













.webp)
July 14, 2026
|
5 min read

Published: June 8, 2026

Blazingly fast way to build, track and deploy your models!
AI-assisted coding tools like OpenCode fundamentally change how developers interact with code. Instead of operating on isolated snippets, these systems reason across files, dependencies, and historical context. The result is a significant productivity boost but also a new cost and scalability challenge that many teams underestimate: token usage.
Unlike traditional developer tools with predictable licensing costs, OpenCode usage is governed by token-based pricing. Every interaction, code generation, refactoring, debugging, or review - consumes tokens. As teams scale usage across developers, repositories, and automated agents, token consumption becomes the primary cost driver.
What makes this particularly tricky is that token usage is often non-intuitive. Small changes in context size, prompt structure, or agent behavior can result in large swings in token consumption. Without a clear mental model of how tokens are used, teams struggle to predict costs, optimize workflows, or enforce guardrails.
This blog breaks down how token usage works in OpenCode at a technical level, why code-related workloads are especially token-heavy, and what platform teams should understand before scaling usage in production.
At its core, OpenCode token usage follows the same mechanics as most LLM-powered systems: tokens are consumed for both inputs and outputs. However, the nature of coding workloads introduces additional complexity.

OpenCode token usage can be broadly divided into two categories:
In OpenCode, prompt tokens typically include:
Completion tokens include:
From a cost perspective, prompt tokens are often the dominant factor in OpenCode usage, especially as repositories and context sizes grow.
Code-related tasks behave very differently from natural language queries. Several factors contribute to higher token consumption:
Unlike chat-based use cases, OpenCode often sends:
Even a “small” codebase can quickly translate into tens or hundreds of thousands of tokens when multiple files are included.
Source code is dense. Syntax, indentation, symbols, and formatting all count toward tokens. A few thousand lines of code can consume far more tokens than an equivalent amount of plain text.
OpenCode workflows frequently involve:
Each step may re-send context or intermediate outputs, multiplying token usage across a single task.
When OpenCode is used via agents or automation (for example, refactoring across multiple files or running in CI pipelines), token usage compounds quickly:
This makes agent-driven usage powerful but also expensive if not bounded.
One of the biggest challenges with OpenCode token usage is that developers rarely see the full context being sent to the model. Editors and tools abstract away:
As a result, two seemingly similar tasks can have wildly different token footprints. Without explicit tracking at the request level, teams often discover cost issues only after usage spikes.
This is why understanding token mechanics is not enough on its own. Teams need visibility into actual token consumption per task, per developer, and per workflow to make informed optimization decisions.
Understanding token usage is important for any AI-powered application, but it becomes especially critical as AI adoption scales across developers, agents, and enterprise platforms. Monitoring and optimizing token consumption helps organizations control costs, improve efficiency, and maintain predictable AI spending.
AI coding assistants such as OpenCode, Claude Code, and similar tools frequently process large codebases, extensive context windows, and multi-turn conversations. As developers interact with these tools throughout the day, token consumption can grow quickly.
Tracking token usage helps engineering teams:
AI agents often perform complex workflows involving planning, reasoning, tool usage, retrieval, and code generation. These multi-step interactions can generate significantly higher token usage than traditional chat applications.
Monitoring token consumption enables teams to:
As agent deployments grow, token visibility becomes essential for maintaining predictable operational costs.
Large organizations frequently deploy AI applications across multiple teams, products, and business units. Without centralized visibility, it can be difficult to understand how tokens are being consumed and where costs are increasing.
Organizations use token monitoring to:
As AI adoption expands, token usage becomes an important operational metric alongside latency, reliability, and model performance. Organizations that actively monitor and optimize token consumption are often better positioned to scale AI workloads efficiently while controlling costs.
Most spikes in OpenCode token usage are not caused by a single obvious mistake. They emerge from how OpenCode is used in real-world engineering workflows—especially when tools and agents are integrated deeply into development and automation pipelines.
Below are the most common scenarios that disproportionately increase token consumption.
One of the biggest contributors to high token usage is overly broad context inclusion. Many OpenCode workflows include entire directories or large subsets of a repository to “be safe,” even when only a small portion of the code is relevant.
Examples include:
Because prompt tokens scale linearly with context size, this pattern alone can multiply costs quickly.
OpenCode often operates iteratively: generate code, review, adjust, regenerate. In many setups, each iteration resends the full context, including files and previous outputs.
This leads to:
Without caching or intelligent context reuse, iteration becomes one of the most expensive patterns.
When OpenCode is used via agents or automated workflows, token usage can escalate rapidly if execution is not explicitly bounded.
Common causes include:
Because these processes often run in the background, teams may not notice runaway usage until costs spike.
Refactoring and review tasks tend to be more token-intensive than code generation because they require:
When these tasks are applied across large codebases or multiple pull requests, token usage increases significantly.
OpenCode usage embedded into CI pipelines or automation workflows introduces a different risk profile. These systems:
Even modest per-run token usage can become expensive when multiplied across many builds or deployments.
Finally, one of the most overlooked drivers of high token usage is the absence of visibility. When teams cannot see:
Optimization becomes guesswork. Teams often respond by restricting usage globally, rather than addressing the specific workflows that drive costs.
Once teams understand where token usage comes from, the next step is optimization. Importantly, optimization is not about limiting usage arbitrarily, it’s about using tokens intentionally so that productivity gains don’t turn into uncontrolled costs.
Below are practical best practices that consistently reduce OpenCode token usage without degrading output quality.
The most effective optimization lever is controlling what context is sent to the model. More context is not always better, especially when it’s irrelevant.
Practical techniques include:
A good rule of thumb: if a file is not required to reason about the change, it should not be part of the prompt.
Instead of sending large amounts of code upfront, teams should move toward on-demand retrieval.
Examples:
This approach reduces prompt size while often improving reasoning quality, since the model receives more targeted information.
Generic prompts tend to encourage broader reasoning and larger outputs, which increases both prompt and completion tokens.
Better patterns:
Task-scoped prompts not only reduce token usage but also improve determinism.
Agent-based workflows amplify token usage if left unchecked. Every agent should operate within clearly defined limits.
Key guardrails include:
Without these bounds, agents can unintentionally reprocess large contexts multiple times, driving up usage.
Many OpenCode workflows repeat similar tasks across iterations or users. Caching can significantly reduce redundant token consumption.
Applicable scenarios:
Even partial caching at the workflow level can yield meaningful savings.
While prompt tokens often dominate, completion tokens matter too, especially in refactoring or explanation-heavy workflows.
Techniques include:
Clear output constraints reduce unnecessary verbosity.
Finally, optimization should not be reactive. Teams should instrument token usage from day one.
At a minimum, this means tracking:
Without this data, teams cannot distinguish between productive usage and waste.
Most teams don’t struggle with OpenCode token usage on day one. The problems emerge gradually as usage spreads across developers, repositories, and automated workflows. What starts as an individual productivity tool quickly becomes shared infrastructure and token usage scales in ways that are difficult to predict or manage.
At scale, OpenCode is no longer used by a single developer in an editor. It is used by:
Each of these consumers generates token usage independently. Without a centralized view, it becomes difficult to answer basic questions like who is using tokens, for what purpose, and at what cost.
Early optimization efforts are often implemented at the application or tool level, custom prompt limits, context trimming, or retry logic. While these help locally, they don’t scale across:
As a result, policies become fragmented and inconsistent. One team optimizes aggressively while another unknowingly drives up costs.
Automation changes the math. A workflow that consumes a modest number of tokens per run can become expensive when:
Because these jobs run without direct human visibility, inefficiencies compound quickly. Token usage spikes often originate from automation rather than interactive usage.
Without fine-grained attribution, teams see only aggregate usage numbers. This makes optimization reactive and blunt.
Common failure modes include:
Effective control requires knowing which workflows generate value and which generate waste something aggregate metrics cannot reveal.
In many organizations, AI tooling adoption outpaces governance. OpenCode usage spreads faster than:
By the time token usage becomes a concern, the tooling is already deeply embedded in workflows, making retroactive controls difficult and disruptive.
The core issue is not misuse - it’s decentralized usage without centralized control. As OpenCode becomes shared infrastructure, token usage must be managed the same way teams manage compute, storage, or CI resources.
This requires:
Without this shift, token usage remains unpredictable, and optimization efforts stay reactive.
Once OpenCode usage reaches production scale, ad-hoc tracking and manual optimizations stop working. At this stage, token usage must be treated like any other shared infrastructure resource - measured continuously, governed centrally, and tied to ownership.
Many teams start by tracking token usage inside individual tools or workflows. While this provides local insight, it breaks down quickly when:
Each integration reports usage differently, and none provide a holistic view. As a result, platform teams lack a single source of truth for token consumption.
At scale, monitoring needs to happen at the request level, not just the tool level. Effective setups capture:
This allows teams to answer questions like:
Without this granularity, optimization efforts remain coarse and often misdirected.
Governance starts with attribution. Token usage must be mapped to owners who can act on it.
Common attribution models include:
Once ownership is clear, cost conversations shift from abstract budgeting to concrete decisions about which workflows deliver sufficient value.
Monitoring alone does not prevent cost overruns. Production systems require enforcement mechanisms that operate in real time.
Typical guardrails include:
These controls should be enforced centrally so that all OpenCode-powered workflows inherit them automatically.
The common thread across effective governance setups is centralization. Token usage policies, limits, and visibility must live at a shared control point rather than being reimplemented across tools.
This is where infrastructure-oriented platforms such as TrueFoundry fit naturally. By centralizing AI traffic, observability, and policy enforcement, platform teams can manage OpenCode token usage consistently across developers, agents, and automated systems - without slowing down individual teams.
As AI adoption grows, tracking and controlling token usage becomes increasingly important. While individual developers can often manage token consumption manually, organizations operating multiple applications, teams, and models typically require centralized visibility and governance.
Manual monitoring can work for small-scale deployments, but it often becomes difficult to track spending, identify inefficiencies, and enforce usage controls as AI workloads scale. AI Gateways provide a centralized layer for monitoring token usage, managing costs, and optimizing model utilization across an organization.
From a platform standpoint, the core challenge with OpenCode token usage is not understanding how tokens are consumed, but where control and visibility should live.
TrueFoundry approaches this problem by treating AI and LLM usage including developer-facing tools like OpenCode as shared infrastructure that must be observable, governable, and cost-aware by default. At the center of this approach is the AI Gateway, which acts as the control plane for all LLM traffic across the organization.
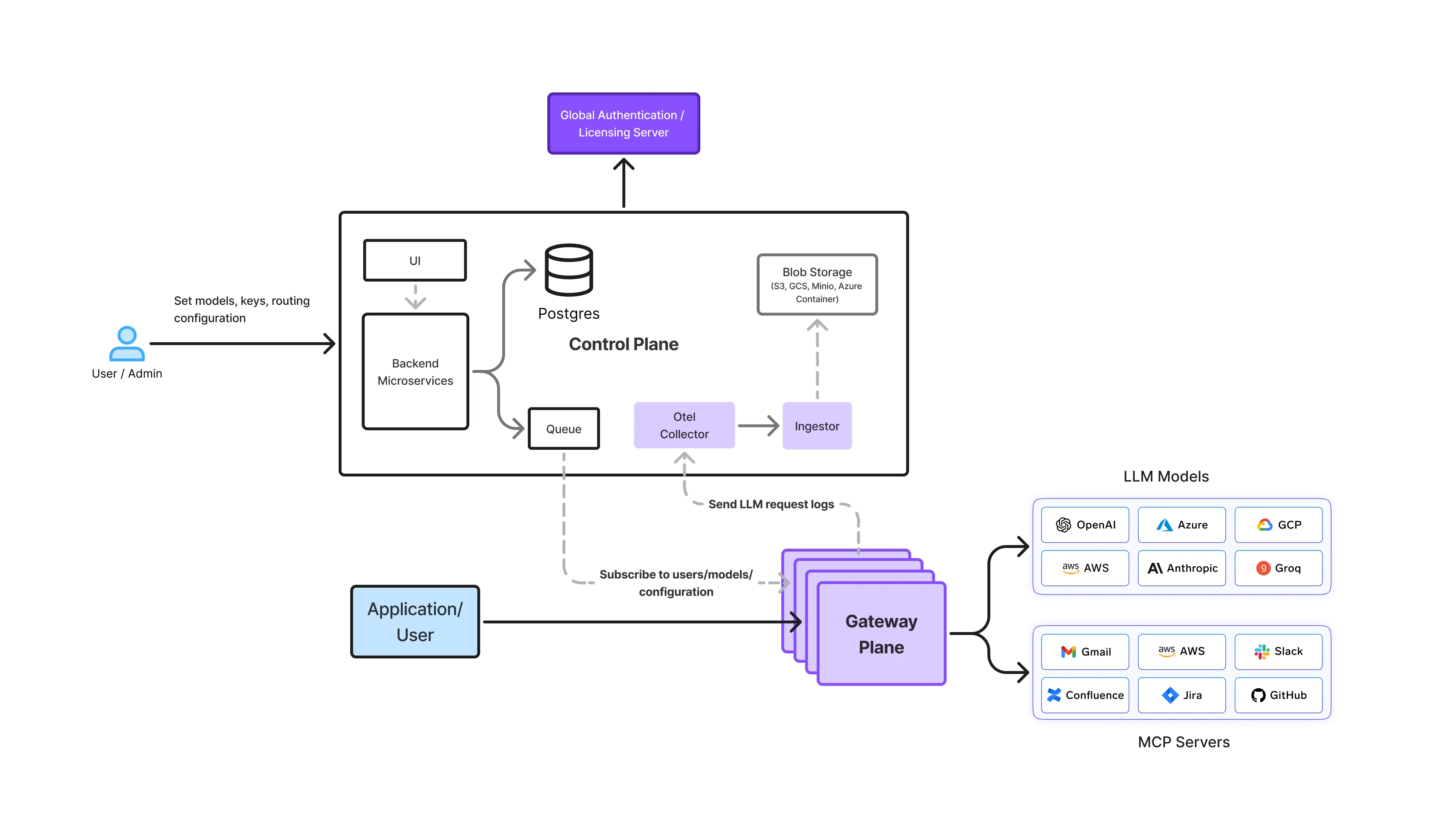
In a TrueFoundry setup, OpenCode does not interact directly with underlying LLM providers. Instead, all requests flow through the AI Gateway, which provides a single, consistent interface for inference.
Architecturally, this enables:
By removing direct model access from individual tools, platform teams gain full visibility into how OpenCode is actually being used across developers, agents, and automation.
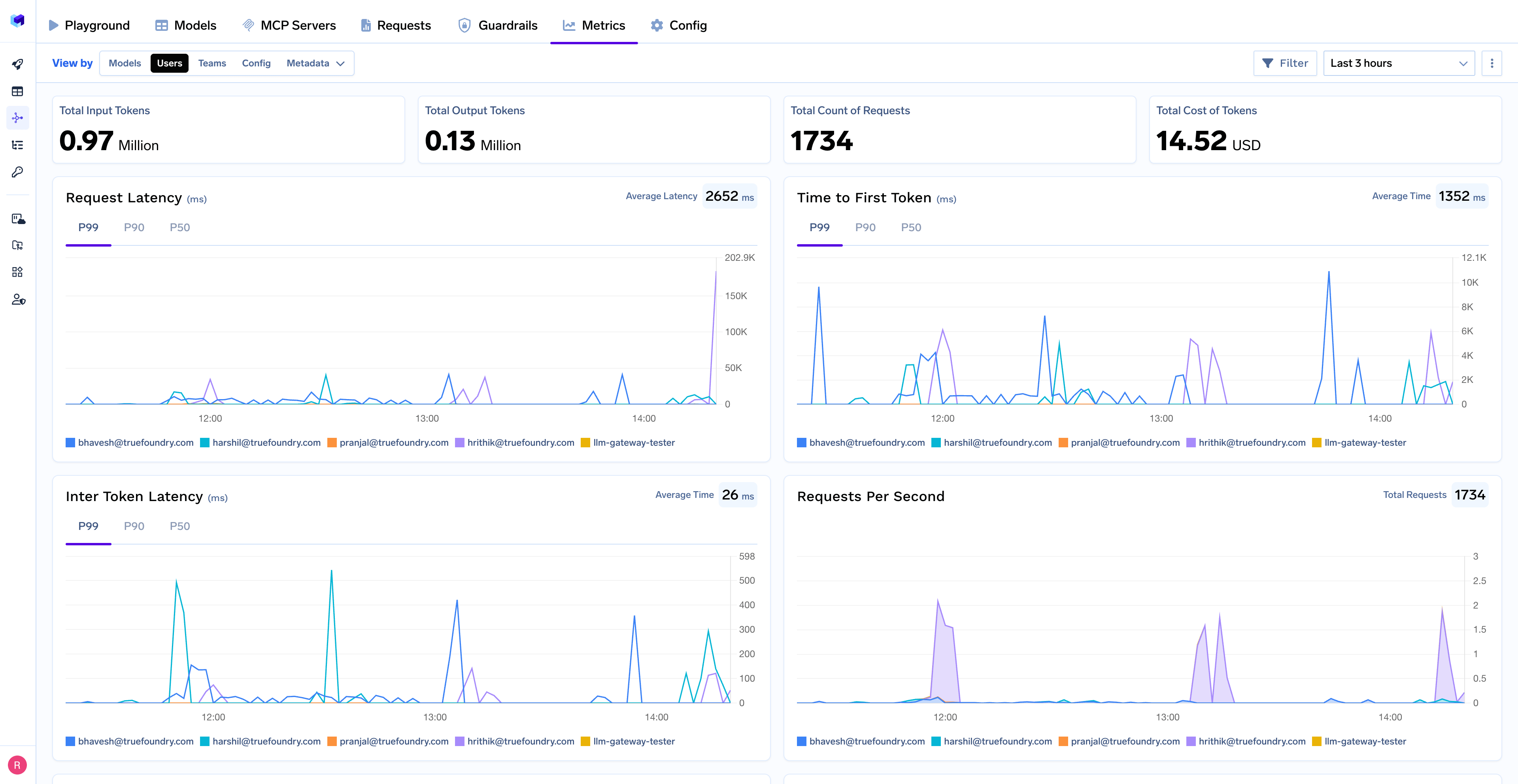
TrueFoundry’s AI Gateway captures token usage at the request level, including:
Critically, this telemetry is not locked into a vendor-controlled system. Logs and metrics are persisted in the customer’s own cloud and storage, allowing teams to:
This avoids the “black box” problem common with AI tooling and makes long-term optimization possible.
Because all OpenCode traffic passes through the gateway, cost controls can be applied consistently and in real time.
Platform teams can:
These policies are enforced once at the gateway and automatically apply to every OpenCode-powered workflow without requiring changes to editors, plugins, or internal tools.
TrueFoundry’s architecture is designed for environments where OpenCode usage extends beyond the IDE. CI pipelines, background jobs, and agents often generate the largest and least visible token consumption.
By routing these workloads through the same AI Gateway, teams can:
This makes it possible to scale OpenCode usage across the organization without losing predictability or control.
OpenCode token usage is the real scaling constraint for AI-assisted coding. As usage spreads across developers, repositories, automation, and agents, token consumption becomes difficult to predict and control without centralized visibility and governance.
Managing this at the tool or application level doesn’t scale. Token usage needs request-level observability, clear attribution, and real-time enforcement, treating AI-assisted coding as shared infrastructure, not an isolated feature.
Platforms like TrueFoundry reflect this approach by centralizing OpenCode traffic through an AI Gateway, enabling teams to monitor, govern, and optimize token usage consistently. For platform and engineering leaders, the takeaway is simple: if OpenCode is core to how software is built, token usage must be managed with the same rigor as any other critical infrastructure resource.
Accurately checking opencode token usage requires explicit tracking and instrumentation at the request level. Since tools often abstract the full context sent to the model, gaining visibility into actual token consumption per task, developer, and workflow is crucial for predicting costs and optimizing your usage effectively.
Opencode token usage is the token-based pricing model for AI-assisted coding tools like OpenCode. Every interaction, from input prompts and code context to generated code and explanations, consumes tokens. Managing this opencode token usage is crucial as it becomes the primary cost driver for development teams in the US.
To reduce opencode token usage, limit context injection to only essential files, avoiding broad repository inclusion. Prevent repeated context rehydration by reusing outputs intelligently across iterations. Break down complex tasks into smaller steps and use precise prompts. Monitoring token consumption for each task provides critical insights for optimizing costs and efficiency.
You can reduce OpenCode token usage by optimizing prompt length, limiting unnecessary context, and using the right model for the task. Large prompts, extensive conversation history, and oversized code contexts can significantly increase token consumption. Regularly reviewing usage patterns can help identify opportunities to improve efficiency and reduce costs.
Several factors can increase token usage in OpenCode, including:
Understanding these factors can help teams optimize AI usage and control spending more effectively.
Organizations typically monitor token usage through centralized dashboards, analytics tools, or AI Gateway platforms. These solutions provide visibility into token consumption across users, teams, applications, and models, helping organizations track spending, identify anomalies, and allocate AI budgets more effectively.
Monitoring token usage at the team level also makes it easier to identify optimization opportunities and prevent unexpected cost increases.
Yes. AI Gateways can help organizations optimize token consumption by providing visibility into usage patterns, enforcing budgets and rate limits, and enabling intelligent model routing.
For example, an AI Gateway can automatically route simpler requests to lower-cost models while reserving premium models for more complex tasks. Combined with usage analytics and governance controls, this helps organizations reduce AI costs while maintaining performance and reliability.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox











.webp)
.webp)
.webp)


