

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Todos hemos tenido ese momento con el intérprete de código de ChatGPT (ahora «Análisis avanzado de datos»). Subes un CSV desordenado, le pides que «fije las fechas y trace la tendencia» y observas con asombro cómo escribe y ejecuta código Python en tiempo real.
Es una superarma de productividad. También es un enorme agujero de seguridad si trabajas con datos confidenciales.
En el momento en que subes ese CSV, sale de tu perímetro. Para nuestro equipo, el objetivo era replicar esta capacidad de «código abierto», es decir, dar a nuestros agentes de LLM la capacidad de escribir y ejecutar código, sin correr el riesgo de que se filtren los datos. No queríamos una API de «caja negra»; necesitábamos una Intérprete de código privado donde el cálculo ocurre junto a los datos.
Así es como implementamos el uso seguro de herramientas y la ejecución de código utilizando los componentes de infraestructura de TrueFoundry.
«OpenCode» no se trata solo de tener un modelo que pueda escribir Python. Requiere tres componentes distintos que trabajen al unísono:
La mayoría de la gente se queda atrapada en «The Hands». No puede simplemente dejar que un LLM ejecute os.system ('rm -rf /') en su clúster de producción. Necesitas un sandbox.
TrueFoundry resuelve esto al permitirnos implementar entornos de ejecución efímeros (Servicios o trabajos) que actúan como caja de arena. LLM Gateway gestiona las definiciones de uso de las herramientas y la ejecución propiamente dicha se lleva a cabo en un contenedor cerrado dentro de nuestra VPC.
Este es el flujo de trabajo de cómo una solicitud de usuario se convierte en una ejecución segura de código.
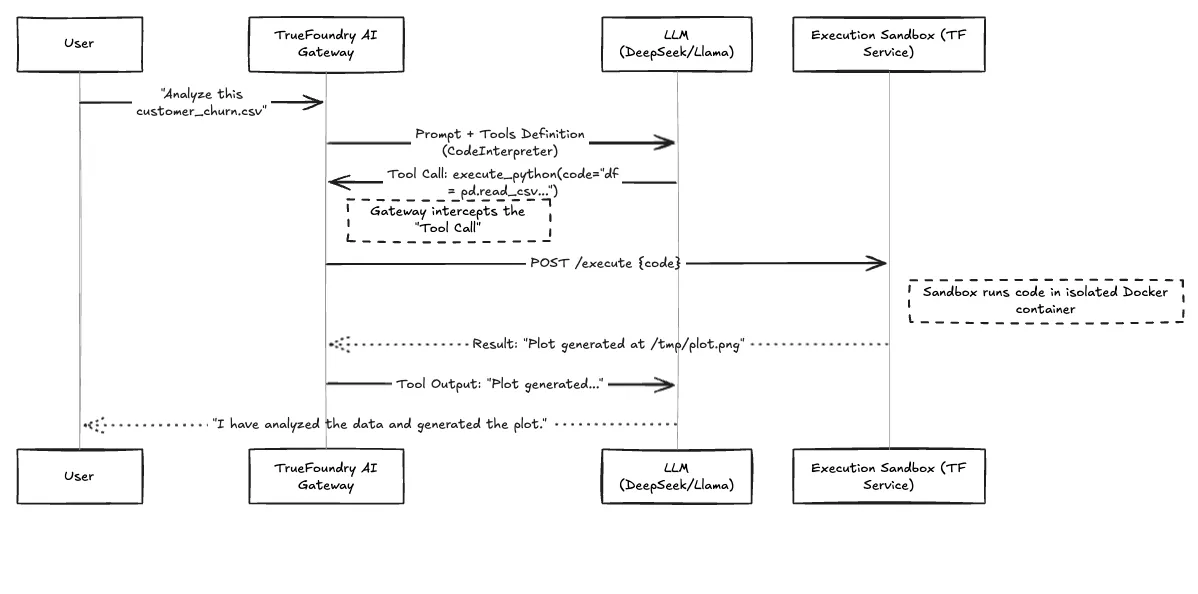
Figura 1: Flujo de trabajo del bucle de ejecución de OpenCode
Cuando intentamos crear esto por primera vez, subestimamos la complejidad del entorno de ejecución. Si utilizas una API de interpretación de código SaaS estándar, les estás enviando tus datos. Si la ejecuta localmente, corre el riesgo de comprometer el host.
Utilizamos TrueFoundry Servicios para alojar un «agente de ejecución de código» personalizado. Básicamente, se trata de un servicio FastAPI de Python incluido en un contenedor Docker que tiene:
Como TrueFoundry administra el manifiesto subyacente de Kubernetes, podemos inyectar estas restricciones de seguridad (SecurityContext, NetworkPolicies) directamente desde la interfaz de usuario de implementación o desde Terraform, garantizando que el entorno de pruebas sea realmente un entorno de pruebas.
La contrapartida siempre ha sido la comodidad frente al control. Al aprovechar TrueFoundry para orquestar el patrón de «código abierto», cambiamos el equilibrio. Tenemos la comodidad de una implementación gestionada sin el riesgo de los datos.
Tabla 1: Este es el ejemplo de comparación de Gateway y Sandbox
El verdadero poder se desbloquea cuando combinas Uso de herramientas con tus API internas.
Configuramos TrueFoundry LLM Gateway para exponer no solo la herramienta «Python Interpreter», sino también las herramientas para nuestro lago de datos interno (por ejemplo, get_user_churn_metrics (user_id)).
Como el LLM pasa por la puerta de enlace y la puerta de enlace está conectada a nuestros servicios privados, el modelo ahora puede:
Todo esto ocurre sin que un solo byte de datos de clientes salga de nuestra subred privada.
La implementación de «OpenCode» ya no es solo un divertido proyecto de hackathon; es un requisito para los agentes de IA modernos. Pero no puedes simplemente hackearlo junto con LangChain y esperar lo mejor.
Tratamos a nuestro intérprete de código como infraestructura crítica. Lo supervisamos utilizando el sistema de observabilidad de TrueFoundry, que no solo rastreamos los tokens de LLM, sino también los picos de CPU en el entorno de pruebas y la latencia de ejecución. Si un usuario escribe un script para intentar asignar 50 GB de RAM, TrueFoundry elimina el pod antes de que afecte al clúster, y el usuario recibe un mensaje de error amable.
Esa es la diferencia entre una demo y una plataforma.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


