

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
A medida que los grandes modelos lingüísticos (LLM) siguen transformando la forma en que se crean las aplicaciones, incluidos los copilotos de IA y las interfaces de chat empresariales, existe una creciente necesidad de infraestructuras y procesos estructurados para gestionarlos de manera eficiente. Esta disciplina emergente se conoce como LLMOP. Al igual que los MLOps disciplinaron los flujos de trabajo tradicionales de aprendizaje automático, los LLMOps se centran en resolver los desafíos operativos únicos que implica trabajar con modelos básicos a escala.
LLMOps no se limita a servir un modelo a través de una API. Implica todo el ciclo de vida, lo que incluye la ingeniería rápida, el ajuste, la generación aumentada por recuperación (RAG), el control de versiones, la supervisión del rendimiento, la optimización de costos y la aplicación del acceso seguro. Debido al tamaño y la complejidad de las LLM, es necesaria una arquitectura dedicada para garantizar despliegues confiables, escalables y fáciles de mantener.
Este artículo explora los fundamentos de la arquitectura LLMOP. Analizaremos sus componentes clave, examinaremos los patrones de referencia utilizados en los sistemas del mundo real y destacaremos las herramientas que respaldan el rápido desarrollo y la gobernanza. Ya sea que esté creando un asistente de atención al cliente, un motor de recuperación de conocimientos o una plataforma de agentes basada en la inteligencia artificial, comprender la arquitectura de LLMOP es esencial para crear soluciones que sean eficientes, escalables y listas para la producción.
LLMOP la arquitectura se refiere al diseño estructurado y al conjunto de componentes necesarios para administrar el ciclo de vida de los modelos de lenguaje de gran tamaño en los entornos de producción. Es la base que permite a los equipos pasar de la experimentación con los LLM a la creación de aplicaciones escalables, seguras y fáciles de mantener impulsadas por esos modelos.
A diferencia de los MLOP tradicionales, que se ocupan principalmente de conjuntos de datos estructurados y canalizaciones de entrenamiento de modelos, los LLMOP deben tener en cuenta desafíos únicos como la orquestación rápida, la generación aumentada con recuperación, el control de versiones de modelos a gran escala y la latencia de inferencia en tiempo real. La arquitectura también debe soportar cargas de trabajo dinámicas, enrutamiento multimodelo, y un acceso seguro para todos los usuarios y equipos.
La arquitectura de LLMops combina infraestructura, automatización y observabilidad para garantizar una implementación y una gobernanza confiables. Por lo general, incluye:
Esta arquitectura está diseñada para admitir tanto los modelos previamente entrenados que funcionan como API como los modelos personalizados ajustados implementados en entornos privados. A medida que crece el uso de la LLM en todos los dominios, una arquitectura bien estructurada se vuelve esencial para una iteración rápida, la rentabilidad y la confianza de los usuarios.
Comprender la arquitectura de LLMOP ayuda a los equipos a crear sistemas que se escalan sin dejar de ser flexibles, compatibles y alineados con los resultados empresariales reales.
La arquitectura LLMops aporta estructura y escalabilidad al despliegue de modelos de lenguaje de gran tamaño. A diferencia de los MLOP tradicionales, aborda las complejidades únicas relacionadas con la orquestación rápida, los canales de recuperación y el comportamiento de los modelos en tiempo de ejecución. Una arquitectura sólida une varias capas principales, cada una de las cuales cumple una función fundamental.
Administración de datos
Los LLM dependen de datos diversos y de alta calidad para funcionar bien. Este componente implica obtener, limpiar, formatear y almacenar datos de texto o documentos a gran escala. Para modelos ajustados, es posible que también se necesiten conjuntos de datos etiquetados. El control de versiones de los datos y el seguimiento del linaje son cruciales para garantizar la trazabilidad en todas las iteraciones del modelo.
Desarrollo de modelos
Esta capa se centra en seleccionar el modelo base y aplicar la personalización mediante el ajuste fino, el ajuste de instrucciones o la ingeniería rápida. Los marcos de evaluación comparativa se utilizan para validar el rendimiento en varias tareas posteriores. Herramientas como LoRa y PEFT ayudan a reducir los costos y los cálculos durante las actualizaciones de los modelos.
Inferencia e implementación
El servicio de LLM requiere una infraestructura escalable. Esto incluye las API optimizadas, la cuantificación de modelos, la transmisión a nivel de token y el escalado automático en las GPU. Las herramientas de observabilidad supervisan el costo, la latencia y el rendimiento de las inferencias. Las configuraciones de producción suelen incluir pruebas A/B, estrategias de reversión y enrutamiento multimodelo.
Seguridad y cumplimiento
Los LLMOP deben abordar las necesidades de seguridad de nivel empresarial. El cifrado, el control de acceso, la seudonimización de los datos y los registros de auditoría son esenciales para cumplir con los estándares de cumplimiento como la HIPAA, el GDPR o el SOC 2.
Gobernanza e IA responsable
Esta capa gestiona el control rápido de versiones, el seguimiento de alucinaciones y la detección de sesgos. El registro de todas las interacciones y la aplicación de filtros para detectar el contenido dañino garantizan un comportamiento ético y coherente en la producción.
Mejores prácticas y preparación para el futuro
Los LLMOP efectivos incluyen tuberías modulares, circuitos de evaluación y trazabilidad rápida. De cara al futuro, las arquitecturas están evolucionando para soportar la recuperación en tiempo real, el ajuste continuo y la coordinación entre varios agentes.
Al alinear estos componentes, los equipos pueden ofrecer aplicaciones de LLM sólidas, adaptables y listas para la empresa.
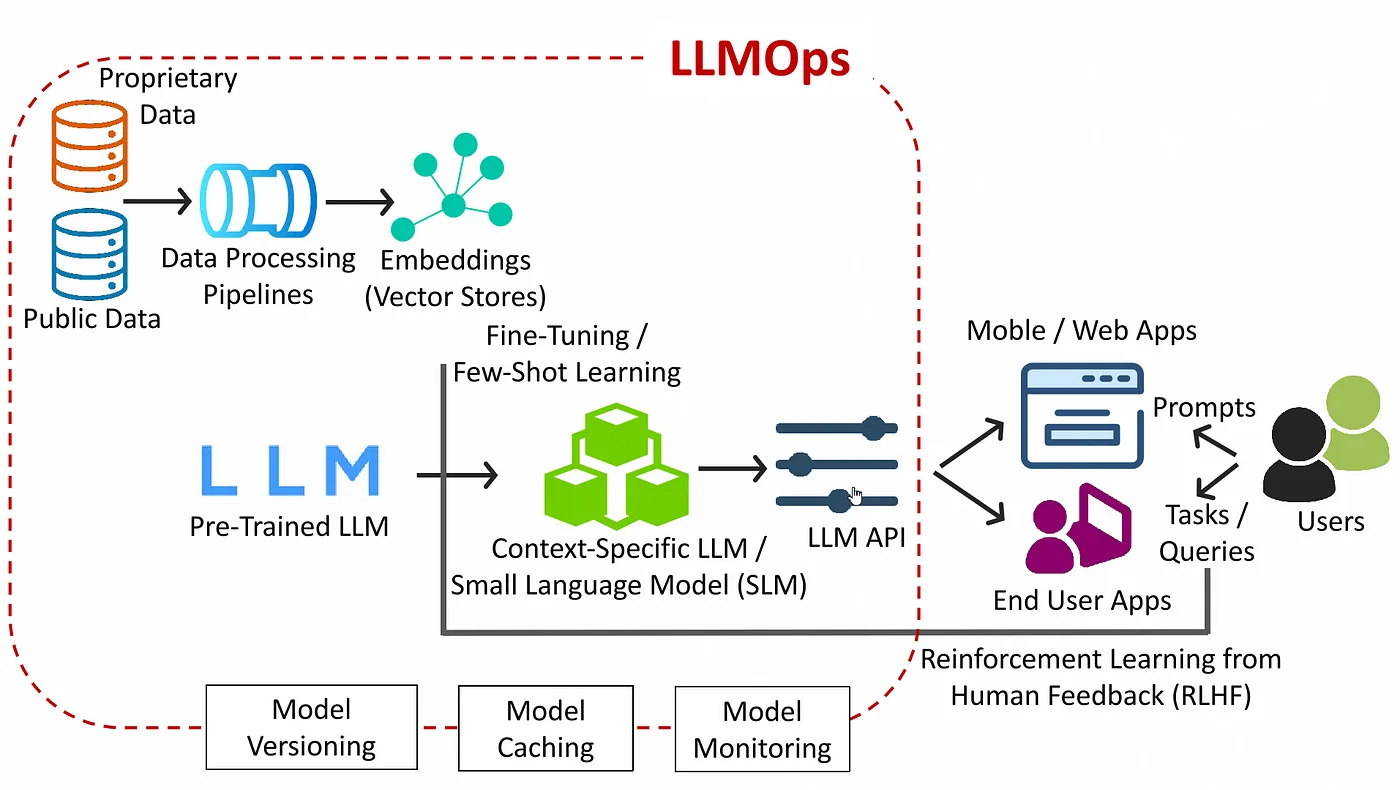
Esta imagen presenta una arquitectura LLMoPS moderna, que abarca todo el proceso, desde la ingestión de datos sin procesar hasta la implementación de la producción, la interacción del usuario y el aprendizaje basado en los comentarios. Refleja cómo se crean y mantienen los sistemas de modelos lingüísticos de gran tamaño del mundo real en todos los equipos y entornos.
Recopilación y procesamiento de datos: La arquitectura comienza con fuentes de datos públicas y propietarias. Estas pueden incluir corpus de texto, documentos, datos de CRM, bases de conocimiento internas o conversaciones con clientes. Todos los datos pasan por un proceso de procesamiento de datos, donde se limpian, normalizan y enriquecen para las tareas posteriores. Esto incluye convertir el texto en incrustaciones vectoriales, que se almacenan en bases de datos vectoriales o almacenes de incrustaciones para una recuperación rápida basada en la similitud.
Selección y adaptación del modelo: Se selecciona un LLM previamente entrenado (como GPT, LLama o Falcon) como modelo fundamental. Mediante el perfeccionamiento o el aprendizaje con pocos intentos, los equipos crean un LLM o un modelo de lenguaje pequeño (SLM) específico para cada contexto y adaptado a su dominio o caso de uso. Esto permite una mejor alineación con el lenguaje, el tono, las tareas y la estructura de datos específicos relevantes para la aplicación.
Puerta de enlace LLM
En el corazón de la arquitectura se encuentra el LLM Gateway. Proporciona una superficie API unificada para todos los puntos finales del modelo, que gestiona la autenticación, el enrutamiento, el procesamiento por lotes y la traducción de protocolos. La pasarela aplica los límites de velocidad y las cuotas, aplica plantillas rápidas y organiza el enrutamiento A/B alternativo entre las versiones del modelo. También recopila métricas detalladas sobre el recuento de solicitudes, las latencias y las tasas de error antes de pasar las llamadas a la capa de inferencia.
Servicio de API de LLM: El modelo personalizado se expone a través de una API de LLM, que actúa como la interfaz principal para las aplicaciones. Estas API están diseñadas para la interacción en tiempo real y gestionan la optimización de las inferencias mediante el control por lotes, la cuantificación y la latencia. La arquitectura también incluye el almacenamiento en caché de modelos para reducir la redundancia y la supervisión de los modelos para garantizar la confiabilidad y la rentabilidad.
Aplicaciones de usuario y bucle de retroalimentación
Los clientes móviles y web envían mensajes a la pasarela, reciben las respuestas generadas y las presentan a los usuarios finales. Los datos de interacción se capturan para volver a capacitarlos en RLHF o fuera de línea, lo que cierra el círculo de la mejora continua del modelo.
Gobernanza y gestión del ciclo de vida: La arquitectura incluye funciones operativas principales, como el control de versiones de modelos, los registros de auditoría, el seguimiento rápido y las políticas de acceso seguro. Esto garantiza que los sistemas LLM sigan siendo reproducibles, interpretables y compatibles a lo largo del tiempo.
Este diagrama captura de manera efectiva el ciclo de vida completo de la implementación y optimización de LLM dentro de una canalización de LLMOP de nivel de producción.
La arquitectura LLMops comienza con datos públicos y privados que fluyen a través de canales de procesamiento para generar incrustaciones, que se almacenan en bases de datos vectoriales. Luego, un modelo de lenguaje de gran tamaño previamente entrenado se ajusta o adapta mediante el aprendizaje de pocos pasos para crear un modelo específico para el contexto. Este modelo se implementa detrás de una API de LLM optimizada que sirve para aplicaciones móviles y web en tiempo real. Los usuarios interactúan con estas aplicaciones enviando mensajes y recibiendo respuestas inteligentes. Los comentarios de las interacciones de los usuarios se aprovechan mediante el aprendizaje reforzado a partir de los comentarios humanos (RLHF), mientras que el control de versiones, el almacenamiento en caché y la supervisión de los modelos garantizan el rendimiento, la trazabilidad y la gobernanza del sistema.
La arquitectura LLMops no es única para todos. Según la escala, el dominio y los requisitos reglamentarios de la organización, surgen diferentes patrones para poner en funcionamiento las LLM de manera efectiva. Estos patrones ayudan a los equipos a equilibrar el rendimiento, los costos, la gobernanza y la velocidad de desarrollo. A continuación, se muestran algunos patrones de referencia ampliamente adoptados en las implementaciones del mundo real.
Implementación de LLM centrada en API
Este es el patrón más común en los equipos en fase inicial o en los casos de uso ligero. Un LLM previamente entrenado o perfeccionado se aloja detrás de una API REST, y las aplicaciones posteriores realizan solicitudes sincrónicas. Las plantillas de mensajes están versionadas y se utiliza una orquestación mínima. Este patrón es fácil de implementar y funciona bien para la generación de contenido, el resumen o las interfaces de chat básicas.
Patrón de generación aumentada de recuperación (RAG)
Utilizada en entornos intensivos en conocimiento, esta arquitectura combina un LLM con una base de datos vectorial que recupera información relevante para el contexto. En primer lugar, las entradas se enriquecen incorporando datos extraídos de bases de conocimiento internas o externas y, a continuación, se transfieren al LLM. Este patrón mejora la base fáctica y la especificidad del dominio. Es ideal para la atención al cliente, el análisis de documentos legales o la búsqueda empresarial.
Patrón de orquestación del flujo de trabajo LLM +
En sistemas más complejos, los LLM se integran en flujos de trabajo más grandes mediante marcos de orquestación como LangChain, LangGraph o Airflow. Estas arquitecturas encadenan varios pasos: la recuperación, el formateo rápido, la inferencia, el posprocesamiento y los desencadenantes de acciones. Esto permite la toma de decisiones dinámicas, los sistemas con múltiples agentes y la ejecución autónoma de tareas. Se usa en aplicaciones de inteligencia artificial, copilotos de inteligencia artificial y de varios turnos.
Patrón LLM privado perfeccionado
Para industrias altamente reguladas o casos de uso de datos confidenciales, las organizaciones pueden ajustar los LLM de código abierto y alojarlos en su propia infraestructura o VPC. La arquitectura incluye la anonimización de los datos, el ajuste preciso de las canalizaciones, los entornos de inferencia aislados y la supervisión y el control de acceso completos. Este patrón es común en la atención médica, las finanzas y la defensa.
Patrón híbrido en el borde de la nube
Este patrón, que surge en escenarios de IA perimetral, mantiene el LLM principal en la nube, pero traslada los modelos ligeros o la lógica de procesamiento rápido a los dispositivos periféricos. Reduce la latencia y el uso del ancho de banda y, al mismo tiempo, mantiene los datos confidenciales de forma local. Se usa cada vez más en experiencias móviles, de automoción y de IoT.
Estos patrones reflejan la flexibilidad y adaptabilidad de los LLMOP, y ofrecen vías para
El ecosistema de los LLMOP está creciendo rápidamente y no hay una sola herramienta que pueda cubrir todas las necesidades. Los equipos de alto rendimiento crean pilas modulares que se alinean con su infraestructura y sus flujos de trabajo. Como elemento central de muchos sistemas de nivel empresarial, TrueFoundry desempeña un papel fundamental al ofrecer soporte en todos los niveles de implementación, observabilidad, orquestación y automatización. A continuación se muestra un desglose de las capas clave y las herramientas que las impulsan.
1. Capa de datos e incrustación
Esta capa gestiona la limpieza, la transformación, la fragmentación y la incrustación de datos para la generación aumentada de recuperación (RAG). Permite a los LLM operar con conciencia contextual.
Estas herramientas permiten a los modelos extraer información relevante en el momento de la inferencia, lo que mejora la base fáctica y la calidad de los resultados.
2. Modelo de servidor e capa de inferencia
Esta es la columna vertebral de la pila de LLMOP. Incluye los componentes necesarios para alojar y ofrecer modelos de manera eficiente, administrar el uso de la GPU y escalar las API.
Esta capa garantiza que las respuestas de LLM se entreguen de forma rápida y rentable, incluso con tráfico de producción.
3. Capa de pronta y orquestación
Esta capa administra las plantillas de mensajes, los flujos de agentes y las interacciones dinámicas. Ayuda a enrutar la lógica y encadenar procesos de varios pasos dentro de las aplicaciones de LLM.
La orquestación rápida permite a los equipos controlar el comportamiento de los LLM en casos de uso empresarial complejos.
4. Nivel de monitoreo, retroalimentación y gobierno
La confiabilidad, la transparencia y la ética requieren sistemas sólidos de monitoreo y gobierno. Esta capa captura los resultados, los comentarios de los usuarios y las métricas de rendimiento.
5. Capa de flujo de trabajo y automatización
Esta última capa administra la capacitación, la evaluación, la automatización de la implementación y la CI/CD. Permite flujos de trabajo rastreables y repetibles que respaldan el desarrollo iterativo.
Estas herramientas, cuando se alinean entre capas, transforman los LLMOP de una experimentación dispersa en una disciplina de ingeniería escalable y repetible. En lugar de confiar en una única solución integral, los equipos modernos crean pilas componibles que se adaptan a sus necesidades de infraestructura, escala y cumplimiento.
La clave es la interoperabilidad, es decir, elegir herramientas que se integren sin problemas, automaticen las etapas clave y brinden transparencia durante todo el ciclo de vida del modelo. Con el paquete adecuado, los LLM pueden pasar de ser prototipos a sistemas de nivel de producción que generen resultados empresariales significativos.
Los LLMOps se están convirtiendo rápidamente en una disciplina fundamental para los equipos que crean aplicaciones impulsadas por modelos lingüísticos de gran tamaño. A medida que los LLM pasan del uso experimental a los sistemas críticos para la producción, las organizaciones necesitan una arquitectura estructurada, herramientas especializadas y flujos de trabajo repetibles para gestionar la complejidad, los costos y el rendimiento. Una arquitectura LLMoPS bien diseñada no solo acelera la implementación, sino que también garantiza la alineación ética, la gobernanza de los datos y la mejora continua a través de la retroalimentación.
Al adoptar herramientas modulares en las capas de administración, inferencia, orquestación y monitoreo de datos, los equipos obtienen flexibilidad y control sobre todos los aspectos del ciclo de vida de la LLM. Ya sea que utilices un modelo de código abierto o perfecciones uno propio, las prácticas escalables de LLMOP son la columna vertebral de los sistemas de IA sostenibles.
El futuro de los LLMOP radica en su capacidad para seguir el ritmo de la rápida evolución del modelo, los riesgos emergentes y la creciente demanda empresarial. Para las organizaciones que están preparadas para escalar de manera responsable, invertir en la arquitectura de los LLMOP ya no es opcional, sino una ventaja estratégica.
Una arquitectura LLMops es el marco estructural diseñado para administrar todo el ciclo de vida de los modelos de lenguaje de gran tamaño en un entorno de producción. Proporciona la infraestructura necesaria para la ingesta de datos, el rápido control de versiones y la orquestación de modelos, lo que permite que la IA pase de la simple experimentación a una implementación empresarial confiable. Esta arquitectura garantiza que las aplicaciones sigan siendo escalables, seguras y fáciles de mantener a medida que evolucionan.
Una arquitectura LLMops consta de varias capas críticas: bases de datos vectoriales para el contexto basado en RAG, sistemas de gestión rápida para el control de versiones y una puerta de enlace de IA centralizada para el servicio de modelos. Además, debe incluir módulos de observabilidad para hacer un seguimiento de la latencia y el uso de los tokens, además de canalizaciones para tareas especializadas. TrueFoundry unifica estos componentes en un único plano de control, lo que simplifica la complejidad de administrar una pila de IA fragmentada.
La principal diferencia en la arquitectura de LLMoPS es el cambio de flujos de trabajo con mucho entrenamiento a canalizaciones con mucha orquestación. Mientras que los MLOps tradicionales se centran en la creación de modelos personalizados y la ingeniería de funciones, los LLMOps priorizan la administración de modelos básicos previamente entrenados mediante la ingeniería rápida y la generación aumentada de recuperación (RAG). TrueFoundry proporciona una plataforma que admite ambos paradigmas, lo que permite a los equipos hacer la transición a la IA generativa sin abandonar los estándares operativos establecidos.
Las herramientas estándar dentro de una arquitectura LLMOps incluyen almacenes vectoriales como Pinecone o Weaviate, marcos de orquestación como LangChain y suites de monitoreo especializadas. Sin embargo, administrarlos como entidades independientes a menudo crea silos de integración. TrueFoundry funciona como una capa de orquestación integral que proporciona la infraestructura necesaria para gestionar las implementaciones de modelos, la rotación secreta y el enrutamiento rentable entre cualquier proveedor de nube.
TrueFoundry es una plataforma ideal para la arquitectura LLMOps porque proporciona un plano de control centrado en el desarrollador que se ejecuta de forma nativa dentro de su propio entorno de nube seguro. Abstrae la complejidad del aprovisionamiento de Kubernetes y de la infraestructura, a la vez que ofrece pasarelas de alto rendimiento y una gran capacidad de observación. Al mantener los datos dentro de su VPC y automatizar la optimización de los recursos, garantiza que la escalabilidad de la IA empresarial siga siendo segura y rentable.
La arquitectura de LLMops generalmente consta de varias capas: la capa de datos, la capa de modelo, la capa de aplicación y la capa de infraestructura. La capa de datos administra los conjuntos de datos, la capa modelo gestiona el entrenamiento o la inferencia, la capa de aplicación integra la IA en los productos y la capa de infraestructura admite la implementación, el escalado, la supervisión y la administración del sistema.
LLMOps incluye un control de versiones estructurado para solicitudes, modelos e iteraciones de ajuste fino. El control de versiones garantiza la reproducibilidad, facilita la reversión y permite la experimentación sin interrumpir los sistemas de producción. Los equipos pueden realizar un seguimiento de las mejoras, comparar el rendimiento de los modelos y mantener el cumplimiento de los requisitos normativos y de auditoría.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


