Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
Isn’t OCR and Document Processing a solved problem?
While many believe OCR and document processing are solved technologies, manual data entry costs U.S. companies around $15000 to $30000 per employee per year. Source: The operational and time drain due to manual document processing is still significant because:
Traditional OCR: Brittle and Underperforming
Traditional OCR (Computer Vision + Rules + NLP) methods exhibit low adaptability to various writing formats and layouts, often failing to account for context and data format requirements.
Low Adaptability: Even best-in-class traditional OCR systems plateau at 85-90% accuracy for complex documents, with handwritten content dropping to a mere 64% accuracy rate. Source
Poor Image quality or lighting: 300 DPI is the standard minimum for optimal OCR results
Noise
Skew and Orientation
Template and Layout Dependence: Fine-tuned to work on a specific template, needs custom downstream processing pipelines or a change in template for each new doc type/template update. E.g., New invoice format from a vendor, a slightly shifted column in a report
Context Blindness: Character-level OCR fails to differentiate between similar characters, losing document-wide context understanding. E.g. "50mg Metformin" might be read as "5Omg Metformin" which is incorrect for any downstream medical task.
OCR/LLM Accuracy by Document Type
Document Type
Traditional OCR
SmolDocling (2B)
Qwen-VL-Max (18B)
GPT-4o
Gemini 2.5 Pro
Claude 3.7 Sonnet
Human Baseline
Clean Printed Text
97–98%
92–95%
97–98%
99–99.5%
99–99.5%
99–99.5%
99.8%
Tables & Forms
80–85%
83–87%
91–94%
96–98%
95–97%
95–97%
98–99%
Handwriting (Print)
70–80%
65–75%
80–85%
86–90%
88–92%
89–93%
96–98%
Handwriting (Cursive)
50–70%
60–70%
75–80%
82–90%
80–89%
81–90%
95–97%
Low-Quality Scans
60–75%
80–85%
90–93%
93–96%
92–95%
93–95%
95–97%
Mathematical Notation
70–80%
75–80%
88–93%
92–96%
94–97%
94–96%
97–99%
LLM-Based OCR: Unpredictable and Costly
LLM-based OCRs solve some challenges in traditional methods but introduce new complexities:
Not solved for Handwritten text: Despite GPT-4V and Claude 3.5 Sonnet achieving 82-90% accuracy on handwritten text, a significant improvement, this still falls short of business-critical thresholds. E.g. In healthcare, a 10-18% error rate on handwritten prescriptions could literally be life-threatening.
Difficult to Scale:
Prohibitively Expensive: For organisations processing millions of documents each year.
Slower responses:
Difficult to maintain SLAs in self-hosted
Downtimes and Latency spikes with 3rd party providers
Inconsistent Outputs:
Hallucinations - e.g., a completely fabricated value for a clause in a legal document
Difficult to comply with structured output
Same prompt, different responses
In Industries such as financial services and healthcare, that process millions of critical documents annually, a system that can scale reliably and generate high quality output at low cost is essential
TrueFoundry’s Intelligent Document Processing (IDP) is a Generative AI-based Accelerator that combines production-ready practices with a highly customizable and accurate OCR pipeline to build and ship end-to-end document processing workflows.
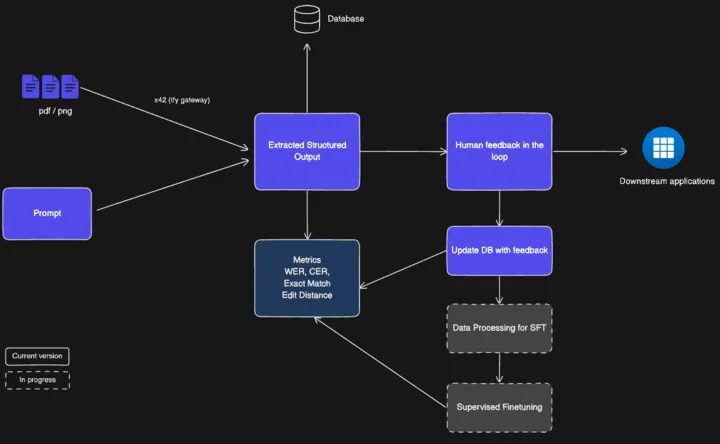
How It Works: Powering your applications with structured data in minutes!
The accelerator ingests your PDFs, images, or faxes and cleans them up: denoising, de-skewing, and upscaling. So models start from a crisp image. It then classifies each document (invoice, prescription, handwritten note) and attaches the correct schema, prompts, and domain rules. The extraction model pulls structured fields and confidence scores; a rules engine validates and enriches them with checks and lookups. Items are routed to a reviewer through a simple UI, and every correction feeds back to improve the system continuously.
Customisable and Modular Components
The Accelerator is composed of pluggable modular components that together can build both a day 1 prototype or a full-scale production-ready application.
Basic Components
Multi-Model Support (OSS & Closed-Source)
Human-in-the-Loop (HITL) & Feedback
Integrated Fine-Tuning Infrastructure
Monitoring & Observability
Knowledge Base Integration (RAG + Knowledge Graph)
Advanced Components
Automated Classification & Routing
Region-Aware OCR & Bounding Boxes
Schema Auto-Discovery (Zero-Shot)
Validation & Post-Processing
Compliance & Auditability
Our Design has been validated across multiple Enterprise Implementations
Build For Choice and Control
The accelerator is model-agnostic, OSS or closed-source, and can route across providers for price/performance and failover. Experts stay in the loop with a domain-tuned review UI whose edits become training data.
Operational from day one.
You get real-time observability (latency, throughput, cost per doc) plus business KPIs—STP, field accuracy, and edit rate. Validation and enrichment enforce cross-field rules and normalize formats before the data reaches downstream applications.
Adaptable, especially for those complex Enterprise Use Cases
Schema discovery, region-aware OCR, and knowledge-base grounding handle complex layouts; audit logs preserve every action, score, and override for regulated environments.
How do we ensure this system scales?
Our architecture is a cloud-agnostic, microservices-based blueprint designed for enterprise-grade reliability, scalability, and cost-efficiency. By decoupling core components with asynchronous message queues, the system handles fluctuating workloads and component failures without data loss, avoiding vendor lock-in.
Ingestion Layer
Stateless LLM gateway: Single entry point (auth/rate-limit) that enqueues every document to a message topic.
Durable buffering: Raw uploads are written to object storage for replay, audit, and recovery.
Processing Pipeline
Service isolation: Separate workers for classification, extraction, and validation; each can be updated and scaled alone.
Independent autoscaling: CPU/GPU-heavy extractors scale up during peaks without impacting lighter stages.
Idempotent jobs: Replayable tasks with dedup ensure safe retries and exactly-once outputs.
Data & State Management
Portable storage: S3-compatible buckets hold documents and artifacts with versioning.
Relational backbone: PostgreSQL-compatible DB tracks metadata, workflow state, and HITL queues.
Schema contracts: Clear interfaces between services enable safe, backward-compatible changes.
Feedback & MLOps Layer
Human loop: Verified corrections are captured with provenance for training data.
Closed loop: Automated retrain/evaluate/deploy pipelines push better models back to production.
Governed releases: Model registry, A/B checks, and rollbacks keep improvements safe and auditable.
Conclusion
Modern OCR isn’t “solved”, especially when accuracy, scale, and cost matter. TrueFoundry’s IDP Accelerator offers a pragmatic, production-ready approach, featuring multi-model extraction, automated validation, and a human-in-the-loop that continuously enhances the system. The result is faster straight-through processing, higher field-level accuracy on the documents that actually run your business, and a platform your teams can operate, not just a demo to admire.
This accelerator helps you process more documents efficiently and cost-effectively, while maintaining data integrity for auditors, experts, and operators, enabling immediate implementation without the need for extensive custom engineering.
Pilot in production: Connect with us using this link. We can create a working prototype on your own use case and help you deliver a production-ready application in 1/10th the normal development time!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.



























.webp)











.webp)
.webp)
.webp)


