July 28, 2026
|
5 min read

Published: March 5, 2026

Blazingly fast way to build, track and deploy your models!
Amazon Bedrock is a viable starting point for teams strictly bound to the AWS ecosystem, offering a managed API layer for Foundation Models (FMs) without immediate infrastructure management. However, as AI workloads mature into production in 2026, engineering teams inevitably face the "Platform Wall." This barrier manifests as three primary friction points:
For architects designing for the long term, the objective shifts from simple API access to building a "Migration and Multi-Cloud Strategy." This guide evaluates the technical trade-offs, unit economics, and operational realities of the top alternatives to Bedrock. While managed services offer convenience, platforms like TrueFoundry are emerging as the preferred control plane for enterprises requiring Bedrock's ease of use combined with the economic and operational control of deploying on their own cloud infrastructure.
In this section, we analyze the engineering merit and architectural fit of the following competitors:
TrueFoundry operates as a platform-agnostic control plane rather than a proprietary ecosystem. Unlike Bedrock, which is a managed API where inference occurs on shared infrastructure, TrueFoundry orchestrates the compute and inference layers directly inside your own VPC or Kubernetes clusters (EKS, GKE, AKS, or bare metal).
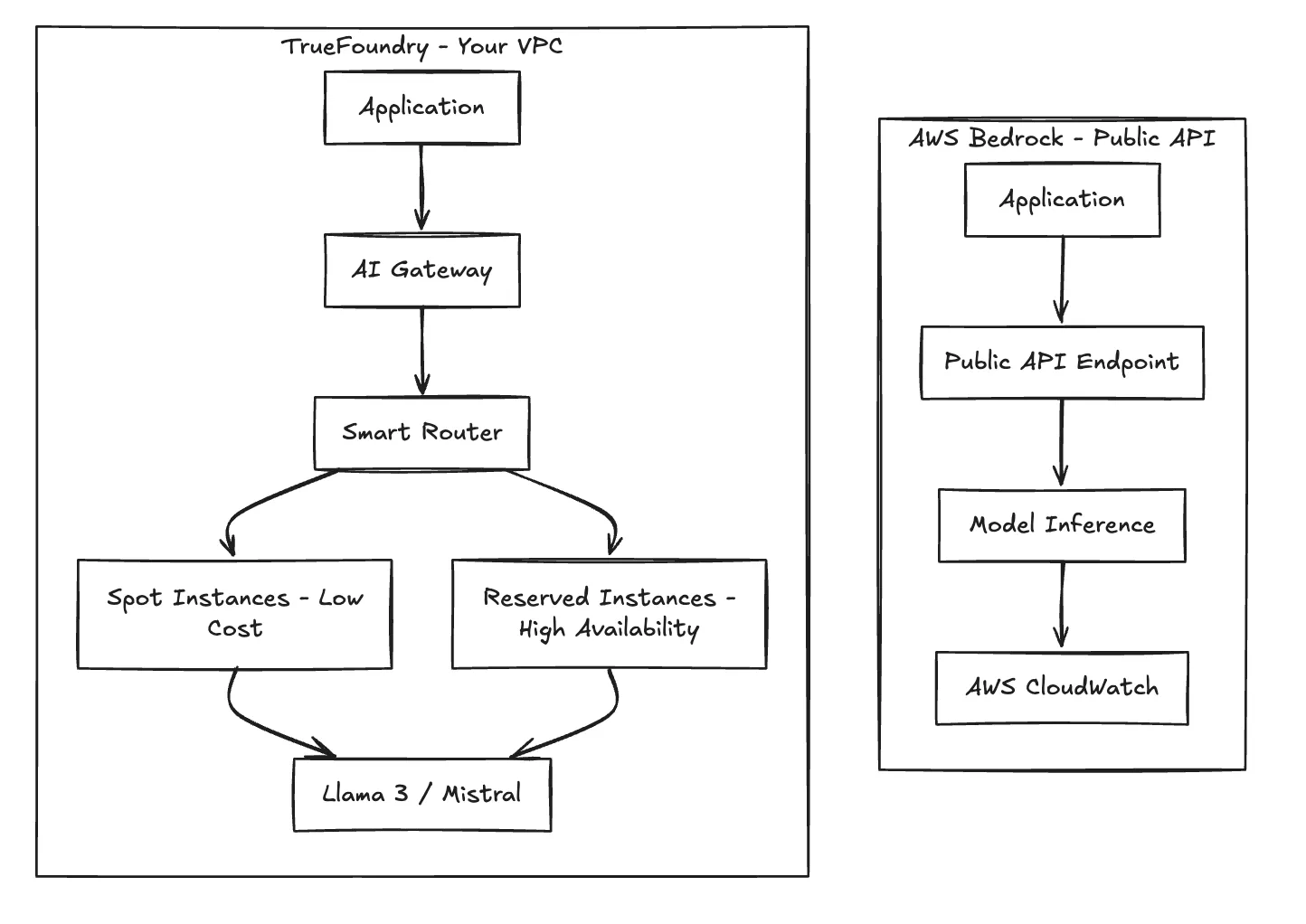
This architecture decouples the developer experience from the underlying infrastructure.
TrueFoundry does not charge a premium on inference tokens when you host your own open-source models. You pay the underlying infrastructure cost directly to your cloud provider. For high-volume workloads, this flat-rate compute cost is significantly cheaper than the linear scaling of token-based pricing.
Users on G2 consistently rate TrueFoundry 4.8/5, highlighting the platform's ability to abstract Kubernetes complexity for backend engineers. One review notes, "It turned our backend team into MLOps engineers overnight without the learning curve of Kubeflow."
Action: Sign up for TrueFoundry Free Tier to test the AI Gateway.
Vertex AI integrates deeply with the Google Cloud ecosystem. It provides native access to the Gemini family and supports AutoML. It excels in operationalizing models with built-in feature stores and vector search that integrates directly with BigQuery.
Pricing is segmented by operation. For example, Gemini 1.5 Pro is priced per 1k characters/images. Crucially, prediction on custom-trained models incurs node-hour charges. See Vertex AI Pricing for the specific breakdown of machine types (e.g., n1-standard-4 vs TPU v5e).
Vertex is optimal for organizations utilizing BigQuery for RAG (Retrieval-Augmented Generation) pipelines due to low-latency data access within the GCP backbone.
Azure OpenAI Service provides enterprise-grade access to GPT-4o and DALL-E 3. It adds compliance layers (SOC2, HIPAA) and private networking via Azure Private Link that standard OpenAI APIs lack.
Azure uses a "Pay-as-you-go" model and "Provisioned Throughput Units" (PTUs). PTUs provide guaranteed latency but require significant upfront commitment. According to the Azure OpenAI Pricing, standard GPT-4 models can cost significantly more per token than open-source alternatives hosted on self-managed VMs.
Default choice for enterprises with existing Microsoft Enterprise Agreements requiring strict RBAC via Microsoft Entra ID.
OCI Generative AI is built on a "Supercluster" architecture with RDMA networking, designed for high-performance training. It features a partnership with Cohere for embedded vector search.
OCI is aggressive on compute. As per Oracle Cloud Pricing, their GPU instances often undercut AWS and Azure, making them attractive for raw training jobs.
Best for High-Performance Computing (HPC) workloads and training massive foundational models from scratch where raw compute efficiency per dollar is the primary KPI.
Mosaic AI enables enterprises to pre-train and fine-tune LLMs using proprietary data inside the "Data Lakehouse." The architecture ensures training data never leaves the customer's governance boundary.
Pricing is denominated in Databricks Units (DBUs) plus underlying cloud costs. This decoupled model offers transparency but requires monitoring of instance types.
Ideal for organizations that view proprietary data as a competitive moat and need to train smaller, domain-specific models (SLMs).
Botpress is a low-code orchestration tool at the application layer. It features a visual flow builder and connectors for WhatsApp/Slack, focusing on dialogue management rather than model hosting.
Usage-based model charging per incoming message.
Best for product teams building customer support bots who do not need to manage GPU infrastructure.
Runpod offers "Serverless GPU" containers (Pods). It allows developers to spin up instances with pre-configured templates for vLLM or Stable Diffusion in seconds.
Runpod competes on raw hourly rates. For example, Runpod Pricing often lists A100 GPUs at rates significantly lower than hyperscalers, sometimes as low as $1.69/hr for community cloud instances.
Targeted at startups needing cost-effective, on-demand GPU compute for batch processing or fine-tuning without long-term contracts.
Focuses on industrial data science, providing a no-code environment for data prep and ML deployment, integrated with simulation workflows.
Uses a licensing unit model (Altair Units) pooled across their software portfolio.
Designed for manufacturing and aerospace sectors involving physics-based simulations.
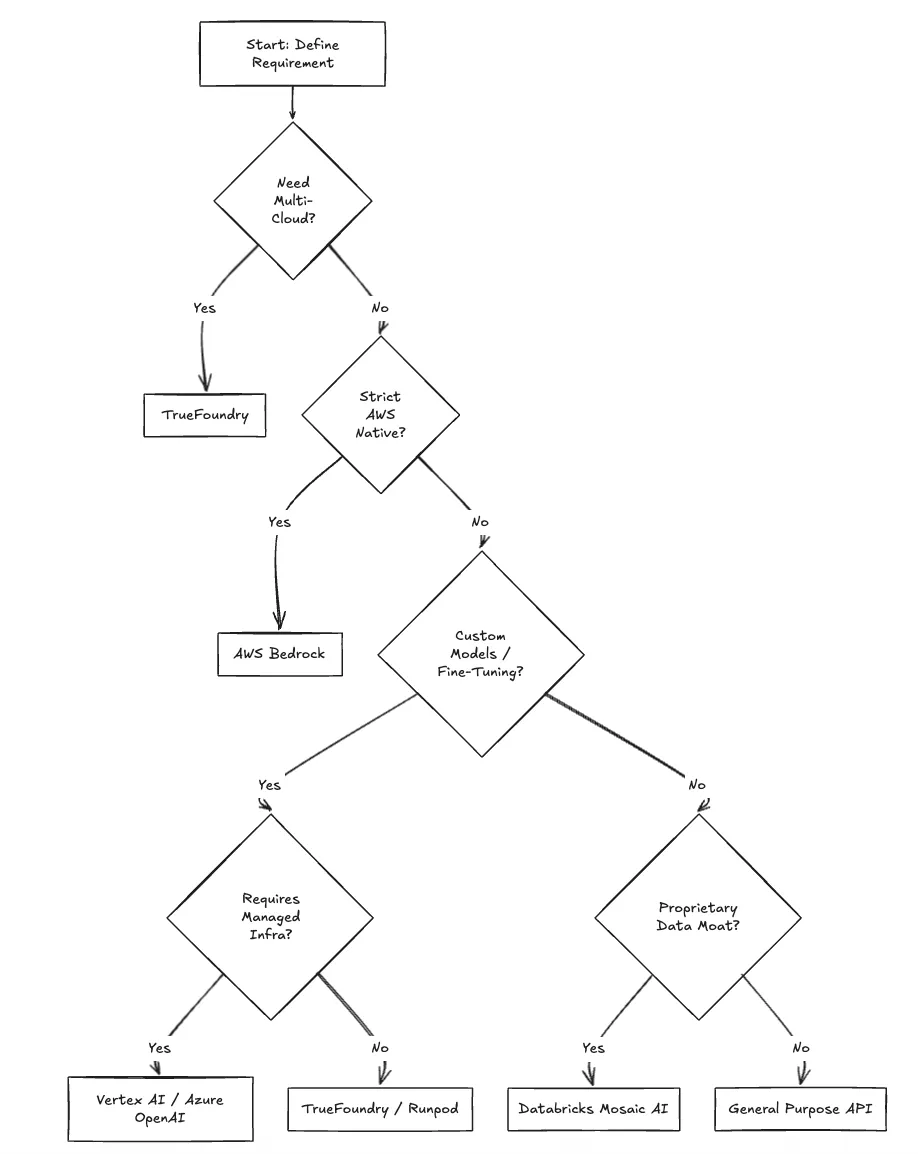
Selecting the right alternative requires a decision framework based on infrastructure maturity and architectural goals.
Are you planning a multi-cloud architecture?
If your strategy involves avoiding single-vendor dependency, a unified control plane is essential. TrueFoundry allows you to deploy to any cluster across AWS, GCP, and Azure from a single dashboard.
Is cost predictability critical for budgeting?
Token-based pricing is difficult to forecast. If you require stable monthly spend, owning the compute via TrueFoundry (on Reserved Instances or Spot) allows for deterministic budgeting. As cited in AWS Savings Plans, committing to compute usage can yield savings of up to 72% compared to On-Demand prices—savings you cannot realize with Bedrock's API pricing.
Do you require data sovereignty and VPC isolation?
Regulated industries often cannot send data to a public multi-tenant API endpoint. TrueFoundry deploys the inference endpoint inside your VPC, ensuring data never leaves your perimeter.
AWS Bedrock is a functional solution for teams prototyping within the AWS ecosystem. However, for engineering teams building multi-cloud, cost-efficient AI products, the "API-wrapper" model becomes a constraint. TrueFoundry offers the necessary bridge: the infrastructure ownership and flexibility of a custom build without the operational overhead of managing raw Kubernetes manifests.
For initial prototyping, Bedrock is efficient. However, for production applications, the markup on tokens often makes it less cost-effective than hosting models on your own infrastructure. Using an AI Platform like TrueFoundry AI Gateway which is made for rapid prototyping of AI models ensures you avoid high expenses and achieves significant cost savings.
Limitations include ecosystem dependency, unpredictable costs at scale (token-based pricing), and restrictions on deploying custom quantized models (like GGUF formats) that could save on compute. Teams often require seamless integration with various data sources for complex tasks while managing different versions of their ML models.
No. ChatGPT is a SaaS application. Bedrock is a PaaS (Platform as a Service) used to build applications like ChatGPT. It is a fully managed service where you can access OpenAI Large Language Models through simple text prompts.
Bedrock follows the AWS Shared Responsibility Model. While it offers encryption, your data is processed on AWS-managed infrastructure. Self-hosting via TrueFoundry inside your own VPC offers higher isolation. We implement strict security measures and access control to protect your AI development across architectures.
Vertex AI is similar to Amazon Bedrock with managed APIs but includes more robust MLOps tools for custom training.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)
.webp)
.png)
.webp)
.webp)


.webp)