














July 18, 2026
|
5 min read

Published: January 19, 2026
Blazingly fast way to build, track and deploy your models!
If you’ve ever sat in a meeting with your InfoSec or Legal team regarding a global ML deployment, you know the exact moment the mood shifts. It’s when someone asks, "Wait, where do the inference logs for the German customers actually sit?"
Data residency used to be a database problem. Now, with ML pipelines spanning training, serving, monitoring, and feature stores, it’s a sprawling mess across your entire infrastructure stack. GDPR, CCPA, data sovereignty laws across Asia – they aren't suggestions. Getting it wrong means massive fines or, worse, having to tear down an active deployment.
We've been using TrueFoundry to manage our ML infrastructure, and frankly, their approach to data residency is one of the main reasons we stuck with them. It fundamentally changes how we think about where data lives versus where it is managed.
Here is a look at how it works in practice and why it feels different than typical SaaS MLOps platforms.
The biggest issue with many managed MLOps platforms is that to get the convenience of their tools, you often have to ship your data (model artifacts, training snippets, logs) to their cloud. That’s a non-starter for highly regulated industries.
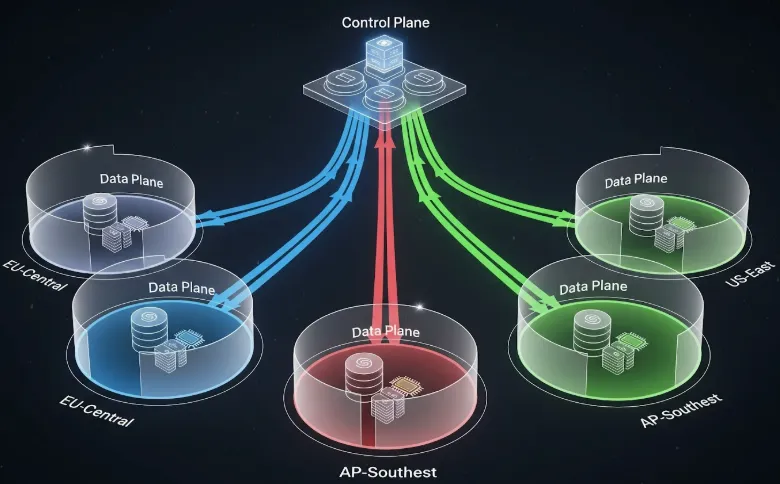
TrueFoundry operates differently. They employ a strict separation between the Control Plane (their SaaS management interface) and the Data Plane (your cloud accounts).
Think of it like this: TrueFoundry is the air traffic controller. They tell the planes where to go and when to land. But you own the airport, the hangars, and the planes themselves. TrueFoundry never actually possesses the cargo inside the plane.
When you connect a Kubernetes cluster (EKS, GKE, AKS) to TrueFoundry, you are essentially installing an agent. That agent reaches out to the TrueFoundry Control Plane for instructions, but all actual data processing and storage happens within your predefined network perimeter.
Here is a high-level view of that relationship.
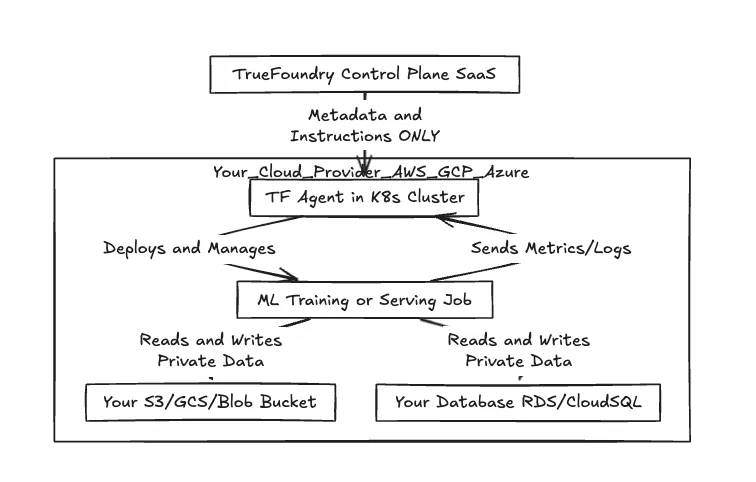
Fig 1: Workflow of the Control Plane vs Data Plane separation
As shown above, the "heavy lifting" and the actual data I/O remain entirely within your cloud environment boundary. The only thing crossing the wire back to TrueFoundry is metadata – job status, resource utilization metrics, and configuration specs.
How does this translate to a real-world setup where you have a team in the EU that legally cannot have their customer data touch US soil?
TrueFoundry uses a concept called "Workspaces." A Workspace is a logical grouping of resources that is tied to a specific underlying compute cluster and artifact storage integration.
To enforce residency, we set up distinct clusters in our required geographic regions.
We repeat the process for us-east-1 with a "US-Prod" workspace.
When an EU data scientist wants to deploy a model, they are granted access only to the "EU-Prod" workspace. When they trigger a training job or deploy a service, TrueFoundry's control plane ensures the compute happens on the Frankfurt cluster and the resulting model weights are saved to the Frankfurt S3 bucket. The platform physically cannot put the data anywhere else, because that workspace doesn't know any other infrastructure exists.
Below is a comparison of how data is handled in a typical managed ML SaaS versus this architecture.
Table 1: This is the Comparison of Data Handling Models
In a mature organization, you end up with a hub-and-spoke model. You have one centralized TrueFoundry control plane giving your platform engineering team a single pane of glass for ease of management, but the actual execution is geographically sharded.
This isolation is critical. It means that even if a developer accidentally tries to configure a job incorrectly, the infrastructure constraints prevent data leakage between regions.
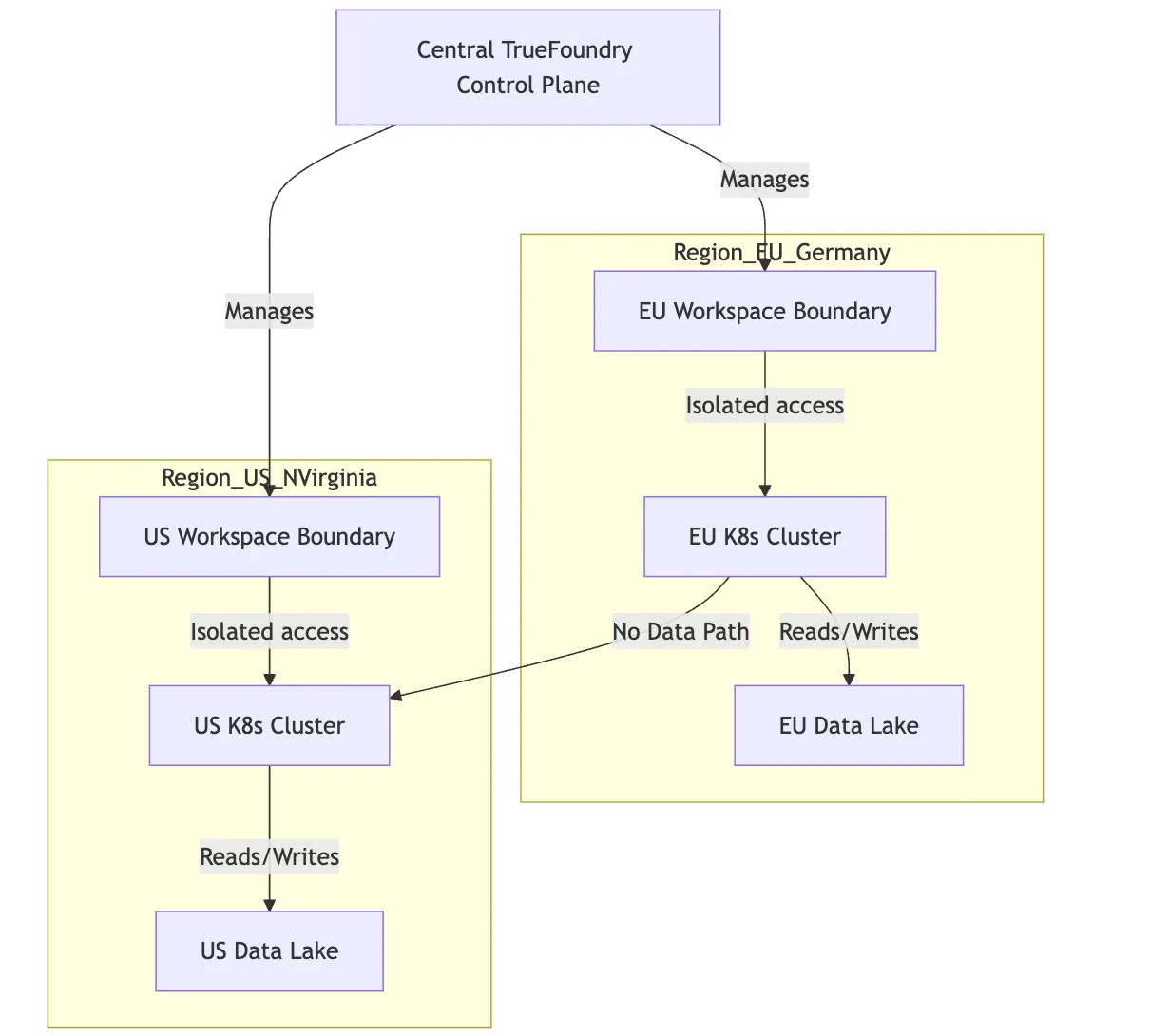
Fig 2: Diagram of Multi-Region Isolation using Workspaces
Data residency is rarely exciting work, but it’s foundational. If you get it wrong, nothing else matters.
The beauty of TrueFoundry’s architecture is that it doesn't try to be a "secure data bunker" itself. Instead, it respects the bunkers you’ve already built in AWS, Azure, or GCP. It allows us to provide our data scientists with a modern, Heroku-like deployment experience without constantly fighting our InfoSec team for exceptions. We define the perimeter once, attach TrueFoundry to it, and stop worrying about accidental data egress.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
.png)

.webp)

.webp)
.webp)



.webp)
.webp)
.webp)





