














June 26, 2026
|
5 min read

Published: March 30, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
It started with an idea: let an AI agent handle a multi-step research task. Connect it to a few tools via MCP, give it access to the right data sources, and let it run.
What actually happened was more instructive. The agent had more access than the task required. It called tools in sequences nobody anticipated, and there were no logs to explain what it had touched or why.
That same token that made the demo work could have wiped the company's shared drive if the model hallucinated or encountered a malicious prompt embedded in the document it was asked to read.
This is the fundamental challenge of MCP security. As the Model Context Protocol becomes the standard for connecting LLMs to external tools and databases, securing these connections requires strict security measures.
This guide explains why traditional API security fails for ai agents, what the real attack vectors look like, and what Zero Trust means in this context. It also details how some platforms charge a premium for security controls that should be standard.

Unlike traditional software that executes deterministic workflows, AI agents make dynamic decisions about which MCP tools to use and how to use them. This autonomy changes how risk propagates through MCP environments and introduces new classes of exposure that impact your security posture.
The AI Agents pose a new type of risk that is fundamentally different from traditional software systems. Their unique combination of autonomy, access, and speed creates unique security risks, especially in MCP-based systems.
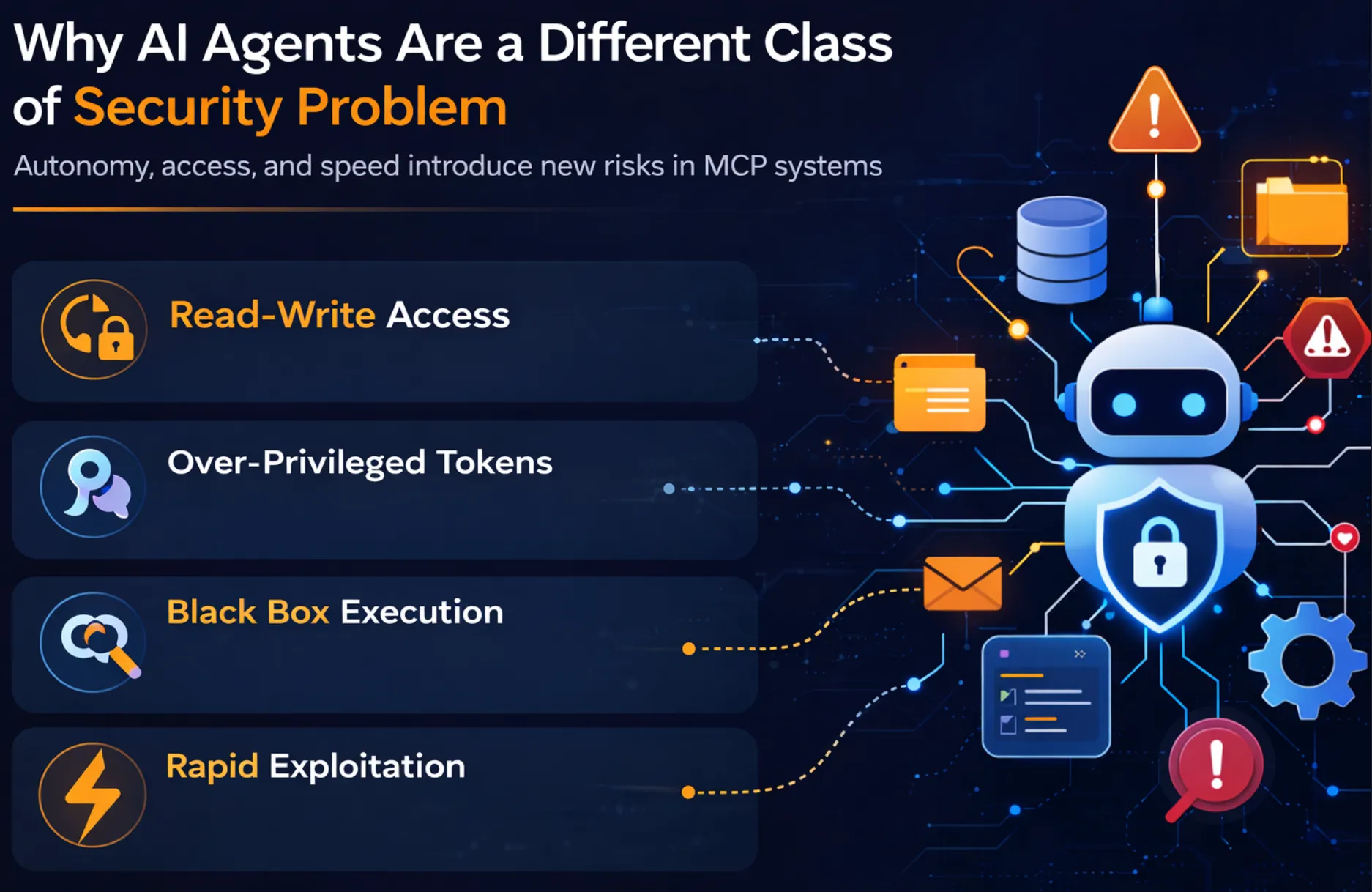
The Model Context Protocol enables powerful tool orchestration, but it also creates new attack surfaces across prompts, tool metadata, and agent execution flows. Unlike traditional APIs, agents interpret instructions and metadata dynamically, which makes subtle manipulation far more dangerous.
The sections below outline the primary attack vectors introduced by MCP-enabled systems.
Prompt injection is not new, but MCP takes it to a broader scale. Because the agent connects to live tools, malicious prompts, even within external content, can trigger real actions. The attacker includes malicious instructions in a document, webpage, or API response that the agent processes.
The agent processes the instructions as legitimate and acts upon them, unaware that they come from a malicious source. This indirect prompt injection is a severe threat to MCP implementations.
While teams focus on securing the agent’s use of data, few focus on securing the tool itself. Tool poisoning occurs at the level where the agent trusts the most. The attacker manipulates the tool descriptions, parameter schemas, or tool manifests, causing the agent to make malicious function calls disguised as legitimate ones.
The agent trusts the tool metadata, and that is where the exploitation happens, creating significant security risks for the enterprise.
The risk is not just the malicious tool call, but the chaining of it. Agents chain multiple tools together to perform a given task, where data exfiltration occurs with open permissions.
An agent with direct access to internal customer data and external web search functionality can be exploited to summarize internal data and transmit it out through search queries.
There is no specific "send data out" command needed; the agent is exploited through legitimate tool combinations, putting sensitive systems at risk.

The trust boundary has expanded with orchestrated multi-agent systems. Every interaction between agents is a potential point for injection attacks, as context passes from one agent to another.
In systems where agents pass information, a compromised upstream MCP client passes false context into the shared state.
The downstream agent treats the compromised context as trusted and continues the propagation without interaction with the original user, corrupting business operations.
While credential hygiene is a known problem, MCP systems introduce new pressure points. The speed of agent prototyping outpaces security practices, and static tokens in config files become casualties.
MCP systems frequently include hardcoded cloud credentials in config files that propagate into version control systems and environments.
Static tokens with no rotation and no scope are among the most commonly documented failures in the MCP architecture.

Conventional API security models rely heavily on perimeter defenses and trusted internal actors. MCP-enabled agents operate differently, invoking tools dynamically and chaining actions across systems. This shift requires a Zero Trust security model where identity, access, and execution are continuously verified.
As MCP adoption grows, a new category of tooling has emerged around securing agent access to tools and data. However, many vendors package foundational security capabilities as premium features, creating operational and cost barriers for teams deploying production AI systems.

TrueFoundry is an enterprise AI platform designed to help security teams build, deploy, and operate production AI systems securely. As organizations adopt MCP-based agents, TrueFoundry provides the infrastructure needed to enforce governance, identity, and access control across interactions.
The platform embeds Zero Trust MCP security into the execution layer so teams can deploy agents without adding separate security gateways or enterprise add-ons.
The rate of MCP adoption is such that most teams are operating under pressure, and under pressure, they take shortcuts. A demo works, the agent is functional, and governance is a feature to be added later, which rarely comes for free.
The issue is structural. When an agent can autonomously make calls between internal systems and external APIs, no amount of prompt-level governance can mitigate a gateway that was never designed for such a reality. You're not just securing a request, you're securing a decision-making process that can take dozens of actions before a human is even presented with a result.
The teams who will regret their MCP adoption are not the teams who went too fast. They're the teams who believe their existing security stack will adapt and adjust without significant changes. API Gateways traditionally do not understand tool schemas. Auth models were traditionally not designed for on-behalf-of scenarios involving autonomous agents. And paywalls for enterprises where basic role-based access control is a premium feature are not a security model; they're a revenue model.
Zero Trust for MCP is not a checkbox; it is a commitment. Every single tool call is verified, every single agent action is recorded, and every single permission is based on the user who initiated the workflow. The difference between teams that get this right and those that do after a breach is simply whether governance was a core part of the gateway from day one. TrueFoundry makes this the default, not a feature.

MCP security entails mechanisms that govern how AI agents access tools using the Model Context Protocol. Due to MCP allowing dynamic tool access, security must extend beyond basic API protection. It includes identity propagation, schema validation, and audit trails. TrueFoundry provides this through a central gateway that manages identity, security controls, and execution logs.
MCP security poses risks because agents dynamically interact with APIs. Security risks include prompt injection attacks, tool schema manipulation, and overprivileged service tokens. Multi-agent pipelines can propagate compromised context across sensitive systems. To mitigate these threats, tool calls must be validated and identity-based permissions enforced. TrueFoundry provides a secure gateway to govern these interactions.
MCP is a neutral protocol standardizing how AI models interact with tools. Whether it is safe depends on the security measures applied. Agents can gain elevated permissions and access private databases. However, by providing robust security infrastructure, such as the gateway provided by TrueFoundry, the protocol can be safely implemented to avoid exposing corporate resources.
Zero Trust assumes no entity is trustworthy. For an AI Agent using MCP, this means all tool calls must be authenticated and validated before execution to stop a malicious server. Agents must execute with the same privileges as the initiating user. TrueFoundry enforces Zero Trust by requiring identity propagation and monitoring all tool calls.
A confused deputy attack occurs when an AI Agent with high privileges is tricked into performing actions on behalf of a malicious actor, potentially leading to data leaks. Since the AI Agent holds valid privileges, the system may not detect the attack. Preventing this requires scoping agent privileges and validating tool call outputs.
Conventional API gateways handle deterministic calls where endpoints are known. MCP-based agents behave differently; they discover tools and dynamically create parameters. Security must be enforced at the tool schema level, not just at the network level, to block malicious code. TrueFoundry extends traditional gateways to meet new security needs related to MCP.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.webp)

.webp)
.webp)
.webp)
.png)






.webp)
.webp)

