














July 1, 2026
|
5 min read

Published: June 18, 2026

Blazingly fast way to build, track and deploy your models!
Between 2020 and 2023, foundation models like GPT-3 and GPT-4 proved that large language models can generate human-like text, write code, summarize documents, and answer complex questions, But these models were stateless and sandboxed, they couldn’t access internal systems, databases, or apps — and had no way to actually take real-world actions.
You could ask a model:
“Write a MongoDB query to list all collections in the compliance database.”
It would generate output that looked like a valid MongoDB query — but:
It was all guesswork — with no feedback loop.
To fix this, developers began building layers around LLMs:
These were clever fixes but harder to maintain.
Frameworks like LangChain, LlamaIndex, and Semantic Kernel emerged to organize these workflows. These tools helped organize things, but the problems didn’t go away. Models were still hallucinating fields, falling for prompt injection, skipping validation, and had no standard way to run actual functions defined. Every new use case still felt like reinventing the wheel.
The real turning point came when developers realized:
“We don’t need models to guess commands. We need them to call real functions — the same way frontend apps call backend APIs.”
Around mid-2023, OpenAI introduced function calling, enabling models to return structured JSON output that directly mapped to real function calls.
It redefined what was possible with model integration
With function calling came the rise of tools and agents — models that could chain actions, follow workflows, and interact with real systems
But…
1. Every implementation was vendor-specific.
2. There wasn’t any shared standard format for how tools were described or invoked.
This is where MCP (Model Context Protocol) enters — proposed as a general, open protocol for structured communication between models and external tools. Instead of hardcoding tool APIs into each LLM app, MCP offers a universal charger for AI-tool connections — like OpenAPI, Anthropic etc but for LLMs calling tools. It’s based on JSON-RPC 2.0, a widely used specification that supports remote procedure calls (RPCs) using JSON.
Think of MCP as the API contract between a model and a tool. Without a standard protocol, every integration required custom engineering — costly, error-prone, and repetitive. MCP solved this by creating one universal language, simplifying tool integrations once and for all. But what exactly is MCP, and how does it work practically? Let’s dive deeper.
MCP (Model Context Protocol) is a lightweight protocol purpose-built for structured communication between AI models and external tools.
At its core, MCP uses JSON-RPC 2.0, a battle-tested protocol for calling remote procedures with structured inputs and outputs — perfect for turning LLM output into real-world tool invocations.
So why invent another protocol?
Existing options like REST or GraphQL are either too generic, too verbose, or just too brittle for AI-first workflows. MCP bridges this gap by providing clear structure, minimal overhead, and an explicit focus on AI-centric workflows. It’s not meant to replace your APIs — it’s meant to let models use them safely, repeatably, and predictably.
Servers typically expose:
Optionally, servers can also expose:
MCP is transport-agnostic and supports two modes:
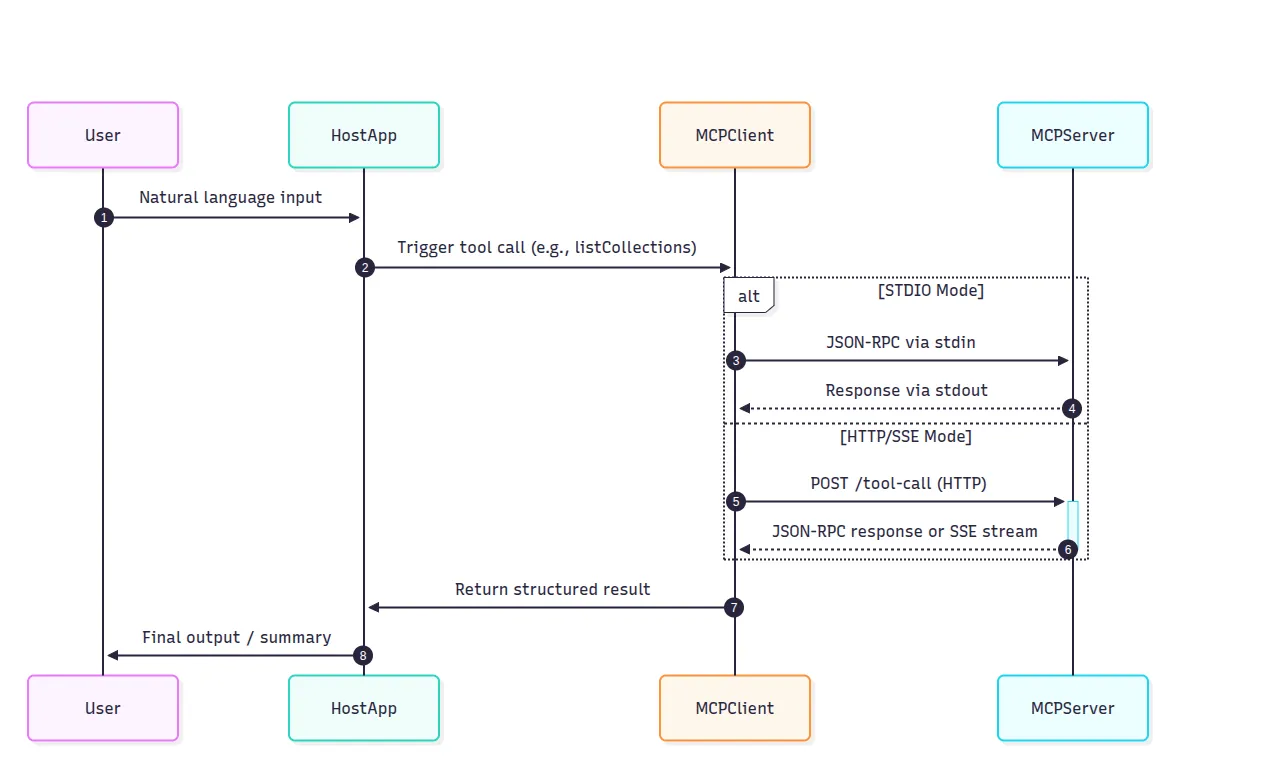
Both transports follow the same JSON-RPC format, so you can switch transports without rewriting logic.
So that’s the big idea behind MCP — a minimal, clean way for models to call tools without fragile prompt glue. No hallucinated commands. No manual context stuffing. Just clear inputs and outputs. But how does that actually work in a real app? Let’s walk through an example with a MongoDB-powered compliance assistant.
Imagine you’re building a GRC (Governance, Risk, and Compliance) assistant.
This assistant needs to:
In a traditional setup, you’d hardwire this logic using REST calls or Python scripts, stuffing schemas and credentials into prompt templates. Every integration would be custom — and fragile.
With MCP, each of these tools — MongoDB, Slack, GitHub — becomes a first-class function provider, exposing clearly defined methods like:
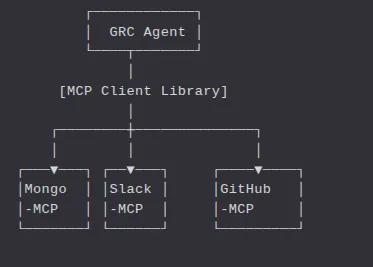
The GRC Agent (our Host App) simply calls these tools using MCP’s JSON-RPC schema
Scenario: Detect and Report Policy Violations User instruction: “Check the compliance database for any policy violations today and notify the team on Slack.”
1. User Input → Host App → LLM The GRC Agent (Host App) sends the user message to the model. The model is tool-aware and responds with:
{
"tool_calls": [
{
"name": "listCollections",
"arguments": {
"database": "compliance"
}
}
]
}
2. Host App Invokes Mongo-MCP via MCP Client This tool call is converted to a JSON-RPC request:
{
"jsonrpc": "2.0",
"method": "listCollections",
"params": {
"database": "compliance"
},
"id": "req-001"
}
3. Mongo-MCP Executes the Function Mongo-MCP maps this call to:
def listCollections(database: str) -> List[str]:
return mongo_client[database].list_collection_names()
It runs the function, gets the result, and responds:
{
"jsonrpc": "2.0",
"result": [
"audit_logs",
"policy_violations",
"user_sessions"
],
"id": "req-001"
}
4. Agent Chains the Next Call: runAggregation The model now generates a follow-up call based on the available collections:
{
"tool_calls": [
{
"name": "runAggregation",
"arguments": {
"database": "compliance",
"collection": "policy_violations",
"pipeline": [
{ "$match": { "timestamp": { "$gte": "2025-08-05" } } },
{ "$group": { "_id": "$severity", "count": { "$sum": 1 } } }
]
}
}
]
}
This results in another JSON-RPC call to Mongo-MCP, and the server returns:
{
"jsonrpc": "2.0",
"result": [
{ "_id": "high", "count": 5 },
{ "_id": "medium", "count": 12 }
],
"id": "req-002"
}
The agent passes this result back to the model with a prompt like:
“Summarize this policy violation data in plain English.”
The model replies:
“Today, there were 5 high-severity and 12 medium-severity policy violations in the compliance database.”
5. Model Calls Slack-MCP to Notify the Team Now the agent issues a final structured tool call:
{
"tool_calls": [
{
"name": "sendMessage",
"arguments": {
"channel": "#compliance-alerts",
"message": "5 high and 12 medium policy violations detected today. Please review."
}
}
]
}
The Slack-MCP server sends the message, and the workflow is complete. All this happened through structured JSON calls, not string manipulation or prompt engineering.

The Mongo-MCP demo looks clean. The model made structured tool calls. Each function worked as expected. No hallucinations. No brittle string templates. But that’s a happy path — and real systems aren’t just about working… they’re about working safely, reliably, and observably at scale.
In production, raw MCP falls short in a few key areas:
1. No Access Control (RBAC) Raw MCP has no built-in way to restrict who can call what.
In real orgs, RBAC (role-based access control) is non-negotiable — especially when models are wired into sensitive tools.
2. No Authentication or API Keys Raw MCP doesn’t handle
This means anyone with access to the mcp server can call any tool — and there’s no audit trail.
3. No Observability You can’t fix what you can’t see.
With raw MCP, you don’t have dashboards, logs, or traces. You’re flying blind.
4. No Guardrails LLMs are creative — sometimes too creative.
Raw MCP has:
Without guardrails, one prompt bug can lead to thousands of Slack messages or accidental data wipes.
5. No Retry, Throttling, or Quotas In production
In production, tools don’t always behave perfectly — they can fail, time out, or respond slowly. Without safeguards, even well-behaved models can:
The raw MCP protocol assumes everything just works — a “happy path” world. But real-world infrastructure is messy. You need smart retry logic, caching, rate limiting, and access control to stay sane at scale.
This is exactly what the TrueFoundry Gateway provides.
In the first half of this article we learned what the Model-Context-Protocol is and used a Mongo mcp server to automate a legacy GRC platform. That toy example is great for a hack-day, but it quickly runs into real-world friction:
TrueFoundry’s AI Gateway packages the missing plumbing—an MCP registry, central auth, RBAC, guard-rails, and rich observability—so teams can move from “hello-world agent” to production safely and repeatedly.
TrueFoundry positions one of the best MCP gateway as a control-plane that sits between your agents (or Chat UI) and every registered MCP server and LLM provider.
Key capabilities include:
Think of it as the API gateway + service mesh + secret store for the emerging MCP environment. “As noted in the MCP Server Authentication guide, the Gateway handles credential storage and token lifecycle automatically.”
The very first step in the UI is to create a group—e.g. dev-mcps or prod-mcps. Groups let you attach different RBAC rules and approval flows to different environments.
“You can follow the TrueFoundry MCP Server Getting Started guide for detailed steps.”
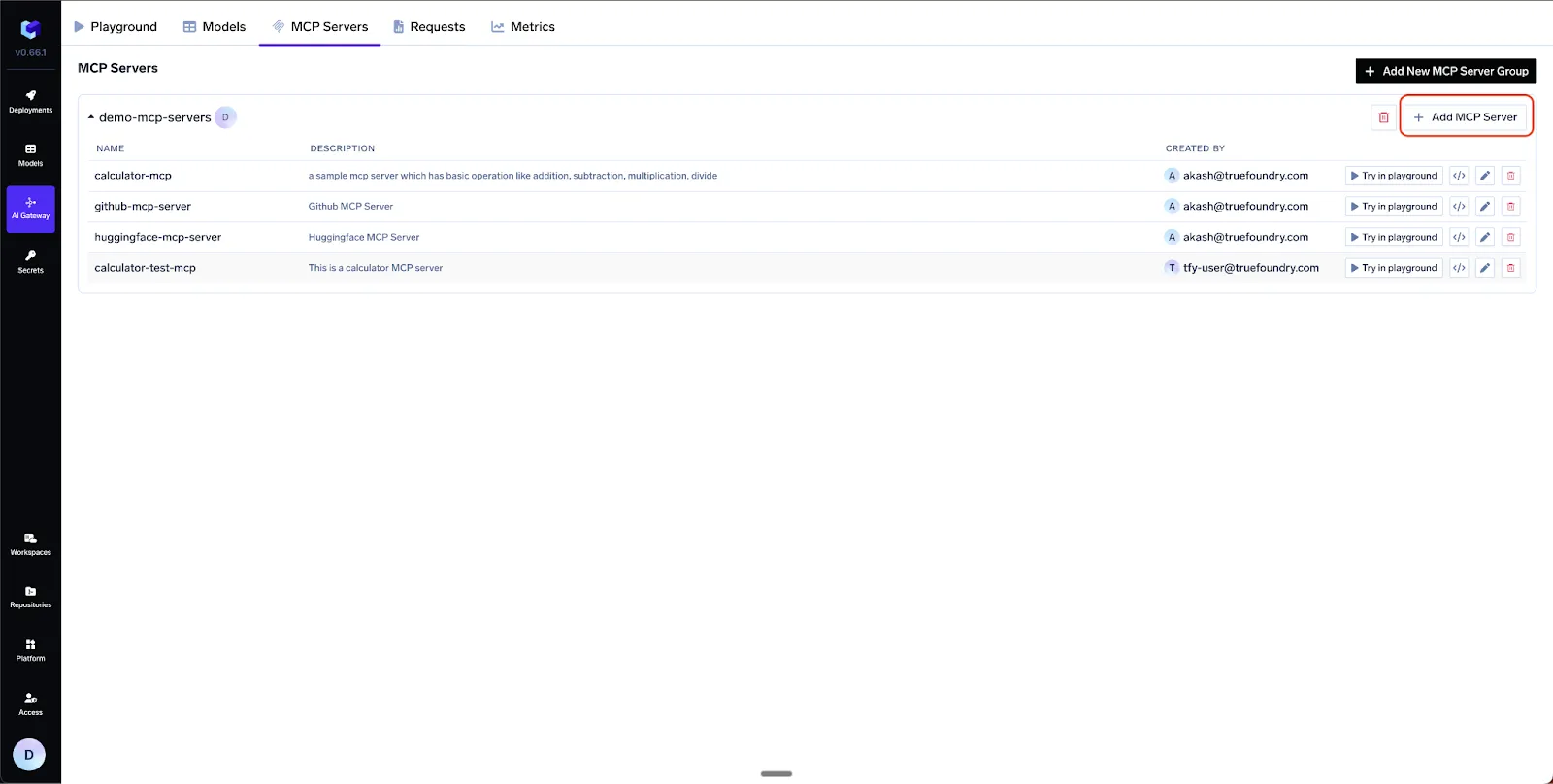
AI Gateway ➜ MCP Servers ➜ “Add New MCP Server Group
name: prod-mcps
access control:
- Manage: SRE-Admins
- User : Prod-Runtime-Service-AccountsYou can just as easily add:
Behind the scenes the Gateway stores credentials in its secret store and handles token refresh.
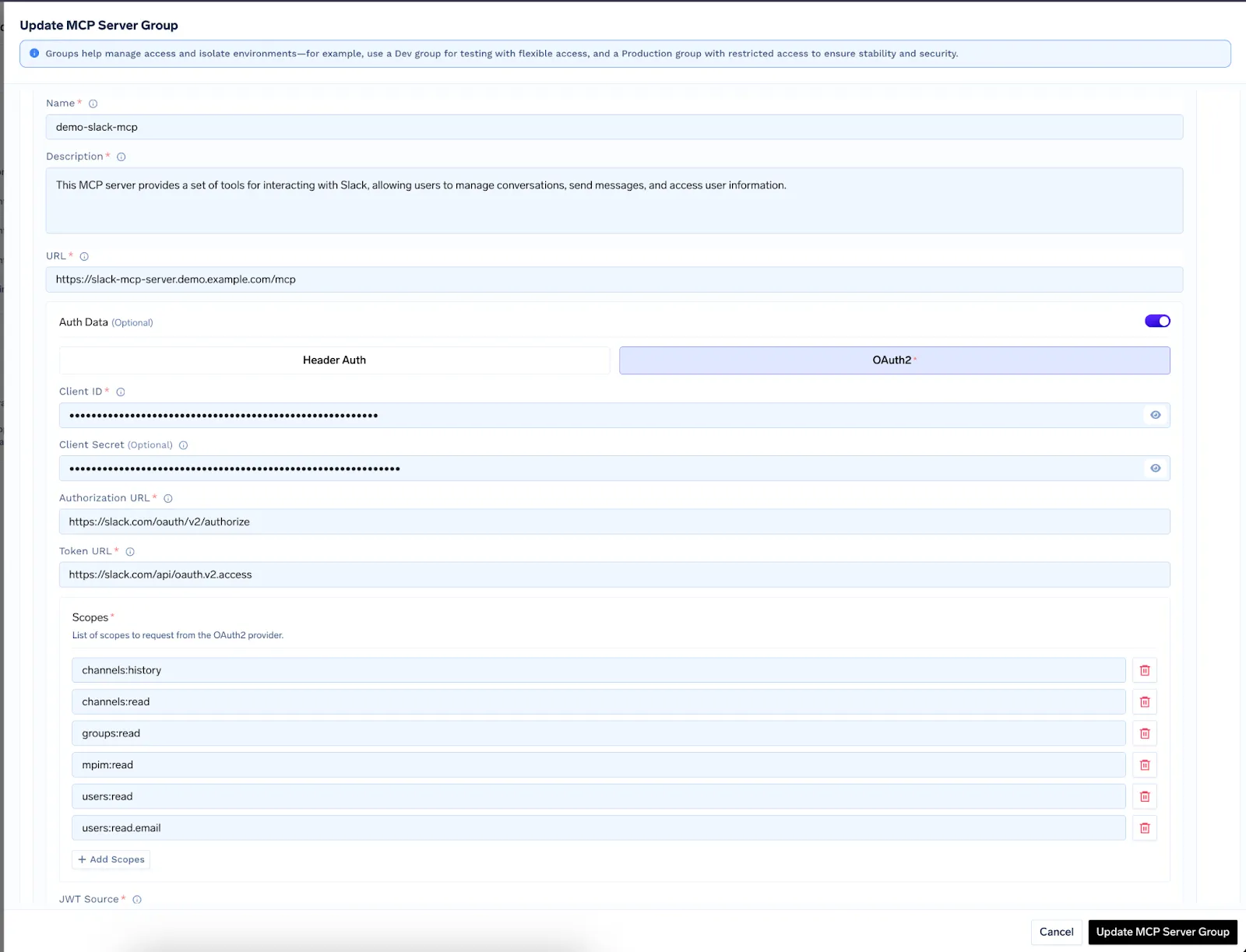
TrueFoundry supports three auth schemes per MCP server :
“These modes are described in more detail in the MCP Server Authentication documentation.”
Once a server is registered you don’t hand raw tokens to every developer. Instead they authenticate once to the Gateway and receive:
The Gateway checks the calling token against:
If any check fails the request is rejected before it hits your Slack workspace.
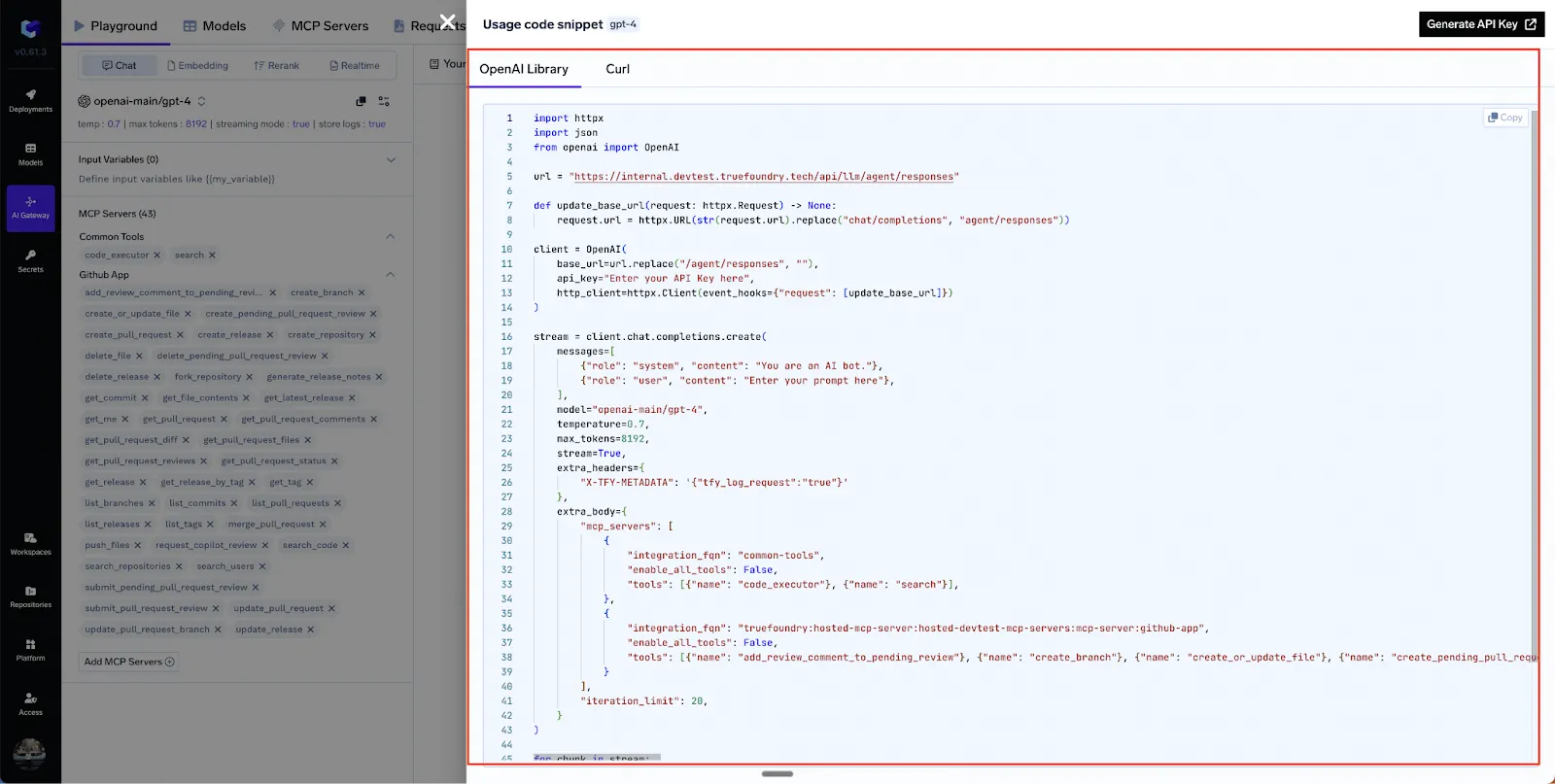
After experimenting in the UI you can click “API Code Snippet” to generate working Python, JS, or cURL examples .Below is a trimmed JSON body that wires three servers together (GitHub, Slack, Calculator):
POST/api/llm/agent/responses
{
"model": "gpt-4o",
"stream": true,
"iteration_limit": 5,
"messages": [
{
"role": "user",
"content": "Summarize open PRs on repo X and DM me the top blockers."
}
],
"mcp_servers": [
{
"integration_fqn": "truefoundry:prod-mcps:github-mcp",
"tools": [ {"name": "listPullRequests"}, {"name": "createComment"} ]
},
{
"integration_fqn": "truefoundry:prod-mcps:slack-mcp",
"tools": [ {"name": "sendMessageToUser"} ]
},
{
"integration_fqn": "truefoundry:common:calculator-mcp",
"tools": [ {"name": "add"} ]
}
]
}
“You can find a similar example in the Use MCP Server in Code Agent guide, which also includes complete Python and JS snippets.”
The streaming response interleaves:
This lets you build reactive UIs that show each step of the agentic loop in real time.
Even a “hello world” agent can cost real money and do real damage. TrueFoundry ships first-class observability:
All metrics come out of the box; no side-car agents or custom exporters required.
Many open-source servers still speak stdio (stdin/stdout) instead of HTTP. TrueFoundry recommends wrapping them with mcp-proxy and deploying as a regular service
# wrap a Python stdio server
mcp-proxy --port 8000 --host 0.0.0.0 --server stream python my_server.py
Ready-made templates exist for Notion and Perplexity servers, plus K8s manifests for Node or Python images. Once proxied, registration is identical to any other HTTP MCP endpoint.
“TrueFoundry’s MCP Server STDIO guide covers this proxying approach and provides deployment templates.”
Let’s return to our legacy GRC scenario but crank the ambition up:
“Keep our compliance evidence up-to-date. If a policy file changes in GitHub, store the diff in MongodB, create a Jira ticket, and post a summary in Slack.”
Because MCP is just JSON-RPC over HTTP or stdio, any internal service can expose tools, here is a small example :
From that moment onwards, every agent in your company can reason over compliance controls with exactly the same ergonomics as Slack or GitHub.
“This sheet has been adapted from the TrueFoundry MCP Overview, these guidelines help ensure secure and reliable deployments.”
MCP lets large language models (LLMs) speak the same language as tools — but it doesn’t handle things like security, discovery, or governance at an enterprise level. That’s where TrueFoundry’s AI Gateway steps in: it adds everything teams need out of the box — like a full MCP registry, built-in authentication, role-based access control (RBAC), deep observability, and a powerful Agent API to tie it all together.
An MCP registry is a centralized catalog that stores and manages available Model Context Protocol (MCP) servers and their specific capabilities. It acts as a searchable directory for AI agents, allowing them to dynamically discover tools and resources. This registry ensures models can identify the correct services needed to execute complex, multi-step tasks.
An MCP registry is a passive directory of tools, while an AI gateway is the active enforcement layer that manages traffic. The registry tells the system what resources exist, whereas the gateway controls access, handles authentication, and applies security policies like PII masking or rate limiting during the actual execution of model requests.
Yes, an AI gateway can function without an MCP registry using static configurations, but it loses the flexibility of dynamic tool discovery. Without a registry, developers must manually hardcode every server connection, making the system difficult to scale and maintain. Integrating a registry allows the gateway to automatically adapt as new tools are added to the ecosystem.
The AI gateway retrieves metadata and governance rules from the MCP registry to validate incoming requests in real time. It cross-references user permissions and security requirements defined in the registry before routing traffic to the appropriate server. This ensures that every interaction remains compliant with organizational standards and data residency protocols.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




