

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 26, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Las herramientas de codificación de IA ahora forman parte del desarrollo diario. Los desarrolladores utilizan productos como Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code y Goose para generar código, refactorizar, depurar y explicar grandes bases de código directamente desde el editor o la terminal. El problema en la mayoría de las empresas no es la adopción. El problema es la gobernanza. Cada herramienta puede comunicarse con uno o más proveedores de modelos. Cada herramienta suele almacenar las claves de forma local. Los equipos acaban rápidamente con docenas de puntos de entrada no gestionados a modelos externos. Esto crea un riesgo real en torno a qué modelos se aprueban, a dónde se envían el código y el contexto, cómo se atribuyen los gastos y cómo se investigan los incidentes. También dificulta la confiabilidad porque el enrutamiento y las alternativas son inconsistentes entre las distintas herramientas.
Si intentas resolver esto manualmente, normalmente terminas creando un proxy interno al que apuntan todos los IDE y CLI. Ese proxy necesita autenticación, autorización, listas de modelos permitidos aprobados, enrutamiento de proveedores, registros de auditoría, límites de velocidad, controles presupuestarios y capacidad de observación. También debe ser compatible con las API que esperan estas herramientas. Muchas herramientas utilizan una API compatible con OpenAI, pero también tienen peculiaridades en lo que respecta a la denominación de los modelos y a los comportamientos especiales que debes gestionar.
He aquí un pequeño ejemplo ficticio que muestra por qué esto se convierte en un verdadero trabajo de ingeniería. No está listo para la producción. Su único objetivo es mostrar la forma del problema.
desde fastapi import, FastApi, Request, HttpException
hora de importación
importar httpx
aplicación = fastAPI ()
MODELOS_APROBADOS = {
«gpt-4o»: {"proveedor»: «openai», «destino»: «gpt-4o"},
«claude-3-5-sonnet»: {"proveedor»: «antrópico», «objetivo»: «claude-3-5-sonnet"},
}
OPENAI_URL = "https://api.openai.com/v1/chat/completions»
URL ANTRÓPICA = "https://api.anthropic.com/v1/messages»
def verify_token (auth_header: str) -> dict:
# En realidad, se trata de una validación de JWT contra Okta o tu IdP.
si no es auth_header o auth_header.startswith («Bearer «):
generar HttpException (status_code=401, detail="token faltante»)
return {"usuario»: «alice», «equipo»: «plataforma"}
@app .post («/v1/chat/terminaciones»)
definición asíncrona chat_completions (requisito: solicitud):
user_ctx = verify_token (req.headers.get («autorización»))
body = wait req.json ()
modelo = body.get («modelo»)
si el modelo no está en APPROVED_MODELS:
generar HttpException (status_code=403, detail="modelo no aprobado»)
ruta = APPROVED_MODELS [modelo]
iniciado = time.time ()
asincrónico con Httpx.AsyncClient (timeout=60) como cliente:
si route ["provider"] == «openai»:
upstream = wait client.post (
ABRIR AI_URL,
headers= {"Autorización»: «Portador" + «UPSTREAM_OPENAI_KEY"},
json= {**body, «model»: ruta ["objetivo"]},
)
otra cosa:
# Aquí también necesitará transformaciones de solicitud y respuesta.
upstream = wait client.post (
URL ANTROPICA,
headers= {"x-api-key»: «UPSTREAM_ANTHROPIC_KEY"},
json= {"model»: route ["target"], «messages»: body.get («messages», [])},
)
latency_ms = int (time.time () - iniciado) * 1000)
# En realidad, emitirías trazas de OpenTelemetry y registros estructurados aquí.
print («llm_request», {"usuario»: user_ctx ["usuario"], «modelo»: modelo, «latency_ms»: latency_ms})
devolver upstream.json ()
Incluso en esta versión simplificada puedes ver las piezas que faltan. Sigues necesitando transformaciones sólidas entre los distintos proveedores, soporte de streaming, reintentos, alternativas, acceso seguro a los encabezados, análisis del alcance de los inquilinos y equipos y registros de auditoría duraderos. También necesitas un sistema de configuración que se adapte a todos los equipos.
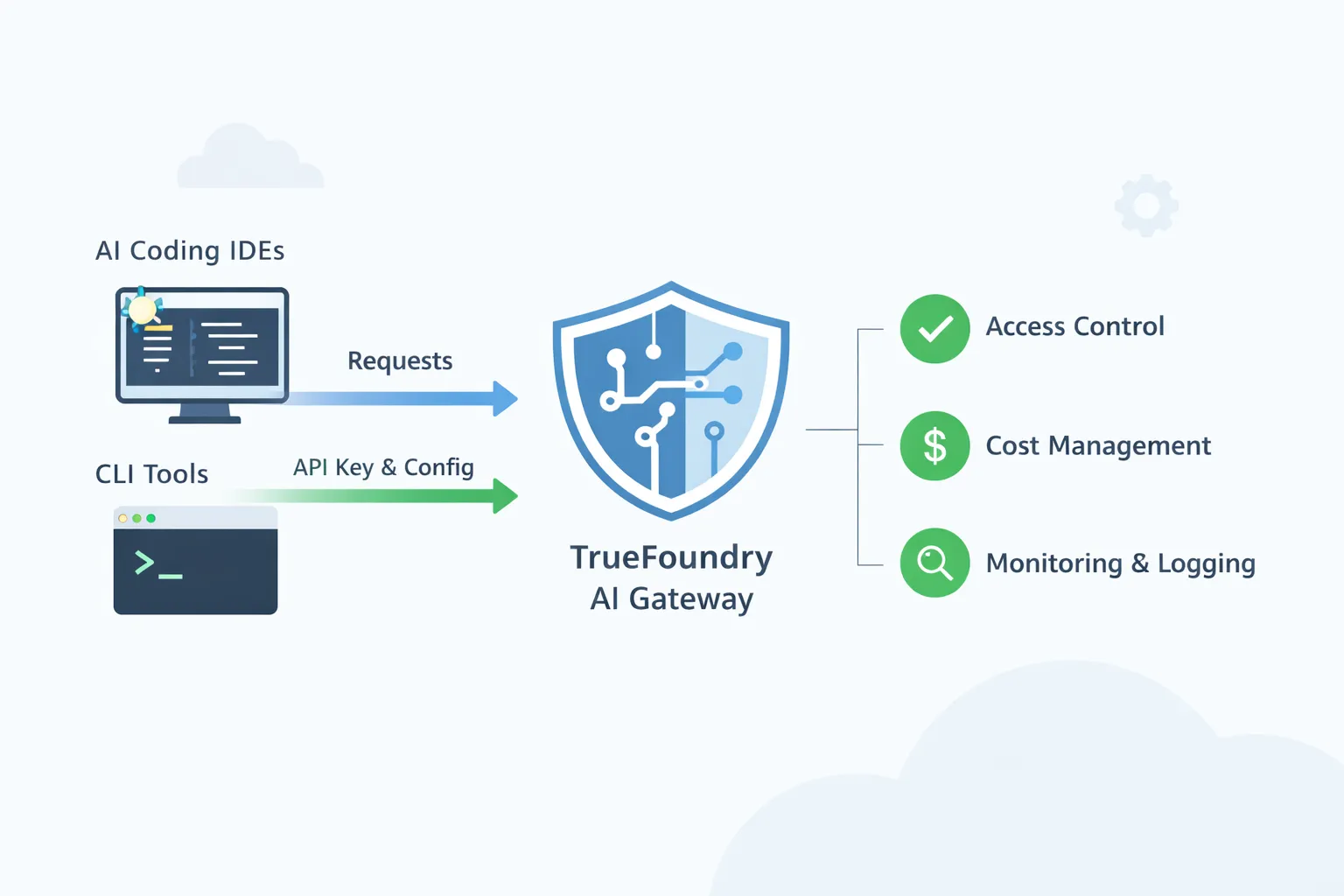
TrueFoundry AI Gateway está diseñado para ser ese punto de control compartido. Los IDE y las CLI siguen utilizando los flujos de trabajo que ya les gustan a los desarrolladores, pero el tráfico se dirige a través de una única puerta de enlace gobernada. La pasarela se convierte en el lugar donde los equipos de la plataforma hacen cumplir los modelos de acceso aprobados, aplican políticas y obtienen una visibilidad total del uso.
Un tema central en las guías del IDE es simple. La URL base y el nombre del modelo se extraen del área de juegos de TrueFoundry AI Gateway. Luego, configuras el IDE o la CLI para usar esa URL base y un token de TrueFoundry.
La mayoría de los IDE de codificación de IA y las herramientas de escritorio pueden apuntar a un único punto final compatible con OpenAI. El TrueFoundry AI Gateway le ofrece ese punto final. Empiezas en el patio de juegos de Gateway y copias el fragmento unificado. Este fragmento le proporciona la URL base y el nombre del modelo que debe usar. A continuación, abre la configuración del IDE y selecciona una opción de proveedor que admita una URL base personalizada. Muchas herramientas consideran que esto es compatible con OpenAI. Se pega la URL base de Gateway. Pegas un token de TrueFoundry como clave de API. El token puede ser un token personal para un desarrollador o un token de cuenta virtual para uso compartido o automatizado. TrueFoundry documenta ambas opciones y recomienda el token de la cuenta virtual para su uso en producción. Lea más aquí
Algunos IDE funcionan mejor cuando ven nombres de modelos estándar cortos, como gpt 4o. Los nombres de los modelos de TrueFoundry suelen estar totalmente cualificados. La solución recomendada es definir una regla de enrutamiento o equilibrio de carga en la puerta de enlace para que el IDE siga usando el nombre abreviado mientras la puerta de enlace lo asigna al modelo objetivo totalmente cualificado. Tanto Cursor como Codex documentan este patrón porque tienen una lógica interna vinculada a los nombres de los modelos estándar. Cursor-docs
También puede haber restricciones de red. Cursor documenta que su flujo de solicitudes puede involucrar a los servidores de Cursor. Esto significa que la URL de la puerta de enlace debe ser accesible desde la infraestructura de Cursor. En la práctica, el punto final de Gateway necesita estar accesible al público para que Cursor funcione como se describe en la guía.
Las herramientas de CLI suelen integrarse mediante variables de entorno o un archivo de configuración local. En el caso de las CLI compatibles con OpenAI, el patrón común es establecer OPENAI_BASE_URL en el punto final de TrueFoundry Gateway y configurar OPENAI_API_KEY en un token de TrueFoundry. TrueFoundry documenta esto como un enfoque de autenticación compatible para el Gateway. Leer más: Autenticación
Algunas CLI utilizan variables específicas del proveedor. La CLI de Gemini usa una URL base de Gemini y una clave de API de Gemini. La guía de TrueFoundry muestra cómo configurar GOOGLE_GEMINI_BASE_URL en una URL proxy de TrueFoundry en Gemini y cómo configurar GEMINI_API_KEY como un token de TrueFoundry para que todas las solicitudes fluyan a través de la puerta de enlace. Leer más: Gemini-CLI
Otras CLI se basan en un archivo json de configuración. Claude Code se configura mediante un archivo settings.json que establece los valores env para la URL base y los encabezados de autenticación. La guía de TrueFoundry muestra a ANTHROPIC_BASE_URL apuntando a la puerta de enlace y utiliza un token de portador en los encabezados personalizados para que el tráfico de Claude Code se controle a través de la puerta de enlace. Más información: Código Claude
Algunas herramientas también necesitan el mapeo de nombres estándar mencionado anteriormente. En la guía de la CLI del Codex se explica que el Codex espera utilizar nombres de modelos estándar y que puede comportarse mal con nombres totalmente cualificados. Se recomienda utilizar el enrutamiento Gateway para llamar al gpt 5 de la CLI mientras el Gateway se dirige al modelo correcto y totalmente cualificado entre bastidores. Leer más: Codex
La aprobación de modelos y el control de acceso son las necesidades de gobierno más básicas cuando las herramientas de codificación de IA se extienden por toda la empresa. Un desarrollador puede instalar Cursor o Cline en cuestión de minutos y dirigirlo a cualquier proveedor de modelos. Sin una puerta de enlace, la empresa termina con muchas rutas no gestionadas en las que el código, el contexto y las indicaciones pueden salir de la red utilizando claves personales. Con TrueFoundry AI Gateway, se crea un pequeño catálogo aprobado de modelos que se permite el uso de la codificación y se asignan esos modelos a equipos o grupos de usuarios. Los desarrolladores siguen usando el mismo IDE que prefieren, pero todas las solicitudes pasan por la pasarela, por lo que se bloquea la solicitud a un modelo no aprobado. Esto también permite separar el acceso por nivel de riesgo. Un ingeniero junior puede tener acceso a un modelo más económico para realizar ediciones rápidas, mientras que un ingeniero de plantilla o un equipo de incidentes de producción pueden acceder a un modelo más sólido para realizar tareas de depuración difíciles. Lo importante es que la aprobación se aplique de forma centralizada, en lugar de depender de que cada desarrollador siga un documento de política.
La propiedad de los costos se vuelve importante porque las herramientas de codificación de IA pueden generar grandes volúmenes de tokens sin que nadie se dé cuenta. Un solo desarrollador que utilice un agente que repita en una base de código puede crear cientos o miles de llamadas en un período breve. Sin una pasarela, el gasto se distribuye entre las claves personales y las cuentas de los proveedores, por lo que el departamento de finanzas recibe una factura, pero no puede ver qué equipo o aplicación la ha generado. Con una puerta de enlace, puede emitir tokens basados en la identidad y requerir que cada sesión de IDE o CLI se autentique mediante una identidad de usuario o de servicio. Esto le permite atribuir el uso a una persona, un equipo o una herramienta interna. Una vez que existe la atribución, los controles se vuelven prácticos. Puedes establecer presupuestos para un equipo para un mes y puedes establecer límites de velocidad para evitar que se produzcan bucles descontrolados y accidentales. Si una herramienta empieza a enviar solicitudes de spam, la pasarela puede limitarla en lugar de dejar que consuma el presupuesto de forma silenciosa.
La respuesta a los incidentes y la auditoría es donde los equipos de la plataforma sienten la diferencia día a día. Cuando un desarrollador dice que el asistente es lento o está fallando, es difícil depurarlo si el tráfico va directamente de un portátil a un proveedor. Es posible que no sepas si el problema es el proveedor, la red, un nombre de modelo mal configurado o una configuración específica de la herramienta. Cuando las solicitudes pasan por la puerta de enlace, el equipo de la plataforma puede consultar las métricas y los registros de la puerta de enlace para ver qué modelo se llamó, cuál era la latencia, qué errores se produjeron y si los errores se han producido solo en un proveedor o en una región. Esta es también la base de los requisitos de auditoría. Los equipos de seguridad y cumplimiento suelen preguntar a dónde se envió el contexto del código y quién tuvo acceso. Una puerta de enlace puede mantener un registro de los destinos que se utilizaron y quién los invocó. También puede respaldar políticas que reducen el riesgo, como ocultar cadenas confidenciales antes de que las solicitudes lleguen a proveedores externos o impedir que ciertos equipos envíen mensajes a puntos finales externos.
La confiabilidad durante los problemas con los proveedores es importante porque los proveedores de modelos tienen ralentizaciones y tiempos de espera periódicos. Las herramientas de codificación de IA son particularmente delicadas porque son interactivas. Unos pocos tiempos de espera pueden hacer que la herramienta parezca estropeada y que los desarrolladores cambien a la que funcione. Muchos IDE también asumen ciertos nombres de modelos. El cursor y herramientas similares suelen funcionar mejor cuando el nombre del modelo se parece a un nombre de estilo OpenAI estándar. Si cambias de proveedor, normalmente necesitarás cambiar la configuración de cada desarrollador. Con el enrutamiento por puerta de enlace, puedes mantener el mismo nombre de modelo en la configuración del IDE y cambiar lo que se asigna entre bastidores. Si un proveedor está agotando el tiempo de espera, puedes dirigirte a otro proveedor o a otra cuenta o región. El desarrollador sigue usando la misma configuración de IDE y simplemente ve que la herramienta sigue funcionando. Esto también es útil cuando quieres implementar un modelo nuevo. Puedes cambiar gradualmente el tráfico hacia el nuevo modelo y, al mismo tiempo, mantener estable la experiencia del usuario, y puedes revertirlo rápidamente si la calidad o la latencia no son aceptables.
Los IDE de codificación con IA hacen que los desarrolladores sean más rápidos. Las empresas necesitan el mismo nivel de gobierno que ya aplican a los sistemas de CI y control de código fuente. El camino práctico consiste en centralizar el control sin obligar a los desarrolladores a cambiar de herramienta. TrueFoundry AI Gateway está diseñado para ubicarse en ese punto de control. Todas las guías de integración de Claude Code, Cline, Cursor, Gemini CLI, OpenAI Codex CLI, Qwen Code CLI, Roo Code y Goose siguen el mismo principio. Mantén el flujo de trabajo de los desarrolladores. Centralice las políticas, la visibilidad y el control en la puerta de enlace.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


