














July 22, 2026
|
5 min read

Published: April 9, 2026

Blazingly fast way to build, track and deploy your models!
Every Friday, I type the same thing:
"I'm Prathamesh. Senior Software Engineer at TrueFoundry. Working on the memory service. Format: what I shipped, what's in progress, blockers. Keep it concise."
Then I ask for my weekly update.
The AI writes it perfectly. But next Friday? Same ritual. It won't remember my name, my role, my project, or that I mentioned the same blocker three weeks in a row.
I built this assistant myself: simple chat UI, TrueFoundry's AI Gateway on the backend. It handles standups, emails, Slack messages, documentation drafts. It's genuinely useful. But every session starts from zero. I'm not using the AI's memory. I am the AI's memory.
ChatGPT solved this with built-in memory. But when you build your own LLM application, that infrastructure doesn't exist. You're on your own. Unless you build it yourself.
So I did. TrueMem is a persistent memory layer for AI applications. It gives any LLM long-term memory that works across sessions and even across different models. No more repeating yourself. The AI actually remembers.
The obvious solutions have obvious problems.
ChatGPT's built-in memory is locked inside OpenAI's ecosystem. You can't access it programmatically, use it with other models, or audit what's being stored. Truefoundry’s AI Gateway helps us to access multiple models, audit what’s being stored. For anyone building their own applications, it's a non-starter.
Retrieval-Augmented Generation (RAG) solves a different problem. RAG retrieves information from documents. It answers "what does this PDF say?" User memory is fundamentally different. It's personal, evolving, and relationship-based. The facts I share in conversation aren't documents to be indexed; they're context that should shape every future interaction.
Expanding context windows is the brute-force approach: include the entire conversation history. Modern models support 128K tokens or more, so why not? Because tokens are expensive, more context means slower inference, and everything vanishes when the session ends. You're paying a premium for amnesia with extra steps.
What we need is a dedicated layer that stores distilled facts about users permanently and retrieves only what's relevant for each query. That's the gap TrueMem fills.
Human memory doesn't work by storing every conversation verbatim. We have working memory for the current task and long-term memory for persistent knowledge. The two systems interact constantly: long-term memories inform how we interpret new information, while important new experiences get consolidated into long-term storage.
TrueMem mirrors this architecture with two distinct components: Short-Term Memory (STM) for conversation context and Long-Term Memory (LTM) for persistent user facts.
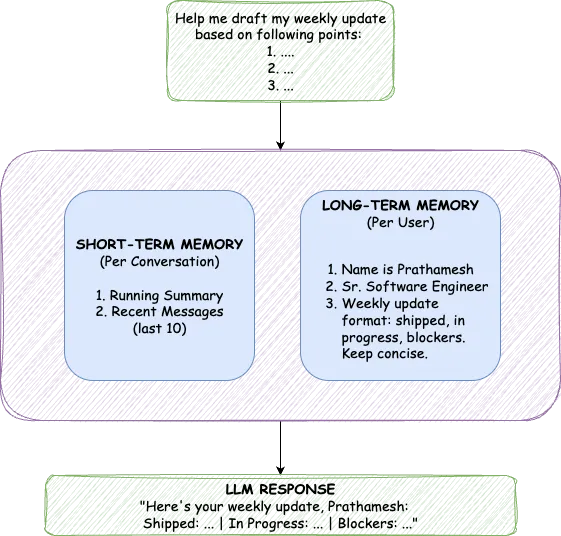
The separation matters because these memory types serve different purposes. STM captures what's happening right now, the full flow of the current conversation. LTM stores distilled facts that persist across all conversations. STM is always included in context; LTM is retrieved based on semantic relevance. Trying to solve both with one mechanism forces a compromise. The dual approach avoids it entirely.
Within a single chat session, the AI needs to remember what you discussed five minutes ago. This is STM's job, and it maintains two components: a running summary of older messages and the last twenty messages in full fidelity.
As a conversation grows, we continuously track the total token count. When it exceeds a threshold, a background worker compresses older messages into the running summary while keeping recent messages intact.

The summarization is asynchronous, so users never wait for it. When the threshold is exceeded, a background job fetches unsummarized messages, combines them with any existing summary, and generates an updated comprehensive summary. Those messages get marked as "summarized" and the cycle continues. Progressive compression means even hour-long conversations stay within reasonable context limits.
But conversation context alone isn't enough. What happens when the user returns tomorrow? That's where long-term memory comes in.
LTM stores facts about users that persist indefinitely: their name, profession, preferences, communication style, and anything else worth remembering across conversations. These aren't stored as raw text. They're converted to vector embeddings, enabling semantic similarity search.
When a user asks "What programming language should I use?", we don't keyword-match against stored memories. We embed the query and find memories that are semantically related. Memories like "User prefers Python" and "Works on ML infrastructure" surface because they're conceptually relevant, even without shared keywords.
The system populates LTM through two channels. Explicit memories come from direct requests: "Remember that I prefer bullet points" or "Don't forget I'm allergic to peanuts." We detect trigger phrases, extract the core fact, and store it with maximum importance. These memories are never automatically deleted.
Automatic memories come from conversation analysis. When a user mentions "I've been leading the ML platform team," that's valuable context even without an explicit save request. After each interaction, a background worker examines the conversation and extracts facts worth storing, each tagged with an importance score.
Importance scores range from one to five. A five means critical information that should never be forgotten: explicit user instructions, strong preferences, allergies. A four represents key personal facts like profession or location. Threes are general context like hobbies and interests. Twos cover temporary information like current projects. Ones are minor details. Explicit memories automatically get a five; automatic extractions typically score between one and four based on how significant the fact seems.
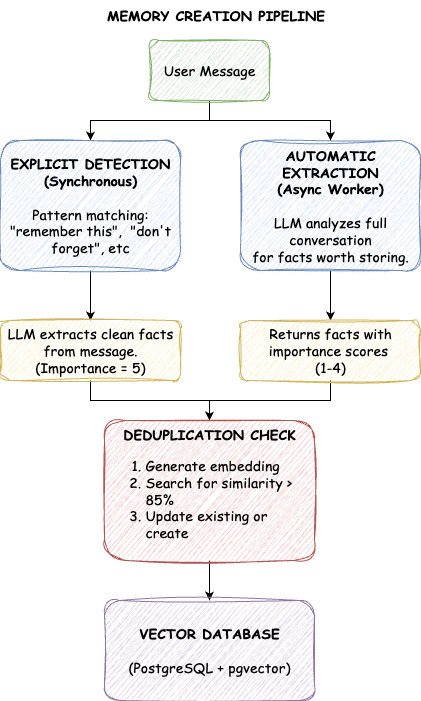
A challenge emerges with automatic extraction: what if a user says "I like Python" in one session and "I prefer Python over JavaScript" in another? Naive storage creates duplicates. TrueMem solves this with semantic deduplication. Before storing, we search for existing memories with similarity above 85%. If a near-duplicate exists, we update it rather than create a new entry. The database stays clean with each fact appearing exactly once in its most complete form.
Privacy is handled through transparency. Users can view, edit, and delete any stored memory. All memories are strictly isolated per-user. For enterprise deployments, the entire system runs on your infrastructure. Nothing leaves your environment.
What about extraction accuracy? Several mechanisms address this: importance scoring means automatic extractions get pruned before explicit memories; users can review and correct mistakes; and correct information reinforced across conversations accumulates higher importance while one-off mis-extractions fade through natural pruning.
Having memories stored is only half the problem. When a user sends a message, we need the right subset: not everything, just what's relevant. A power user might have 150 stored facts; including all of them would blow up the context window.
The process embeds the user's message, performs cosine similarity search, and returns the top ten matches. This takes under 10 milliseconds with proper indexing.
One exception: new users. If someone has fewer than ten memories, we include all of them regardless of similarity. Early in a relationship, every piece of context matters. Once the count exceeds ten, we switch to pure similarity-based retrieval.
This retrieval is part of a larger context preparation flow, and it needs to be fast.
A memory layer is only useful if it doesn't add noticeable latency. Users are sensitive to delays; even 200 milliseconds feels sluggish. Our target was sub-80ms for context preparation.
The key is parallelization. Context preparation involves several independent operations: generating an embedding, fetching recent messages, checking for explicit triggers, and searching long-term memories. Instead of running sequentially, we fire them off in parallel.
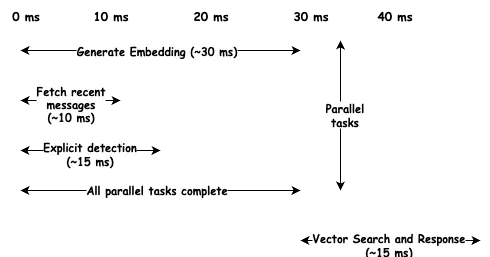
Embedding generation is slowest at around 30 milliseconds, but it runs alongside database queries that complete in 10ms. We pay for the longest operation, not the sum. Total latency lands around 45ms, well under target.
Heavy operations like summarization and memory extraction run asynchronously after the response is sent. The user never waits; processing happens in background workers. This separation between the fast synchronous path and slow asynchronous path is essential for production use.
With memory working reliably, an unexpected benefit emerged: we'd accidentally built something model-agnostic.
Here's what we didn't anticipate. Once memory lives outside the model, you're no longer locked to a single provider.
Switch from GPT-4 to Claude? Your memory persists. Use different models for different tasks, like complex reasoning with one and creative writing with another? They all share the same understanding of you. Fine-tune a custom model? It inherits existing user relationships from day one.
The memory layer becomes your constant; models become interchangeable.
Integration stays minimal: fetch context before the LLM call, log the interaction afterward. Two API calls transform any stateless model into one with persistent memory. No SDK lock-in, no complex integration. Just HTTP endpoints that fit any architecture.
Of course, memories can't grow forever. A system without lifecycle management would drown in outdated facts.
Every memory has an importance score from one to five. Explicit instructions get a five. Key personal facts get a four. General context gets a three. Temporary information gets a two. Minor details get a one.
When count exceeds a soft limit (150 by default), pruning kicks in. The system never touches importance four or above. Among lower-importance memories, it removes the lowest-scored first, using age as a tiebreaker.
Explicit user instructions survive indefinitely. Low-value automatic extractions get recycled to make room for new information. The memory stays relevant without manual curation.
A user opens a chat and types: "Help me draft my weekly update, based on following points …"
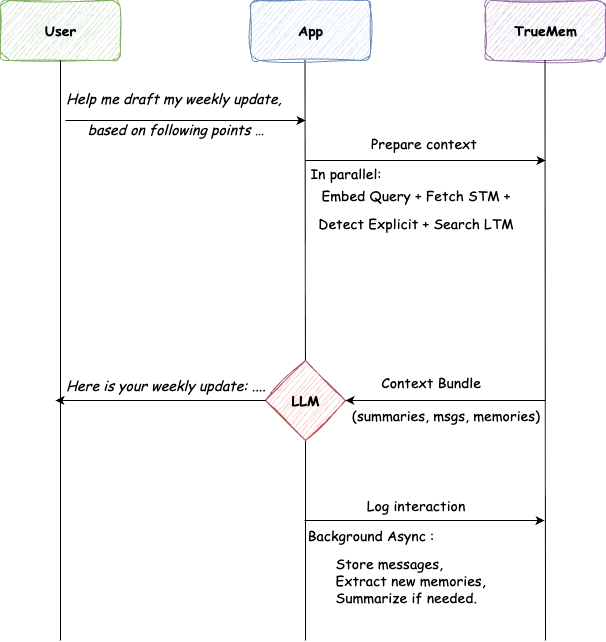
The app calls TrueMem for context. TrueMem assembles STM and relevant LTM, including "Name is Prathamesh," "Senior ML Engineer," "Working on memory service." This takes 45 milliseconds.
The LLM generates a personalized response: "Here's your weekly update, Prathamesh..." No ritual. No re-introduction. The AI knows who's asking.
After responding, the app logs the interaction. Background workers store messages, extract any new facts, update summaries as needed. Heavy lifting happens invisibly.
We chose PostgreSQL with pgvector over dedicated vector databases for pragmatic reasons. Most teams already run Postgres. Memories sit alongside user data with full ACID guarantees. For per-user collections of 100-200 vectors, pgvector delivers sub-10ms similarity search. For user-scoped memory, it's the right choice.
Background workers run on Redis-backed queues because LLM calls take seconds, far too long to block requests. Workers can retry failures, batch operations, and scale independently without affecting user-facing latency.
Remember that Friday ritual? "I'm Prathamesh. Senior Software Engineer. Working on memory service."
With TrueMem, it happens once. The AI remembers. Next Friday's update just works. Next month's email draft knows my signature. The context is always there.
Even better: switch to a different model, and the memory carries over. The daily assistant becomes model-agnostic without extra work.
That's the goal. AI that remembers you. Not because you keep reminding it, but because it actually does.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox








.png)

.webp)
.webp)
.webp)



.webp)


