

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
.webp)
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Si bien el desarrollo de modelos se ha simplificado, la implementación, el escalado y la administración de modelos de aprendizaje automático en producción siguen siendo un obstáculo importante. Los equipos de plataformas son responsables de garantizar que los modelos de aprendizaje automático se puedan implementar, monitorear, escalar y optimizar sin problemas en múltiples entornos, al tiempo que se minimizan los costos de infraestructura y se mantiene la confiabilidad.
Los enfoques tradicionales de implementación de ML suelen requerir una amplia experiencia en Kubernetes, una administración manual de los recursos de la GPU y mecanismos de escalado ineficientes, lo que genera una gran sobrecarga operativa para los equipos de plataforma. En respuesta a estos desafíos, TrueFoundry ofrece una solución de implementación de aprendizaje automático como servicio, diseñada para automatizar la selección de infraestructuras, simplificar la implementación, optimizar el rendimiento y mejorar la observabilidad.
La implementación de modelos de aprendizaje automático requiere seleccionar las instancias de GPU, los servidores modelo y las configuraciones de Kubernetes correctas. Sin una automatización inteligente, los equipos de plataformas deben asignar los recursos de forma manual, lo que conduce a despliegues lentos y propensos a errores.
El proceso actual a menudo implica múltiples transferencias entre científicos de datos, ingenieros de aprendizaje automático y equipos de DevOps. Los ingenieros de plataformas intervienen con frecuencia para ayudar a configurar, escalar y supervisar Kubernetes, lo que genera ineficiencias y cuellos de botella.
Las implementaciones de ML tradicionales carecen de mecanismos de escalado automático de GPU integrados. Sin un escalado dinámico basado en las solicitudes por segundo (RPS), la utilización o los desencadenantes basados en el tiempo, la infraestructura se subutiliza (lo que genera un desperdicio de gastos) o se aprovisiona en exceso (lo que provoca cuellos de botella en el rendimiento).
Elegir el más eficiente modelo de servicio El enfoque, junto con el modelo de servidor correcto (por ejemplo, vLLM, SGLang, Triton, FastAPI, TensorFlow Serving) requiere una amplia experiencia en la evaluación comparativa del rendimiento, la optimización de la memoria y el equilibrio de carga.
Las implementaciones de ML generan registros, métricas y eventos en varias plataformas. La solución de problemas o fallos de rendimiento es tediosa, ya que los registros suelen estar dispersos, lo que dificulta que los equipos de plataformas identifiquen y resuelvan rápidamente los problemas.
Sin una optimización automatizada de los recursos, los equipos de la plataforma deben supervisar y gestionar manualmente los modelos inactivos, lo que genera gastos innecesarios en la nube. Los métodos tradicionales de implementación del aprendizaje automático no admiten el apagado automático ni el escalado dinámico.
Las empresas requieren actualizaciones del modelo sin tiempo de inactividad, pero los métodos tradicionales carecen de actualizaciones continuas, lanzamientos canarios e implementaciones azul-verdes. Esto aumenta el riesgo de interrupciones del servicio al implementar nuevas versiones de modelos.
TrueFoundry elimina estos desafíos al proporcionar un plataforma de implementación de ML totalmente gestionada, habilitando despliegues de autoservicio, selección inteligente de recursos, optimización de costos y observabilidad mejorada. Así es como:
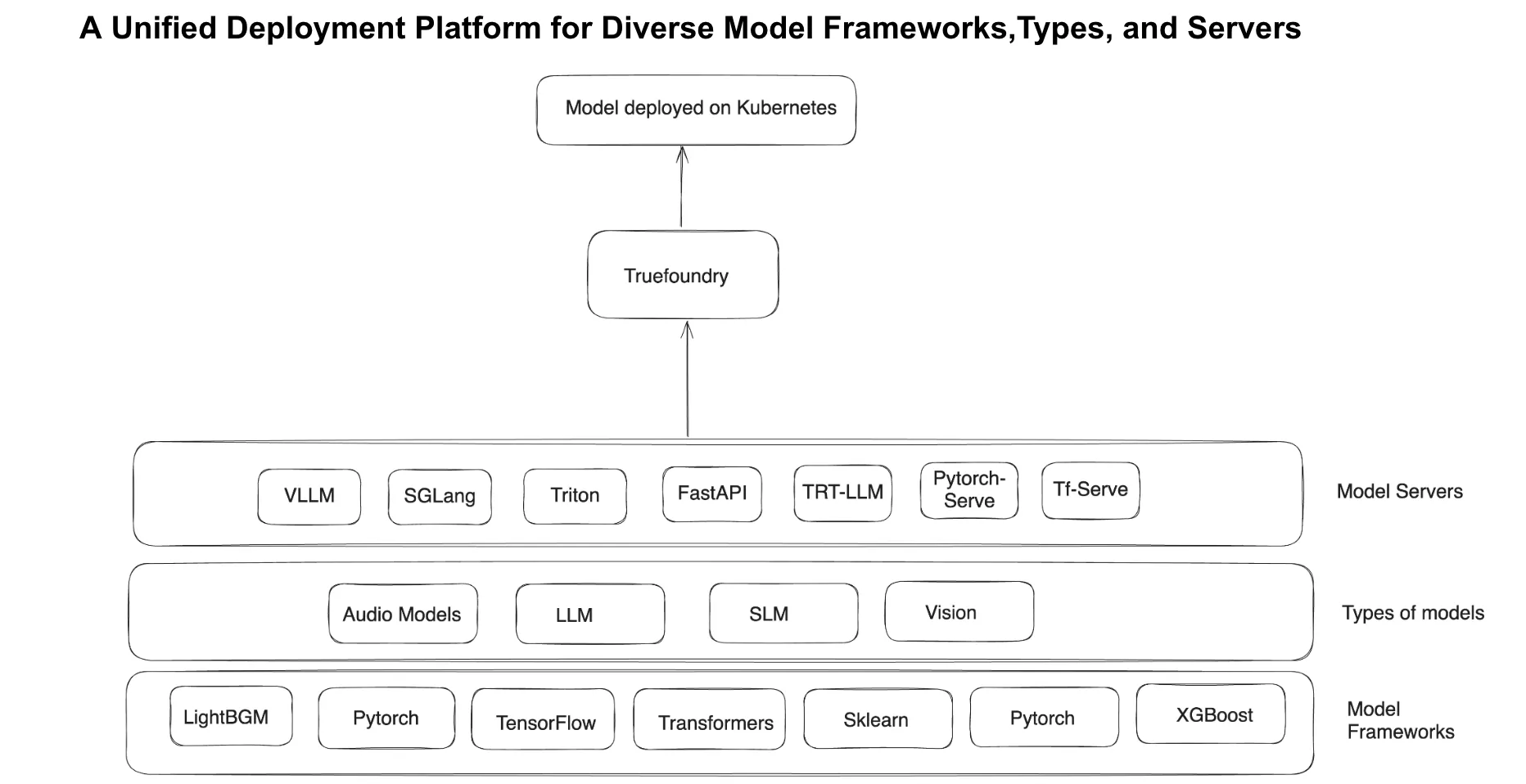
TrueFoundry permite a los equipos de plataforma implementar modelos de aprendizaje automático con un solo clic, lo que elimina la necesidad de contar con experiencia en Kubernetes. La plataforma selecciona de forma inteligente las mejores configuraciones de infraestructura, seleccionando los tipos de instancias de GPU, los servidores modelo y las estrategias de escalado óptimos en función de los requisitos de carga de trabajo.
Además, la integración de GitOps garantiza que todas las implementaciones sean automatizadas y reproducibles, con la generación de YAML integrada para facilitar los flujos de trabajo de CI/CD. Al abstraer las complejidades de la infraestructura, TrueFoundry permite a los científicos de datos y a los ingenieros de aprendizaje automático implementar modelos de forma independiente, lo que reduce la carga operativa de los equipos de la plataforma.
El escalado automático avanzado basado en GPU de TrueFoundry ajusta los recursos de forma dinámica en función de la demanda en tiempo real. Los modelos se escalan hacia arriba y hacia abajo en función del RPS, el uso de la GPU o los activadores programados, lo que garantiza un rendimiento y una rentabilidad óptimos. La plataforma también ofrece:
Además, TrueFoundry admite estrategias de implementación avanzadas, que incluyen actualizaciones continuas, lanzamientos canarios e implementaciones azul-verdes, lo que permite a los equipos de plataforma implementar nuevas versiones de modelos sin tiempo de inactividad.
TrueFoundry proporciona una observabilidad centralizada y ofrece registros, métricas y eventos en un solo lugar, lo que mejora significativamente la eficiencia de la solución de problemas. Este panel unificado ayuda a los equipos de la plataforma a:
El enrutamiento fijo para las LLM mejora aún más el rendimiento en un 50%, lo que garantiza una gestión eficiente de las solicitudes, mientras que la compatibilidad con el catálogo de modelos (actualmente integrada con Hugging Face) proporciona una manera fácil de administrar las versiones y los registros de los modelos.
Además, las sugerencias de infraestructura automatizadas de TrueFoundry optimizan las configuraciones de la CPU, la memoria y el escalado automático en función de los patrones de tráfico, lo que agiliza aún más la administración de la implementación.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


