














July 22, 2026
|
5 min read

Published: June 8, 2026

Blazingly fast way to build, track and deploy your models!
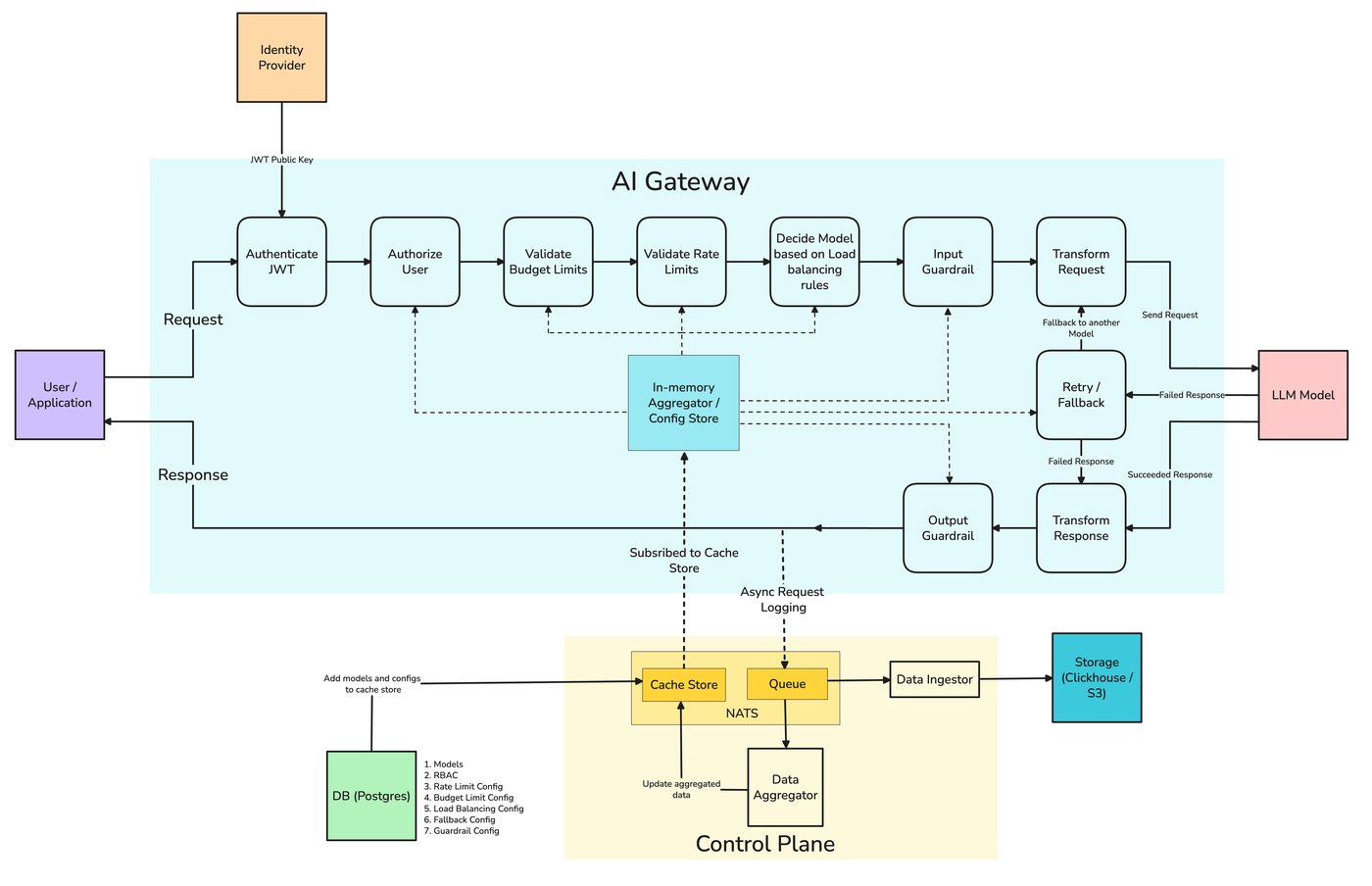
Prefix caching reuses identical prompts. Semantic caching reuses similar ones — embed the incoming request, and if a near-identical question was answered recently, serve the stored answer instead of calling the model. It's one of the highest-leverage cost and latency levers a gateway can pull, and one where "it works in the demo" and "it's safe in production" are very different claims. This post is how it works, the single knob that governs it, the cases where it quietly serves the wrong answer, and where the cache should live.
Kabir, a backend engineer, had a good week and then a bad one. The good week: he'd put a semantic cache in front of Northwind's support assistant — embed each incoming question, and if a near-identical question had been answered recently, return the stored answer instead of calling the model. Model-call volume dropped 35%. Latency on cache hits fell from roughly 900 ms to under 40 ms. The bad week: a customer asked "where's my delivery?" and got a confident, detailed answer — about someone else's order. Two customers had asked semantically identical questions minutes apart; the cache embedded both to nearly the same vector, scored a hit, and served the first customer's answer to the second.
The cache was working exactly as designed. It just had no idea that "where's my delivery?" means something different depending on who is asking. Semantic caching trades a model call for a similarity match, and the entire safety of that trade lives in two places: the threshold you match on, and what you allow into the cache in the first place. This post is both.
Everything in this post — exact-match and semantic caching, the similarity threshold as a per-route knob, per-tenant scoping so Kabir's bug from the cold open never happens, and the hit-rate / cost-saved telemetry that tells you whether the cache is actually paying off — is something TrueFoundry's AI Gateway caching expresses as gateway configuration. A single header on the request turns it on; the gateway hashes the request (or embeds the last message for semantic), compares against a Redis-backed store, and returns the cached response on a hit. On a miss, the request goes to the provider and the new response and embedding are cached for next time.
The correctness story — making sure two semantically similar requests from different users never return each other's answers — is built in via two-level namespacing. Level 1 is automatic: every cache entry is scoped to the calling user or virtual account, so User A's request can never hit User B's entry, full stop. Level 2 is optional: a namespace field in the cache config partitions further (per tenant, per environment, per system-prompt version), which is what the post's namespace argument needs in practice. Together, they're what makes a gateway-level semantic cache safe to share across services without each one re-implementing isolation.
Application code stays the same — the cache is opt-in per request via a single header. The example below uses semantic, which is a superset of exact-match (it will also serve identical-text hits), with a conservative starting threshold of 0.9 and a custom namespace so a multi-tenant app keeps each tenant's cache isolated even beyond the automatic per-user scoping:
Calling the gateway with semantic caching enabled (Python, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>",
api_key="<your-virtual-account-token>",
)
resp = client.chat.completions.with_raw_response.create( # raw_response → see headers
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": user_question}],
extra_headers={
# Semantic is a superset of exact-match. Start strict (0.9) and tune from there.
"x-tfy-cache-config": (
'{"type":"semantic",'
'"similarity_threshold":0.9,'
'"ttl":600,'
'"namespace":"tenant-acme-faq"}'
),
},
)
print(resp.headers.get("x-tfy-cache-status")) # "hit", "miss", or "error"
print(resp.headers.get("x-tfy-cache-similarity-score")) # e.g. "0.95" on a semantic hit
print(resp.parse().choices[0].message.content)"Caching" covers three distinct mechanisms with very different reach and risk, and it's worth being precise about which one you're deploying.
Provider prefix caching reuses an exact, identical prompt prefix — the system prompt and tool definitions that repeat unchanged across calls. The provider matches on an exact prefix and bills the repeated portion at a steep discount. It's automatic, safe, and covered in our context-engineering post; it never serves a wrong answer because it only matches identical text.
Exact-match response caching hashes the entire normalized request and returns the stored response on an identical hash. Also safe — identical input, identical output — but the hit rate is low, because users rarely phrase things identically.
Semantic caching is the subject here: embed the request and serve a cached response when a similar prior request exists. This is where the hit rate jumps, because "where's my package?" and "has my order shipped yet?" can share a cached answer — and it's also where the risk appears, because "similar" is a judgment call made by a similarity threshold rather than an exact match.
The mechanism is three steps. Embed the incoming request into a vector. Search a vector store for the nearest prior request within the right scope. If the nearest neighbor's similarity exceeds a threshold, return its stored response; otherwise call the model and store the new request/response pair for next time.
Semantic cache lookup — embed, search within scope, serve on a confident hit
emb = embed(request.text) # ~10-30 ms
hit = vector_store.nearest(emb, scope=tenant_id) # scoped search — never global for user data
if hit and hit.score >= THRESHOLD: # the knob that governs everything
return hit.response, "cache_hit" # tens of ms, no model call
resp = call_model(request) # miss -> full model call
vector_store.put(emb, resp, scope=tenant_id, ttl=TTL)
return resp, "cache_miss"On a hit, you've replaced a model call — typically several hundred milliseconds and a per-token charge — with an embedding call and a vector lookup, on the order of tens of milliseconds and a fraction of the cost. On a miss, you've added the embedding and lookup latency to the normal model call, which is the small tax you pay for the chance at a hit. The economics of that trade depend entirely on the hit rate (section 7), and the safety depends entirely on the threshold (next).
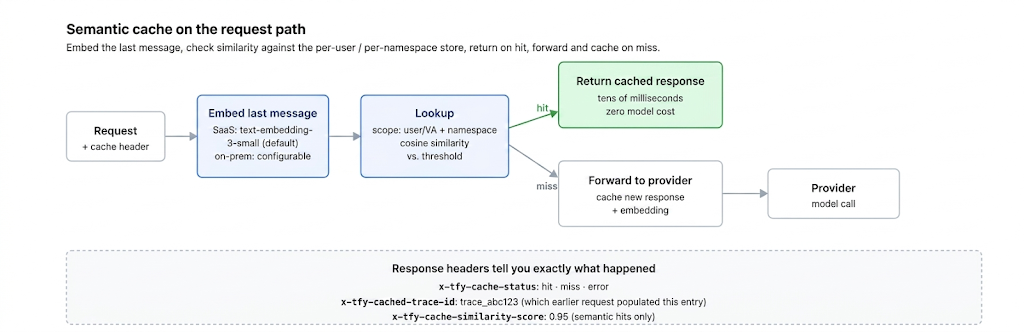
The threshold decides how close a new request must be to a cached one to count as a hit, and it is a direct precision/recall tradeoff. Set it too low — accept loose matches — and the hit rate is high but you serve answers to questions that weren't quite asked (false hits). Set it too high — demand near-identical phrasing — and the cache is safe but rarely fires, collapsing toward exact-match caching with extra steps.
There is no universal correct value, because it depends on the embedding model, the domain, and how much a wrong answer costs you. The way to set it is empirical: assemble labeled pairs of requests that should and should not share an answer, sweep the threshold, and pick the point where false hits drop to an acceptable rate for that route. High-stakes routes (anything touching money, health, or identity) warrant a conservative threshold or no semantic caching at all; low-stakes informational routes (documentation Q&A, general explanations) can run looser. Per-route thresholds, not one global number, are the production pattern — and a gateway like TrueFoundry's AI Gateway, which already sits on every route, is the natural place to set them per route and watch each route's false-hit rate rather than scattering the policy across services.
The core hazard is simple to state and easy to underestimate: embedding-close is not meaning-equal. Embeddings capture topical similarity, not logical equivalence. "What is the capital of France?" and "What is the capital of Germany?" are extremely close in embedding space — same structure, same domain, one word different — yet require different answers. A threshold tuned for recall will treat them as the same question.
The mitigations stack, and none is complete on its own. A conservative threshold reduces loose matches. Entity and keyword guards add a check that the salient entities (the country, the order number, the product) match before serving a hit, catching the France/Germany case that pure cosine similarity misses. Per-namespace caches keep distinct contexts from colliding. And the most reliable mitigation is upstream: don't cache the classes of request where a near-miss is dangerous at all, which is the next section. Treat semantic caching as a tool with a known failure mode you design around, not a transparent speedup you can apply everywhere.
Some responses are unsafe to serve from a similarity match regardless of how good the threshold is, because the thing that makes two requests different isn't in the text the embedding sees.
A semantic cache entry is not keyed by text alone; it's keyed by an embedding inside a namespace, and the namespace is where correctness is enforced. The namespace should encode everything that makes two textually-similar requests genuinely different: the tenant or user (for anything user-specific), the model, the system-prompt version, and the active tool set. Two identical questions under different system-prompt versions are different questions, because the instructions that shape the answer changed.
Namespacing a cache entry (illustrative)
# Same text in a different namespace is a different entry — by design.
namespace = f"{tenant_id}:{model}:{system_prompt_version}"
# For user-specific answers, the user/tenant MUST be in the namespace,
# so a lookup can never return another user's cached response.
vector_store.put(emb, resp, namespace=namespace, ttl=TTL)Invalidation has two triggers. Time, via a TTL chosen for how fast the underlying truth changes — short for anything that drifts, longer for stable reference answers. And version, via the namespace: bumping the system-prompt version or changing the tool set rolls the cache forward, so stale answers from the old configuration are never served. The failure to invalidate on a prompt change is a common and subtle bug — the prompt improves, but cached answers keep reflecting the old one until the TTL expires.
In TrueFoundry's caching, all of this is the x-tfy-cache-config header (or a centrally-managed policy that sets the same fields). The schema is small and the controls match what this section just described:
Per-route caching for a multi-tenant assistant — three patterns, same schema
# Route A: low-risk FAQ. Broad matching is fine; cache for 1 hour.
x-tfy-cache-config: {"type":"semantic","similarity_threshold":0.88,"ttl":3600,
"namespace":"faq:v3"}
# Route B: per-tenant support. Per-tenant namespace + stricter threshold to
# avoid cross-tenant near-misses (automatic per-user scoping ALREADY isolates
# users; the namespace partitions further along business boundaries).
x-tfy-cache-config: {"type":"semantic","similarity_threshold":0.93,"ttl":600,
"namespace":"tenant-acme:assistant:v7"}
# Route C: deterministic dev/test. Exact-match only.
x-tfy-cache-config: {"type":"exact-match","ttl":600,"namespace":"staging"}The docs' threshold guidance matches the post: 0.95–1.0 for very strict use cases where a wrong hit is costly, 0.85–0.95 for balanced conversational assistants, below 0.85 for exploratory or low-risk routes. Starting at 0.9 and adjusting based on observed false-hit rate is what they recommend, and the response header x-tfy-cache-similarity-score is what makes that measurable — every hit tells you the score it cleared on, so a sweep across labeled pairs becomes a few queries, not a custom evaluation harness.
Two implementation details worth knowing. The embedding model on SaaS is OpenAI's text-embedding-3-small by default and is not configurable in that mode; on self-hosted deployments it's pickable via Controls → Settings → Semantic Cache, and the chosen model applies to all semantic-cache operations gateway-wide.
The store on self-hosted is Redis — either the bundled Redis from the tfy-llm-gateway Helm chart, or your own Redis (or Redis-compatible like Valkey) via env vars. Both choices matter because the cache only earns its keep when the embedding+lookup is genuinely faster and cheaper than the model call it's avoiding.
The other side of the namespace argument from the post is the part the gateway makes automatic: Level-1 isolation. Every entry is implicitly scoped to the user or virtual account that created it, so even if you forget to set namespace, User A's request never returns User B's cached answer. The custom namespace is an additional partition for the cases the post describes — multi-tenant apps sharing one virtual account, system-prompt versions, environments — not the only thing standing between two callers' answers. That layering is what makes "share one cache across services" a defensible default rather than a foot-gun.
The value of semantic caching is governed by one number: the hit rate. As an illustrative model, suppose a route runs at some per-call model cost and the cache achieves a 30% hit rate at a safe threshold. Roughly 30% of requests now skip the model call, so cost on that route falls by close to 30% (minus the embedding and lookup cost, which is small relative to a generation). Latency improves on exactly those 30% of requests, dropping from a several-hundred-millisecond generation to a tens-of-milliseconds lookup, which pulls down both the average and the tail.
Two honest caveats on the math. The hit rate is workload-specific — a narrow FAQ-style assistant might see far more than 30%, while a long-tail creative workload might see almost none — so the only credible number is the one you measure on your own traffic. And the savings are net of the embedding tax on every miss; if your hit rate is very low, you can spend more on embeddings than you save. Measure the cacheable fraction before committing, rather than assuming a headline rate. Running the cache behind TrueFoundry's AI Gateway is what makes that measurable in the first place — the hit rate and the spend it avoids show up next to the per-call cost from the cost-attribution work, so the savings are an observed number rather than a projection.
A semantic cache can live in the application, but the gateway is the stronger default for the same reasons that apply to routing and reliability: it already sits on every request, so the cache is shared across services rather than reimplemented in each, and it already holds the per-call cost and latency telemetry needed to measure whether the cache is actually paying off.
Running the cache at TrueFoundry's AI Gateway means one place to enforce per-tenant scoping (so the cold open can't happen), one place to see the hit rate, cost saved, and latency saved, and the same cost-attribution view from the cost-attribution post showing the cached-vs-uncached split per team and route. The division of labor is the one that recurs across this series: the gateway provides the shared, scoped, observable cache; the application owns the policy decision of which routes are safe to cache and at what threshold — because only the application knows that "where's my delivery?" is personalized and "what's your return window?" is not.
How is this different from the prompt caching in the context-engineering post?
That post covered provider prefix caching — reusing an identical system-prompt prefix at a billing discount, which never serves a wrong answer because it matches exact text. Semantic caching reuses similar requests by embedding them, which is where both the higher hit rate and the false-hit risk come from. They compose: cache the static prefix on every call, and semantically cache whole responses only on the routes where it's safe.
How do I pick the similarity threshold?
Empirically, per route. Build a labeled set of request pairs that should and shouldn't share an answer, sweep the threshold, and choose the point where false hits fall to a rate that's acceptable given what a wrong answer costs on that route. High-stakes routes get a conservative threshold or no semantic caching; low-stakes informational routes can run looser. A single global threshold is almost always wrong for some route.
Can I safely cache anything personalized?
Only with an explicit per-user (or per-tenant) scope in the cache namespace, so a lookup can never return another user's response — and even then, watch for time-sensitivity. The safe default for personalized, time-sensitive, stateful, or high-stakes responses is not to semantically cache them. The cold open is what happens when a personalized answer is cached without user scope.
What happens to the cache when I change the system prompt?
You must invalidate, or you'll serve answers shaped by the old prompt until their TTL expires. The clean way is to put the system-prompt version in the cache namespace, so a prompt change rolls the cache forward automatically and old entries are simply never matched again.
Gateway or application?
The gateway for the mechanics — shared cache, per-tenant scoping, and the hit-rate/cost/latency observability that tells you whether it's working. The application for the policy — which routes are cacheable and at what threshold — because that judgment needs domain knowledge the gateway doesn't have.
Kabir's cache wasn't a bad idea; it was an unscoped one. Semantic caching earns real cost and latency wins on the routes where similar questions genuinely share an answer — and the discipline that makes it safe is knowing, route by route, which questions those are.
TrueFoundry's AI Gateway is an enterprise-grade control plane that sits between your applications and 1,600+ models — across OpenAI, Anthropic, Google, AWS Bedrock, Azure OpenAI, and your own self-hosted models — behind a single OpenAI-compatible API. It turns caching strategies in this post into configuration rather than per-service code: exact-match and semantic caching via a single x-tfy-cache-config header, per-route similarity thresholds and TTLs, automatic per-user / per-virtual-account isolation, optional namespace partitioning for multi-tenant apps and prompt versions, and Redis-backed storage that works the same way on SaaS and self-hosted (with the embedding model configurable on-prem).
Because the gateway already sits on every request and emits a complete trace for every call, the cache becomes measurable in the same view as everything else: x-tfy-cache-status, the cached trace ID, and the actual similarity score land on each response and roll up to cost-saved and latency-saved dashboards. The same gateway adds RBAC, virtual accounts, budgets and rate limits, fallbacks and retries, guardrails, and observability dashboards. It deploys as SaaS, in your VPC, on-prem, or air-gapped with SOC 2, HIPAA, and ITAR compliance, and is recognized in Gartner's Market Guide for AI Gateways. See the caching docs or the AI Gateway overview to go deeper.
Northwind and Kabir are illustrative. The mechanics of embedding-based caching, the precision/recall behavior of the similarity threshold, and the embedding-close-is-not-meaning-equal failure mode are general properties of the technique. Specific figures — the 35% call reduction, the 900 ms-to-40 ms latency on hits, the 30% hit-rate example, the 10–30 ms embedding cost — are representative order-of-magnitude assumptions to illustrate the tradeoffs, not measurements; measure your own cacheable fraction and false-hit rate before enabling semantic caching in production.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox








.png)

.webp)
.webp)
.webp)



.webp)


