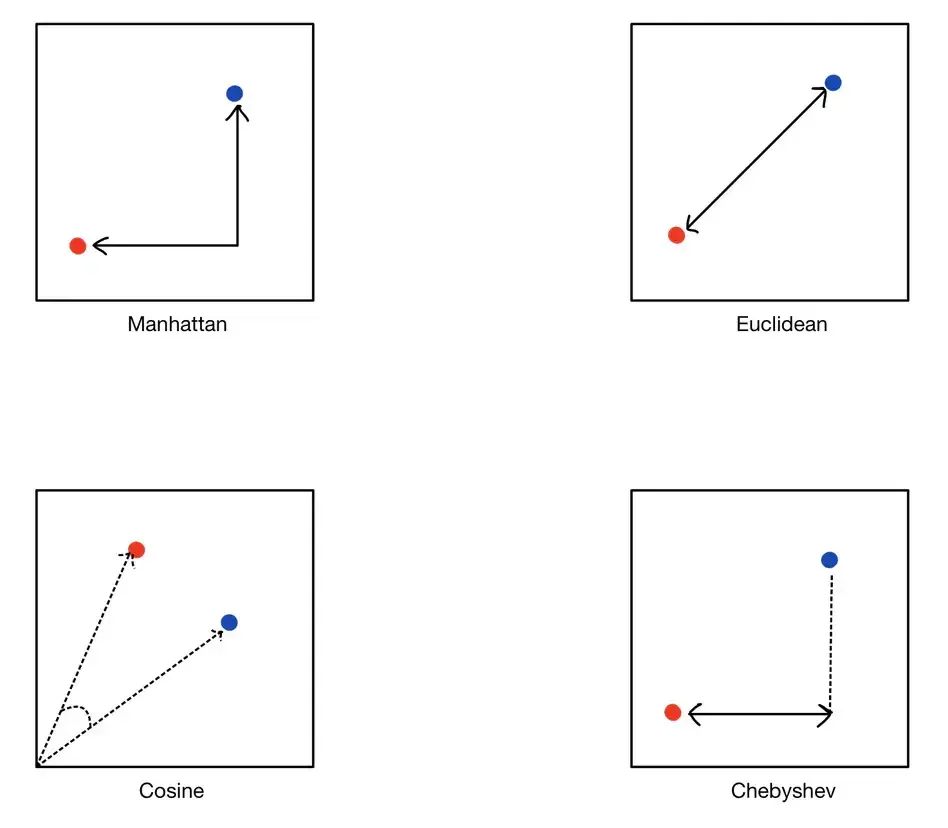
Para determinar qué tan similares son las incrustaciones de dos vectores, utilizamos métricas de distancia. Estas métricas calculan la «distancia» entre los vectores en el espacio vectorial; las distancias más pequeñas indican una mayor similitud.
La distancia euclidiana mide la distancia en línea recta entre dos puntos en un espacio de alta dimensión. Es la forma más intuitiva de medir la distancia, similar a la distancia geométrica que se puede medir con una regla. Resulta útil cuando los datos son densos y el concepto de distancia física es relevante.
Fórmula:
.webp)
También conocida como distancia L1, la distancia de Manhattan suma las diferencias absolutas de sus coordenadas. Esta métrica es adecuada para estructuras de datos similares a cuadrículas y se puede visualizar como la distancia total de una «manzana» que se recorrería entre los puntos de una cuadrícula.
Fórmula:
.webp)
La similitud de coseno mide el coseno del ángulo entre dos vectores, centrándose en su dirección en lugar de en la magnitud. Esto es particularmente útil para los datos de texto, donde la magnitud del vector (frecuencia de las palabras) puede variar, pero la dirección (patrón de uso de las palabras) es más importante.
.webp)
La distancia de Chebyshev mide la distancia máxima entre las coordenadas de un par de vectores. Se usa con frecuencia en escenarios de cuadrícula similares a los del ajedrez, donde puedes moverte en cualquier dirección, incluso en diagonal.
.webp)
La elección de la métrica de distancia correcta depende de las características y requisitos específicos de la aplicación. Estas son algunas pautas para seleccionar la métrica adecuada:
K-Nearest Neighbors (k-NN) es un algoritmo popular que se utiliza para encontrar los vectores más cercanos a un vector de consulta determinado. Así es como funciona y sus ventajas y desventajas:
.webp)
Para abordar la ineficiencia de k-NN con grandes conjuntos de datos, los métodos del vecino más cercano aproximado (ANN) proporcionan una alternativa más rápida, aunque menos precisa. El objetivo de los algoritmos ANN es encontrar una «estimación acertada» de los vecinos más cercanos, intercambiando algo de precisión por velocidad.
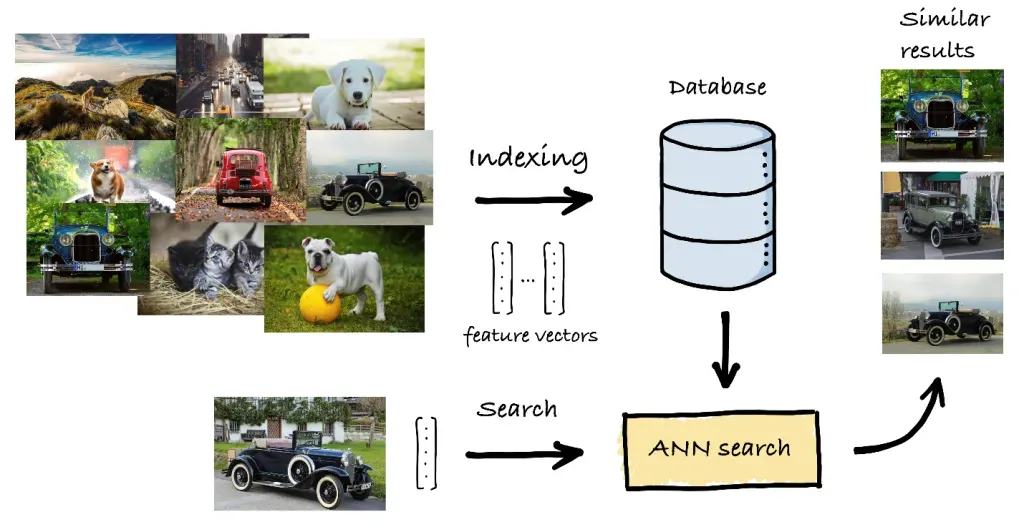
Al implementar la búsqueda por similitud en la práctica, varias bibliotecas y marcos pueden ayudar a:
La búsqueda por similitud tiene una amplia gama de aplicaciones en varios campos, lo que aprovecha la capacidad de encontrar y comparar artículos similares de forma rápida y precisa. Estas son algunas de las aplicaciones clave:
Los sistemas de recomendación utilizan la búsqueda por similitud para sugerir productos, contenido o servicios en función de las preferencias y el comportamiento del usuario.
La búsqueda por similitud es crucial para recuperar imágenes o vídeos visualmente similares de grandes bases de datos.
En la PNL, la búsqueda por similitud ayuda en varias aplicaciones basadas en texto al encontrar documentos o frases semánticamente similares.
Detectar actividades fraudulentas mediante la búsqueda de patrones y anomalías que se desvían del comportamiento normal.
La búsqueda de similitudes ayuda en el diagnóstico médico y la investigación genética al comparar los datos de los pacientes y las secuencias genéticas.
Uno de los principales desafíos en la búsqueda por similitud es la naturaleza de las consultas de los usuarios. Las consultas pueden ir desde términos muy genéricos, como «zapatos», hasta artículos muy específicos, como «Nike AF-1 LV8». El sistema debe ser capaz de discernir estos matices y comprender cómo se relacionan los diferentes elementos entre sí. Esto requiere una comprensión profunda del significado semántico detrás de las consultas, que va más allá de la simple coincidencia de palabras clave.
Otro desafío importante es la escalabilidad. En las aplicaciones del mundo real, a menudo trabajamos con conjuntos de datos masivos que pueden incluir miles de millones de elementos. La búsqueda eficiente en volúmenes tan grandes de datos requiere técnicas avanzadas y potentes recursos computacionales. Los sistemas de bases de datos tradicionales, que están diseñados para obtener coincidencias exactas y representaciones simbólicas, tienen dificultades para funcionar bien en estos escenarios.
La búsqueda por similitud, también conocida como búsqueda vectorial, desempeña un papel fundamental en varias aplicaciones modernas. Al aprovechar las incrustaciones vectoriales y las sofisticadas métricas de distancia, la búsqueda por similitud nos permite encontrar y comparar elementos en función de su significado semántico. Estas son las principales conclusiones:
Para aprovechar realmente el poder de la búsqueda por similitud, es esencial comprender los principios subyacentes y elegir las herramientas y técnicas adecuadas para sus necesidades específicas. Ya sea que esté creando un motor de recomendaciones, un sistema de recuperación basado en contenido o un mecanismo de detección de fraudes, la búsqueda por similitud puede mejorar significativamente la precisión y la eficiencia de sus soluciones.
La búsqueda por similitud es una técnica para encontrar elementos que son similares en grandes conjuntos de datos. Se basa en incrustaciones vectoriales que capturan el significado conceptual de los datos y, a menudo, utilizan representaciones vectoriales y métricas de distancia. Este proceso es crucial para aplicaciones como las recomendaciones de productos y la comparación de textos, ya que permite a los sistemas identificar la información relevante de manera eficiente y precisa.
Para realizar una búsqueda de similitud, los objetos como texto o imágenes se convierten primero en incrustaciones vectoriales mediante modelos especializados. Luego, las métricas de distancia, como la distancia euclidiana o la distancia del coseno, miden la «distancia» entre estos vectores en un espacio de alta dimensión. Las distancias más pequeñas indican una similitud mayor. Como alternativa, las métricas de similitud, como la similitud entre cosenos, puntúan directamente la aproximación, donde una puntuación más alta (más cercana a 1) significa más similitud.
Un excelente ejemplo de búsqueda por similitud es una plataforma de comercio electrónico que recomienda productos similares a los que un usuario ha visto o comprado. Esto ayuda a los compradores a descubrir artículos relevantes sin esfuerzo. La búsqueda de imágenes, es decir, la búsqueda de imágenes visualmente similares en vastas bases de datos, es otra aplicación clave que utiliza la tecnología de búsqueda de similitudes.
En los sistemas impulsados por LLM, especialmente en los canales RAG (Retrieval-Augmented Generation), la búsqueda por similitud funciona junto con el modelo al convertir el texto en incrustaciones vectoriales que capturan el significado semántico. Una capa de recuperación busca en estos vectores para encontrar el contenido más parecido a una consulta y, a continuación, transfiere los resultados al LLM midiendo la distancia entre estos vectores. Es crucial para recuperar información relevante y generar respuestas que tengan en cuenta el contexto, lo que mejora en gran medida la comprensión del modelo y su utilidad para los usuarios.
La búsqueda de similitudes es crucial en muchas aplicaciones. Mejora las recomendaciones de productos de comercio electrónico, facilita la búsqueda de imágenes y vídeos y mejora el procesamiento del lenguaje natural para la comparación de textos. En el sector sanitario, ayuda a identificar casos médicos similares, transformando datos complejos en información útil en todos los sectores.
La búsqueda semántica se basa en la búsqueda por similitud para encontrar elementos en función de su significado, no solo de palabras clave. Utiliza incrustaciones vectoriales para representar los datos semánticamente. Si bien la búsqueda por similitud es la técnica para comparar estos vectores, la búsqueda semántica es la aplicación que la aprovecha para una comprensión contextual más profunda.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


