

July 21, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
El equipo de ventas está en pánico: la semana que viene habrá una importante conferencia sobre el cuidado de la salud. En el sitio web del evento figuran 200 ponentes (médicos, ejecutivos e investigadores) repartidos en una docena de subpáginas paginadas. Para crear una lista de clientes potenciales, alguien tiene que abrir el sitio, hacer clic en un nombre, copiar los detalles en una hoja de cálculo, abrir una nueva pestaña, buscar a esa persona en LinkedIn, copiar la URL del perfil y volver a pegarla.
Tienen que hacerlo 200 veces.

Para los ingenieros, esta solicitud suele dar como resultado una secuencia de comandos rápida de Python que utiliza Selenium o BeautifulSoup. Inspecciona la fuente de la página, busca el div con el nombre del orador de la clase y extrae el texto. Funciona perfectamente durante aproximadamente una semana. Luego, el sitio web actualiza su marco de interfaz, las clases de CSS cambian y el script se bloquea.
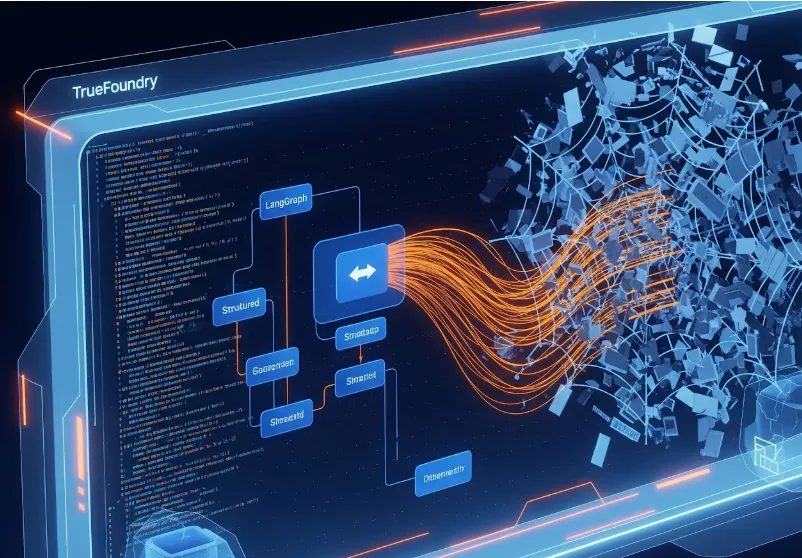
Construimos el Perfil: Crawler acelerador para detener este ciclo. Es un agente autónomo que navega por los sitios web y extrae datos basándose en lo que dice la página, no en cómo está estructurado el HTML.
Así es como diseñamos la solución utilizando LangGraph para la orquestación, Playwright para la interacción y TrueFoundry para administrar la infraestructura.
La razón principal por la que los scripts de scraping fallan es porque se basan en el Document Object Model (DOM). Si le dices a un script que busque div.content-wrapper > h2.title, se interrumpirá en el momento en que un desarrollador cambie el nombre de una clase.
Pasamos a un enfoque de agencia. No se lo decimos al bot donde los datos están ubicados en píxeles. En su lugar, enviamos el HTML renderizado (convertido a Markdown) a un LLM. El modelo lee el texto igual que lo haría un humano. Entiende que una sección denominada «Oradores principales» contiene los datos que queremos, independientemente de las etiquetas subyacentes.
Necesitábamos un sistema que pudiera gestionar la toma de decisiones, no solo un guion lineal. La aplicación debe decidir: ¿Esta entrada es una URL o solo el nombre de una empresa? ¿Hemos conseguido un captcha? ¿Esta página es una lista de personas o una sola biografía?
Elegimos LangGraph para modelar este flujo de trabajo como una máquina de estados, especialmente cuando Langflow frente a LangGraph las decisiones favorecen la orquestación estatal.
El sistema funciona en bucle en lugar de en línea recta:
Esta es la arquitectura del sistema:
La ejecución de navegadores sin memoria y agentes de LLM en producción crea problemas operativos: pérdidas de memoria de Chromium, límites de velocidad en las API de LLM y la necesidad de aislar los procesos.
Lo implementamos en True Foundry para hacer frente a estas restricciones específicas.
Esta aplicación hace un uso intensivo de los LLM para tomar decisiones de navegación. Sin gobernanza, los costos se disparan rápidamente. Redirigimos todas las llamadas modelo a través del Puerta de enlace de IA TrueFoundry.
Estructuramos la aplicación utilizando Protocolo de contexto modelo (MCP). El «Crawler» no es solo una función de Python, es un servidor MCP. Esto nos permite configurar el entorno del navegador en un entorno aislado. Si el navegador se bloquea (lo que ocurre con frecuencia en sitios con mucho contenido de JavaScript), no se elimina la lógica principal de la aplicación.
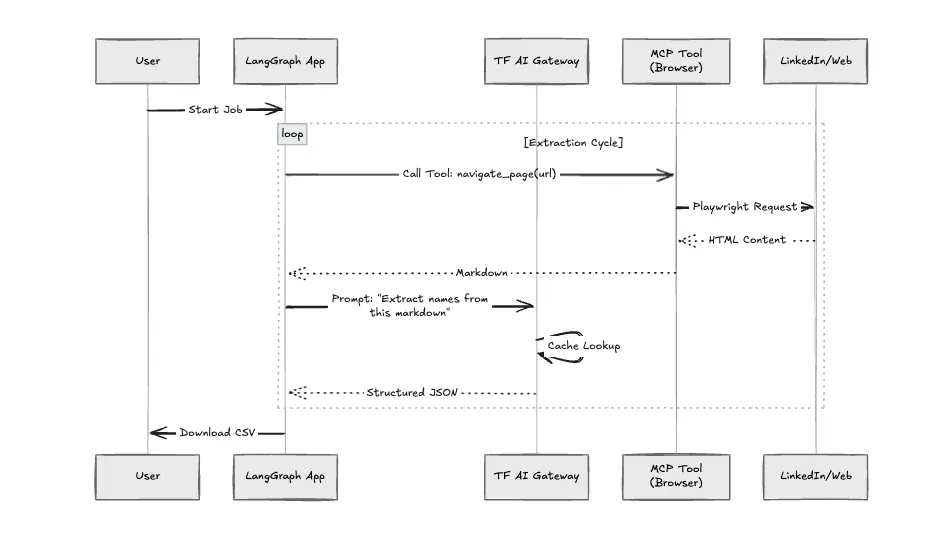
Comparamos el enfoque estándar del script de Python con esta arquitectura.
Construir el camino feliz es fácil. Hacerlo confiable requirió resolver tres problemas de ingeniería específicos:
Esta arquitectura resuelve la «última milla» de la adquisición de datos al reemplazar los frágiles scripts por agentes adaptables. Al ejecutarlo en TrueFoundry, nos aseguramos de que el sistema sea observable, con costos controlados y escalable.
Hoy mismo puede implementar esta arquitectura exacta, incluida la configuración de Gateway y los agentes dockerizados, desde la biblioteca de aplicaciones de TrueFoundry.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


