Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.
9,9
GenAI como servicio para empresas
Published: April 22, 2026
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Gestiona más de 350 RPS en solo 1 vCPU, sin necesidad de ajustes
Listo para la producción con soporte empresarial completo
Para los ingenieros de plataformas, GenAI as a Service significa crear un sistema que permita a diferentes equipos (científicos de datos, desarrolladores de aplicaciones y usuarios empresariales) acceder, implementar y experimentar sin problemas con modelos de IA sin preocuparse por los cuellos de botella operativos y de infraestructura.
Si bien la idea de GenAI parece emocionante, la realidad es que los equipos de plataformas están sometidos a una enorme presión para ofrecer una infraestructura de IA escalable, rentable y segura. Se enfrentan a plazos ajustados, a necesidades empresariales en constante evolución y a modelos de IA que cambian rápidamente, lo que convierte el despliegue de GenAI en un objetivo en constante cambio.
El desafío principal: la proliferación de modelos y la complejidad de la infraestructura
Uno de los mayores quebraderos de cabeza para los equipos de plataformas es que los modelos se están convirtiendo en una mercancía. Cada pocas semanas, se lanzan nuevos y mejorados LLM, modelos de integración, cambios de clasificación, etc. Los equipos empresariales quieren integrarlos de inmediato, pero esto supone una pesadilla para la planificación de infraestructuras.
¿Cómo se intercambian y se intercambian los LLM sin interrumpir las aplicaciones existentes?
¿Cómo se asegura de que los diferentes equipos tengan acceso al modelo correcto sin duplicar sus esfuerzos?
¿Cómo se mantienen los modelos funcionando de forma rentable cuando los recursos de la GPU son limitados?
Las empresas necesitan un sistema centralizado que resuma estas complejidades y permita a los equipos consumir servicios de IA sin dañar la infraestructura.
Desafíos en la operacionalización de GenAI como servicio
Ready to Build With GenAI? Start With TrueFoundry.
TrueFoundry gives you everything you need to build, deploy, and scale generative AI applications across open and closed-source models. From a unified API layer and prompt management to full observability and self-hosted deployment, it’s the enterprise-grade GenAIaaS platform built for developers.
La implementación interna de modelos GenAI es mucho más compleja que la ejecución de una aplicación de software estándar -
Soporte para diversos modelos
Soporte para varios modelos de código abierto (por ejemplo, Llama) y modelos de API patentadas (por ejemplo, OpenAI, Anthropic).
Las empresas deben admitir varios modelos, como modelos de incrustación, cambio de posición, etc., para diferentes tareas.
Implementación local y en múltiples nubes: Las empresas necesitan flexibilidad para implementar modelos en todos los proveedores de la nube (AWS, GCP, Azure) o en las instalaciones en función del costo, el cumplimiento y la disponibilidad de la GPU
La orquestación de la GPU no es trivial: Kubernetes, Ray y Slurm suelen ser necesarios para asignar las GPU de forma dinámica. Además, cambiar de proveedor (por ejemplo, de AWS A100 a GCP TPU) requiere un trabajo personalizado.
Contenerización y orquestación: Sin la contenedorización de los modelos, los equipos luchan contra los desajustes de dependencia, los conflictos de software y los problemas de control de versiones. También proporciona beneficios adicionales como el escalado automático, la programación de la GPU, la tolerancia a fallos, etc., que son muy importantes en el entorno de producción.
Implementación en diferentes configuraciones de infraestructura: Algunas cargas de trabajo requieren una latencia ultrabaja para la producción, mientras que el desarrollo y la experimentación pueden tolerar latencias más altas. Ejemplo: Es posible que una empresa necesite dos instancias diferentes de Llama: una que se ejecute de manera eficiente en las GPU T4 o A10G para garantizar la rentabilidad, y otra que se ejecute en las GPU H100 para aplicaciones de alta prioridad y sensibles a la latencia.
Integración con registros modelo: Las organizaciones suelen mantener varios registros de modelos (por ejemplo, MLFlow, SageMaker, Hugging Face), lo que requiere una integración perfecta para el control de versiones y la auditoría.
Manejo de modelos ajustados: Los científicos de datos con frecuencia ajustan los modelos, y los equipos de plataforma deben garantizar que estos modelos se implementen de manera eficiente y segura.
2. Permitir una inferencia segura y escalable
Una vez implementados, el desafío pasa a hacer que estos modelos estén disponibles para la inferencia en varias aplicaciones empresariales.
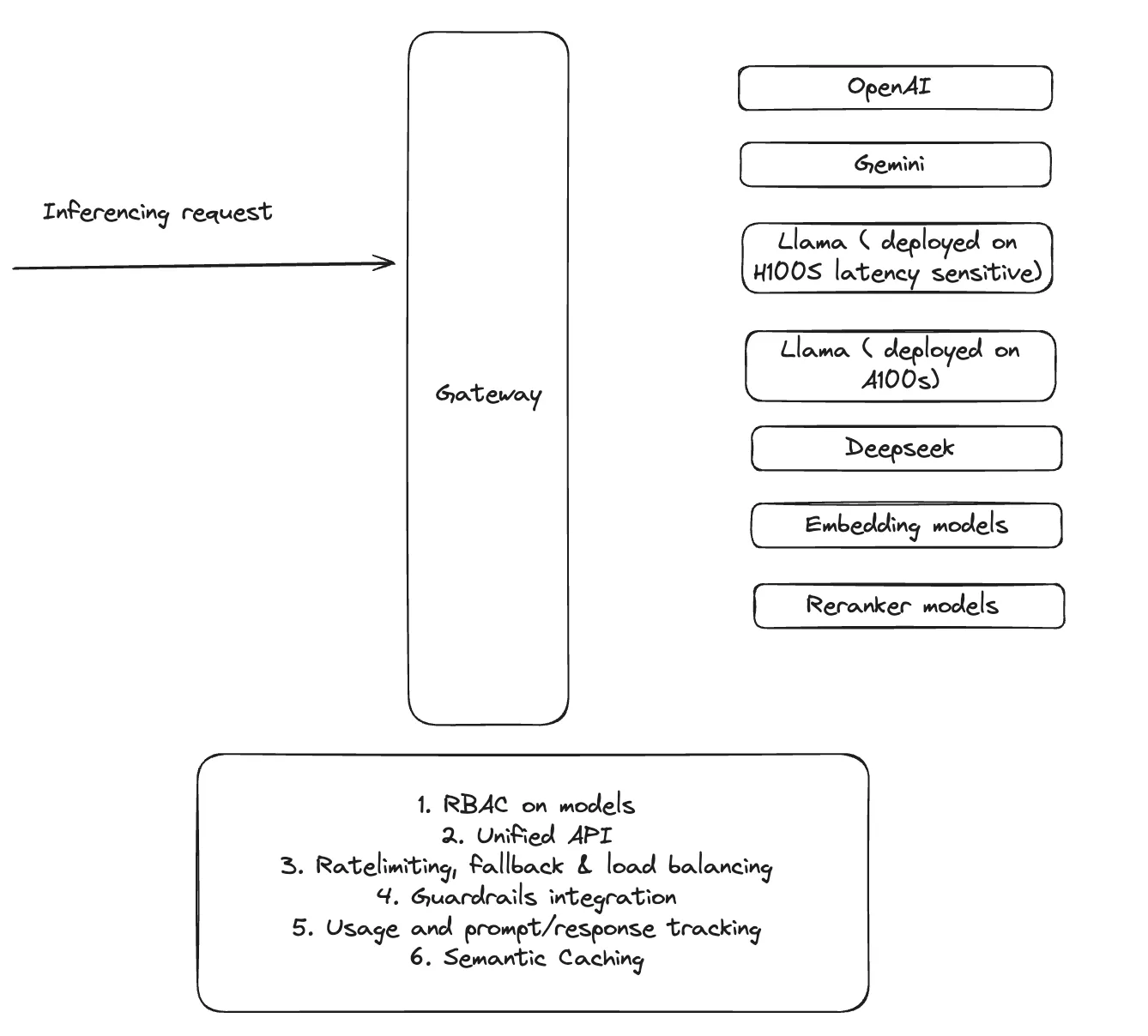
Control de acceso en modelos: Definir el RBAC (control de acceso basado en roles) para administrar el acceso al modelo en función de los equipos o los usuarios
APIs y estandarización: Permitir a los equipos crear fácilmente puntos finales de inferencia e intercambiar o intercambiar varios LLM a través de un portal de autoservicio.
Cuotas personalizadas y limitación de tasas: Definir cuotas de uso del modelo a nivel de usuario, equipo u organización para garantizar una asignación justa de los recursos.
Mecanismos de conmutación por error: Implementar soluciones alternativas para evitar interrupciones en la producción, como el cambio automático a otro proveedor de modelos (por ejemplo, OpenAI a un modelo alternativo).
Almacenamiento en caché semántico: Aprovechar las estrategias de almacenamiento en caché para garantizar que las consultas similares no requieran computación redundante, lo que mejora la eficiencia.
Observabilidad del uso del modelo: Capturar todas las solicitudes de los usuarios, las respuestas de los modelos y las llamadas a la API para la gobernanza, la depuración y la facturación.
3. Observabilidad y gobernanza
Los modelos GenAI no son estáticos; necesitan evaluación y mejora continuas. Los equipos de plataformas tienen dificultades para:
Información sobre la disponibilidad y el uso de la GPU: Ofrecer transparencia en la utilización de la GPU para optimizar la asignación de recursos.
Registro y depuración: Capturar todas las métricas de uso, incluidas las solicitudes de los usuarios y los resultados del modelo, para un mejor seguimiento y análisis.
Evaluación comparativa de LLM: Proporcionar datos empíricos sobre el rendimiento de la LLM para garantizar que los modelos elegidos cumplan con los estándares de calidad y confiabilidad deseados de la empresa.
Barandas de seguridad: Integración con barreras predefinidas o personalizadas para evitar la exposición de datos de PII y otra información confidencial
Complejidad de administración de claves: La administración de las claves, los secretos y la autenticación de las API en diferentes entornos de nube aumenta los riesgos de seguridad y la sobrecarga operativa.
Cómo TrueFoundry habilita GenAI como servicio
TrueFoundry proporciona una plataforma de infraestructura de IA de extremo a extremo que simplifica la implementación, la inferencia y la gobernanza de los modelos, lo que permite a los equipos de la plataforma centrarse en la escalabilidad, la eficiencia y la seguridad en lugar de en los cuellos de botella de la infraestructura.
La plataforma todo en uno para despliegues unificados
TrueFoundry ofrece una plataforma de IA nativa de Kubernetes que automatiza la implementación de modelos y la administración de la infraestructura, eliminando la necesidad de una configuración manual.
Soporte local o entre nubes: con el soporte local y multinube, las empresas pueden implementar modelos en AWS, GCP, Azure o centros de datos privados sin gastos operativos adicionales.
Soporta la implementación de modelos en diversos marcos, tipos y servidores de modelos. También admite la implementación de modelos embebidos y reclasificados.
La plataforma selecciona automáticamente la mejor configuración de implementación de Kubernetes en función de la arquitectura del modelo, la disponibilidad de la GPU y los requisitos de rendimiento.
TrueFoundry también optimiza la infraestructura al proporcionar capacidades de escalado automático que reducen el tiempo de escalado del modelo entre 3 y 5 veces, lo que reduce significativamente los retrasos en el arranque en frío.
También admite funciones avanzadas como la transmisión de imágenes, el enrutamiento fijo para los LLM y las recomendaciones inteligentes de GPU
Además, TrueFoundry permite la implementación de modelos de autoservicio, lo que permite a los científicos de datos implementar modelos sin la experiencia de Kubernetes, lo que reduce la dependencia de los ingenieros de plataforma y acelera la adopción de la IA en todos los equipos.
Soporte completo de Gitops para facilitar la vida de los equipos de la plataforma
Inferencia de modelos unificada y escalable
TrueFoundry simplifica la inferencia de modelos al proporcionar una puerta de enlace de IA centralizada, lo que garantiza un acceso sin problemas a los modelos en diferentes entornos de nube.
Con una sola API, los equipos de plataforma pueden gestionar modelos de código abierto (Llama), soluciones comerciales (OpenAI, Bedrock, Mistral) y modelos empresariales ajustados. Esta unificación garantiza experiencias de inferencia coherentes en todos los flujos de trabajo.
También admite la limitación de velocidad para garantizar las cuotas entre usuarios, equipos y modelos, el equilibrio de carga y la conmutación por error automatizada para evitar interrupciones. En caso de interrupciones del servicio o degradación del rendimiento, los modelos pueden recurrir sin problemas a proveedores alternativos sin intervención manual.
Además, el almacenamiento en caché semántico reduce los cálculos redundantes, lo que optimiza el tiempo de respuesta y reduce los costos operativos.
TrueFoundry también integra de forma nativa modelos de reposición e incrustación, lo que facilita la creación de la generación aumentada por recuperación (RAG), un caso de uso común
Observabilidad, seguridad y gobernanza
Los equipos de plataforma pueden realizar un seguimiento del uso de los modelos en tiempo real, supervisar quién invoca qué modelos y con qué frecuencia, y analizar el rendimiento del sistema para optimizar la asignación de recursos.
La plataforma ofrece herramientas detalladas de registro y depuración, que permiten a los ingenieros rastrear los problemas de manera eficiente, reducir el tiempo de inactividad y mejorar la confiabilidad.
La seguridad es un objetivo fundamental, con una gestión centralizada de las claves de API, que evita el acceso no autorizado y garantiza que los procesos de autenticación permanezcan seguros en todos los entornos de nube. TrueFoundry también garantiza la privacidad de los datos a nivel empresarial al implementar todas las cargas de trabajo de IA en la infraestructura de VPC de la organización, lo que elimina los riesgos de exposición de datos externos.
Además, la plataforma se integra perfectamente con barandillas como las barandillas Nemo, Arize, etc., para la detección de PII, etc.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.
Diseñado para la velocidad: ~ 10 ms de latencia, incluso bajo carga






























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


