

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Se trata de un hackatón de IA interno de su empresa, y el agente de codificación de un participante se queda atrapado en un ciclo de reintentos no deseados. Sigue enviando solicitudes de contexto prolongado a un modelo de alto coste durante horas.
Como los organizadores entregaron claves de proveedor sin procesar a todos los participantes, no hay controles a nivel de equipo sobre el gasto o la velocidad de las solicitudes. Para el lunes por la mañana, un flujo de trabajo descontrolado había consumido una gran parte del presupuesto compartido para la LLM y había llevado a la organización a tener que reducir las tasas.
Esa historia llega porque es verosímil. Pero la verdadera lección es más amplia: el patrón empresarial correcto para un hackathon no es distribuir credenciales de proveedor sin procesar y esperar que los equipos se comporten bien. Consiste en enviar todas las solicitudes a través de una pasarela controlada que puede separar a los equipos, adjuntar políticas a los metadatos y mantener la experimentación dentro de un modelo operativo controlado.
TrueFoundry se adapta perfectamente a ese patrón porque combina los límites del espacio de trabajo nativo de Kubernetes, la indirección secreta, los controles de políticas que reconocen los metadatos, las barreras de protección de los agentes y un campo de juego nativo de Gateway. La afirmación más precisa no es que garantice «cero filtraciones» o una contabilidad perfecta y estricta en cada patrón de ráfagas. La afirmación más sólida y defendible es que proporciona a los equipos de plataformas un plano de control creíble para organizar hackatones sin convertirlos en eventos de seguridad y costes no gestionados.

La primera regla de un hackathon seguro es simple: los participantes nunca deberían necesitar ver las claves de API del proveedor sin procesar. Una vez que una clave se copia en cuadernos, entornos locales o archivos de configuración de los agentes, se convierte en un problema de seguridad y de facturación.
El modelo de espacio de trabajo de TrueFoundry ayuda en este sentido porque el aislamiento del espacio de trabajo se asigna a los límites del espacio de nombres de Kubernetes. En la práctica, esto significa que las cargas de trabajo de un espacio de trabajo se ejecutan en un espacio de nombres diferente al de las cargas de trabajo de otro espacio de trabajo, y las credenciales de los proveedores se pueden exponer a través de grupos secretos y FQN secretos en lugar de pegarse directamente en los manifiestos de las aplicaciones o en los archivos fuente.
Esa es la arquitectura adecuada para los equipos de hackathon. Proporcione a cada equipo un espacio de trabajo, conceda a las cargas de trabajo acceso solo a los grupos secretos que necesitan y mantenga la credencial de proveedor real bajo el control de la plataforma en todo momento. La experiencia del usuario sigue siendo sencilla, pero el radio de explosión es menor y se puede auditar.
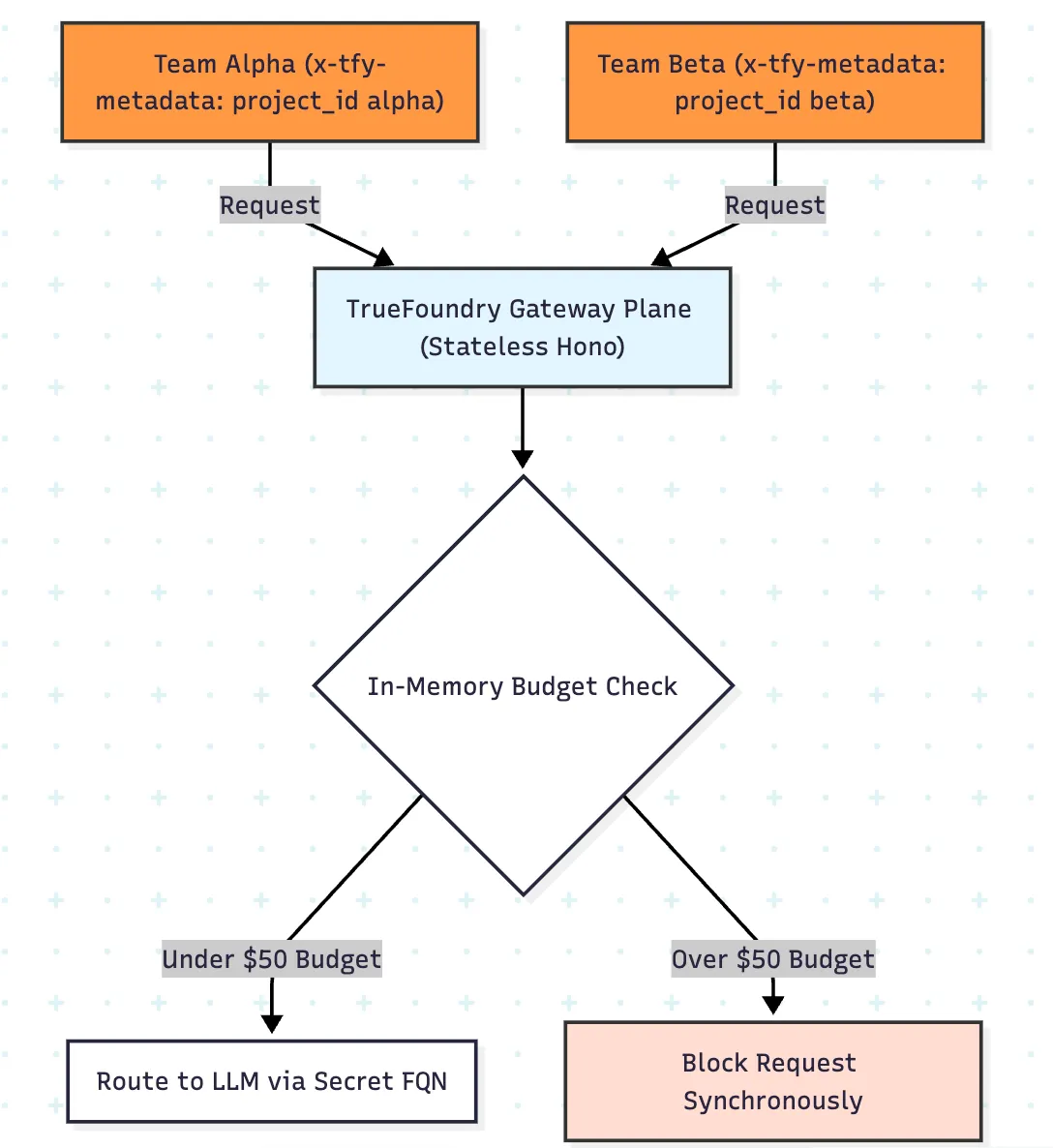
La pregunta operativa más importante en un hackatón de IA no es si se puede ver el gasto a posteriori. La cuestión es si la plataforma puede evaluar la política en la ruta de solicitud antes de que una carga de trabajo descontrolada se convierta en algo caro.
El plano de puerta de enlace de TrueFoundry evalúa la autenticación, el enrutamiento, las barreras, los límites de velocidad y la política presupuestaria en la ruta activa mediante el estado en memoria, lo que permite la aplicación de baja latencia antes de la invocación del modelo. Esto es considerablemente mejor que un diseño en el que la única visualización fiable de los costos se obtiene una vez que los registros se procesan posteriormente.
La parte especialmente útil para los hackatones es la determinación del alcance de los metadatos. En lugar de crear manualmente una regla por equipo, puedes adjuntar la identidad del equipo en x-tfy-metadata y aplicar la política de forma dinámica con campos como metadata.project_id. Esto significa que una regla presupuestaria y una regla de límite de velocidad pueden dividirse en contadores aislados y gastar sobres por equipo.
En los hackatones, los equipos prueban los servidores MCP, los agentes de llamada de herramientas, los conectores de bases de datos y las API internas de MCP. Ahí es exactamente donde un modelo de seguridad tradicional basado exclusivamente en la LLM comienza a fallar.
El modelo de barandilla de TrueFoundry es especialmente relevante aquí porque expone cuatro puntos de ejecución: entrada LLM, salida LLM, herramienta previa a MCP y herramienta posterior MCP. De este modo, los equipos de plataformas disponen de una forma más operativa de controlar a los agentes, en lugar de basarse en un único filtro genérico antes del modelo.
La distinción útil es que los diferentes riesgos aparecen en diferentes etapas. Es posible que aparezca una inyección inmediata al entrar. Los argumentos inseguros de la herramienta aparecen antes de la ejecución. Es posible que los registros confidenciales aparezcan solo después de que la herramienta regrese. El modelo de cuatro ganchos permite colocar el control correcto en el punto correcto del flujo.
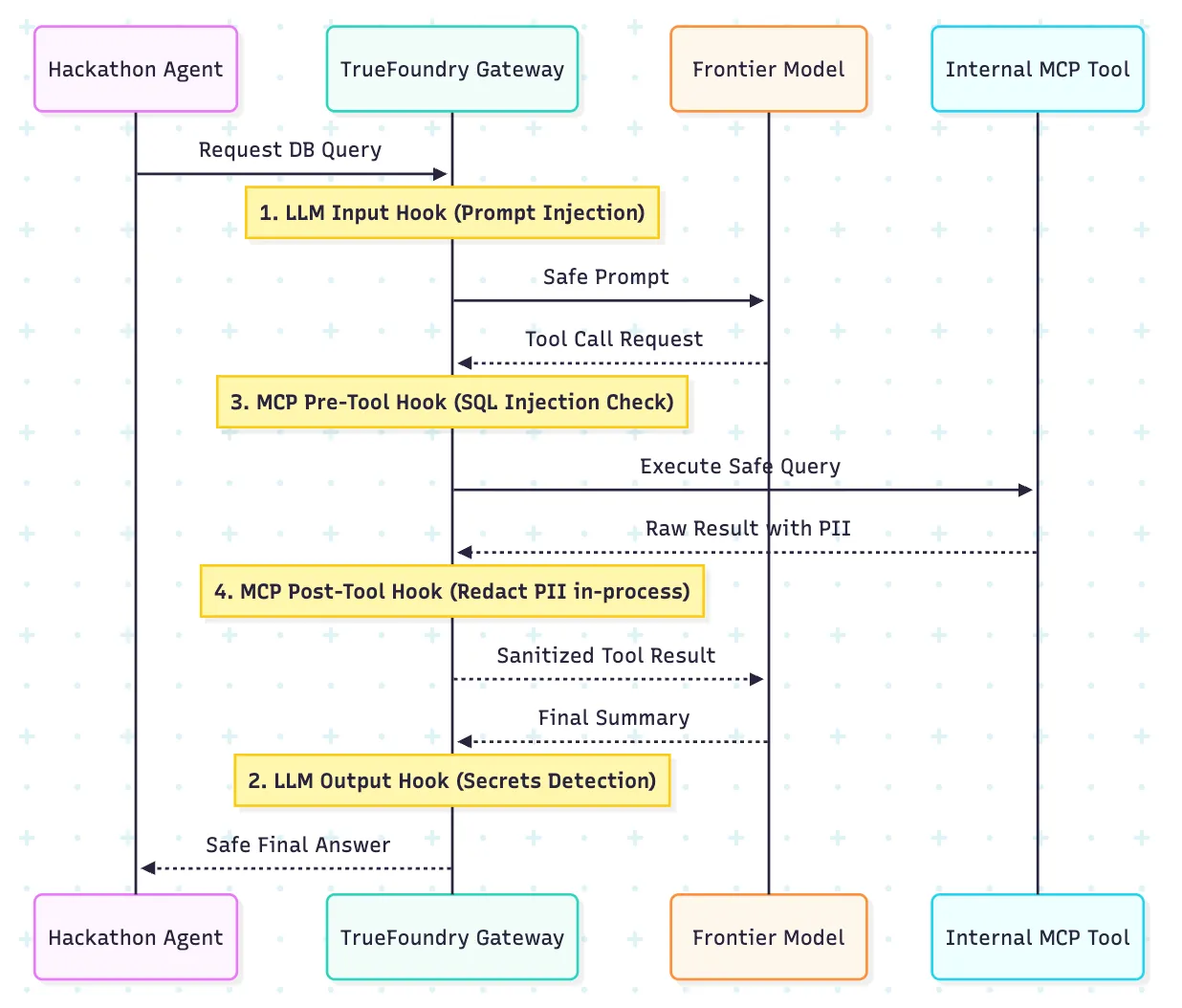
Aquí también es importante la detección durante el proceso. Si el análisis secreto y las comprobaciones relacionadas se pueden ejecutar dentro de la ruta de la puerta de enlace sin que se produzca una dependencia adicional con la salida, es más fácil razonar sobre el modelo de control durante un evento en directo. Mantén las barreras básicas comunes a todos los equipos y, a continuación, aplica políticas más estrictas para los equipos que utilizan herramientas o conjuntos de datos confidenciales.
Un hackathon seguro todavía tiene que parecer rápido. Si los equipos necesitan un ticket cada vez que quieren probar algo nuevo, recorrerán la plataforma. La respuesta no es tener menos control. La respuesta es hacer que la ruta controlada sea la más fácil.
Aquí es donde importa el patio de recreo nativo de Gateway. La ventaja arquitectónica es que el tráfico de prueba puede fluir a través del mismo plano de puerta de enlace utilizado para las políticas de producción, de modo que los equipos pueden validar las solicitudes, el enrutamiento y las barreras de seguridad de forma continua, en lugar de descubrir el comportamiento de las políticas solo después de la implementación.
La experiencia del desarrollador también mejora cuando la plataforma expone señales de depuración a nivel de respuesta. Los encabezados, como x-tfy-resolved-model y x-tfy-applied-configurations, junto con los desgloses de temporización de los servidores, ayudan a los equipos a comprender qué ocurrió realmente en una solicitud de prueba, en lugar de tener que adivinar si se ha activado una regla alternativa, de protección o de enrutamiento.
Los lectores empresariales rechazarán de inmediato si una publicación promete demasiado sobre la residencia de los datos. Deberían hacerlo. La afirmación útil no es que cada despliegue sea como por arte de magia. Lo que pasa es que el diseño de planos divididos permite a los equipos gestionar el plano de acceso en su propia infraestructura y, al mismo tiempo, mantener la vía rápida para la inferencia, la verificación de políticas y el acceso a los modelos bajo un control operativo más estricto.
La otra mitad de la historia es la observabilidad. Un hackathon es más fácil de gestionar cuando el equipo de la plataforma puede ver rápidamente los rastros, la latencia y el comportamiento de las políticas. Sin embargo, la observabilidad también es una superficie de gobernanza de datos. Si se exportan datos de pronósticos o respuestas para su análisis, debe ser una elección intencionada con los controles de retención y destino adecuados.
La historia de la residencia se fortalece cuando se describen de forma explícita el modo de implementación, el comportamiento del registro y las rutas de exportación. Eso genera más confianza que decir «cero filtraciones» y esperar que el lector no haga preguntas complementarias.
Sí, añadir un flujo de trabajo de propietario explícito es una buena idea. Convierte la publicación de un comentario sobre arquitectura en una guía de ejecución.
1. Una semana antes del evento: defina el modelo de control
Crea un espacio de trabajo por equipo o por pista de competición. Decide los modelos permitidos, la ruta de proveedores predeterminada, el presupuesto por equipo, el límite de tarifas por equipo y qué equipos pueden usar las herramientas del MCP o los datos internos confidenciales.
2. Antes del inicio: precarga la ruta segura
Publica un pequeño kit de inicio para los participantes: el punto final de la puerta de enlace, la forma de metadatos requerida, ejemplos de fragmentos del SDK y una breve guía del campo de juego. Los equipos deben empezar por la ruta regulada, no desde los paneles de control de los proveedores sin procesar.
3. Al registrarse: asigna un project_id a cada equipo
Haga que project_id sea el campo de metadatos obligatorio desde el primer día. Esto permite una segmentación limpia del gasto, un seguimiento más limpio, una revisión de incidentes más limpia y una menor necesidad de mapeo manual en el futuro.
4. Durante las horas de construcción: supervise el evento como si fuera un sistema en vivo
Observe el gasto a nivel de equipo, la presión por los límites de velocidad y los patrones de rastreo inusuales. El objetivo es rescatar a los equipos desde el principio, no solo analizar las fallas más adelante.
5. Para los equipos de agentes: es necesario revisar las herramientas antes de tener un acceso amplio
Si un equipo quiere acceder a la base de datos, a los servidores MCP o a las API internas, muévalos a un perfil de protección más estricto antes de habilitar esas herramientas. Los experimentos con los agentes deberían convertirse en algo que genere más confianza, no empezar por ahí.
6. Antes de las demostraciones: forzar un pase final al patio de recreo
Haga que cada equipo valide su recorrido final por el patio de recreo o la superficie de prueba oficial. De este modo, se detectan los metadatos faltantes, las rutas inesperadas y las sorpresas inesperadas antes de la hora de la demostración.
7. Después del evento: convierta las observaciones en valores predeterminados de la plataforma
Revisa los rastreos, los incidentes presupuestarios, las llamadas bloqueadas y las preguntas de soporte. A continuación, convierte las prácticas recomendadas en plantillas de espacio de trabajo, fragmentos y líneas base de políticas predeterminadas para el próximo hackathon.
La tesis central de la publicación original sigue siendo válida: si estás organizando un hackathon de IA empresarial, el patrón más seguro es no entregar claves de proveedor sin procesar. Se trata de enviar las solicitudes a través de una pasarela que puede separar a los equipos, medir los gastos, controlar el rendimiento y controlar los flujos de trabajo de los agentes.
Lo que hace que la versión revisada sea mejor es que dice esto de una manera que un comprador escéptico puede creer. La historia más sólida de TrueFoundry sobre un hackatón no es una vaga promesa de seguridad total. Es una combinación práctica de aislamiento del espacio de trabajo, indireccionamiento secreto, políticas basadas en metadatos, enlaces de agentes controlados, controles de rutas de solicitud y un campo de juego que ayuda a los equipos a realizar pruebas en la misma superficie política por la que van a trabajar.
Con eso basta. Sus hackers aún pueden construir el futuro. Sus equipos de plataforma, seguridad y finanzas no tienen por qué perder ni un fin de semana en el proceso.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


