

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
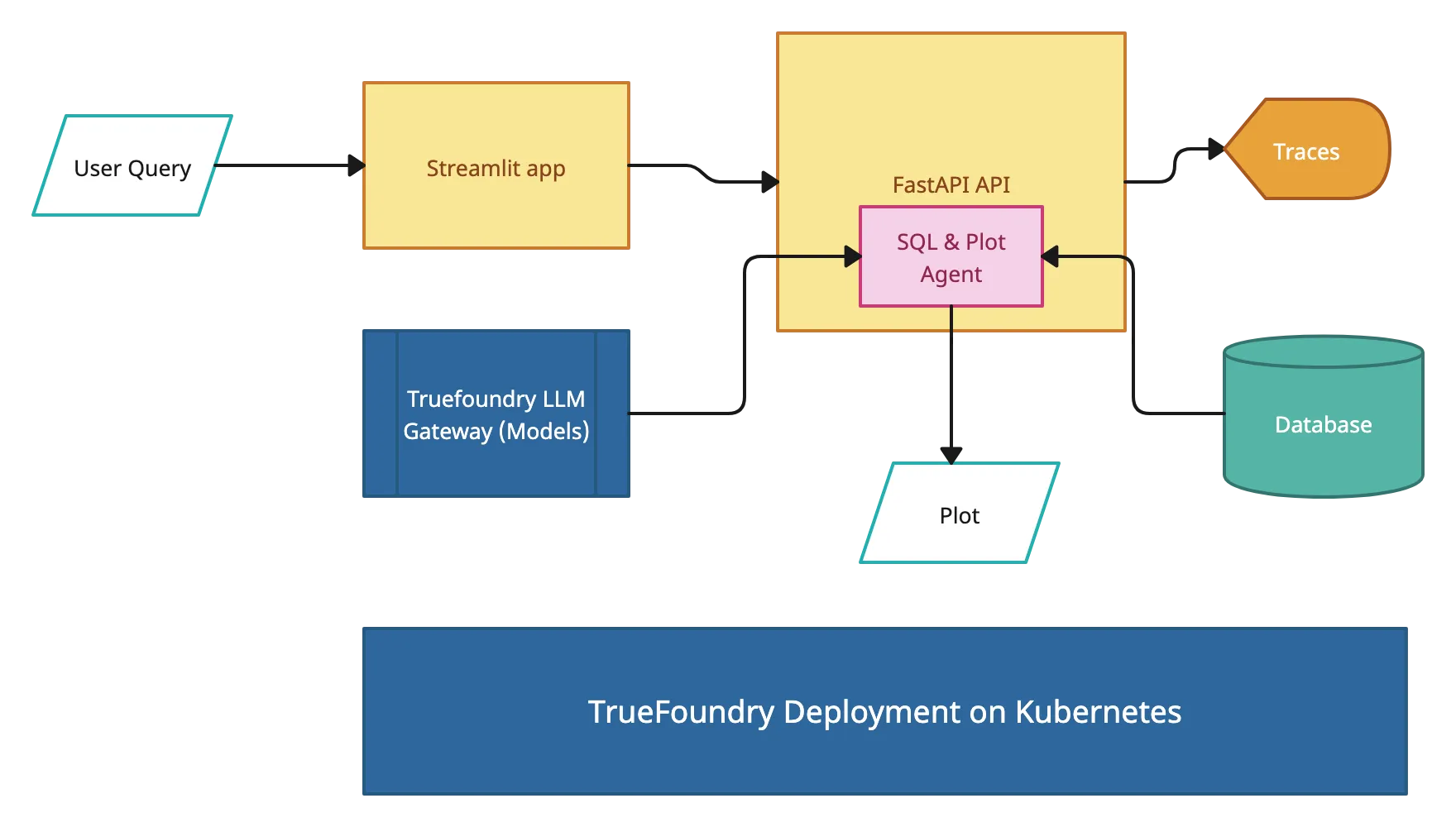
En esta guía, le mostraremos cómo implementar un Langgraph agente en True Foundry, una plataforma diseñada para simplificar la implementación de la IA con una experiencia mínima en DevOps o MLOps. TrueFoundry automatiza la administración, el escalado y la supervisión de la infraestructura, lo que le permite centrarse en obtener información en lugar de gestionar las complejidades de la implementación. Con solo unos pocos clics, puede transformar las solicitudes en lenguaje natural en consultas SQL y gráficos dinámicos, lo que hace que la exploración de datos sea fluida e inteligente. ¡No es necesario realizar consultas manuales!
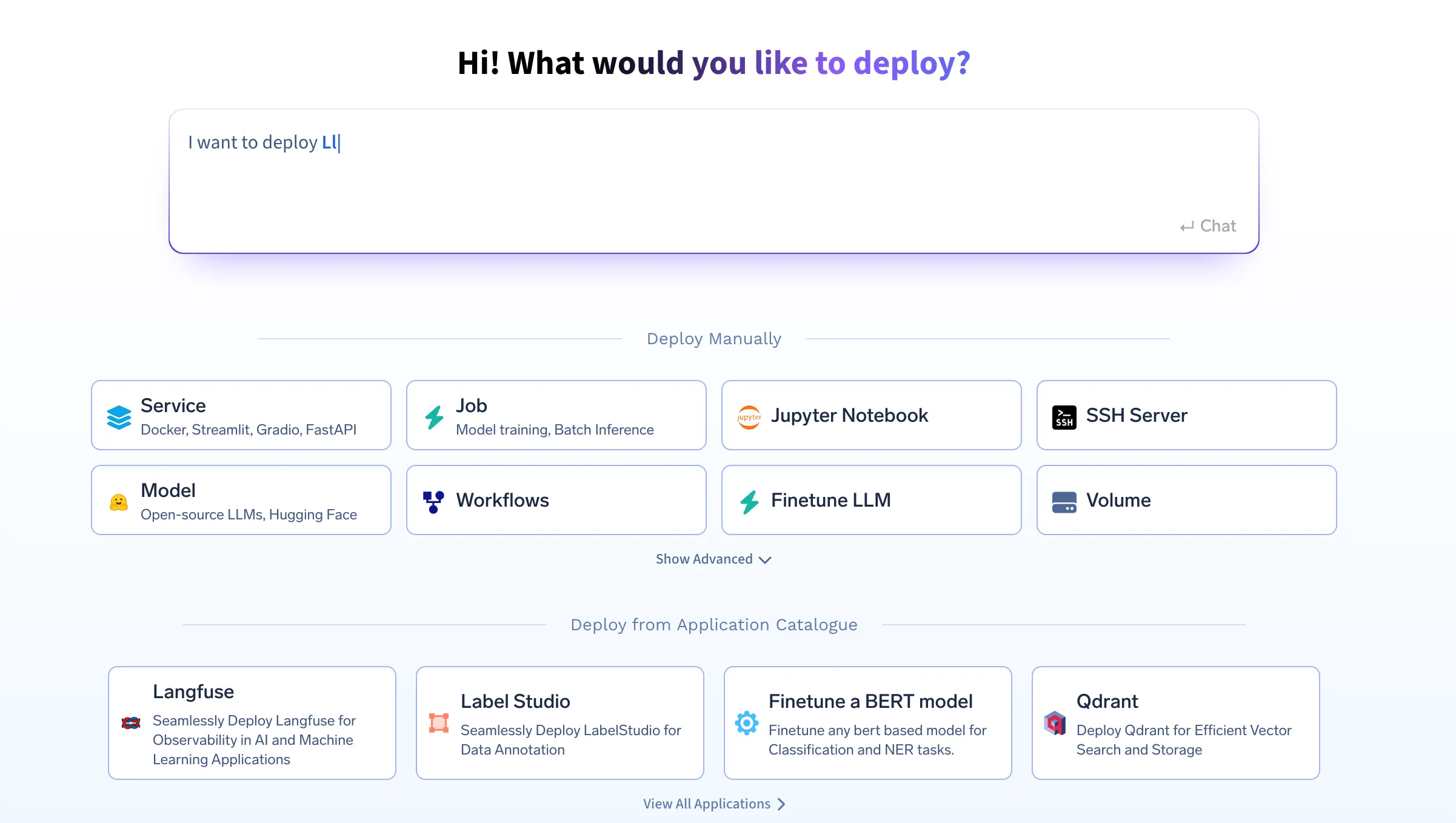
Si quieres probarlo directamente, visita la plataforma TrueFoundry y navega hasta Live Demos y Langgraph-Streamlit: Demostración en vivo del flujo de trabajo de nuestros agentes
Este proyecto consta de varios componentes clave que trabajan en conjunto:
Agente de consultas
Agente de visualización: Un segundo agente de IA que
Backend de FastAPI: API RESTful que
Interfaz optimizada: Interfaz de usuario que
Clonar el repositorio
En primer lugar, navegue hasta el Ejemplos de introducción a TrueFoundry reposicionarlo y clonarlo:
git clone <https://github.com/truefoundry/getting-started-examples.git>Navegue hasta el directorio de agentes gráficos
Cambie al directorio plot_agent:
cd getting-started-examples/plot_agent/langgraph_plot_agentConfiguración del entorno
Para crear y activar un entorno virtual:
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activateInstalar dependencias
pip install -r requirements.txtConfiguración del entorno
Copie el archivo de entorno de ejemplo:
```bash
cp .env.example .env
```Crea un .env archiva con tus credenciales
# Truefoundry LLMGateway Configuration if using Truefoundry LLM Gateway for calling models
LLM_GATEWAY_BASE_URL=your_llm_gateway_base_url_here
LLM_GATEWAY_API_KEY=your_llm_gateway_api_key_here
# OPENAI API Configuration if not using Truefoundry LLM Gateway
OPENAI_API_KEY=<your_openai_api_key_here>
# ClickHouse Database Configuration
CLICKHOUSE_HOST=your_clickhouse_host_here
CLICKHOUSE_PORT=443
CLICKHOUSE_USER=your_clickhouse_user_here
CLICKHOUSE_PASSWORD=your_clickhouse_password_here
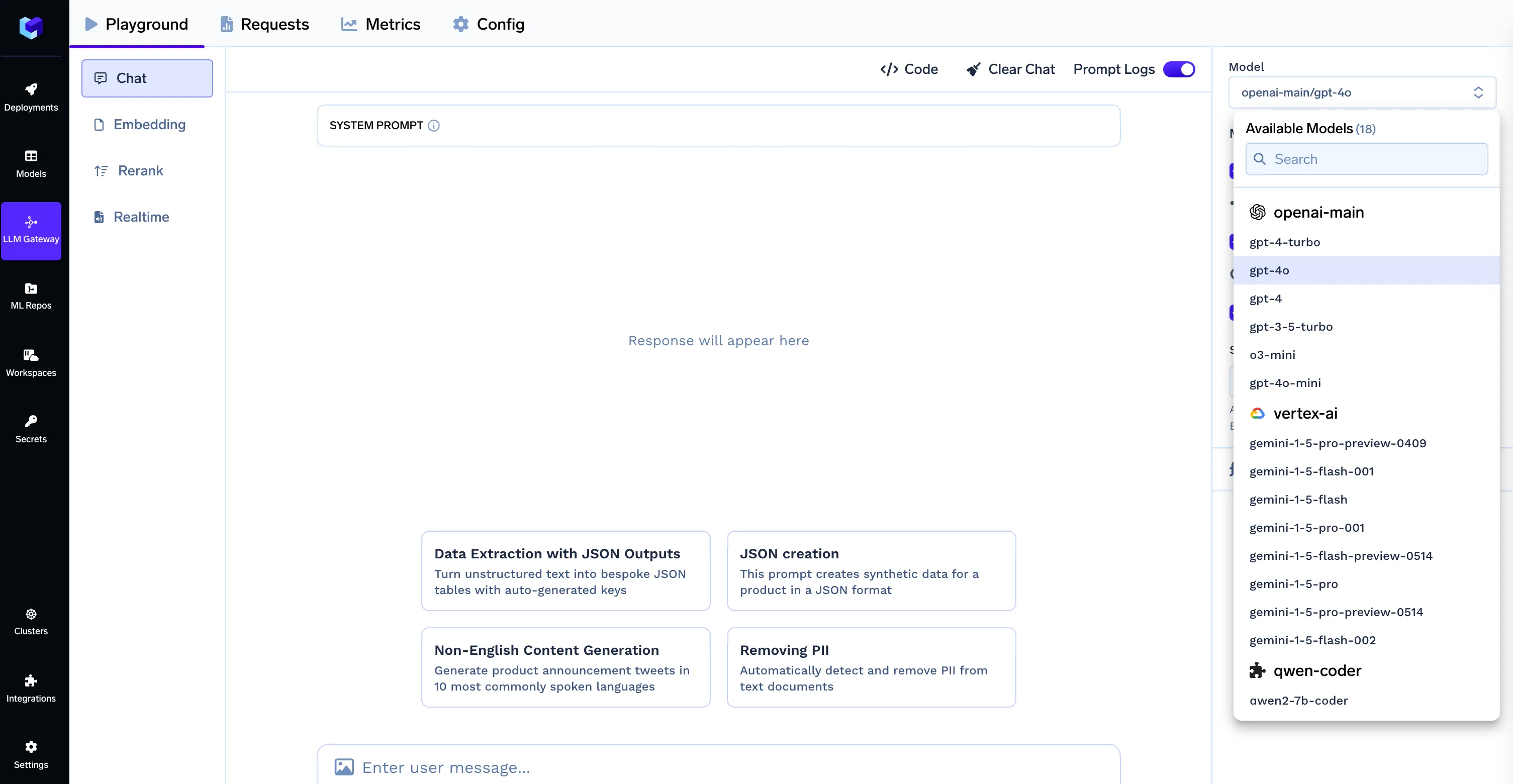
CLICKHOUSE_DATABASE=defaultNota: Al utilizar TrueFoundry LLM Gateway, el formato de ID del modelo debe ser nombre-proveedor/nombre-modelo (p. ej., openai-main/gpt-4o). Asegúrese de que su .env El archivo contiene las credenciales correctas de LLM Gateway, tal como se muestra en la sección Configuración del entorno.
Para obtener las credenciales de Clickhouse, cree una cuenta en Clickhouse, inicia sesión y crea un servicio. Tras hacer clic en el servicio, verás un botón de conexión en el centro de la barra lateral izquierda, en el que podrás hacer clic para ver las credenciales, tal y como se muestra a continuación. Puedes crear una base de datos cargando tus archivos o usar una base de datos predefinida.

El proyecto utiliza dos agentes de LangGraph, lo que también lo convierte en una referencia práctica útil a la hora de evaluar AutoGen frente a LangGraph para el diseño de flujos de trabajo de múltiples agentes. Si prefiere usar solo openai, sustituya:
model=OpenAIChat(
id="openai-main/gpt-4o", # Format: provider-name/model-name
api_key=os.getenv("LLM_GATEWAY_API_KEY"),
base_url=os.getenv("LLM_GATEWAY_BASE_URL")
),Con:
model=OpenAIChat(
id="gpt-4o", # Specify model here
api_key=os.getenv("OPENAI_API_KEY")
),Así es como se configuran en una configuración en la que Langflow frente a LangGraph a menudo se basa en opciones de orquestación.
class State(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
tools_list = [execute_clickhouse_query, create_plot]
def tools_condition_modified(state):
ans = tools_condition(state)
human_messages_id = [m.id for m in state["messages"] if m.type == "human"]
if ans == "tools":
return "tools"
else:
return "__end__"
def create_agent():
builder = StateGraph(State)
llm = ChatOpenAI(
model=os.getenv("MODEL_ID"),
api_key=os.getenv("LLM_GATEWAY_API_KEY"),
base_url=os.getenv("LLM_GATEWAY_BASE_URL"),
streaming=True # Enable streaming for the LLM
)
llm.bind_tools(tools_list)
# Define nodes: these do the work
builder.add_node("assistant", llm)
builder.add_node("tools", ToolNode(tools_list))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_edge("tools", "assistant")
builder.add_conditional_edges(
"assistant",
tools_condition_modified,
)
builder.add_edge("assistant", "__end__")
agent = builder.compile()
return agent
agent = create_agent()
Inicie el servidor FastAPI:
python api.pyInicie Streamlit UI (nueva terminal):
streamlit run app.py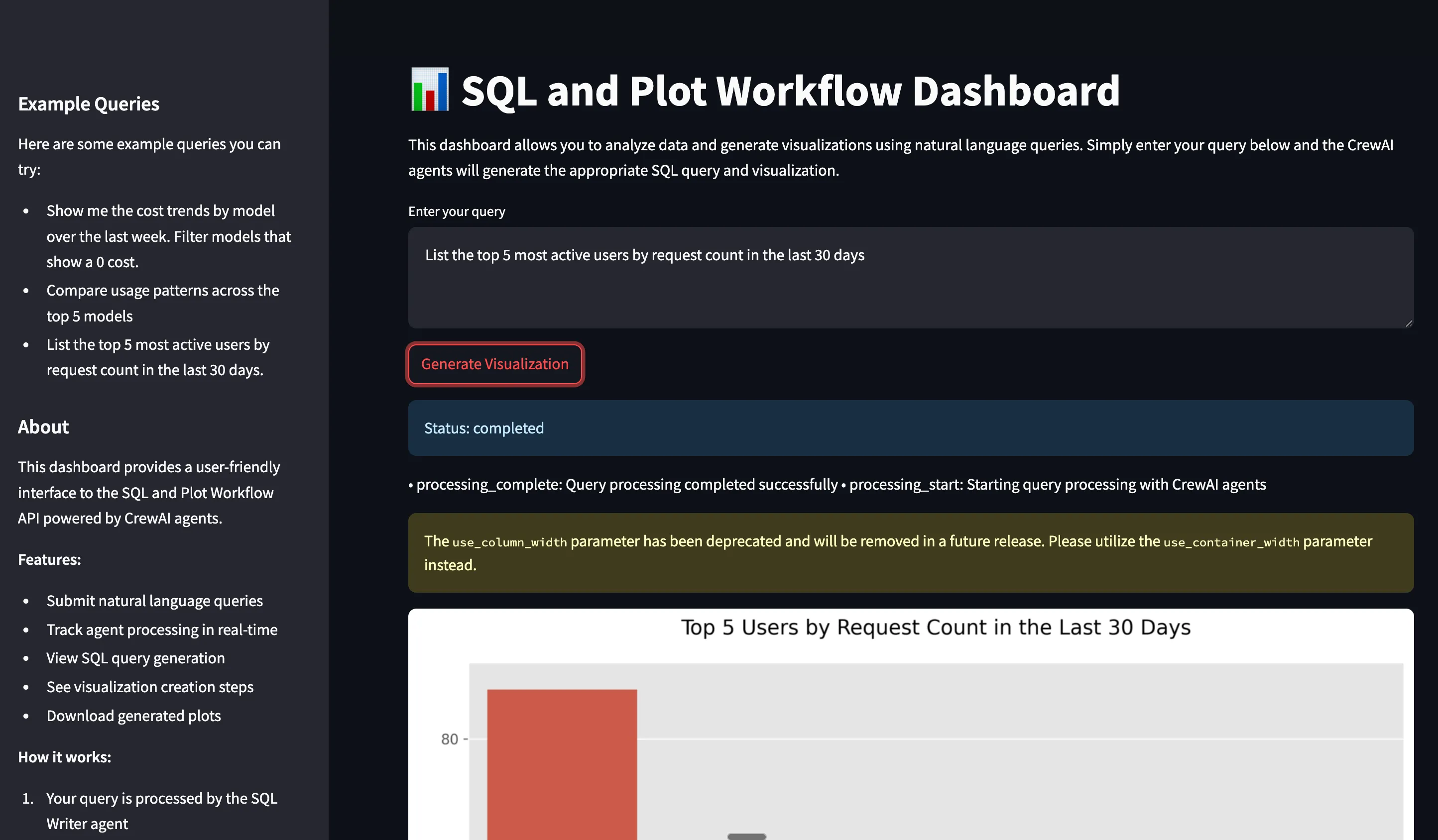
Prerrequisitos
Instale la CLI de TrueFoundry:
pip install -U "truefoundry"Inicie sesión en TrueFoundry:
tfy login --host "<https://app.truefoundry.com>"
# In the generated deploy.py file, locate the env section and add your variables:
env={
# If using OPENAI
"OPENAI_API_KEY": "your_openai_api_key",
# If using LLM_GATEWAY
"LLM_GATEWAY_API_KEY": "your_llm_gateway_api_key",
"LLM_GATEWAY_BASE_URL": "your_llm_gateway_base_url",
"CLICKHOUSE_HOST": "your_clickhouse_host",
"CLICKHOUSE_PORT": "443",
"CLICKHOUSE_USER": "your_user",
"CLICKHOUSE_PASSWORD": "your_password",
"CLICKHOUSE_DATABASE": "default",
"MODEL_ID": "gpt-4o"
}, Asegúrese de reemplazar los valores de los marcadores de posición por sus credenciales reales. Sin estas variables de entorno, la aplicación no funcionará correctamente.
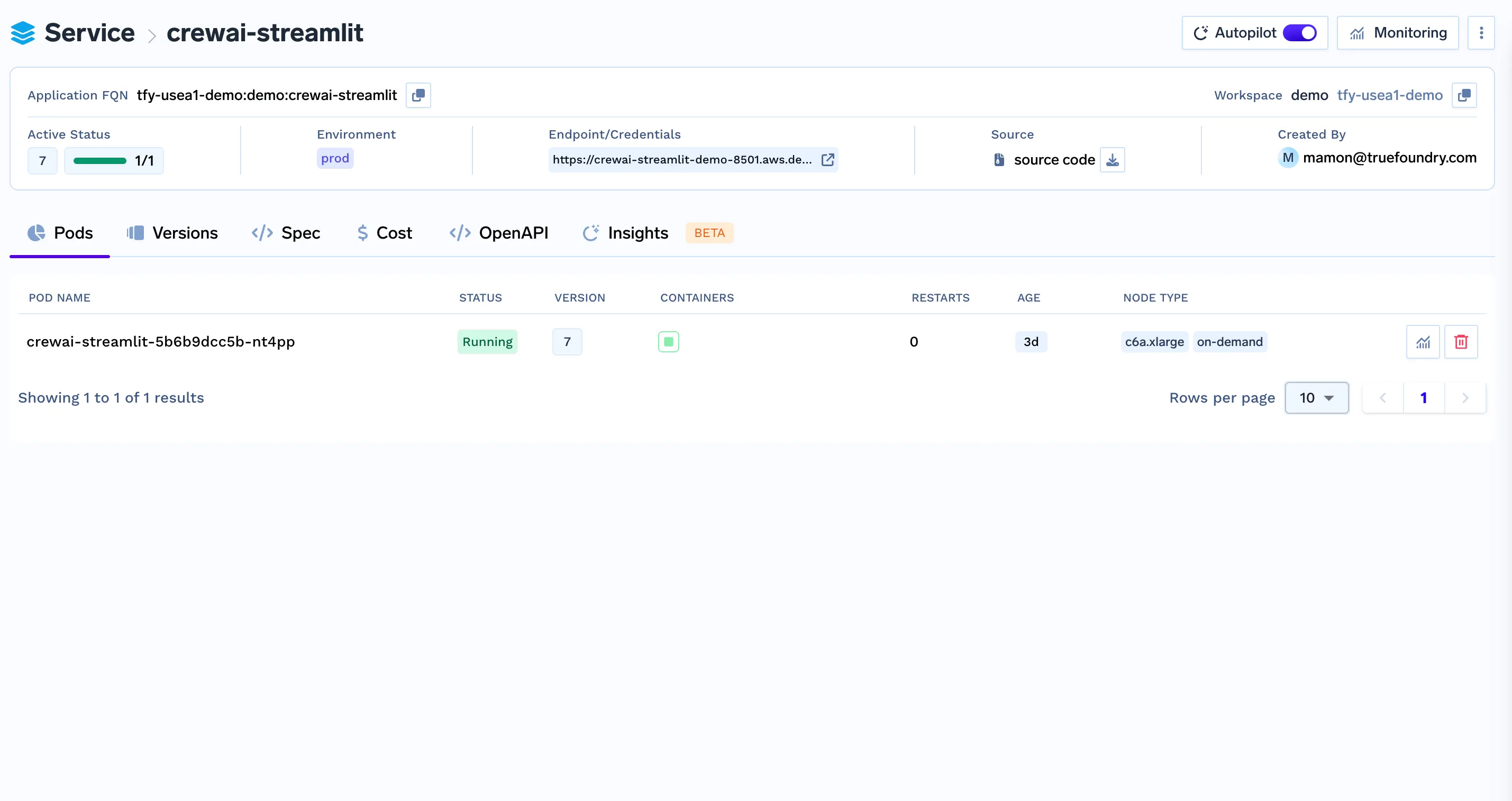
python deploy.py¡Su API de flujo de trabajo de SQL y Plot ya está implementada y ejecutándose en TrueFoundry!
curl -X POST -H "Content-Type: application/json" \
-d '{"query": "Show me the cost trends by model over the last week"}' \
https://Langgraph-plot-agent-demo-8000.aws.demo.truefoundry.cloud/query Si todo está configurado correctamente, deberías recibir una respuesta como:
{
"job_id": "123e4567-e89b-12d3-a456-426614174000",
"status": "processing",
"message": "Query is being processed. Check status with /status/{job_id}"
} 
curl -X POST "https://plot-agent-8000.your-workspace.truefoundry.cloud/query" \
-H "Content-Type: application/json" \
-d '{"query": "Show me the cost trends by model over the last week"}' curl -X POST http://localhost:8000/query \
-H "Content-Type: application/json" \
-d '{"query": "Show me the cost trends by model over the last week. Filter models that show a 0 cost."}'
{
"job_id": "123e4567-e89b-12d3-a456-426614174000",
"status": "processing",
"message": "Query is being processed. Check status with /status/{job_id}"
}
curl -X GET http://localhost:8000/status/123e4567-e89b-12d3-a456-426614174000
curl -X GET http://localhost:8000/plot/123e4567-e89b-12d3-a456-426614174000 --output plot.png Para garantizar una comunicación adecuada entre FastAPI y Streamlit, debe implementar Streamlit como un servicio independiente en la plataforma TrueFoundry.
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
) Tu aplicación Streamlit debe usar una variable de entorno para apuntar al backend de FastAPI: En tu Entorno optimizado configuración:
FASTAPI_ENDPOINT="https://langgraph-plot-agent-demo-8000.aws.demo.truefoundry.cloud"A continuación, modifique su Aplicación Streamlit para leer esta variable de entorno:
import os
FASTAPI_ENDPOINT = os.getenv("FASTAPI_ENDPOINT", "http://localhost:8000")Esto garantiza que Streamlit haga referencia de forma dinámica a la instancia de FastAPI correcta.
4. Utilice puertos separados
Si se implementa localmente o si TrueFoundry no gestiona automáticamente los conflictos de puertos, asegúrese FastAPI y Streamlit se ejecutan en puertos separados.
Ejemplo:
API rápida: https://langgraph-plot-agent-demo-8000.aws.demo.truefoundry.cloud
Streamlit: https://langgraph-streamlit-demo-8501.aws.demo.truefoundry.cloud
Para ejecutar Streamlit en un puerto diferente de forma local:
streamlit run app.py --server.port 8501El rastreo te ayuda a entender lo que ocurre de manera clandestina cuando se llama a un agente. Cuando ejecutas tu agente con la función de rastreo de Truefoundry, solo tienes que añadir muy pocas líneas de código para entender la ruta, las herramientas, las llamadas realizadas, el contexto utilizado y la latencia que se sigue.
Debe instalar lo siguiente
pip install traceloop-sdkY, a continuación, añada las variables de entorno necesarias para habilitar el rastreo
"TRACELOOP_BASE_URL": "<your_host_name>/api/otel" # "https://internal.devtest.truefoundry.tech/api/otel"
"TRACELOOP_HEADERS"="Authorization=Bearer%20<your_tfy_api_key>"En su base de código donde define su agente, solo necesita estas líneas para habilitar el rastreo
from traceloop.sdk import Traceloop
Traceloop.init(app_name="langraph")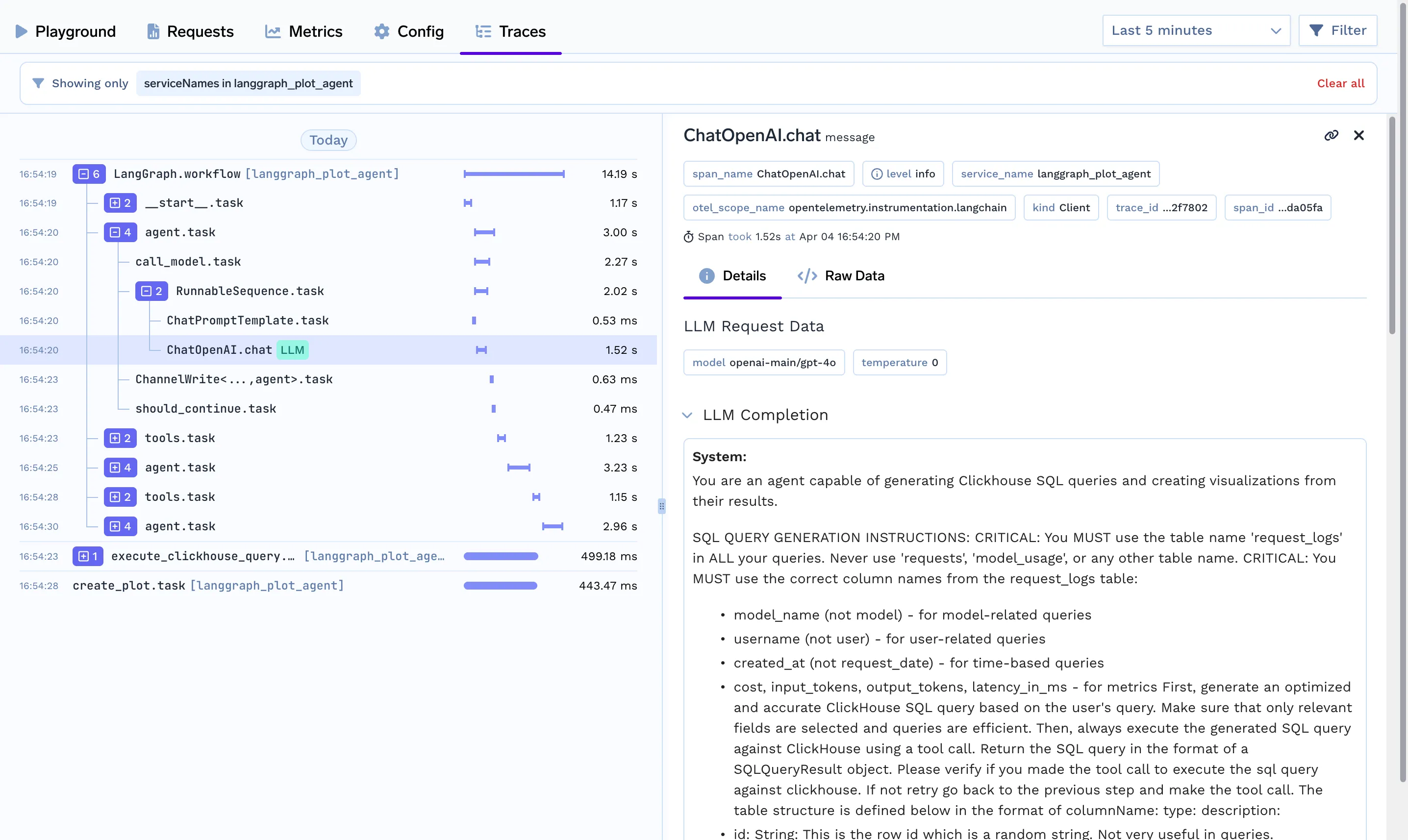
Después de implementar ambos servicios, asegúrese de:
.env archivo con el punto final de FastAPI correcto.Esto garantiza que su API de flujo de trabajo de SQL y Plot funcione correctamente en ambos servicios.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


