














July 3, 2026
|
5 min read

Published: June 25, 2026

Blazingly fast way to build, track and deploy your models!
CI/CD has quietly become one of the largest LLM cost lines in modern engineering organizations. A single security-review agent firing on every pull request can outspend the entire engineering team's customer-facing AI workload by a factor of three. The provider invoice tells you the total. It does not tell you which pipeline, which repository, or which agent step caused it. Without that attribution, the only available response is a blanket ban, and the productivity loss exceeds the original overrun.
TrueFoundry's AI Gateway closes that gap with three primitives — mandatory metadata tagging on every request, hierarchical per-cost-center budgets with soft, constrained, and hard thresholds, and a rolling P95 forecast that surfaces overruns before they hit the invoice. The configurations in this post are real, copy-pasteable, and based on TrueFoundry's official Budget Limiting and Rate Limiting schemas.
Production LLM applications run on user traffic, which is bounded by user count and request frequency. CI/CD pipelines run on machine traffic — automated agents, scheduled jobs, periodic regressions, every-PR reviews. The cost shape is fundamentally different. A team of 50 engineers, each opening 15 pull requests per week, generates 750 PR-driven LLM invocations per week before anyone touches a user-facing feature. Each invocation may chain four or five agent steps. Each step may make multiple model calls with multi-thousand-token contexts. The throughput multiplier between user-facing AI and CI/CD AI is routinely 10x to 100x.
The first time engineering leadership notices is when finance forwards an invoice with a number that does not match anyone's mental model. The story repeats at every organization that rolls out agentic CI/CD without observability: October is a small bill, November is medium, December is the month that prompts an executive meeting. The pattern is consistent enough that platform teams should treat it as the operating expectation, not a surprise.
The provider's invoice — Anthropic, OpenAI, Bedrock, or any other — itemizes by model and token type. It cannot itemize by repository, by pipeline, or by agent step, because the provider does not know what those concepts mean inside your engineering organization. That information lives in your request metadata, which the provider never sees. From the provider's perspective, all 847 million Sonnet input tokens last month look identical; from your perspective, 80% of them came from one runaway pipeline you would have throttled in week one if you had known.
The mismatch between what finance receives and what engineering needs to debug is the structural reason cost-governance projects stall. Finance receives a bill. Engineering receives the same bill with no breakdown. Without a per-workload ledger, the response collapses to "stop spending on AI for two weeks while we figure this out," which kills the productivity gain the AI was producing.
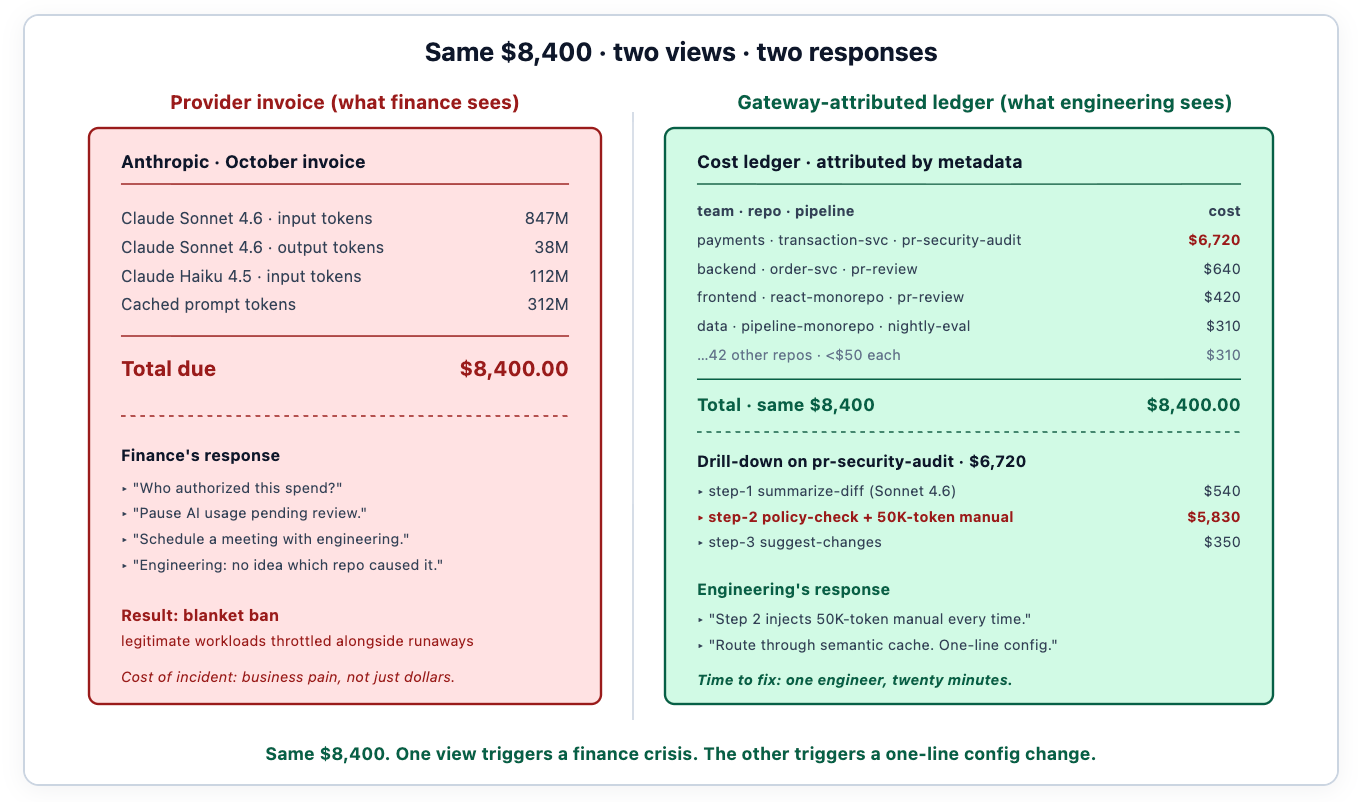
The same dollar figure produces opposite responses depending on whether the team has attribution. Without it, the response is structural: ban the spend, escalate to leadership, schedule a meeting that's going to feel bad for everyone. With it, the response is one engineer reading the cost ledger, identifying that step 2 of one specific pipeline is injecting a 50,000-token policy manual into every prompt, and writing a one-line config change to route step 2 through the semantic cache. Same invoice. Different outcome.
The foundation of cost attribution is mandatory tagging at the gateway. CI/CD pipelines have to inject identity on every request — identifying the team, the repository, the pipeline, the agent step, and the cost center responsible. Per TrueFoundry's request-headers documentation, that identity travels in a single header — x-tfy-metadata — whose value is a stringified JSON object with string keys and string values, capped at 128 characters per value. The fields inside the JSON are conventions chosen by the platform team; they are not HTTP headers in their own right.
A correctly-formed request from a CI/CD pipeline looks like this on the wire:
POST /api/llm/api/inference/openai/chat/completions HTTP/1.1
Host: gateway.truefoundry.ai
Authorization: Bearer {TFY_API_KEY}
Content-Type: application/json
x-tfy-metadata: {"team":"payments-platform","repo":"transaction-service","pipeline":"pr-security-audit","agent_step":"step-2-policy-check","cost_center":"eng-backend","run_id":"gh-run-882134"}The gateway documentation enumerates exactly nine accepted custom request headers: Authorization, x-tfy-metadata, x-tfy-provider-name, x-tfy-strict-openai, x-tfy-retry-config, x-tfy-request-timeout, x-tfy-ttft-timeout-ms, x-tfy-logging-config, and x-tfy-mcp-headers. Custom identity — team, repo, pipeline, cost_center, run_id, anything else the platform team defines — lives strictly inside the JSON value of x-tfy-metadata, not as separate headers. This is the only contract the gateway recognizes. Teams that invent additional x-tfy-* headers find them silently ignored — the metadata never reaches the cost-tracking or policy layers, dashboards lose attribution, and audit logs carry only the bearer token. One header, JSON inside, is the rule.
Visibility without enforcement is a dashboard nobody acts on. The gateway attaches hierarchical, mathematically-enforced budgets to every cost center the tagging produces. The payments-platform team gets, say, $500 per week for CI/CD agentic workflows; that budget is enforced at the gateway, in the request path, with three thresholds that fire different responses.
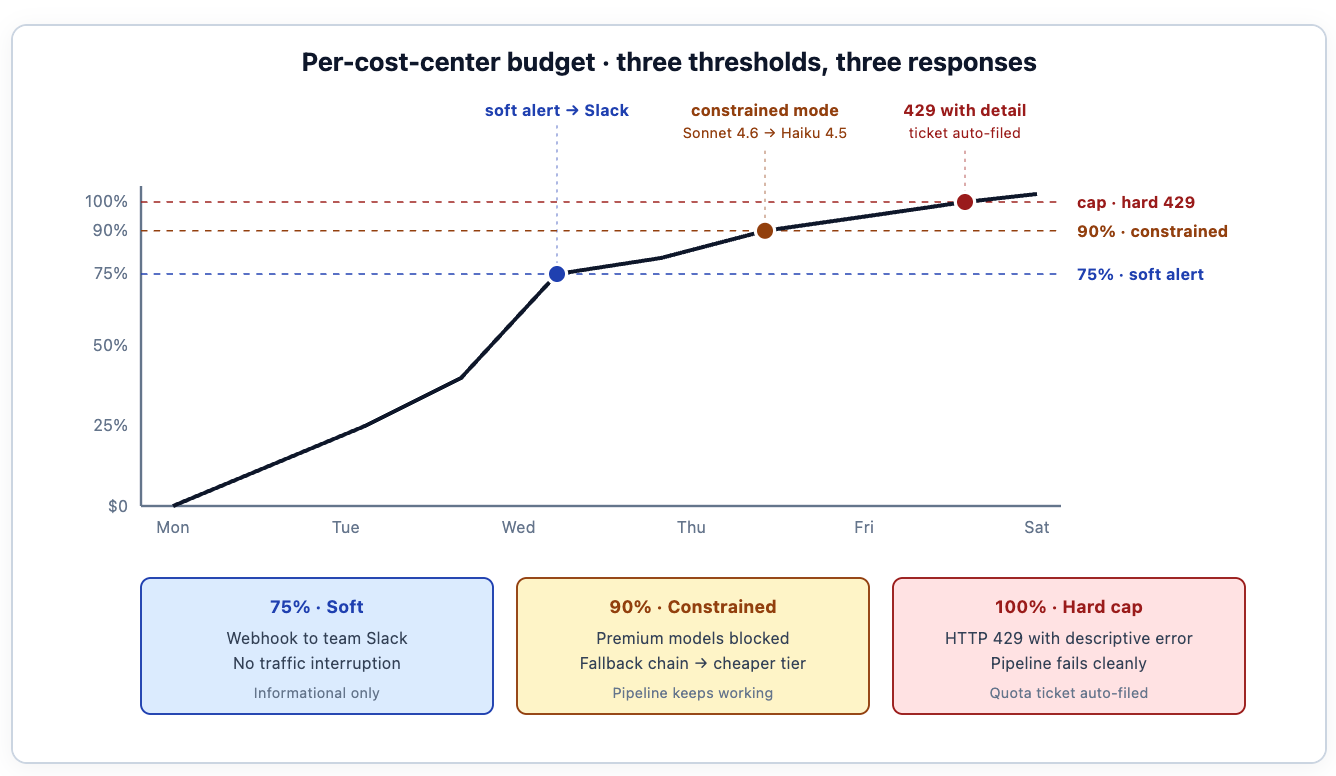
75% of cap — soft alert. A webhook posts to the team's Slack channel: "You're three quarters of the way through this week's AI budget." No traffic interruption. The workload owner sees the alert during normal working hours and can decide whether to tune the agent's behavior, request a quota increase, or do nothing because the spend is legitimate.
90% — constrained mode. Premium models (Sonnet 4.6, Opus 4.7, GPT-4o) are blocked; the gateway transparently routes requests to cheaper fallbacks (Haiku 4.5, GPT-4o-mini) through virtual-model fallback configuration, so pipelines keep working while costs flatten. The fallback chain is defined in a separate routing config — the budget config triggers the constraint, the routing config executes the swap. The application sees a header indicating which model actually served the request, and quality may differ for specific workloads.
100% — hard cap. The gateway rejects further requests with HTTP 429. Below is the shape platform teams typically design for the error body — the gateway's default response is concise, and the team enriches it via their wrapping layer with the cost-center context, the dashboard pointer, and the quota-request flow:
{
"error": "Budget Exceeded",
"detail": "Cost center 'eng-backend' has exhausted its weekly $500 AI budget.",
"context": {
"spent_to_date": "$501.23",
"cap": "$500.00",
"resets_at": "2026-05-19T00:00:00Z",
"top_consumer": "pipeline=pr-security-audit · 87% of spend"
},
"mitigation": "Review pipeline logs for runaway loops, or request a quota increase at /governance/quota."
}The error body is part of the design. A pipeline that hits its budget should know what to do next — read the logs, file a quota request — without the developer having to chase the platform team for context. CI runners interpret 429 as a standard backoff signal; the build fails cleanly with an actionable message rather than crashing in confusing ways. The same 429 pattern composes with the rate-limit and runaway-detection layers, so a workload that exceeds multiple controls receives a coherent failure path rather than a cascade of unrelated errors.
Tagged data flowing into Grafana lets the platform team build dashboards that answer ownership questions instead of generating more aggregate noise. Instead of staring at a spike and asking "who did this?", the dashboard already tells you that at 02:00 UTC the frontend team deployed a new agent to react-monorepo that hallucinated a missing dependency and entered a 400-step resolution loop. The metadata fields surface as Prometheus labels; standard PromQL queries produce per-team, per-repo, per-pipeline breakdowns; standard Grafana dashboards visualize them.
That kind of operational context turns cost from a finance problem into an engineering problem. Once the team can see that switching the initial code-summarization step from Sonnet 4.6 to Haiku 4.5 cuts that step's cost by 80% without affecting PR review quality, they make the change. The argument about budget caps does not need to happen in a steering committee — the data is the argument, and the change is the response.
A useful dashboard has three views: an aggregate cost-per-cost-center over time, a drill-down by pipeline and step, and an anomaly view that surfaces cost outliers automatically. The first two are the operating views; the third is the early-warning view that finds the runaways before the budget breaker does. The OpenTelemetry traces emitted by the gateway include the model, the token counts, the metadata fields, and the dollar amount per call — Grafana's existing tooling handles the rest.
Aggregated tagging data also makes forecasting tractable. Agentic workloads are bursty — periodic heavy CI jobs dominate the bill — which is why simple trailing averages systematically underestimate spend. A team that averaged $40/day for three weeks and $400 on a single Wednesday's release-train run has a trailing average of $51/day; their actual end-of-month spend if they ship two more release trains is north of $2,000.
The gateway runs a 7-day P95 rolling forecast per repo and per cost center. P95 captures the burst risk that an average smooths over, projecting end-of-month spend with enough lead time to adjust budgets, raise quotas, or kill an offending pipeline before finance sees the surprise. "Surprise" is the operating word: this is a forecast designed not to produce them. When the forecast says a team is on track to exceed its monthly budget by 30%, the team has two or three weeks of room to act before the hard cap fires.
The forecast surfaces in the same Grafana dashboard as the realtime spend, with the projection drawn alongside the historical curve. Platform teams reviewing the forecast weekly catch the pattern that produces the next quarter's budget crisis; teams that do not review the forecast learn about the problem the same way they always did — from finance.
What follows is an illustrative composite drawn from patterns this team has seen across real customer deployments — the numbers are stylized to make the mechanics clear, but the failure mode and the fix are both common.
A 50-engineer organization built a three-step Claude Code review agent that ran on every pull request: (1) summarize the diff, (2) review the diff against security policies via an MCP documentation server, (3) suggest code changes. Sensible architecture, useful workflow, no obvious red flags. The agent went into production in early September.
At roughly 15 PRs per engineer per week, accounting for retries and the context-window cost of injecting whole files into prompts, the agent averaged around 400,000 input tokens per PR. Month-one bill for CI/CD automation: $8,400. The bill arrived on October 5th. The Slack message from finance arrived October 6th. The conversation that produced this post arrived October 7th.
Attribution surfaced the actual cause within minutes of the team logging into the cost dashboard. Step 2 was injecting a 50,000-token security manual into every prompt, on every PR, regardless of whether the diff actually touched policy-relevant code. The model was reading the entire manual to assess whether to apply it; the answer was "no, this is a CSS change" 80% of the time; the cost was paid every time. Routing step 2 through the gateway's semantic cache — keyed on the diff's file-extension and content signature — reduced token overhead by 92%. Same coverage. Same suggestions. Monthly bill under $800.
Without attribution, the response would have been a blanket ban on Sonnet for CI workflows. Engineering would have absorbed the productivity hit; finance would have absorbed the political win; nobody would have learned what the actual problem was. With attribution, the response was a one-line config change. That is the difference the data makes.
Two TrueFoundry policy configurations carry the weight of the entire pattern: a budget config that enforces dollar caps with audit modes and alerts, and a rate-limit config that enforces token and request quotas. Both are real schemas — copy these directly into the AI Gateway Policies tab. The schema reference is in the official documentation for Budget Limiting and Rate Limiting. Two semantic points to internalize before deploying these:
First, on rule order and layered tracking: per TrueFoundry's budget documentation, when a request matches multiple rules, the cost is tracked against every matching rule, but only the first matching rule controls the allow/block decision. Rule order in the YAML determines priority — there is no separate priority field. In the configuration below, a payments-platform request matches both the specific payments-platform-weekly rule (first match, controls block decision) and the broad per-user-daily-default rule (also tracks the cost, useful for per-developer visibility). This is intentional: the dashboard shows both the cost-center-level and the per-user-level usage on the same request.
Second, on provider account naming: model identifiers like anthropic-main/claude-opus-4-7 follow the format <provider-account-name>/<model-id>, where the provider account name is whatever the workspace administrator named the Anthropic account in AI Gateway → Models. The model-id portion is fixed by Anthropic. Verify the provider account name in your specific TrueFoundry instance before copy-pasting.
Budget config — dollar enforcement per cost center, with audit mode for safe rollout:
name: cicd-budget-config
type: gateway-budget-config
rules:
# Priority 1 (first in list = first match): payments-platform — higher cap
- id: 'payments-platform-weekly'
when:
metadata:
cost_center: 'eng-backend-payments'
limit_to: 800
unit: cost_per_week
audit_mode: false # enforce: block on exceed
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: slack-bot
notification_channel: 'eng-alerts-channel'
channels: ['#eng-backend-ai']
# Priority 2: data team — lighter cap, longer period
- id: 'data-team-monthly'
when:
metadata:
cost_center: 'eng-data'
limit_to: 2000
unit: cost_per_month
audit_mode: false
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: email
notification_channel: 'data-alerts'
to_emails: ['data-platform-lead@example.com']
# Priority 3: intern sandbox — hard cap, no exceptions
- id: 'intern-sandbox-weekly'
when:
metadata:
cost_center: 'intern-sandbox'
limit_to: 50
unit: cost_per_week
audit_mode: false
alerts:
thresholds: [100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']
# Default per-user safety net — $20/day per individual developer.
# Tracks against every request (layered), controls block only for requests
# that don't match a higher-priority rule above.
- id: 'per-user-daily-default'
when: {}
limit_to: 20
unit: cost_per_day
budget_applies_per: ['user']
audit_mode: true # audit-only during initial rollout
alerts:
thresholds: [90, 100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']Rate-limit config — request and token quotas, the second line of defense:
name: cicd-ratelimiting-config
type: gateway-rate-limiting-config
rules:
# Per-pipeline token ceiling: prevents runaway agents.
# metadata.pipeline accesses the 'pipeline' field inside x-tfy-metadata JSON.
- id: 'pipeline-hourly-token-cap'
when: {}
limit_to: 500000
unit: tokens_per_hour
rate_limit_applies_per: ['metadata.pipeline']
# Per-user request floor: stops developer mistakes from going viral
- id: 'per-user-daily-requests'
when: {}
limit_to: 5000
unit: requests_per_day
rate_limit_applies_per: ['user']
# Premium-model brake: caps Opus consumption per cost center.
# Replace 'anthropic-main' below with your workspace's Anthropic
# provider-account name (see AI Gateway → Models in the dashboard).
- id: 'opus-per-cost-center-daily'
when:
models: ['anthropic-main/claude-opus-4-7']
limit_to: 200000
unit: tokens_per_day
rate_limit_applies_per: ['metadata.cost_center']Both configurations are version-controlled, reviewed in pull requests, and applied through the same GitOps flow the platform team uses for the rest of the gateway. The schemas above match the official docs exactly — every field, every value, every rate_limit_applies_per entry is documented and supported. Workload teams propose changes to their own cost-center entries through pull requests; the platform team approves; the gateway picks up the change on its next reconciliation loop.
The audit_mode: true setting on the default per-user rule is the safety primitive worth highlighting. During rollout, audit mode lets the rule track real spend and fire alerts without blocking any traffic. After a week or two of observation, the team flips audit_mode to false to enforce. This is the lowest-risk path to a production-grade budget enforcement system: observe first, enforce second, and never enforce a number you haven't yet seen real traffic produce.
The single-organization case where every cost center belongs to one company is the easy one. Many production AI deployments are multi-tenant: a B2B SaaS product offers AI features to its own customers, and the AI bill needs to be allocated per tenant before the company knows which customers are profitable and which are subsidized. The cost-attribution layer is what makes this question answerable.
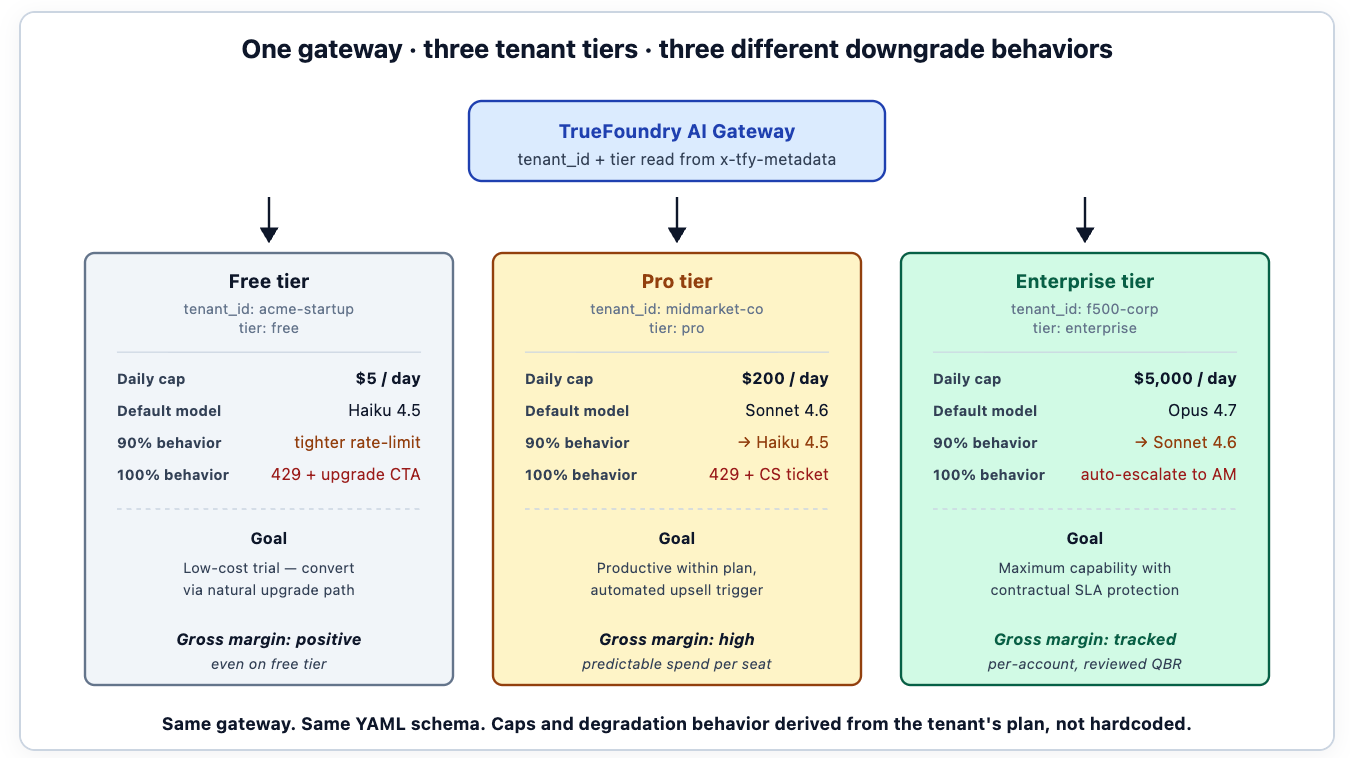
The pattern that works adds tenant_id as another field on the metadata envelope. The bucket key for budgeting becomes the combination of tenant_id and workload; the dashboard supports a per-tenant view alongside the per-cost-center view; the FinOps report joins gateway data to the company's billing system to produce gross margin per tenant. A tenant whose AI consumption exceeds their plan tier shows up in the dashboard before customer success has to chase the conversation.
Tier-aware budget caps are the second pattern. The free-tier tenant gets a tighter cap than the enterprise-tier tenant; the caps are derived from the tenant's plan rather than hardcoded. When a tenant upgrades, the cap updates without code changes — the plan is metadata on the tenant identity, the cap is a function of the plan. Teams that hardcode caps end up rewriting them every time pricing changes; teams that derive them from tenant data inherit the right behavior automatically.
The third pattern: degraded-but-working modes per tier. The enterprise-tier tenant's constrained mode might keep them on a frontier model with stricter rate limiting; the free-tier tenant's constrained mode might route them to a self-hosted small model. Same gateway, different downgrade chains, expressed as configuration. The B2B SaaS company's pricing structure shows up directly in the gateway configuration — which is the right place for it.
Four configuration mistakes appear regularly in teams' first attempts at cost attribution. Each produces a different failure mode worth knowing.
Optional tagging. The team configures the gateway to log untagged requests but pass them through, intending to enforce later. "Later" doesn't arrive, and the dashboard accumulates an "unknown" bucket that grows month over month. By the time enforcement is enabled, half the traffic is in the unknown bucket and breaking it is politically expensive. The fix is to enforce rejection from week 2, when the visible traffic is still small.
Inventing extra headers. Teams sometimes try to spread identity across multiple headers — separate headers for team, repo, cost center, and so on. The gateway recognizes exactly nine custom headers, listed earlier in this post; the rest are silently ignored. All custom identity belongs inside the JSON value of x-tfy-metadata. One header. JSON inside. The contract is documented and the gateway enforces it.
Cost centers that span teams. A cost center like shared-infra looks like a clean abstraction but produces no engineering ownership when it overruns — there is no team to call. Cost centers should map to a team's responsibility surface; shared work belongs in a "platform" cost center owned by the platform team, not in a vague shared bucket.
Hard caps without descriptive errors. A 429 with body {"error": "rate_limited"} tells the developer nothing actionable. A 429 with the cost center, the cap, the top consumer, and a link to the quota request flow tells them exactly what to do. The error-body schema is one of the most-tuned parts of the configuration in any mature deployment.
Cost attribution is one of the safer rollouts in the AI platform space because the failure mode of "miscalibrated budget" is bounded (some pipelines hit constrained mode unexpectedly) and the failure mode of "no attribution" is catastrophic (the runaway bill). The right sequence is observe-first, enforce-second.

Week 1 — Tagging in audit mode. Update the CI templates to inject x-tfy-metadata on every request. Configure the gateway to log untagged requests as warnings but pass them through. The dashboard at the end of the week tells the team the natural shape of their spend: which pipelines dominate, which cost centers are the heavy users, which models the workloads actually prefer. This is the data that informs the budget calibration.
Week 2 — Reject untagged requests. Flip the gateway to return 400 for untagged requests. The CI templates updated in week 1 are the only legitimate clients; any 400 response indicates either an un-updated template or an out-of-band caller that needs to be addressed. By the end of week 2 every request in production is tagged.
Weeks 3-4 — Configure budgets in audit mode. Deploy the budget config with audit_mode: true across all rules. Set the soft thresholds (75%) against the observed P95 of legitimate spend plus margin. Alerts fire to team Slack channels; no enforcement actions trigger yet. The team observes which thresholds are reasonable and which need tuning. Some workloads will appear to be on a runaway trajectory; one or two will actually be, and the team can intervene before enforcement kicks in.
Week 5 — Enable enforcement. Flip audit_mode to false on the budget rules. Turn on the 90% downgrade chain (paired virtual-model fallback config) and the 100% hard cap. The downgrade chain is the more contentious change with workload owners — some teams strongly prefer "fail fast" over "degraded but working" for their pipelines. Make the chain per-cost-center configurable from the start, so each team can choose its preferred behavior.
Week 6+ — Forecasting and review cadence. Enable the 7-day P95 forecast. Set up a weekly platform-team review of the forecast against the budgets. New cost centers default into reasonable starting caps based on observed early usage; quota changes flow through pull requests against the configuration. The system runs as infrastructure, not as a project.
The cost-attribution layer needs a clear ownership boundary because the data it produces lands in multiple stakeholders' worlds at once. The right split is: platform team owns the layer, workload teams own their budgets, finance owns the strategic view, engineering leadership owns the policy.
The platform team operates the gateway, the tagging discipline, the budget engine, and the forecast. They review and approve quota requests, they tune the downgrade chains based on quality feedback from workload owners, and they triage the alerts that fire during off-hours. Their job is to make the system run; they do not decide how much each workload should cost.
The workload teams own their own cost-center entry in the configuration. They propose budget changes through pull requests; they tune their pipelines when they hit soft alerts; they choose between degraded-but-working and fail-fast behavior for their hard-cap response. The platform team approves; the workload team executes.
Finance and engineering leadership consume the aggregate views. Monthly close calls cite specific cost centers and specific pipelines rather than aggregate numbers. Quarterly planning uses the forecast to project AI infrastructure spend; budget cycles become predictable instead of reactive. This is the property that makes AI spend a budgeted line item rather than a recurring surprise.
Mandatory tagging is not a substitute for prompt engineering. A workload that injects a 50,000-token manual into every prompt will see the tag tell them exactly which workload is expensive; it will not tell them how to fix it. The fix — a smaller manual, a cache, a more focused retrieval, a model better-suited to the task — is the engineering work that follows the attribution. The dashboard is the diagnosis; the fix is the treatment.
Hierarchical budgets are not a guarantee of cost control. A team that gets its budget raised every time it hits the cap eventually arrives at "the cap doesn't exist." The discipline is in the budget-review cadence, not in the technical mechanism. Platform teams that approve every quota request lose the leverage the budget was meant to provide.
And cost attribution at the gateway is not the right answer for every organization. Teams whose total AI spend is small enough that the engineering investment exceeds the savings should pick a different problem to solve first; teams whose existing FinOps tooling already produces per-workload attribution from cloud-provider data don't need a parallel system at the gateway. The pattern fits organizations whose AI spend has grown faster than their visibility into it — typically anywhere above $5K/month of provider spend, where the cost of one runaway incident exceeds the cost of building the layer. Below that threshold, the math of even an off-the-shelf gateway like TrueFoundry's doesn't always pencil out; the team is better off keeping the spend in one or two well-monitored applications and applying the layer when growth makes it warranted.
Both, concurrently. Dollars align with finance and operational planning. Tokens are the engineering metric that lets the team debug prompt efficiency — a workload whose token consumption doubles while its dollar cost stays flat (because the model got cheaper) is worth investigating from an engineering standpoint even if finance doesn't notice. The gateway tracks both; finance owns the dollar dashboards, engineering owns the token dashboards, and the gateway is the source of truth for both.
The pipeline receives a 429 with the descriptive error body shown above and a link to the budget dashboard. CI runners interpret 429 as a standard backoff signal; the build fails cleanly with an actionable message rather than crashing in confusing ways. Quota increases are filed as standard tickets against the platform team through the link in the error body. The pipeline's last successful step is preserved; resuming after the quota increase doesn't redo work already paid for.
In practice, no. TrueFoundry ships SDK wrappers that inject the metadata envelope automatically from environment variables CI runners already set, so individual developers never edit headers. The one-time cost is updating the team's pipeline templates; the recurring cost is zero. The recurring benefit is every dashboard that follows.
Use a stable workflow_id field inside the x-tfy-metadata JSON — the same value for every request belonging to the same logical workflow. The gateway groups requests by workflow_id for per-workflow budget enforcement. A workflow with a $5 cap can span hundreds of requests; the gateway tracks running total against the workflow's identifier rather than the individual request.
It matches the provider's invoice within roughly 1% for input and output token costs; the small variance comes from rounding and from provider-side surcharges (volume discounts, region differentials) that the gateway cannot see at request time. For most planning purposes the gateway's numbers are tight enough; for accounting-grade reconciliation the provider's invoice remains the source of truth, with the gateway providing the per-workload breakdown. TrueFoundry's cost-tracking documentation describes both public-pricing (provider-published rates) and private-pricing (custom contracts) modes.
Budgets are scoped per cost center; one team's runaway only consumes their own budget. The hard cap stops the runaway before it can affect other teams. The model-level cap rule in the rate-limit config (the opus-per-cost-center-daily example) is a backstop for the case where multiple teams misbehave simultaneously or where attribution itself is wrong; it operates above the per-cost-center layer.
Cross-team work is uncommon but real. The cleanest pattern is to define a "shared-initiative" cost center owned by the platform team, with explicit charge-back rules documented in the gateway README. Tagging stays single-valued — the request belongs to exactly one cost center at runtime — but the platform team can journal the spend out to participating teams at the end of each billing period via the exported cost data described in the cost-tracking documentation.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.webp)


.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




