

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Si alguna vez se ha reunido con su equipo legal o de seguridad informática en relación con una implementación global de aprendizaje automático, sabrá el momento exacto en que cambia el estado de ánimo. Es cuando alguien pregunta: «Espera, ¿dónde están realmente los registros de inferencias de los clientes alemanes?»
La residencia de datos solía ser un problema de base de datos. Ahora, con las canalizaciones de aprendizaje automático que abarcan la capacitación, el servicio, la supervisión y los almacenes de funciones, es un desastre cada vez mayor que afecta a toda la infraestructura. El RGPD, la CCPA y las leyes de soberanía de datos en Asia no son sugerencias. Hacerlo mal implica multas masivas o, lo que es peor, tener que desmantelar un despliegue activo.
Hemos estado usando TrueFoundry para administrar nuestra infraestructura de aprendizaje automático y, francamente, su enfoque de la residencia de datos es una de las principales razones por las que nos quedamos con ellos. Cambia radicalmente nuestra forma de pensar acerca de dónde residen los datos en lugar de dónde se administran.
He aquí un vistazo a cómo funciona en la práctica y por qué se siente diferente a las plataformas SaaS MLOps típicas.
El mayor problema con muchas plataformas mLOps administradas es que, para aprovechar la comodidad de sus herramientas, a menudo tiene que enviar sus datos (artefactos de modelo, fragmentos de entrenamiento, registros) a su nube. Esto es un fracaso para las industrias altamente reguladas.
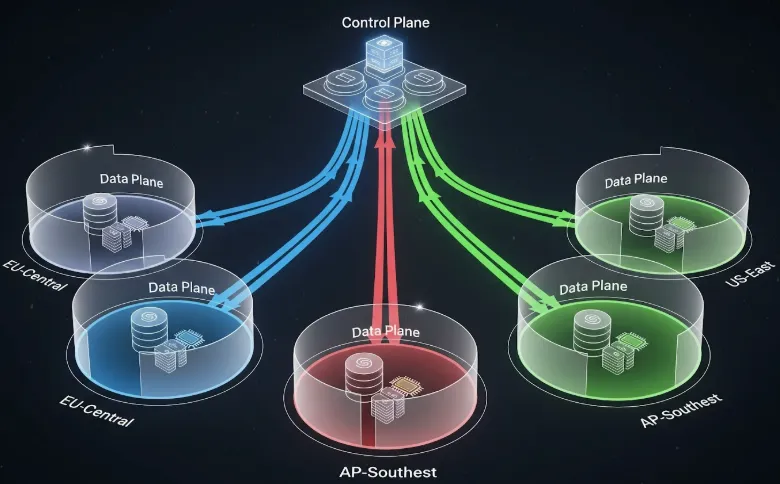
TrueFoundry funciona de manera diferente. Emplean una separación estricta entre Plano de control (su interfaz de administración de SaaS) y Plano de datos (sus cuentas en la nube).
Piénsalo así: TrueFoundry es el controlador de tráfico aéreo. Le dicen a los aviones adónde ir y cuándo aterrizar. Pero el aeropuerto, los hangares y los propios aviones son suyos. En realidad, TrueFoundry nunca posee la carga dentro del avión.
Cuando conectas un clúster de Kubernetes (EKS, GKE, AKS) a TrueFoundry, básicamente estás instalando un agente. Ese agente se dirige al plano de control de TrueFoundry para obtener instrucciones, pero todo el procesamiento y almacenamiento de los datos se lleva a cabo dentro del perímetro de red predefinido.
He aquí una visión de alto nivel de esa relación.
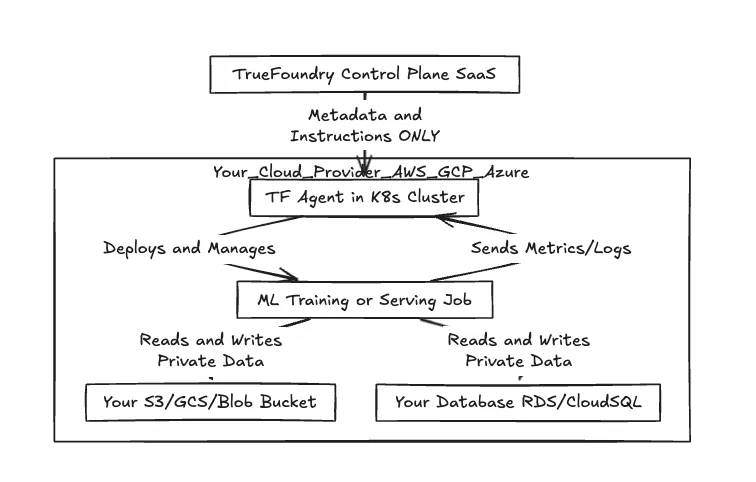
Figura 1: Flujo de trabajo entre el plano de control y la separación del plano de datos
Como se muestra arriba, el «trabajo pesado» y la E/S de datos reales permanecen completamente dentro de los límites de su entorno de nube. Lo único que se cruza en el camino hacia TrueFoundry son los metadatos: el estado de los trabajos, las métricas de utilización de los recursos y las especificaciones de configuración.
¿Cómo se traduce esto en una situación real en la que tienes un equipo en la UE que legalmente no puede permitir que los datos de sus clientes lleguen a suelo estadounidense?
TrueFoundry usa un concepto llamado «Espacios de trabajo». Un espacio de trabajo es una agrupación lógica de recursos que está vinculada a una integración específica de almacenamiento de artefactos y clústeres de cómputos subyacentes.
Para hacer cumplir la residencia, configuramos grupos distintos en nuestras regiones geográficas requeridas.
Repetimos el proceso para us-east-1 con un espacio de trabajo «US-Prod».
Cuando un científico de datos de la UE quiere implementar un modelo, solo se le concede acceso al espacio de trabajo «EU-Prod». Cuando inician un trabajo de formación o despliegan un servicio, el plano de control de TrueFoundry garantiza que el cálculo se realice en el clúster de Fráncfort y que las ponderaciones resultantes del modelo se guarden en el bucket S3 de Fráncfort. La plataforma no puede colocar físicamente los datos en ningún otro lugar, porque ese espacio de trabajo no sabe que existe ninguna otra infraestructura.
A continuación se muestra una comparación de cómo se gestionan los datos en un SaaS de ML gestionado típico con respecto a esta arquitectura.
Tabla 1: Esta es la comparación de los modelos de manejo de datos
En una organización madura, se termina con un modelo centralizado. Dispones de un plano de control centralizado de TrueFoundry que proporciona a tu equipo de ingeniería de plataformas un único panel de control para facilitar la administración, pero la ejecución real está fragmentada geográficamente.
Este aislamiento es fundamental. Esto significa que, incluso si un desarrollador intenta configurar accidentalmente un trabajo de forma incorrecta, las restricciones de la infraestructura evitan la filtración de datos entre regiones.
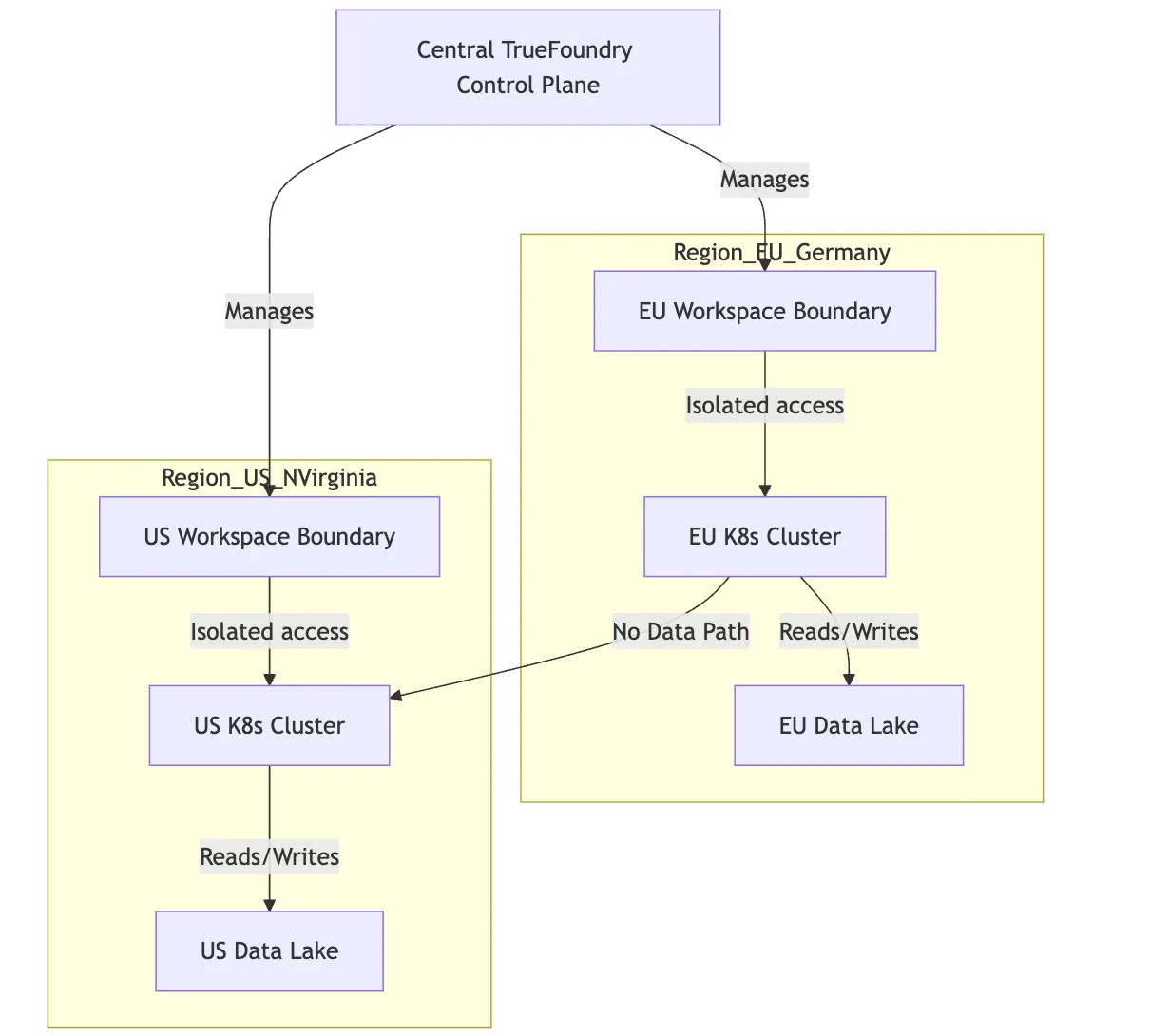
Figura 2: Diagrama del aislamiento multirregional mediante espacios de trabajo
La residencia de datos rara vez es un trabajo emocionante, pero es fundamental. Si te equivocas, nada más importa.
La belleza de la arquitectura de TrueFoundry es que no intenta ser en sí misma un «búnker de datos seguro». Por el contrario, respeta los búnkeres que ya has creado en AWS, Azure o GCP. Nos permite ofrecer a nuestros científicos de datos una experiencia de implementación moderna, similar a la de Heroku, sin tener que luchar constantemente con nuestro equipo de InfoSec para obtener excepciones. Definimos el perímetro una vez, le añadimos TrueFoundry y dejamos de preocuparnos por la salida accidental de datos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


