

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Hemos superado la fase de «echa un vistazo a esta fantástica demostración» de Voice AI. Las empresas ya no se limitan a desarrollar lindas habilidades de Alexa. Están desplegando sistemas complejos y multimodales diseñados para gestionar millones de interacciones delicadas con los clientes, desde transferencias bancarias hasta la clasificación de los servicios de salud.
Pero he aquí la incómoda verdad sobre el traslado de la IA de voz del prototipo a la producción: es increíblemente frágil.
A diferencia de los chatbots basados en texto, donde un error es solo una mala respuesta de texto, un error en Voice AI es visceral. Es aire muerto. Es una voz robótica tartamudeando. Es un cliente que grita «¡agente!» repetidamente porque la latencia en la búsqueda RAG tardaba 400 ms de más y el ASR los cortaba.
Cuando se está organizando un paquete extenso que incluye el reconocimiento automático de voz (ASR), la clasificación compleja de intenciones, la generación aumentada de recuperación (RAG) mediante agencias y la conversión de texto a voz (TTS) realista, las herramientas estándar de monitoreo de aplicaciones (APM) son lamentablemente inadecuadas. Te lo dicen eso algo se rompió, pero rara vez por qué.
Esta publicación analizará un caso de uso empresarial realista y a gran escala para demostrar por qué la observabilidad especializada no es negociable y cómo plataformas como TrueFoundry se están convirtiendo en el plano de control de estos sistemas complejos.
Para entender el desafío de la observabilidad, primero debemos observar a la «bestia» que estamos intentando domar. Un agente de voz moderno y conversacional no es un modelo único; es una carrera de relevos de componentes altamente especializados, que a menudo se distribuyen en diferentes infraestructuras.
Si un solo traspaso en esta carrera de relevos fracasa, toda la experiencia del usuario se bloquea.
Imaginemos a Apex Financial, un banco grande que implementa un asistente de voz para gestionar las transacciones de nivel intermedio, como comprobar los saldos de diferentes clases de activos e iniciar transferencias internacionales.
La escala: 50 000 llamadas simultáneas durante las horas pico.
Lo que está en juego: mucho. Malinterpretar «cincuenta» con «sesenta» durante una transferencia es catastrófico.
La pila:
Llama una clienta, «Sarah». Tiene un ligero ruido de fondo y dice: «Tengo que enviarle 5000 libras a mi hermano en Londres con mis ahorros».
Así es como se ve ese flujo de trabajo y dónde suelen salir mal las cosas.
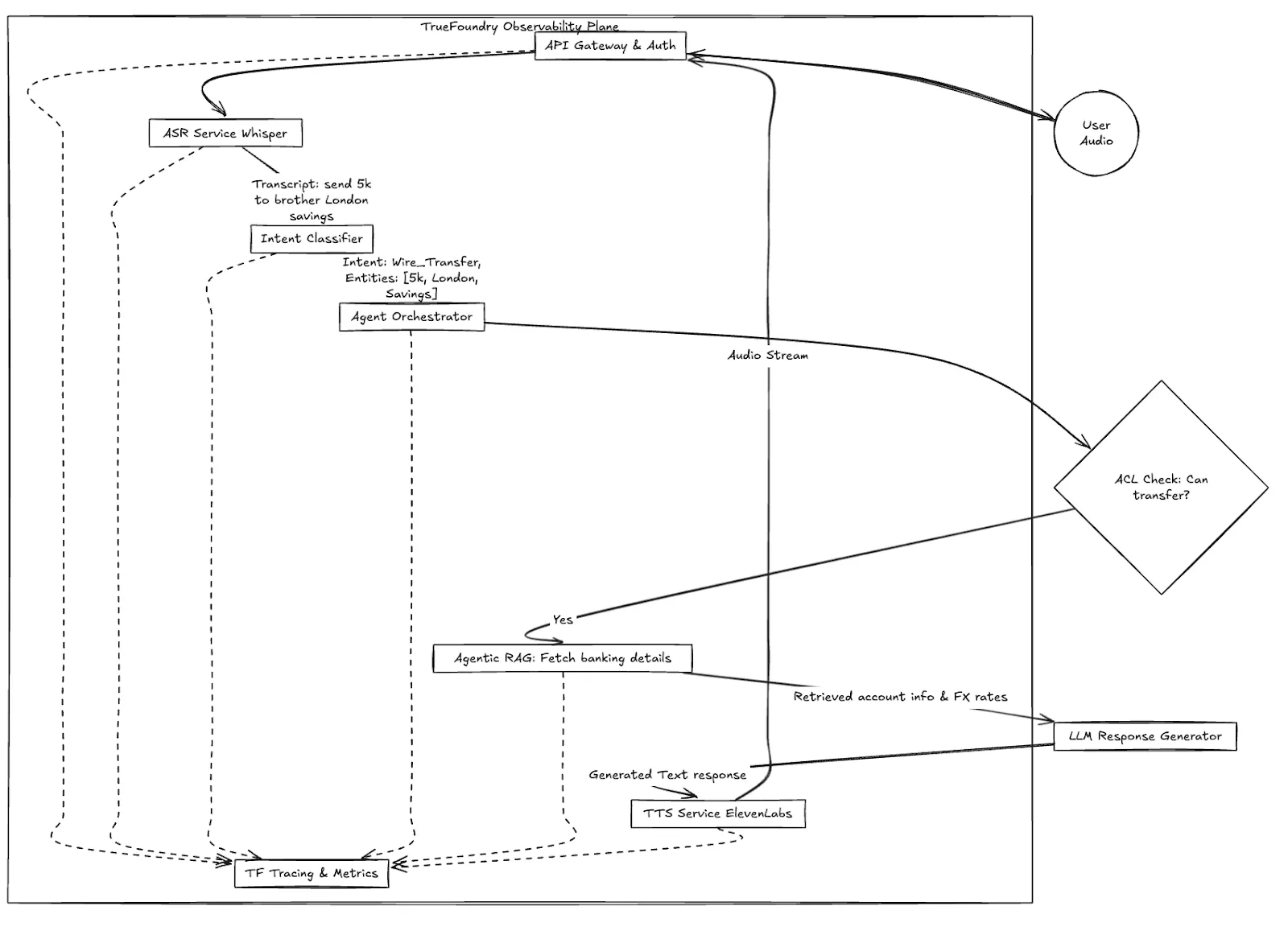
Figura 1: Flujo de trabajo de alto nivel de la transacción de voz de Apex Financial, que muestra el papel fundamental del plano de observabilidad.
En una configuración estándar, si la llamada de Sarah falla, el equipo de ingeniería recibe una multa que dice: «El robot de voz colgó».
Comprueban Datadog o Prometheus. La CPU está bien. La memoria está bien. Los módulos de Kubernetes están listos. ¿Qué pasó?
Sin una observabilidad de IA de voz especializada, depurar esto es como resolver un misterio laberíntico sin herramientas forenses.
En un sistema de IA de voz distribuido, la latencia es acumulativa. Un retraso de 200 ms en ASR más un retraso de 400 ms en RAG equivale a una experiencia de cliente fallida. Se necesita un rastreo que comprenda los fotogramas de audio, no solo las solicitudes HTTP.
Aquí es donde plataformas como TrueFoundry se están volviendo esenciales. TrueFoundry no es solo otro panel de monitoreo; es una infraestructura de inteligencia artificial y aprendizaje automático y una plataforma de observabilidad creada específicamente para las complejidades de las pilas de GenAI, incluida la voz.
TrueFoundry trata toda la cadena, desde el primer paquete de audio hasta la transmisión TTS final, como un flujo observable.
Así es como aborda las necesidades empresariales críticas que las herramientas genéricas no tienen en cuenta:
El seguimiento estándar muestra los tiempos de salto de servicio a servicio. El rastreo especializado de TrueFoundry le permite visualizar el presupuesto de latencia de una conversación en tiempo real.
Puede ver que, en la llamada de Sarah, el ASR tardó 350 ms (aceptable), pero el paso con el RAG de Agentic tardó 2,1 segundos (inaceptable). Puede profundizar inmediatamente en el paso del RAG: ¿se trataba de la recuperación de la base de datos vectorial? ¿Fue el modelo de cambio de clasificación?
Deja de adivinar y empieza a arreglar el cuello de botella.
Cuando tu IA de voz usa un agente para tomar decisiones (como comprobar si Sarah tiene fondos suficientes) delante de preguntando por el destino), es necesario auditar el «proceso de pensamiento» del agente.
TrueFoundry proporciona observabilidad en los pasos intermedios del agente. No solo está viendo la entrada y la salida; está viendo las herramientas que el agente seleccionó, las consultas que ejecutó en la base de datos vectorial y el contexto sin procesar que recuperó. Si el bot da una respuesta incorrecta, puedes ver exactamente qué datos obsoletos ha recuperado del sistema RAG y que han causado la alucinación.
En la banca, «quién puede hacer qué» es primordial. No puedes permitir que tu robot de voz de marketing acceda accidentalmente al agente de transacciones.
TrueFoundry proporciona listas de control de acceso (ACL) sólidas que rigen qué modelos y agentes pueden interactuar. Además, a medida que crecen los sistemas multiagente, TrueFoundry está adoptando estándares como el Model Context Protocol (MCP) para garantizar una comunicación autenticada y segura entre los diferentes agentes de IA de su ecosistema.
La observabilidad aquí no es solo el rendimiento; es la auditoría de seguridad. Necesitas un registro que demuestre por qué Al agente A se le negó el acceso a la fuente de datos B durante una llamada en vivo.
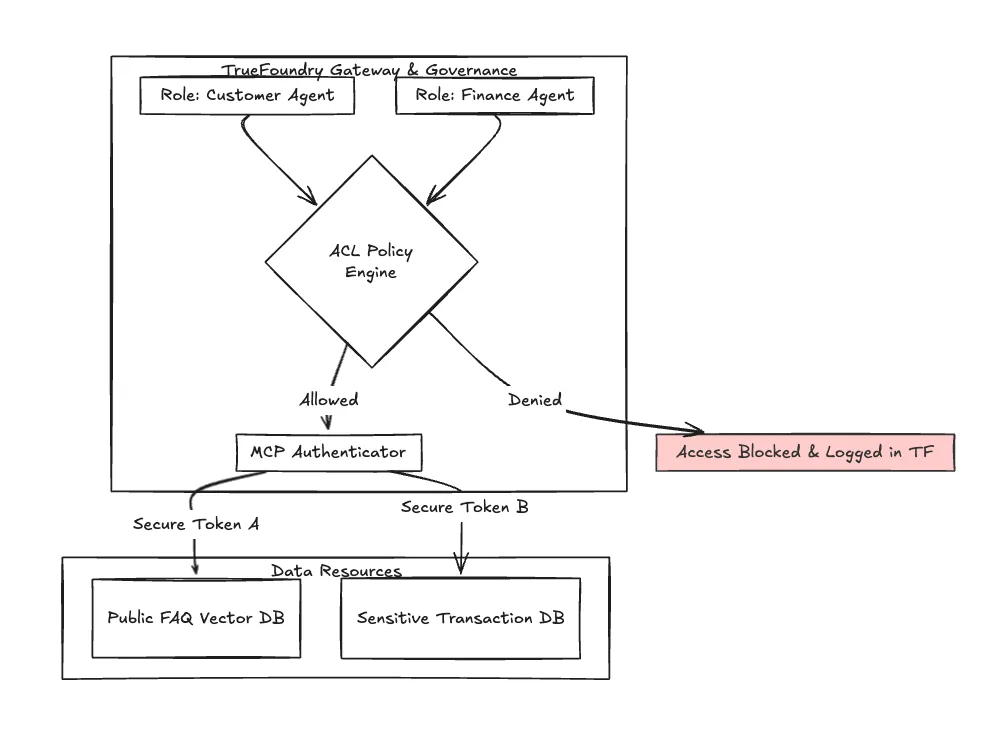
Figura 2: Vista simplificada del flujo de autenticación de ACL y MCP administrado dentro del ecosistema de TrueFoundry, lo que garantiza el aislamiento de los agentes de voz sensibles.
Para resumir la diferencia entre el monitoreo estándar y lo que se requiere para la IA de voz empresarial:
Tabla 1: Comparación de las profundidades de observabilidad de la IA de APM estándar con las de TrueFoundry Voice.
Para Apex Financial, la implementación de TrueFoundry supuso la diferencia entre revertir su programa de asistente de voz y ampliarlo. Pasaron de un tiempo medio de detección (MTTD) de horas a minutos. Pudieron identificar de forma proactiva que un modelo de incrustación RAG específico estaba provocando picos de latencia durante los períodos de gran volumen delante de los clientes empezaron a colgar.
Al crear una IA de voz empresarial, los modelos que elija (Whisper, ElevenLabs, GPT-4O) son solo el motor. La observabilidad es el sistema de aviónica. No deberías intentar volar un jet solo con un velocímetro; no intentes utilizar un sistema de voz empresarial sin una capacidad de observación profunda y especializada.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


