

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: July 8, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La disponibilidad informática es el principal obstáculo para capacitar a los LLM y escalar la inferencia de alto rendimiento. Si ha intentado aprovisionar Instancias P5 de Amazon EC2 En el caso de las máquinas virtuales Azure ND H100 v5 últimamente, es probable que se haya encontrado con errores de InsuficientInstanceCapacity o que se le haya dicho que necesita un acuerdo de precios privado de varios años.
Esta escasez convierte a los proveedores de GPU especializados, como CoreWeave, Lambda Labs y FluidStack, en alternativas viables. Estas «neonubes» ofrecen NVIDIA H100s y los A100 suelen tener tarifas bajo demanda más bajas que las de los tres grandes.
¿El problema? ¿Está ejecutando AWS para su Amazon S3 el lago de datos, al tiempo que se activan manualmente nodos sin procesar en Lambda Labs, crea flujos de trabajo fragmentados. Para solucionar este problema, tratamos las nubes especializadas como estándar Kubernetes clústeres dentro de un plano de control unificado.
TrueFoundry utiliza una arquitectura de plano dividido. El plano de control gestiona la programación de tareas y el seguimiento de los experimentos, mientras que el plano de cálculo permanece en su entorno. Dado que la mayoría de las nubes especializadas proporcionan una Kubernetes dar servicio o permitirle implementar K3, los adjuntamos a través de un agente estándar.
Abstraemos el almacenamiento y la entrada. Ya sea que el proveedor utilice Vast Data o un RAID NVMe local, lo asignamos a un Reclamación de volumen persistente. Esto mantiene tu Estibador contenedores portátiles entre proveedores.
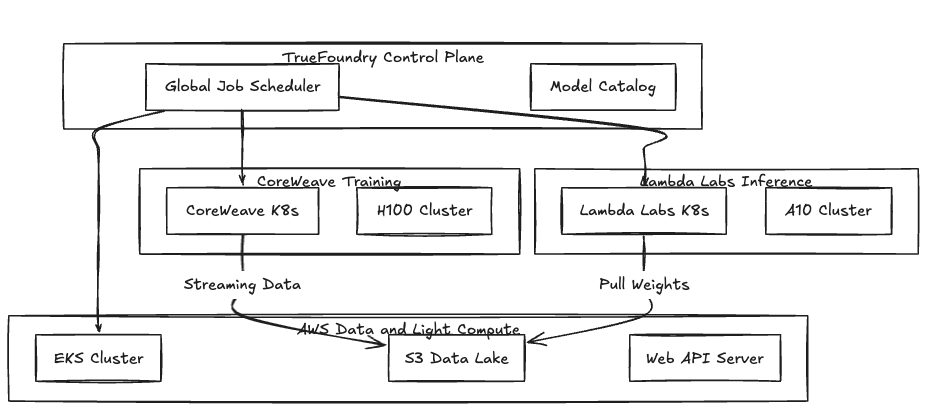
Figura 1: Topología híbrida que utiliza AWS para la persistencia de datos y nubes especializadas para cargas de trabajo con uso intensivo de la GPU.
Los precios del H100 bajo demanda varían significativamente. Usamos TrueFoundry para configurar colas priorizadas. Lo primero que puede hacer es utilizar una capacidad interrumpible y barata en nubes especializadas. Si el proveedor se antepone a la instancia o la capacidad desaparece, el programador puede conmutar automáticamente por error a una instancia reservada Amazon EC2 instancia.
Confiar en plataformas de IA patentadas a menudo lo vincula a un ecosistema de almacenamiento e IAM específico de la nube. Empaquetamos los trabajos de formación como contenedores estándar. TrueFoundry se encarga de Controladores Kubernetes CSI para el montaje de S3 y configura el Kit de herramientas de contenedores de NVIDIA variables de entorno automáticamente. Para mover un trabajo de AWS a CoreWeave, actualice el cluster_name en sus especificaciones de implementación.
Las configuraciones de nubes múltiples generalmente interrumpen el registro. Agregamos Prometeo métricas y Grafana paneles en todos los clústeres. Si un trabajo de entrenamiento se realiza en un nodo de Lambda Labs, verá los registros de uso de la GPU y del sistema en la misma interfaz de usuario que utiliza para su entorno de EKS de producción.
Para agregar capacidad especializada, siga este ciclo de vida:
helm repo add truefoundry https://truefoundry.github.io/infra-charts/
helm install tfy-agent truefoundry/tfy-agent \
--set tenantName=my-org \
--set clusterName=lambda-h100-pool \
--set apiKey=<YOUR_API_KEY>
Comparación de modelos de infraestructura
Confiar en una sola nube para la computación de LLM ya no es una estrategia viable para los equipos de ingeniería de alto crecimiento. Al desvincular la definición de la carga de trabajo del lugar de ejecución, puede tratar las GPU como un producto básico. Para aumentar la eficiencia, dirija su entrenamiento intensivo a nubes especializadas y, al mismo tiempo, mantenga sus datos y servicios principales en su región de hiperescala principal.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


