

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
La implementación de la IA generativa en Google Cloud Platform (GCP) requiere organizar un conjunto complejo de primitivas: Google Kubernetes Engine (GKE), TPU en la nube y Vertex AI. Si bien GCP proporciona la computación sin procesar, conectarla a una plataforma de desarrollo interno (IDP) que cumpla con las normas requiere una ingeniería personalizada sustancial.
TrueFoundry actúa como la superposición de la infraestructura. Nos encargamos de la organización, lo que le permite tener el control sobre la VPC y la residencia de los datos. En esta publicación, se detallan nuestros patrones de integración con GCP, específicamente en lo que respecta a la arquitectura de plano dividido Federación de identidades de carga de trabajoy administración de TPU.
Usamos una arquitectura de plano dividido para aislar la interfaz de administración de su entorno de ejecución de cargas de trabajo.
Límite de seguridad No exigimos reglas de firewall de entrada. El agente de su clúster inicia una transmisión WebSocket o gRPC segura y solo de salida a nuestro plano de control. Sondea los manifiestos de despliegue e impulsa la telemetría. Su VPC permanece privada frente al tráfico de entrada externo.
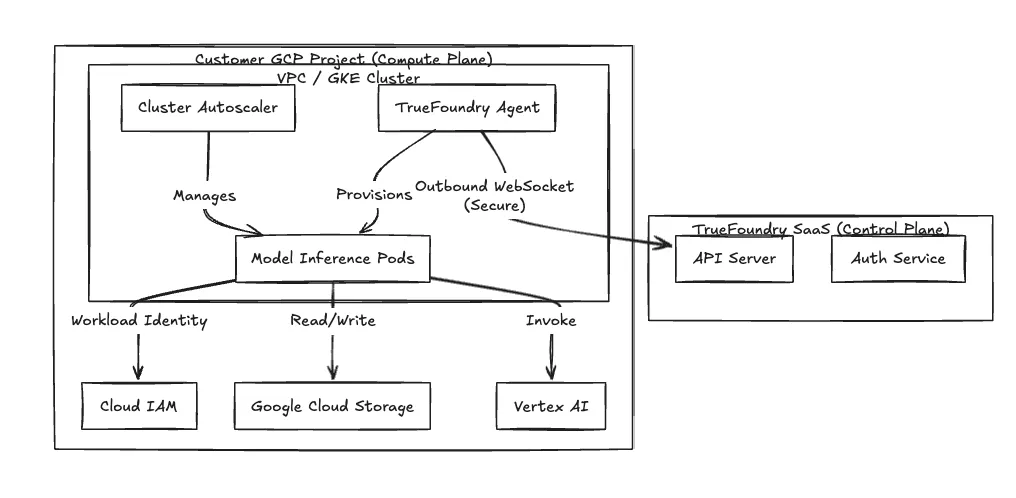
Figura 1: La arquitectura de plano dividido aísla el procesamiento de datos dentro de la VPC del cliente.
Para un alto rendimiento, configuramos el plano de procesamiento para usar Clústeres nativos de VPC usando IP de alias. Todos los recursos informáticos residen en subredes privadas.
Entrada (solicitudes de inferencia) El tráfico de aplicaciones entra en la VPC a través de Balance de carga en la nube (normalmente un ALB externo global). El ALB termina el TLS y reenvía las solicitudes al Puerta de enlace Istio Ingress que se ejecuta en el clúster de GKE.
Acceso privado a Google Para mantener el cumplimiento, el tráfico a las API de Google (Cloud Storage, Vertex AI) se dirige a través de Acceso privado a Google. Esto mantiene el tráfico entre los módulos de inferencia y los servicios gestionados por GCP en la red troncal de la red de Google, sin pasar por la Internet pública.
Salida Los nodos de trabajo de GKE requieren acceso saliente para extraer imágenes de contenedores desde Registro de artefactos. Enrutamos este tráfico NAT en la nube conectado a las subredes privadas.
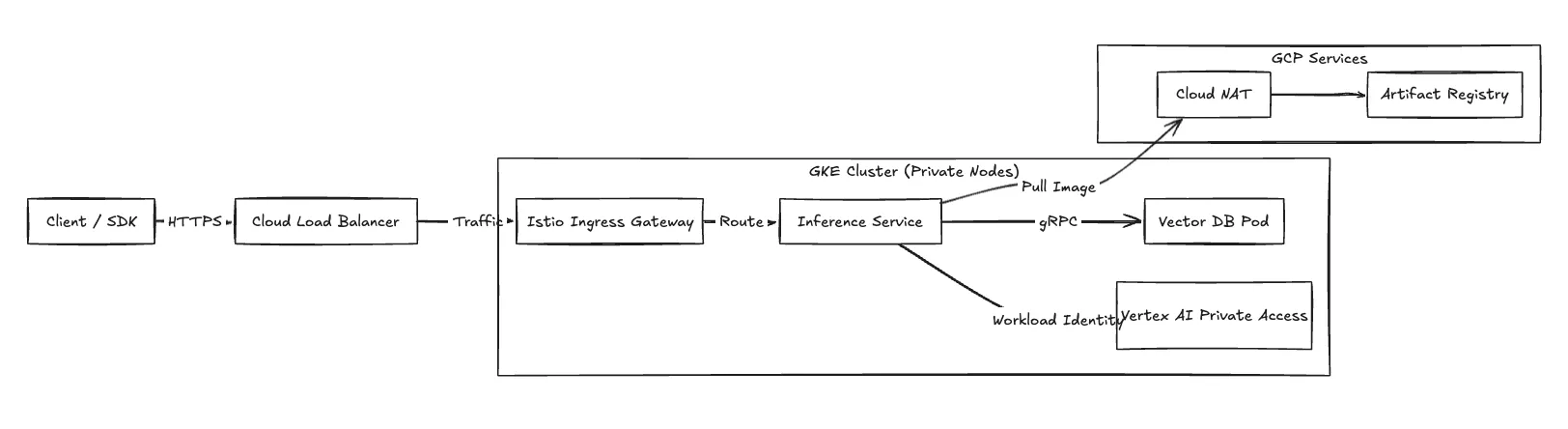
Figura 2: Flujo de tráfico de red que detalla la entrada y la conectividad privada.
Impulsamos la eliminación de las claves estáticas de las cuentas de servicio (archivos.json). TrueFoundry implementa Identidad de carga de trabajo de GKE para toda la autenticación de cargas de trabajo.
La secuencia de autenticación
Si una cápsula se ve comprometida, el radio de explosión se limita estrictamente a las funciones de IAM asignadas a esa GSA específica.
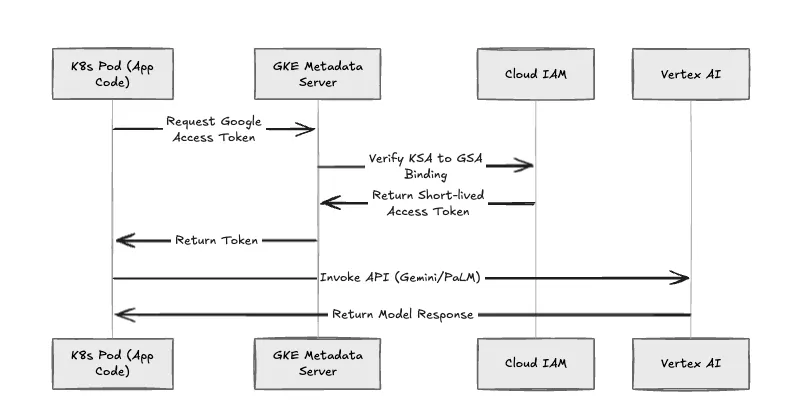
Figura 3: El flujo de autenticación de la identidad de carga de trabajo de GKE.
Nos integramos con Grupos de nodos de GKE para orquestar las GPU NVIDIA y las TPU en la nube.
Orquestación de TPU La programación en TPU requiere gestionar restricciones topológicas específicas. TrueFoundry administra el NodeSelector y las tolerancias necesarias para programar los pods en segmentos de TPU (p. ej., las versiones 4-8 y 5e). Introducimos automáticamente los controladores y los límites de recursos necesarios en el manifiesto de despliegue, con lo que extraemos la configuración de Kubernetes de bajo nivel.
Administración puntual de máquinas virtuales Para las cargas de trabajo de procesamiento o desarrollo por lotes, gestionamos Detecta máquinas virtuales para reducir los costos (normalmente entre un 60 y un 90% en comparación con bajo demanda).
Administrar claves distintas para modelos como Géminis Pro crea una sobrecarga operativa. TrueFoundry proporciona una puerta de enlace de IA que actúa como una interfaz API unificada.
Esta integración permite a tu equipo aprovechar al máximo las ventajas del hardware de GCP (en concreto, las TPU y las redes de alto rendimiento) sin verse atrapado en la fricción operativa que supone gestionar Kubernetes sin procesar. TrueFoundry actúa como un multiplicador de fuerza para tu infraestructura: eliminamos la complejidad de la organización de GKE y tú conservas la autoridad absoluta sobre la seguridad y la residencia de los datos. Este equilibrio te permite poner en funcionamiento las cargas de trabajo de GenAI de forma inmediata, lo que convierte la infraestructura de una limitación en una ventaja competitiva en velocidad.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


