














April 17, 2025
|
5 min read

Published: January 7, 2026
Blazingly fast way to build, track and deploy your models!
As large language models move from experimentation into production, teams are rethinking how AI traffic should be managed, secured, and observed. What once looked like a simple API integration now involves prompts, tokens, model routing, retries, cost tracking, and reliability concerns that traditional application infrastructure was never designed to handle.
Many engineering teams begin this journey by extending familiar API gateways such as Kong, leveraging existing routing, authentication, and rate-limiting patterns. As LLM usage grows, AI-native gateways like Portkey enter the picture, offering abstractions tailored to prompts, models, and token-level observability.
Both approaches aim to solve real problems but they come from fundamentally different starting points. Kong is rooted in managing HTTP APIs and microservices, while Portkey is designed specifically for LLM application workflows. The differences between these philosophies become increasingly important as AI systems scale across teams, environments, and production use cases.
In this article, we compare Kong and Portkey across architecture, observability, governance, and enterprise readiness. We’ll look at where each tool fits best, where limitations begin to surface, and what platform teams should consider as AI becomes a core part of their infrastructure stack.
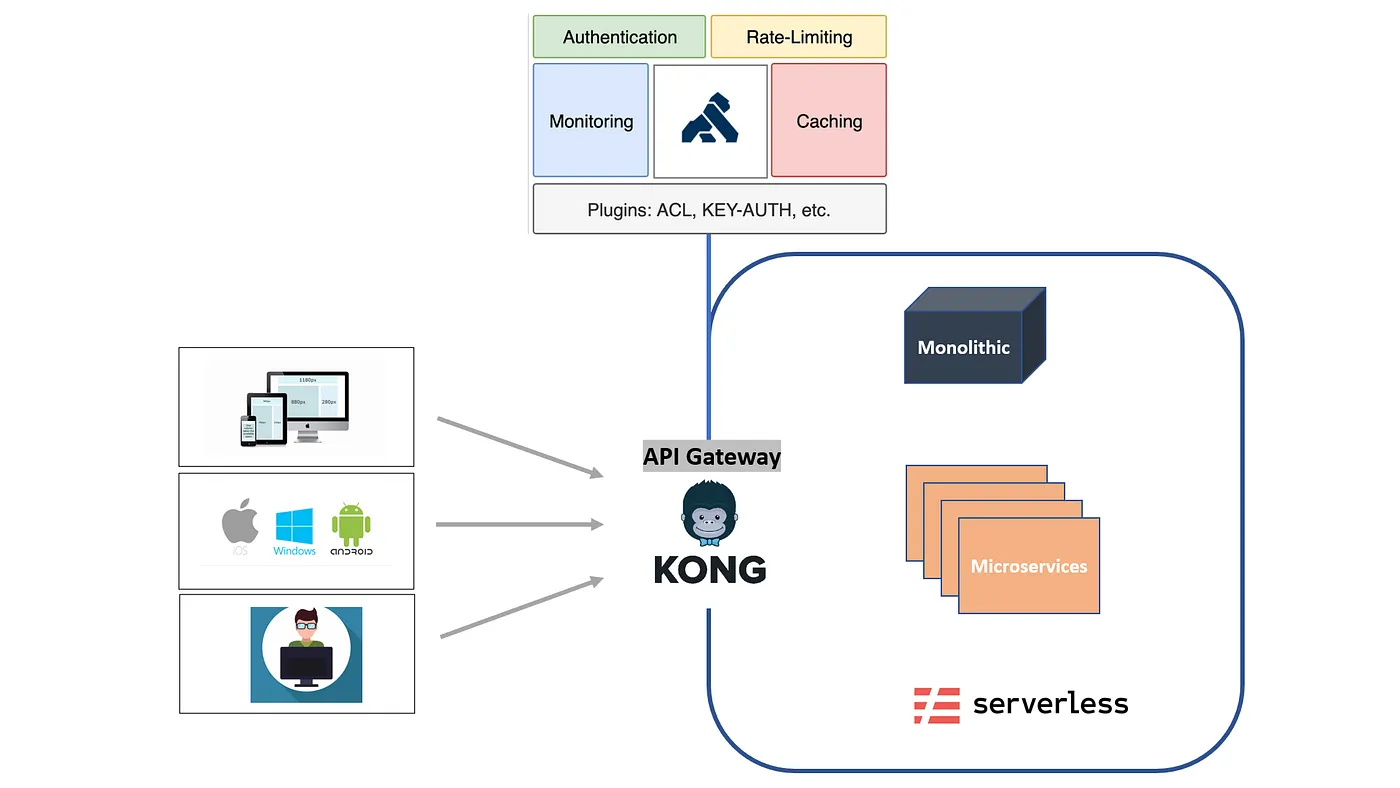
Kong is a widely adopted API gateway built to manage, secure, and route HTTP traffic across microservices. It is commonly used as an ingress layer in Kubernetes-based architectures and is well known for handling concerns such as authentication, rate limiting, traffic routing, and request-level observability.
From an architectural standpoint, Kong is optimized for API-first systems. Its core abstractions revolve around endpoints, services, routes, and plugins—making it a strong fit for traditional backend and microservices environments where requests are stateless, predictable, and uniform.
As teams introduce LLMs, Kong is often the first tool repurposed to manage AI traffic - treating LLM calls as just another API endpoint. This works initially for:
However, LLM traffic introduces properties that do not map cleanly to traditional APIs.
As AI usage grows beyond simple experimentation, these gaps become increasingly visible, especially in multi-team or cost-sensitive environments.
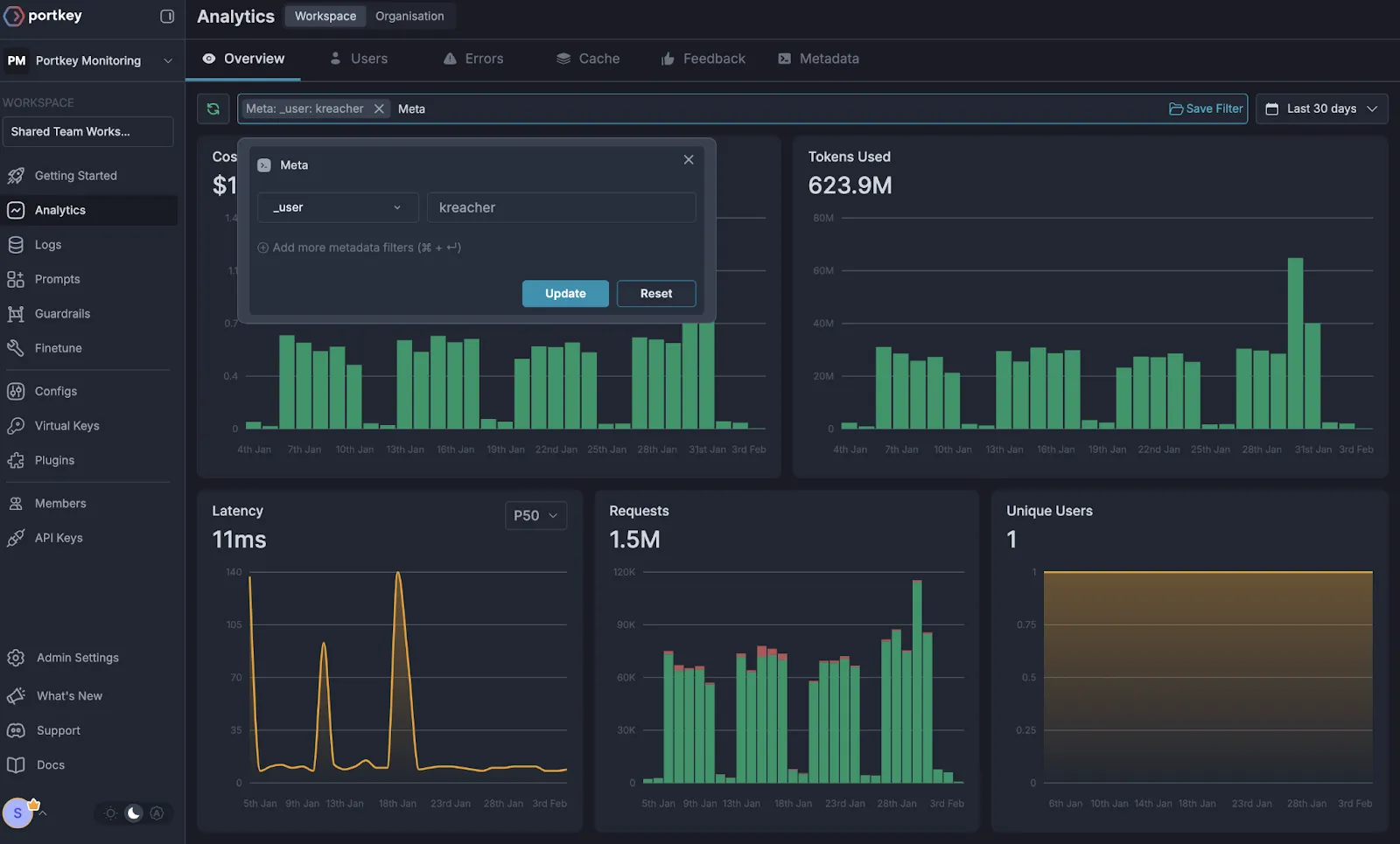
Portkey is an AI-native gateway designed specifically for applications built on large language models. Instead of treating LLM calls as generic API requests, Portkey introduces abstractions that are aligned with how AI applications actually work - prompts, models, tokens, and providers.
At its core, Portkey acts as an intermediary layer between AI applications and multiple LLM providers. It enables developers to switch between models, route traffic, and observe usage without tightly coupling application code to a specific provider’s API.
Compared to API gateways like Kong, Portkey is LLM-aware by design. It understands that:
This makes Portkey a strong choice for teams building and iterating on LLM-powered applications, especially in early or mid-stage production environments.
As LLM usage expands across teams and environments, some limitations emerge:
These constraints become important when AI moves from being an application feature to a shared enterprise capability.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

While Kong and Portkey can both sit in front of AI workloads, they are built on very different architectural assumptions. Understanding this difference is critical for platform teams deciding how to scale AI beyond a single application.
Kong is a good choice if:
In this setup, Kong works as a temporary extension of existing API infrastructure.
Portkey fits well when:
Portkey shines at the application layer, especially for fast-moving AI product teams.
Both Kong and Portkey address real challenges in the AI stack but they do so at different, and ultimately limited, layers. These limitations become apparent as AI evolves from a single application feature into a shared enterprise capability spanning multiple teams, environments, and regulatory boundaries.
Kong is designed to govern API requests, not AI behavior. Prompts, tokens, model selection, and agent execution are opaque to the gateway.
Portkey introduces LLM-aware controls, but governance remains largely application-scoped.
Enterprise AI teams, however, need answers to questions such as:
Neither Kong nor Portkey provides organization-wide AI governance as a first-class capability.
AI costs are shaped by a combination of:
Kong has no visibility into these AI-specific cost drivers.
Portkey exposes token-level metrics, but cost attribution becomes increasingly difficult as usage spans multiple teams, applications, and environments.
Without infrastructure-level attribution, platform and finance teams struggle to answer a basic question: who is spending what, and why?
Production AI systems demand strict separation between:
Kong was not built with AI environment isolation in mind.
Portkey optimizes for application workflows rather than enforcing hard environment boundaries.
For enterprises in regulated industries, this lack of isolation quickly becomes a deployment blocker.
Enterprise AI deployments must satisfy requirements such as:
These constraints must be enforced at the infrastructure layer, not embedded into application code or handled manually by teams.
Kong treats AI traffic as generic HTTP requests.
Portkey assumes cloud-first, application-level usage.
Neither approach is designed for compliance-first AI deployments.
AI in production is no longer limited to synchronous prompt–response calls. Real-world systems include:
Gateways that focus only on API traffic or prompt routing fail to govern the full lifecycle of AI workloads.
As AI adoption matures, enterprises converge on the same realization: Gateways alone are not enough. Running AI in production requires an infrastructure layer that unifies access, deployment, observability, governance, and compliance. This is why organizations eventually move beyond API gateways and LLM application gateways toward AI-native infrastructure platforms built for enterprise scale
The limitations of Kong and Portkey stem from the same root cause: both were designed to solve gateway-level problems, not enterprise AI infrastructure problems.
As AI becomes a shared, production-critical capability, enterprises need more than traffic routing or prompt abstraction. They need a platform that treats AI governance, deployment, observability, and security as first-class infrastructure concerns. This is where TrueFoundry stands apart.
TrueFoundry is built around the idea that AI workloads should be managed like any other critical production system but with AI-native primitives. Instead of operating only in the request path, TrueFoundry functions as a unified AI control plane.
At a high level, TrueFoundry brings together:
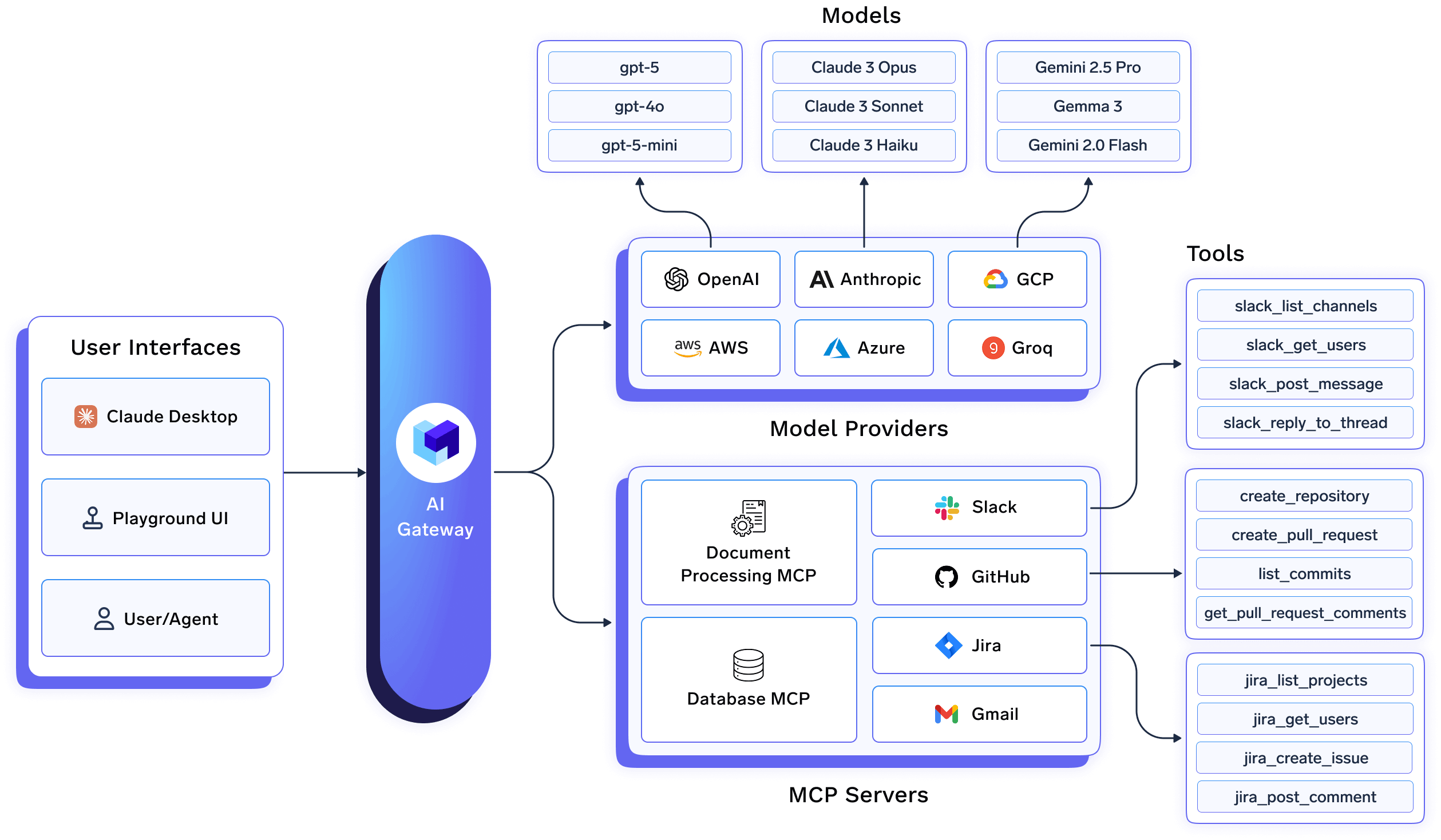
In many AI stacks, LLM usage is treated as an API integration problem: requests are routed, authenticated, and logged, but everything beyond the request boundary is left to individual applications. TrueFoundry takes a different approach by treating AI workloads services, jobs, and agents as infrastructure objects with lifecycle, ownership, and operational boundaries.
Rather than only deciding whether a request should be allowed, TrueFoundry controls where AI systems run, how they execute, and under what constraints, from deployment through runtime. This shift from request routing to lifecycle control is what enables consistent governance as AI usage scales.
Concretely, this shows up in several critical dimensions.
In gateway-centric architectures, access policies are typically embedded in application code, SDK configuration, or per-service gateway rules. This quickly becomes brittle as teams, services, and environments multiply.
TrueFoundry enforces access and usage policies at the workspace and environment level. Models, agents, and tools are scoped to environments such as development, staging, and production, with permissions and controls applied consistently across all workloads deployed in that environment.
Because policies are tied to environments rather than individual applications:
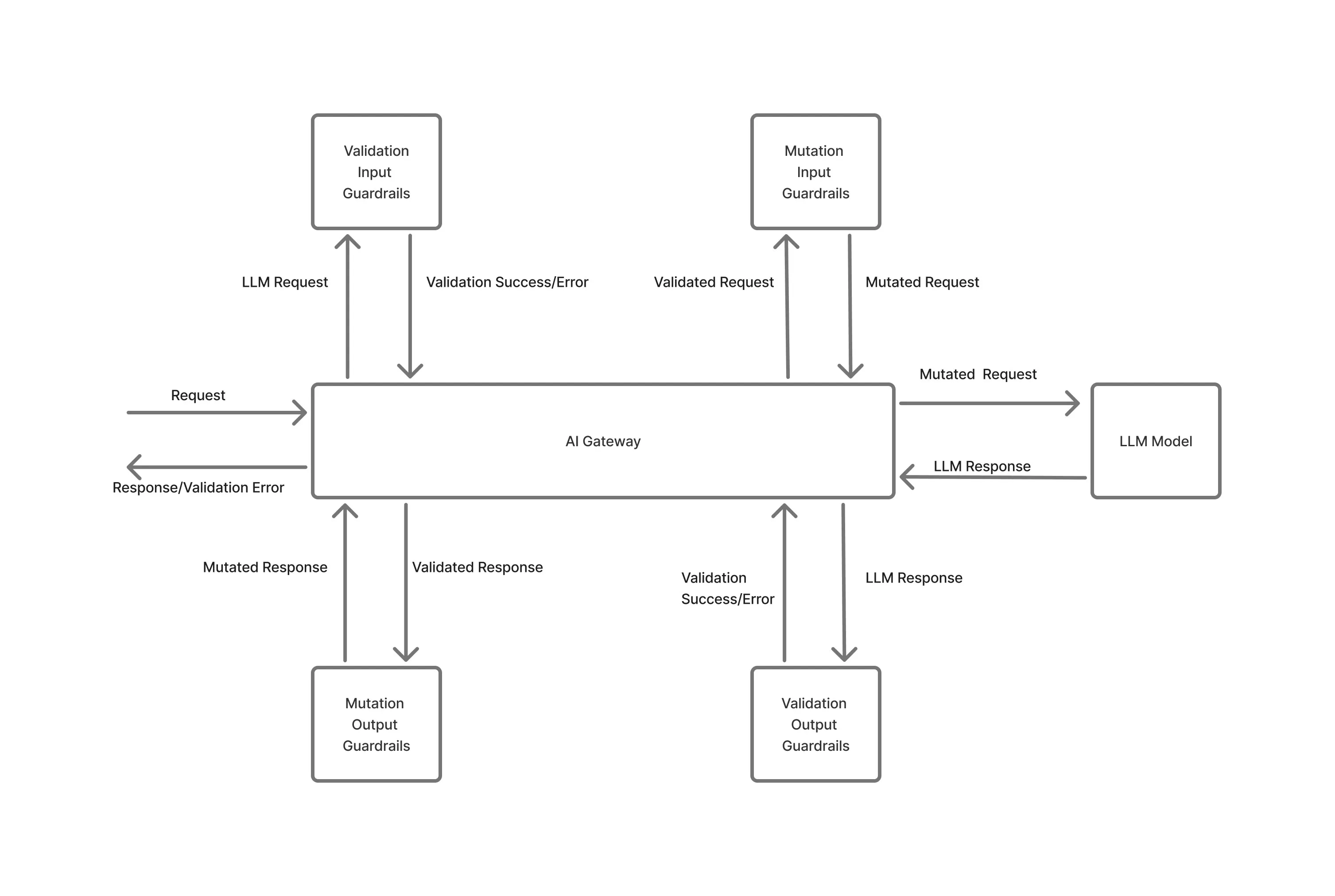
AI systems fail in production not because a single request is invalid, but because usage accumulates in unexpected ways through concurrency spikes, retry storms, or background workloads running at scale.
TrueFoundry enforces usage guardrails at execution time, with visibility into how workloads behave at runtime. Concurrency limits, throughput constraints, and usage caps are applied centrally across services and jobs that share underlying models or infrastructure.
Because these limits are enforced at the platform layer:
This is fundamentally different from client-side or SDK-level controls, which assume applications behave correctly and independently.
TrueFoundry enforces isolation at the deployment and environment layer, not just at request admission. AI services, batch jobs, and agent workflows are deployed as isolated workloads within defined environments, with access, policies, and resources scoped per environment.
These workloads run as separate deployments and jobs with independent runtime processes and failure domains, rather than sharing a single flat execution context behind a gateway. As a result:
Application-level LLM gateways, which operate primarily in the request path, do not control runtime execution or infrastructure state. As a result, they cannot provide this level of deployment and environment isolation - an issue that becomes increasingly visible as AI workloads scale across teams and production environments.

Token-level metrics are useful, but insufficient once AI workloads span long-running services, background jobs, and agent workflows. In production systems, cost and performance emerge from the interaction between:
TrueFoundry correlates these signals at the platform layer, allowing teams to reason about AI behavior the same way they reason about other production systems—by environment, service, and owner, not by individual API calls.
Many enterprise AI deployments operate under constraints that application-level gateways implicitly assume away, including:
TrueFoundry’s control plane is designed to operate across these deployment models, ensuring that governance, isolation, and observability remain consistent regardless of where inference runs. As a result, compliance properties - such as data boundaries and auditability are enforced as part of the infrastructure itself, rather than added later through application logic or process controls.
Kong and Portkey each solve important problems at different stages of AI adoption. Kong extends familiar API gateway patterns to AI traffic, while Portkey introduces LLM-native abstractions that make it easier to build and operate AI-powered applications.
However, as AI becomes a shared, production-critical capability, enterprises quickly encounter challenges that go beyond request routing or prompt management. Governance, cost attribution, environment isolation, and compliance all require controls at the infrastructure level not just at the gateway.
This is why many organizations move beyond API and LLM application gateways toward AI-native infrastructure platforms like TrueFoundry, which are designed to run, govern, and scale AI systems reliably across teams and environments.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox



.webp)


.webp)
.webp)


.webp)
.webp)
.webp)







