

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 28, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los sistemas de IA ya no son herramientas pasivas. Lo son cada vez más agente - funciona de forma autónoma en todos los flujos de trabajo, las API y los datos empresariales confidenciales. En los sistemas tradicionales, la residencia de los datos se definía según el lugar donde se almacenaban los datos. Una vez que las bases de datos y el almacenamiento se instalaron en las regiones aprobadas, el cumplimiento se consideró resuelto.
La IA de las agencias rompe ese modelo. Cada interacción genera nuevas superficies de datos - solicitudes, memoria del agente, registros, seguimientos y datos de inferencia transitoria, que se procesan y observan en tiempo de ejecución, a menudo en todas las regiones, incluso cuando no se conserva nada.
Como resultado, la residencia de datos ya no es una casilla de verificación de cumplimiento. Es un preocupación principal en materia de infraestructura ahora se discute a nivel de junta. La pregunta que las empresas deben responder es sencilla: ¿A dónde se mueven los datos generados por la IA en tiempo de ejecución y quién controla esas rutas?
En True Foundry, la residencia de datos se aplica en el Puerta de enlace de IA, donde convergen la inferencia, los agentes y las herramientas. La residencia se trata como propiedad del sistema, que se aplica en condiciones normales de funcionamiento, fallos y escala. Este blog explica cómo se define, aplica y verifica la residencia de los datos en el TrueFoundry AI Gateway.
La residencia de datos era más sencilla cuando las aplicaciones tenían rutas de datos predecibles. Las solicitudes pasaban de los usuarios a los servicios y a las bases de datos, por lo general dentro de una sola región, y los controles de cumplimiento eran en gran medida estáticos.
Los sistemas de IA rompen este modelo en tiempo de ejecución.
En las arquitecturas de IA modernas, el movimiento de datos es dinámico y se basa en la toma de decisiones, no está arreglado. Una solicitud de un solo usuario puede activar varias rutas de ejecución, todas ellas orquestadas por el AI Gateway. Aquí es donde la residencia de los datos se vuelve frágil.
Durante el tiempo de ejecución, una puerta de enlace de IA puede:
Cada una de estas decisiones puede introducir movimiento de datos implícito, a menudo sin que la aplicación lo sepa.
Los fallos de residencia de datos más comunes en los sistemas de IA se producen:
Fundamentalmente, estas fallas ocurren incluso cuando:
Todas estas fallas tienen una cosa en común: ocurren en tiempo de ejecución, impulsado por el enrutamiento, los reintentos, la ejecución del agente y el comportamiento de registro.
El AI Gateway es la única capa que:
Esta es la razón por la que la residencia de los datos en los sistemas de IA no se puede garantizar únicamente mediante la configuración de la implementación. Debe hacerse cumplir en el AI Gateway, donde las rutas de ejecución se deciden en tiempo real.
En plataformas como True Foundry, la residencia se trata como restricción de tiempo de ejecución estricta, no es una preferencia basada en el mejor esfuerzo para garantizar que ninguna ruta de ejecución, incluidos los escenarios de fracaso, pueda infringir los límites regionales.
Los sistemas de IA agentic no solo utilizar datos, ellos generar continuamente nuevas superficies de datos en tiempo de ejecución. Estas superficies no existían en las aplicaciones tradicionales y cambian radicalmente lo que debe tener en cuenta la residencia de los datos.
En los sistemas de IA, la residencia de datos ya no se limita a los datos en reposo. Se extiende a todos los datos creados, procesados u observados durante la inferencia y la ejecución del agente, incluso si esos datos solo existen brevemente.
Los más importantes de estos nuevos pasivos relacionados con los datos suelen ser los menos visibles.
Las solicitudes de inferencia llevan indicaciones y respuestas a través de AI Gateway, que con frecuencia contiene lógica patentada, datos de clientes o contexto interno confidencial. A diferencia de las API tradicionales, estos datos son de formato libre y no están desinfectados, lo que los hace particularmente riesgosos.
Los flujos de trabajo de agencia presentan contexto y memoria persistentes en todas las interacciones. Si este estado se procesa o reproduce fuera de las regiones aprobadas, se infringe la residencia, incluso cuando las llamadas de inferencia individuales parezcan cumplir con las normas.
Los sistemas de IA también generan registros, trazas, incrustaciones y metadatos de ejecución que puede codificar información confidencial. Si las canalizaciones de observabilidad exportan estos datos de una región a otra, las infracciones se producen de forma silenciosa.
Fundamentalmente, no es necesario almacenar los datos para no cumplir con las normas. Datos de inferencia transitoria, procesada solo en la memoria durante milisegundos, sigue estando sujeta a los requisitos de residencia si cruza un límite jurisdiccional.
Los controles de residencia tradicionales se diseñaron para sistemas estáticos, no para el enrutamiento dinámico, los reintentos, la conmutación por error y la ejecución impulsada por agentes. En los sistemas de IA, se debe hacer cumplir la residencia en tiempo de ejecución, donde se crean estas rutas de datos.
En plataformas como True Foundry, esta aplicación se lleva a cabo en el Puerta de enlace de IA, donde convergen las solicitudes, el contexto del agente, los reintentos y la telemetría, lo que convierte la residencia en una propiedad del sistema y no en una suposición.
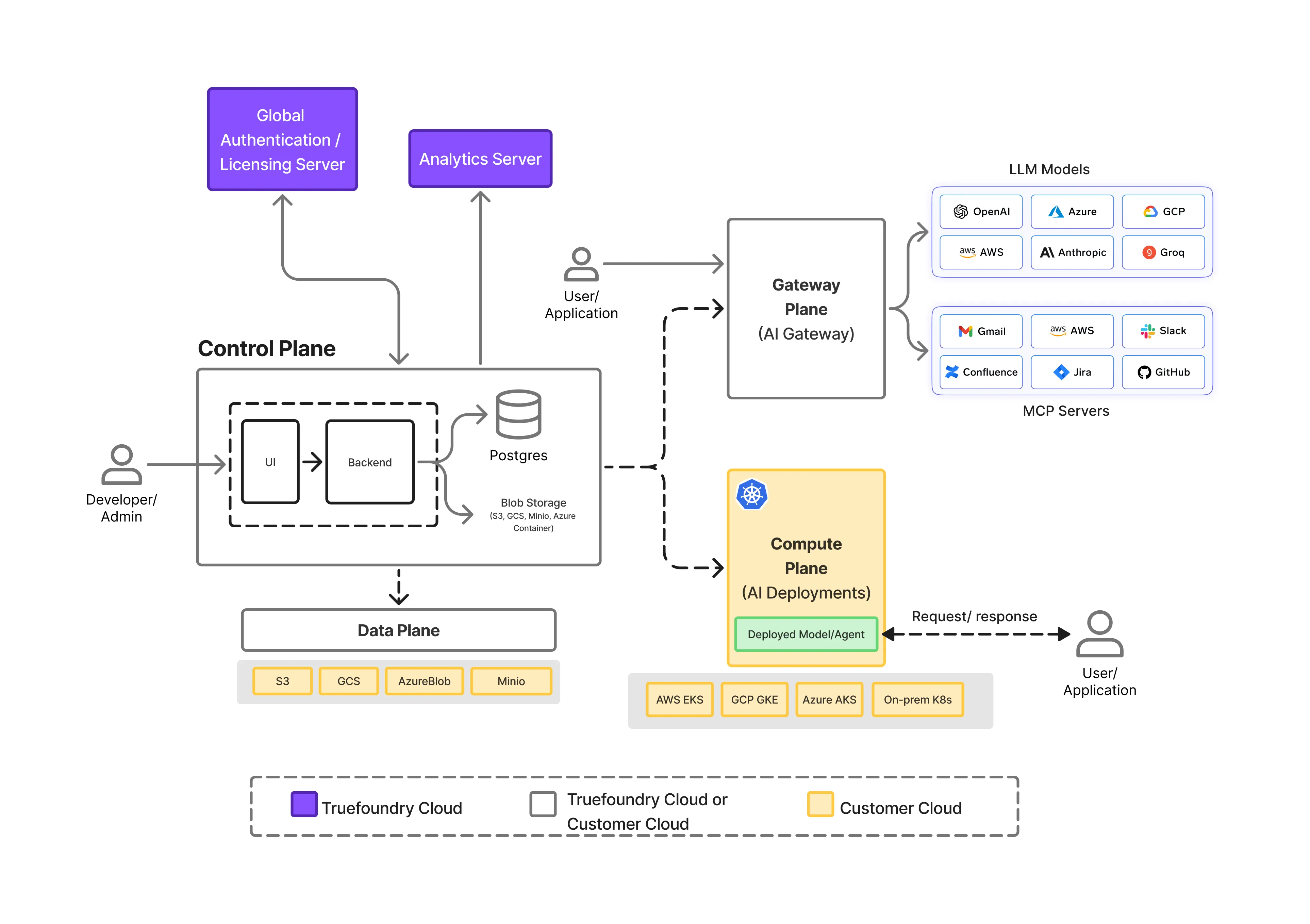
Imponer la residencia de datos en los sistemas de IA requiere más que un despliegue regional. Requiere clara separación de responsabilidades en toda la pila de IA, de modo que la ejecución, el control y las rutas de datos se puedan gestionar de forma independiente.
TrueFoundry está diseñado en torno a un plano dividido arquitectura eso hace que esto sea posible.
En un nivel alto, la plataforma se compone de tres planos distintos:
Esta separación es fundamental para la forma en que la residencia de los datos se aplica de manera confiable en tiempo de ejecución.
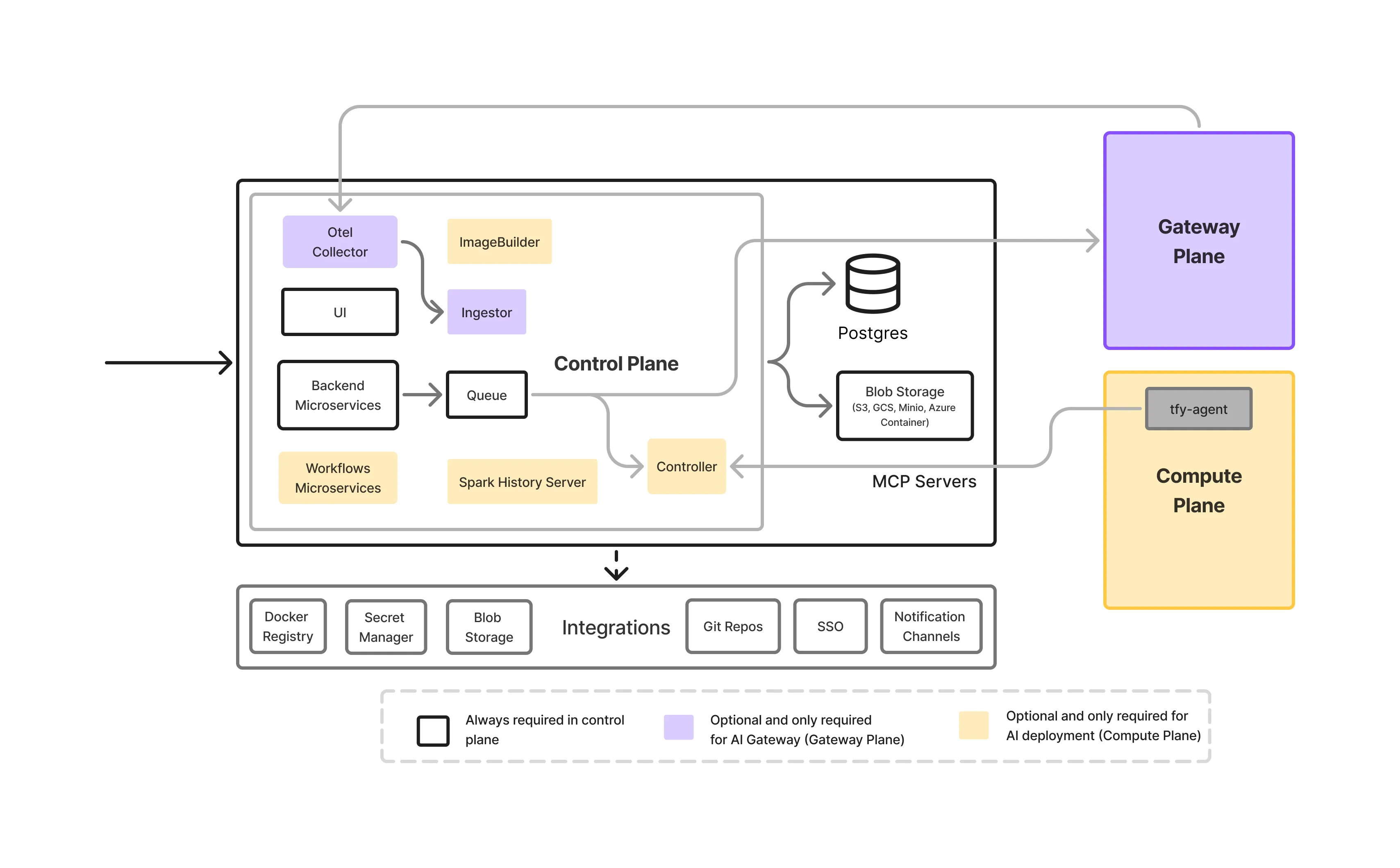
El plano de control es la capa de orquestación de la plataforma TrueFoundry. Es responsable de:
Fundamentalmente, el plano de control no procesa el tráfico de inferencia y no ejecuta cargas de trabajo. Define qué debería suceder, no donde los datos fluyen en tiempo de ejecución.
Para las empresas con requisitos de cumplimiento estrictos, TrueFoundry es compatible con:
Esto permite a las organizaciones elegir el equilibrio adecuado entre la simplicidad operativa y los requisitos de soberanía, sin cambiar la forma en que se hace cumplir la ley de residencia en etapas posteriores.
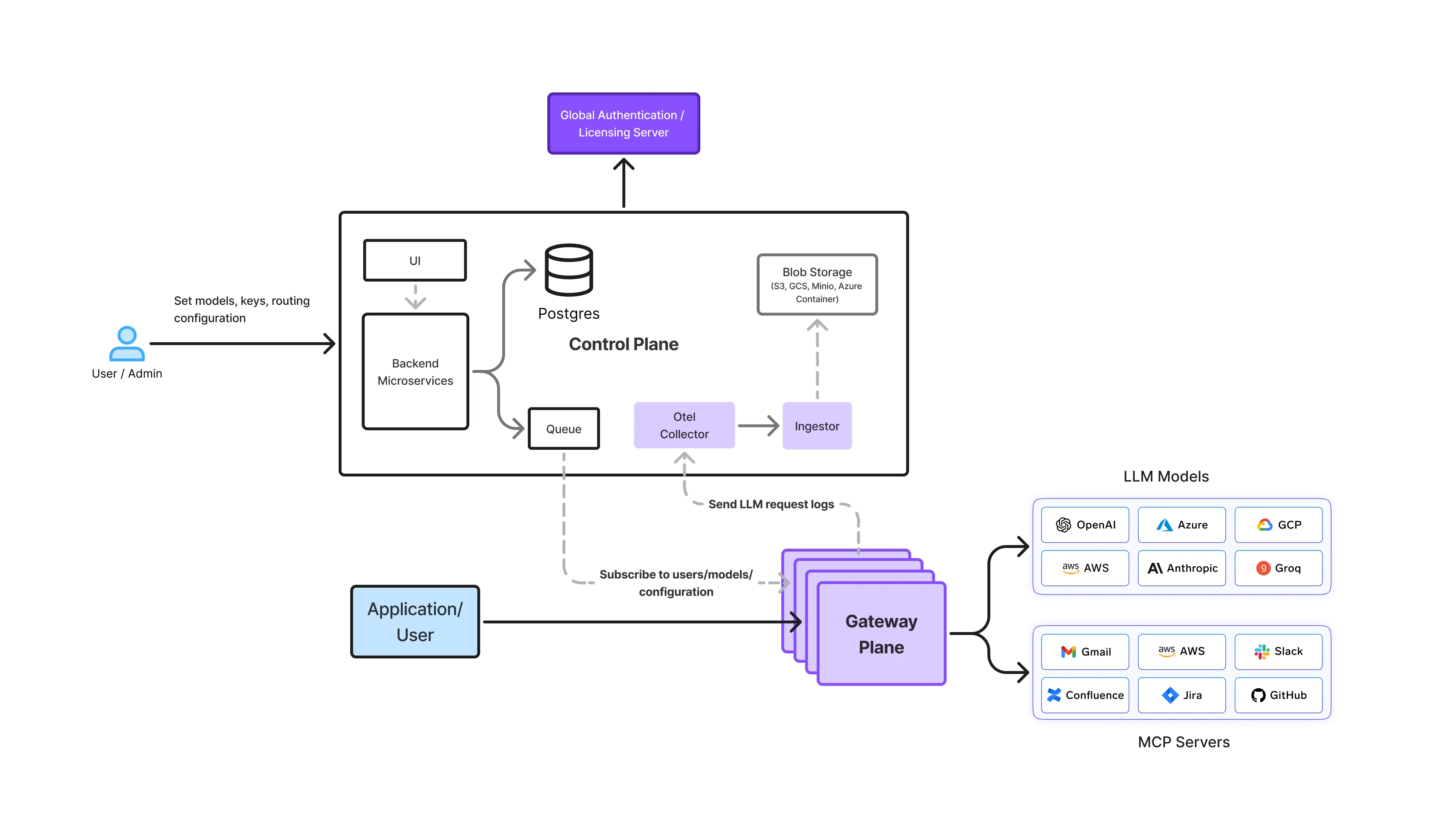
El plano de puerta de enlace es donde la residencia de datos se aplica activamente.
Las pasarelas de IA de TrueFoundry se encuentran entre las aplicaciones y todos los proveedores de modelos, y actúan como:
Todos los eventos de solicitud de inferencia, reintento, conmutación por error, invocación de agentes y observabilidad pasan por la puerta de enlace. Esto le da una visibilidad total de:
Debido a esto, el plano de puerta de enlace es el única capa capaz de imponer la residencia de datos como una restricción estricta.
Si una solicitud no puede satisfacerse dentro de los límites de residencia configurados, la puerta de enlace falla la solicitud cerrada en lugar de dirigirlo silenciosamente a una región que no cumpla con las normas.
Esta es la diferencia clave entre cumplimiento del tiempo de ejecución y configuración con el máximo esfuerzo.
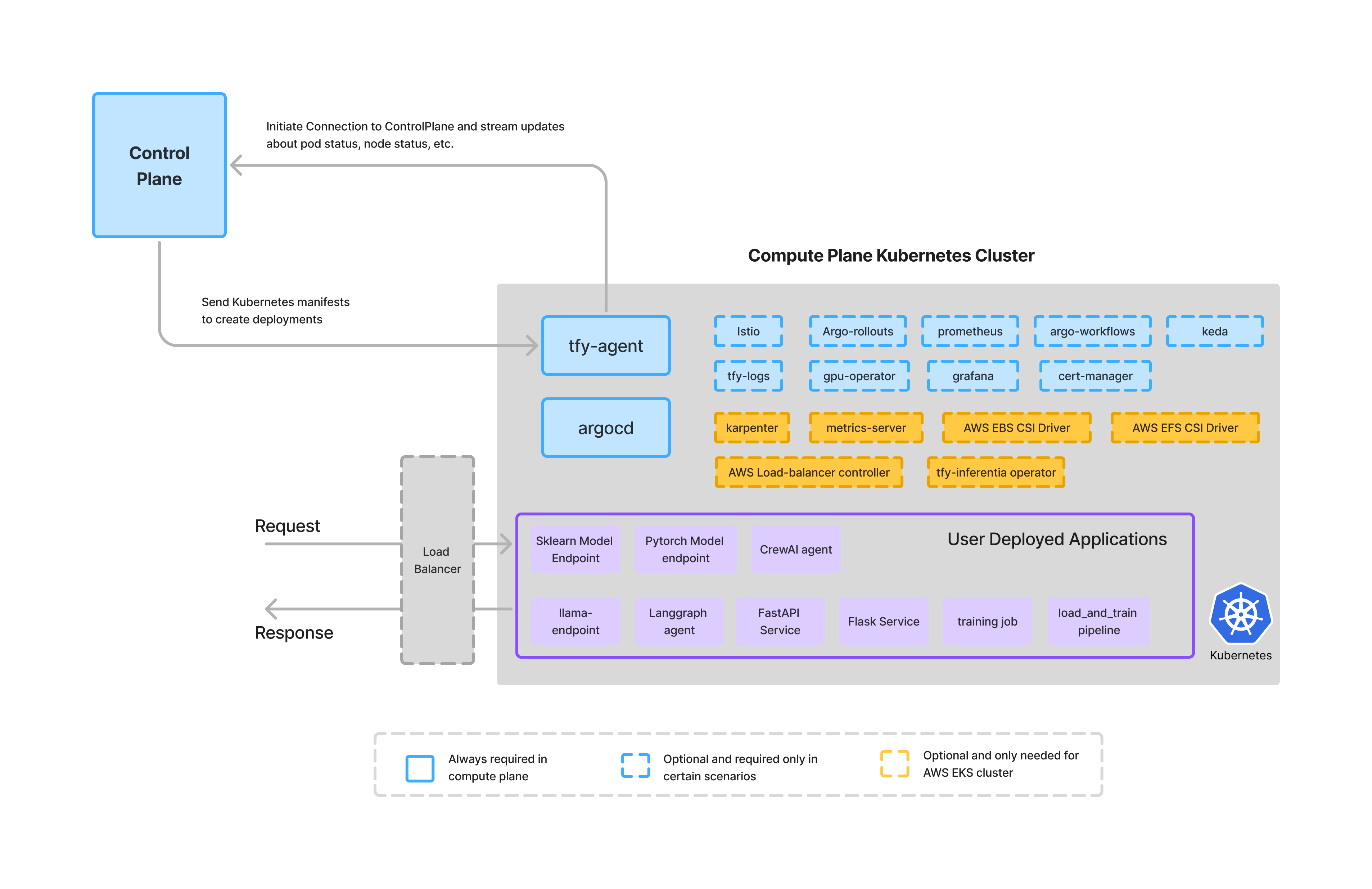
El plano de cómputos es donde realmente se ejecutan las aplicaciones, los agentes y las cargas de trabajo.
En TrueFoundry, el plano de cálculo:
Este diseño garantiza que:
TrueFoundry no ejecuta las cargas de trabajo de los clientes en cómputos compartidos. En su lugar, se integra con los clústeres existentes del cliente o ayuda a aprovisionar otros nuevos, manteniendo la ejecución dentro de los límites de confianza de la organización.
Esta separación de planos permite a TrueFoundry imponer la residencia de los datos. sin compromiso:
Dado que la aplicación se aplica en la puerta de enlace, donde convergen el enrutamiento, los reintentos, los agentes y los registros, la residencia de los datos se mantiene incluso en los siguientes casos:
Esto es lo que permite que la residencia de datos se convierta en propiedad del sistema, no es una suposición vinculada a los diagramas de despliegue.
La residencia de datos en los sistemas de IA no es un cambio único, sino que debe aplicarse en todos los sistemas ejecución, enrutamiento y almacenamiento. En True Foundry, esto se logra mediante tres modos de aplicación complementarios que, en conjunto, cubren todo el ciclo de vida de los datos de IA.
Cada modo aborda una clase diferente de riesgo de residencia y se puede usar de forma independiente o en combinación, según los requisitos de la empresa.
Para las organizaciones con las necesidades de residencia y cumplimiento más estrictas, TrueFoundry permite un modelo de implementación donde los datos nunca salen del entorno del cliente.
En este modo:
Esto se aplica tanto a:
Al garantizar que la ejecución y las rutas de datos permanezcan completamente dentro de la infraestructura controlada por el cliente, este modo proporciona las garantías de residencia más sólidas posibles y simplifica las auditorías reglamentarias.
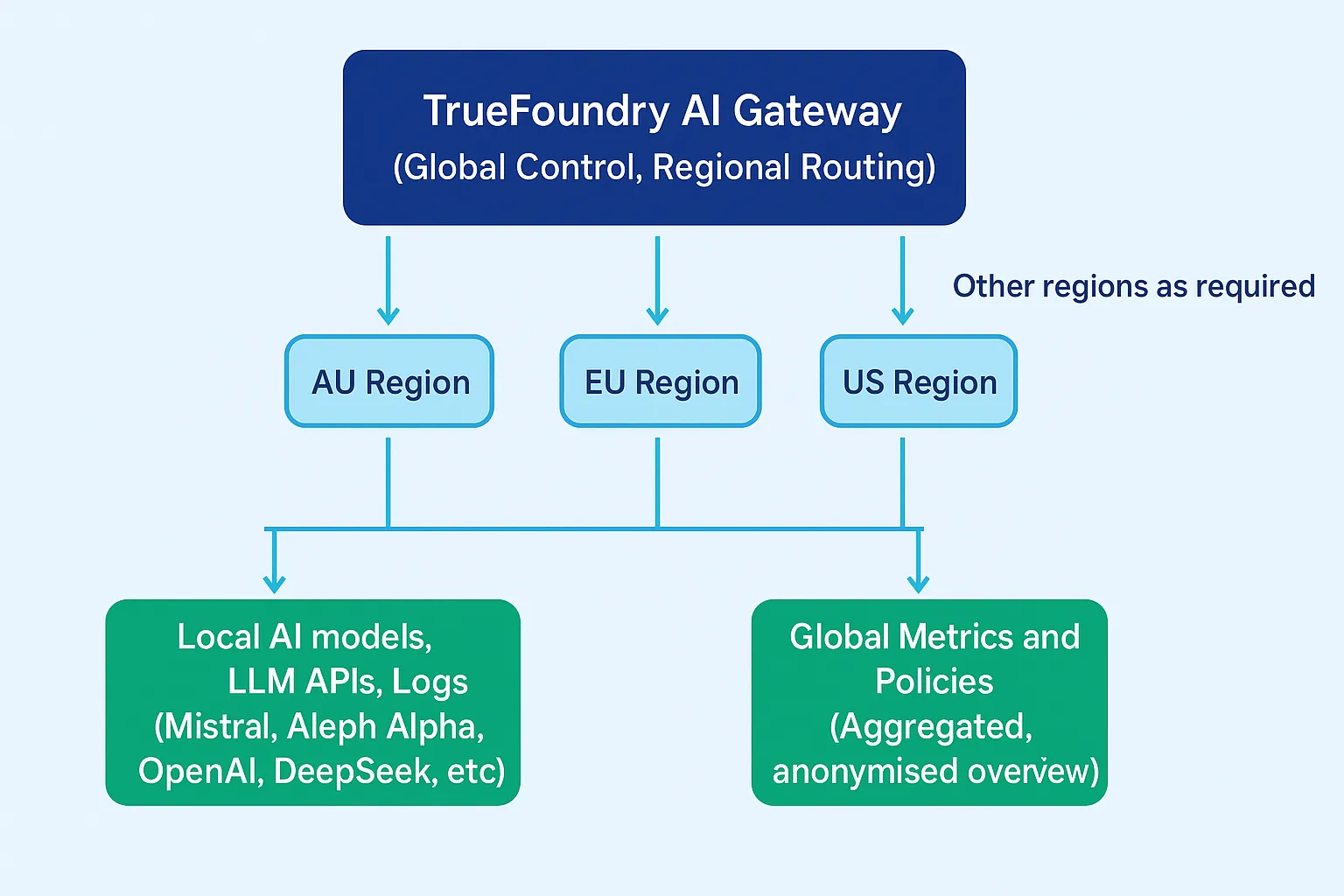
Muchas empresas necesitan operar a nivel mundial y, al mismo tiempo, garantizar que los datos de una geografía determinada nunca cruzan los límites jurisdiccionales.
TrueFoundry refuerza esto a través de despliegues de AI Gateway específicos de la región:
Las aplicaciones eligen explícitamente qué punto final de puerta de enlace regional usar. Esto hace que la residencia de datos:
Si no existe una ruta de ejecución que cumpla con los requisitos de residencia para una solicitud, la puerta de enlace falla la solicitud cerrada en lugar de dirigirlo a otra región. Esto garantiza que los mecanismos de disponibilidad nunca anulen la intención de cumplimiento.
La inferencia y la ejecución son solo una parte de la historia de residencia de datos. Registros, trazas, indicaciones y telemetría a menudo contienen información igualmente confidencial y deben seguir las mismas reglas de residencia.
TrueFoundry permite a las empresas imponer la residencia en la capa de almacenamiento de la siguiente manera:
Esto permite:
Como estas opciones de almacenamiento se integran directamente en la configuración del SDK y la puerta de enlace de IA, los datos de observabilidad siguen las mismas garantías de residencia que el tráfico de inferencia.
Cada modo de aplicación resuelve un problema diferente:
Juntos, garantizan que se haga cumplir la residencia de los datos:
Este enfoque por capas es lo que permite a TrueFoundry convertir la residencia de datos en un configuración óptima en un propiedad del sistema verificable y aplicada en tiempo de ejecución.
En True Foundry, la residencia de los datos se aplica mediante capas múltiples y explícitas dentro de AI Gateway, cada uno de los cuales aborda una clase diferente de riesgo de ejecución.
Estas capas trabajan en conjunto para garantizar que las garantías de residencia se mantengan en condiciones reales.
En los sistemas de IA, las garantías de residencia de datos solo se mantienen si se cumplen en tiempo de ejecución, en todas las rutas de ejecución, no solo durante la operación en estado estacionario. En True Foundry, el AI Gateway es el punto de cumplimiento en el que convergen las decisiones de enrutamiento, los reintentos, la ejecución de los agentes y la observabilidad.
Los siguientes mecanismos explican cómo se aplica la residencia de datos de manera determinista dentro del TrueFoundry AI Gateway.
Los modelos de TrueFoundry están registrados en afinidad de región explícita. El AI Gateway evalúa las restricciones de residencia antes del enrutamiento cualquier solicitud y solo selecciona puntos finales modelo que sean aptos para la región permitida de la carga de trabajo.
Esto evita:
Porque la residencia se trata como restricción de enrutamiento estricto, no es una preferencia, nunca se consideran los modelos que no cumplen con las normas, incluso si están disponibles o son más rápidos.
Los reintentos y las rutas de conmutación por error son la fuente más común de violaciones silenciosas de residencia de datos en sistemas de IA.
La puerta de enlace de IA de TrueFoundry aplica:
Esto garantiza que los mecanismos de disponibilidad nunca anulen la intención de cumplimiento. Si una ruta compatible no está disponible, el sistema falla de forma explícita en lugar de enrutar los datos entre regiones.
Para las cargas de trabajo de las agencias, la residencia de los datos debe permanecer uniforme en todas partes inferencia de modelos e invocación de herramientas posteriores.
TrueFoundry aplica:
Esto elimina un modo de error común en el que la inferencia sigue siendo compatible, pero los agentes filtran datos de forma indirecta a través de herramientas o servidores MCP implementados en otras regiones.
Los canales de observabilidad con frecuencia se pasan por alto en los diseños de residencia de datos, a pesar de que a menudo contienen datos altamente sensibles.
La puerta de enlace de IA de TrueFoundry garantiza que:
Esto cierra una de las brechas de residencia más persistentes en los sistemas de IA, donde la inferencia cumple con las normas, pero los registros y las trazas no.
Estos mecanismos de cumplimiento se aplican de manera uniforme en:
Porque la aplicación ocurre antes de la ejecución, la residencia de datos se convierte en propiedad verificable del sistema, no es una configuración óptima vinculada a la ubicación de la infraestructura.
La mayoría de las infracciones de residencia de datos en los sistemas de IA no se deben a errores de configuración obvios. Surgen de casos extremos y rutas de excepción que rara vez se prueban hasta que algo sale mal.
A continuación se muestran los escenarios de fracaso más comunes a los que se enfrentan las empresas y cómo Puerta de enlace de IA TrueFoundry está diseñado para prevenirlas.
Qué ocurre en muchos sistemas
Un punto final del modelo regional deja de estar disponible. El AI Gateway vuelve a intentarlo automáticamente o conmuta por error al siguiente punto final disponible, a menudo en otra región.
Desde el punto de vista de la disponibilidad, esto parece un éxito.
Desde el punto de vista del cumplimiento, se trata de una violación silenciosa.
Cómo evita esto TrueFoundry
Esto asegura que los mecanismos de disponibilidad nunca anulan la política de residencia.
Qué ocurre en muchos sistemas
Algunos modelos se implementan en la región, mientras que otros (a menudo copias de seguridad o modelos más nuevos) se alojan en todo el mundo. Las políticas de enrutamiento seleccionan involuntariamente modelos no residentes.
Cómo evita esto TrueFoundry
Esto hace que las garantías de residencia sean resistentes a la rotación de modelos y a la experimentación.
Qué ocurre en muchos sistemas
La inferencia se ejecuta localmente, pero los agentes invocan herramientas o servidores MCP implementados en otras regiones, lo que genera un movimiento indirecto de datos.
Cómo evita esto TrueFoundry
Esto mantiene la residencia uniforme en todas las inferencias y ejecución posterior.
Qué ocurre en muchos sistemas
Las indicaciones, las respuestas y los seguimientos se exportan a servicios centralizados de registro o supervisión fuera de la región, a menudo de forma predeterminada.
Cómo evita esto TrueFoundry
Esto cierra una de las brechas de cumplimiento que más se pasan por alto en los sistemas de IA.
Las garantías de residencia solo tienen sentido si pueden ser verificado y demostrado. TrueFoundry permite a las empresas validar la residencia de los datos mediante visibilidad y auditabilidad del tiempo de ejecución, no suposiciones posthoc.
El AI Gateway proporciona visibilidad de:
Esto permite a los equipos confirmar que cada ruta de ejecución siguió cumpliendo con los requisitos.
Para las revisiones de cumplimiento y seguridad, TrueFoundry presenta:
Esto hace posible demostrar la residencia durante las auditorías, en lugar de basarse únicamente en diagramas arquitectónicos.
Una ventaja clave de la aplicación a nivel de puerta de enlace es la capacidad de prueba.
Las empresas pueden:
Esto convierte la residencia de un requisito estático en un propiedad del sistema verificable de forma continua.
En los sistemas de IA modernos, la residencia de los datos no se puede garantizar únicamente con las opciones de implementación. El enrutamiento dinámico, los reintentos, los flujos de trabajo de los agentes y los canales de observabilidad introducen rutas de ejecución en las que los datos pueden cruzar silenciosamente las fronteras regionales.
El Puerta de enlace de IA es la única capa con suficiente contexto para evitarlo. Ve cada solicitud de inferencia, cada reintento, cada acción del agente y cada rastreo emitido por el sistema. Si la residencia no se aplica aquí, no se puede hacer cumplir de manera uniforme en ningún otro lugar.
En True Foundry, la residencia de datos se trata como propiedad del sistema de ejecución. Las rutas de ejecución están restringidas por el diseño, los casos de excepción no se cierran y la aplicación es observable y auditable. Esto hace que las garantías de residencia sean resilientes no solo durante el estado estacionario, sino también en caso de fracaso, escala y cambio.
Para las empresas que implementan la IA en entornos regulados o multirregionales, esa distinción es importante. La residencia de datos ya no es una casilla de verificación, sino un compromiso arquitectónico. Y el AI Gateway es el lugar donde ese compromiso se hace realidad.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


