




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
When LLMs move from a pilot to production across many teams, governance stops being optional. Someone will ask who can call which model, with what budget, on whose data — and whether every call can be reconstructed for an audit. This post is the control plane that answers those questions: virtual keys that decouple access from provider credentials, RBAC and policy-as-code, budgets and quotas as governance, compliance-grade audit logs, data residency, and how these gateway controls map to obligations like the EU AI Act — framed as what they help satisfy, not as a compliance guarantee.
Quarter-end at Northwind. Mei, the platform lead, got a question from the security and compliance team she couldn't answer: which teams had sent customer data to which model providers over the last quarter, and could she produce the records. She couldn't. Every service called the model providers through one shared API key, checked into a config years ago. There was no per-team attribution, no record of which requests carried customer data, no way to revoke one team's access without rotating the key for everyone, and no audit trail beyond the providers' own opaque billing. The LLM usage had grown from one prototype to a dozen production services, and the governance had not grown with it.
Nothing had gone wrong, exactly — no breach, no overspend anyone had caught. But "we can't answer the question" is its own finding, and it's the one that turns a routine audit into a project. This post is the control plane that makes the question answerable before someone asks it.
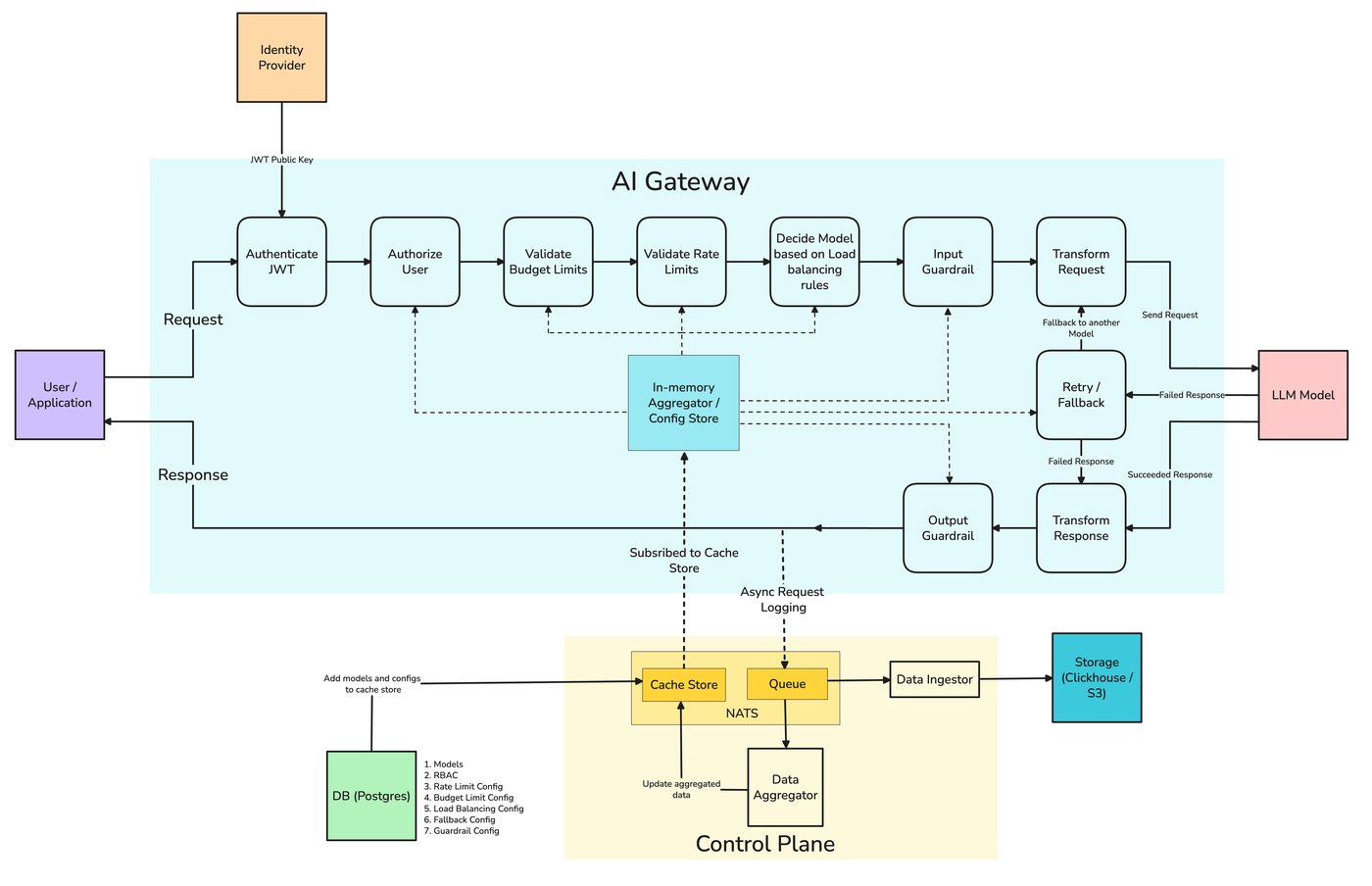
Everything in this post — virtual keys, RBAC, budgets, rate limits, audit logs, residency rules, and guardrails as enforced policy — is something TrueFoundry's AI Gateway expresses as configuration in one control plane. Access control defines who (users, teams, virtual accounts) may call which provider accounts and models; Personal Access Tokens and Virtual Account Tokens are how applications authenticate to the gateway instead of holding raw provider keys; rate-limit and budget configs apply per user, team, virtual account, model, or any custom metadata key; and guardrails — including Cedar and OPA as policy-as-code at the MCP-tool boundary — run as enforced rules at four lifecycle hooks.
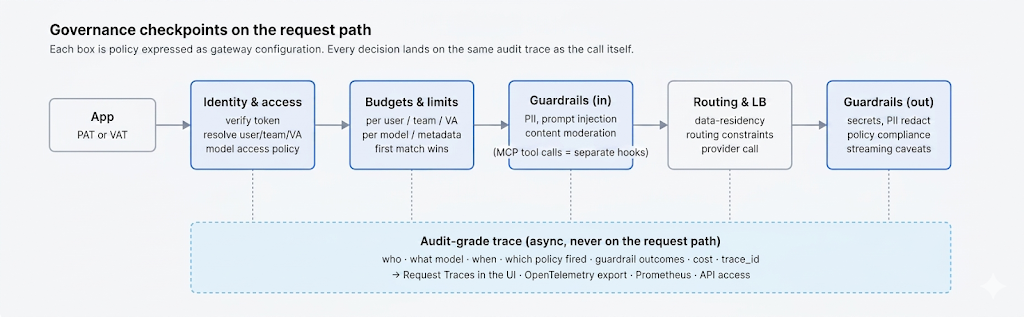
Every request crosses the same path: authenticate, resolve the calling identity, evaluate access policy and per-key budgets, evaluate rate-limit rules in order (first match wins), run input guardrails, route to a provider, emit an audit-grade trace, then run output guardrails. The same view becomes the record an auditor needs: who called what, when, against which policy, with which guardrail outcomes. Request Traces and OpenTelemetry export let the trail land in your SIEM rather than a vendor dashboard you cannot query.
The application code is unchanged from any OpenAI-style call — the governance is in the bearer token and the metadata header, not in client logic. A Personal Access Token resolves to a user; a Virtual Account Token resolves to a non-human identity for production services. The X-TFY-METADATA header carries the structured fields (team, project, cost_center, environment) that policies, budgets, and audit logs match against:
Calling the gateway with an identity and audit metadata (Python, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-virtual-account-token>", # VAT for production; PAT in dev
)
resp = client.chat.completions.create(
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": "Summarize this document."}],
extra_headers={
# Structured identity for audit, attribution, and policy matching.
"X-TFY-METADATA": '{"team":"support-ai","project":"helpdesk","cost_center":"cc-203","environment":"production"}',
},
)
print(resp.choices[0].message.content)A single prototype calling one model on one key needs no governance. A dozen services across several teams, calling several providers, on data of varying sensitivity, needs a control plane — because the failure modes are no longer hypothetical. A shared key means no usage attribution, so you can't tell finance which team is driving spend or tell security which team touched customer data. No spend limits means one runaway agent (recall the routing post's silent escalation) can burn the budget before anyone notices. No audit trail means you can't reconstruct what happened for an incident or an auditor. And no access control means shadow AI: teams wiring up models without anyone tracking it.
On top of the operational pressure sits regulatory pressure. The EU AI Act is phasing in obligations around record-keeping, transparency, and human oversight (section 7), and sector regimes — SOC 2, HIPAA, financial rules — have long expected access control and audit. The common thread is that they all assume you can answer Mei's question. AI governance is the work of being able to.

The root cause of Mei's problem is the shared provider key. A virtual key fixes it: instead of handing teams the real provider credential, you issue each team or app its own gateway-managed key that maps to the underlying provider key at the gateway. The application authenticates with its virtual key; the gateway holds the real one.
That one indirection buys most of governance. Usage attributes to the virtual key, so spend and data access can be reported per team (the cost-attribution post builds on exactly this). Revocation is local — disable one team's virtual key without rotating the provider key for everyone else. And access is scopable — a virtual key can be limited to certain models, routes, or data classes. The provider credentials live in one place, the gateway, rather than scattered across a dozen service configs where they can't be tracked or rotated cleanly. In TrueFoundry's AI Gateway, virtual keys are the unit that ties usage, budgets, and access policy to a team or application rather than to an opaque shared credential.
Virtual keys establish identity; RBAC and policy decide what that identity may do. The questions are concrete: which teams may use the expensive frontier model, which may reach a given provider, which may call which tools (in an MCP setting), and which data classes may be sent where. Encoding these as policy-as-code — with an engine like Cedar or OPA — makes the rules explicit, reviewable, and versioned, rather than living as tribal knowledge or scattered conditionals.
Illustrative access policy (conceptual — exact schema is gateway-specific)# Only the research team may call the frontier model.allow if principal.team == "research" and resource.model == "gpt-5.5"# Customer-data requests must stay on an EU-resident model.deny if request.data_class == "customer_pii" and resource.region != "eu"# Finance team may not call external providers at all — self-hosted only.allow if principal.team == "finance" and resource.kind == "self_hosted"
The value of policy-as-code is that it turns "who can call what" into something you can review in a pull request, test, and prove to an auditor — the same governance discipline applied to MCP tool access in TrueFoundry's MCP security work, where Cedar and OPA gate which tools an agent may invoke. The gateway is the enforcement point because it's the one place every request crosses before reaching a provider or a tool.
Budgets and rate limits are usually framed as protection against abuse or runaway cost. In a governance context they're also fairness and accountability controls: each team gets a defined share, overruns are visible, and no single team can quietly consume the org's entire model budget. The mechanics are hard and soft limits per team or virtual key, alerting as a limit approaches, and enforcement — typically a 429 — when it's exceeded, the same enforcement path described in the cost-attribution post.
The governance framing changes how you set them. A soft limit with alerting is an accountability tool — it tells a budget owner their team is trending over, without breaking production. A hard limit is a guardrail against the runaway case, like the silently-escalating cascade from the routing post. Rate limits per key also double as a fairness mechanism in a shared-capacity setting, keeping one team's batch job from starving another team's interactive traffic. Setting these at TrueFoundry's AI Gateway means they apply per virtual key, consistently, rather than being reimplemented per service.
The schema is intentionally rule-based so a policy reads the way you'd describe it to an auditor: who (subjects: users, teams, virtual accounts, or any custom metadata key), what (models), how much (limit and unit — requests or tokens per minute, hour, or day), and scoped how (one shared limit, or a separate limit per user / per model / per metadata value via rate_limit_applies_per). Rules evaluate in order and the first match wins, so specific rules sit above broader fallbacks:
gateway-rate-limiting-config (real schema from TrueFoundry docs)
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Specific override: bob's runaway script gets a hard 1k requests/day on gpt4
- id: "bob-gpt4-day-cap"
when:
subjects: ["user:bob@example.com"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Team-level token cap on a costly model
- id: "backend-team-gpt4-tpm"
when:
subjects: ["team:backend"]
models: ["openai-main/gpt4"]
limit_to: 20000
unit: tokens_per_minute
# 3. Fairness floor: every user gets their own 1M-token/day budget on any model
- id: "user-daily-token-cap"
when: {}
limit_to: 1000000
unit: tokens_per_day
rate_limit_applies_per: ["user"]
# 4. Project-level cap based on metadata in the request header
- id: "project-hourly-cap"
when: {}
limit_to: 50000
unit: tokens_per_hour
rate_limit_applies_per: ["metadata.project_id"]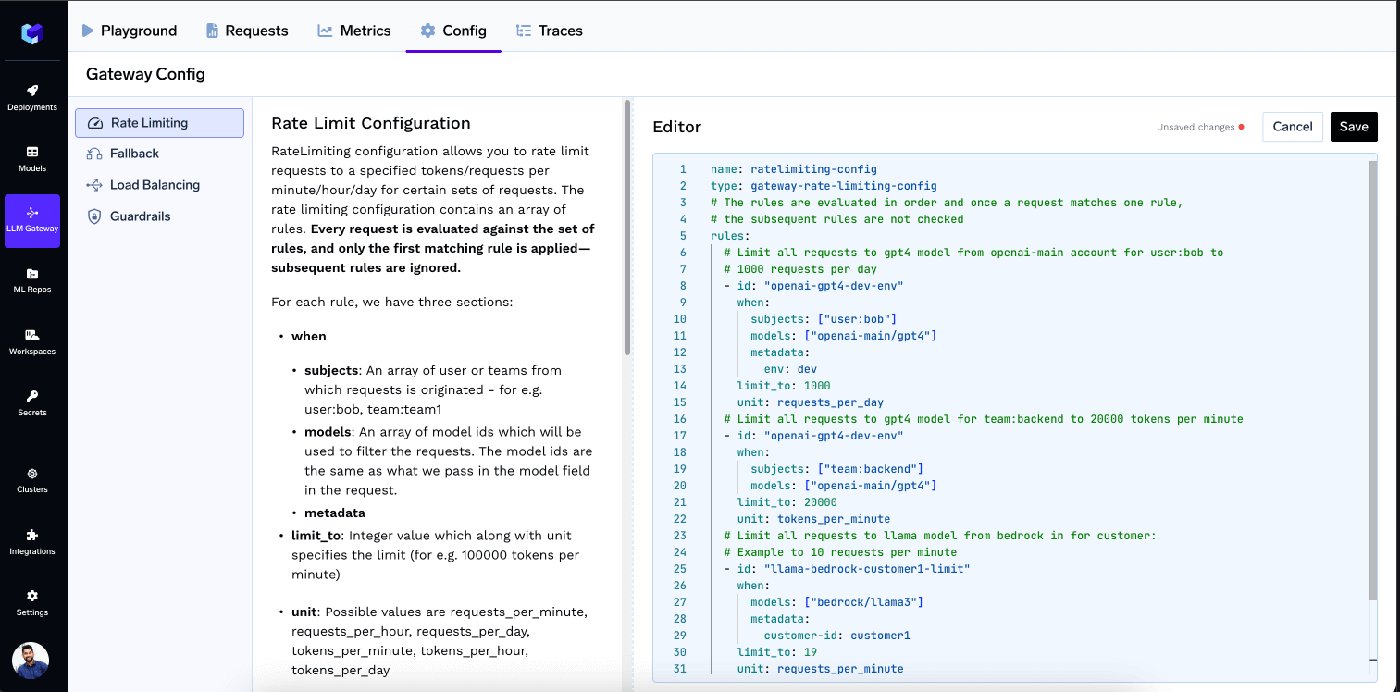
Under the hood, enforcement uses a sliding-window token-bucket algorithm with twelve 5-second buckets summed across a 60-second window — bursty enough that a brief spike doesn't lock a team out, strict enough that a runaway script trips it within seconds. Because the gateway resolves identity (PAT or VAT → user, team, virtual account) and reads X-TFY-METADATA on every call, the same rule expression covers the four governance audiences a single policy usually has to serve: a developer rate-limited per-key, a team rate-limited collectively, a model rate-limited globally, and a project rate-limited by its metadata tag.
The audit story is the other half. Every rate-limit decision, every guardrail outcome, every fallback hop, and every model call lands on the same request trace (x-tfy-trace-id in the response), and the same trace is what's exposed via Request Traces in the UI and exported through OpenTelemetry. That's what turns "we have logs" into "we have an audit trail we can hand to a regulator."
"We have logs" and "we have a compliance-grade audit trail" are different claims. A log that holds up to an audit has four properties. It is immutable — entries can't be edited or deleted after the fact. It is complete — every call records who (which team/virtual key), what (model, route, action), when, and which data category was involved. It is tamper-evident — entries carry something like a cryptographic trace ID or hash chain so alteration is detectable. And it is exportable — يتدفق إلى نظام SIEM الخاص بك بدلاً من أن يقتصر وجوده على لوحة تحكم مورد لا يمكنك الاستعلام عنها.
هذه هي الطبقة التي كانت ستمكن "مي" من الإجابة على سؤالها: سجل غير قابل للتغيير، خاص بكل فريق، وموسوم بفئة البيانات لكل مكالمة، يتم تصديره إلى نظام SIEM، ويمكن الاستعلام عنه بعد وقوعه. وهو يعتمد مباشرة على التتبع من منشور OpenTelemetry — نفس النطاقات التي تدعم قابلية المراقبة، مع خصائص الاكتمال وعدم القابلية للتغيير التي يتطلبها التدقيق.
بالنسبة للبيانات المنظمة، فإن مكان معالجة الطلب هو بحد ذاته قرار حوكمة، ويتم فرضه كتوجيه. يحافظ التوجيه المدرك للمنطقة على الطلبات التي تحمل بيانات شخصية من الاتحاد الأوروبي على نقاط نهاية مقيمة في الاتحاد الأوروبي. تمنع قيود المزود فئات معينة من البيانات من الوصول إلى مزودين معينين بالكامل. وبالنسبة للبيانات الأكثر حساسية، تحافظ النماذج ذات الأوزان المفتوحة المستضافة ذاتيًا على المعالجة داخل البنية التحتية الخاصة بك، بحيث لا يغادر المحتوى المنظم حدودك على الإطلاق.
تتكامل هذه القرارات مع محرك السياسات من القسم 3: سياسة تنص على أن "معلومات التعريف الشخصية للعملاء لا يجوز معالجتها إلا على نموذج مقيم في الاتحاد الأوروبي" هي قاعدة إقامة معبر عنها كسياسة وصول، ويفرضها المدخل عن طريق التوجيه — أو رفض التوجيه — وفقًا لذلك. لأن بوابة الذكاء الاصطناعي من TrueFoundry تقدم نماذج مستضافة وذاتية الاستضافة من خلال واجهة واحدة، تصبح الإقامة قاعدة توجيه بدلاً من تكامل منفصل، ويتم تسجيل اختيار مكان معالجة فئة البيانات مثل أي قرار آخر.
يدخل قانون الذكاء الاصطناعي للاتحاد الأوروبي حيز التنفيذ تدريجياً: بدأت الممارسات المحظورة والتزامات محو الأمية في مجال الذكاء الاصطناعي في التطبيق منذ فبراير 2025، والتزامات نماذج الذكاء الاصطناعي للأغراض العامة منذ أغسطس 2025، والتزامات الأنظمة عالية المخاطر — إدارة المخاطر، حوكمة البيانات، حفظ السجلات/التسجيل، الشفافية، والإشراف البشري — ستطبق حوالي أغسطس 2026، على الرغم من أن توقيت الأنظمة عالية المخاطر القائمة على الاستخدام (الملحق الثالث) يخضع لاقتراح تبسيط "الحافلة الرقمية" للمفوضية، والذي وقت كتابة هذا التقرير هو في مرحلة الحوار الثلاثي وسوف يؤجل أجزاء منه حتى ديسمبر 2027. التواريخ تتغير؛ تعامل معها كمنطقة حية وتأكد من النص الحالي.
حيث تساعد البوابة هو في الركيزة التشغيلية التي تفترضها العديد من هذه الالتزامات. يتوافق حفظ السجلات والتسجيل التلقائي مع سجل التدقيق المتوافق مع المعايير (القسم 5). يتوافق الإشراف البشري مع نقاط التفتيش التي تتضمن التدخل البشري والتي نوقشت في منشور حقن الأوامر للإجراءات عالية المخاطر. تتوافق حوكمة البيانات مع توجيه الإقامة وحواجز حماية معلومات التعريف الشخصية. يتم دعم التزامات الشفافية من خلال القدرة على إظهار ما فعله النظام وعلى أي بيانات.
لا تقتصر الحوكمة على الوصول والميزانيات فحسب؛ بل تتعلق أيضًا بالمحتوى المسموح بتدفقه. إن حواجز الحماية من بقية هذه السلسلة — اكتشاف معلومات التعريف الشخصية/المعلومات الصحية المحمية، والدفاع ضد حقن الأوامر، وتعديل المحتوى، واكتشاف الأسرار — هي ضوابط حوكمة عندما يتم فرضها كسياسة بدلاً من تركها لتقدير كل تطبيق. "يتم تنقيح معلومات التعريف الشخصية للعملاء في كل مسار" و"يتم فحص المخرجات قبل وصولها إلى سجل التسجيل" هي بيانات سياسة، والمكان المناسب لفرضها بشكل موحد هو البوابة.
هذا يكمل الحلقة مع المنشورات السابقة. الـ منشور معلومات التعريف الشخصيةنقاط الإدخال الأربع الخاصة به، الـ منشور حقن الأوامرحواجز الحماية للمدخلات/المخرجات، والتحكم في الوصول المستند إلى الدور (RBAC) والتدقيق في هذا المنشور هي جوانب من مستوى تحكم واحد: الهوية تحدد من، والسياسة تحدد ما يمكنهم استدعاؤه، وحواجز الحماية تحدد المحتوى الذي يمكن أن يمر، والميزانيات تحدد الكمية، والإقامة تحدد أين، وسجل التدقيق يسجل كل ذلك. حواجز حماية TrueFoundry تعمل عند نقاط ربط LLM و MCP كسياسة قابلة للتكوين ومفروضة، وهذا ما يحول مجموعة من النوايا الحسنة إلى حوكمة يمكن للمدقق التحقق منها.
ما الفرق بين المفتاح الافتراضي ومجرد وجود مفاتيح مزود منفصلة لكل فريق؟
تمنحك مفاتيح المزود المنفصلة بعض الإسناد ولكنها تترك بيانات الاعتماد الحقيقية منتشرة عبر تكوينات الخدمة، مما يجعل تدويرها صعبًا وتسريبها سهلاً، ولا تحمل أي سياسة. المفتاح الافتراضي يدار بواسطة البوابة: فهو يرتبط بمفتاح المزود الحقيقي مركزيًا، ويحمل سياسة التحكم في الوصول المستند إلى الدور (RBAC) والميزانية والإقامة الخاصة بالفريق، ويمكن إلغاؤه أو إعادة تحديد نطاقه دون المساس ببيانات اعتماد المزود أو أي فريق آخر. الوساطة هي جوهر الأمر.
هل يعني سجل التدقيق تسجيل المطالبات؟
لا — وعادة لا ينبغي لك ذلك. سجل البيانات الوصفية اللازمة لإعادة بناء ما حدث: الفريق، النموذج، المسار، الإجراء، فئة البيانات، أحداث حواجز الحماية، الطابع الزمني، ومعرف التتبع. تسجيل محتوى المطالبة الخام يعيد إنشاء مشكلة البيانات الحساسة التي تهدف حواجز حماية معلومات التعريف الشخصية (PII) إلى منعها. مستوى الامتثال يعني الاكتمال في البيانات الوصفية وغير قابل للتغيير، وليس نسخة حرفية من بيانات المستخدم.
هل ستجعلنا البوابة متوافقين مع قانون الاتحاد الأوروبي للذكاء الاصطناعي؟
لا. إنها تساعد في تلبية التزامات تشغيلية محددة — حفظ السجلات، التسجيل، دعم الإشراف البشري، حوكمة البيانات — لكن الامتثال يعتمد على تصنيف المخاطر الخاص بك، ودورك كمزود أو ناشر، والتوثيق، وتقييم المطابقة الذي لا تقوم به أي بوابة. تعامل مع البوابة كبنية تحتية ضرورية واستشر اللوائح الفعلية والمستشار القانوني بشأن ما تتطلبه حالة الاستخدام الخاصة بك. الجداول الزمنية لا تزال تتغير بموجب مقترح "Digital Omnibus".
أليس هذا مجرد منشور تحديد تكلفة الإسناد مرة أخرى؟
يتشاركون أساس المفتاح الافتراضي وتحديد المصدر لكل فريق، لكن المنظور يختلف. منشور التكلفة يدور حول الإنفاق — من يقوده، الميزانيات، استرداد التكاليف. هذا المنشور يدور حول التحكم والمساءلة — من يمكنه استدعاء ماذا، ما المحتوى الذي يمكن أن يتدفق، ما الذي يتم تسجيله للتدقيق، أين تتم معالجة البيانات المنظمة. نفس مستوى التحكم، التزامات مختلفة تقع عليه.
أين يجب أن تكون الحوكمة — في التطبيق أم في البوابة؟
في البوابة، لأن الحوكمة بطبيعتها شاملة: مجموعة واحدة متسقة من قواعد الوصول والميزانية والإقامة والتدقيق عبر كل خدمة، يتم فرضها عند النقطة الوحيدة التي يمر بها كل طلب. حوكمة كل تطبيق على حدة تنحرف وتترك ثغرات — وهذا هو السبب في بقاء مفتاح مشترك لسنوات. لا يزال التطبيق يمتلك الأحكام الخاصة بالمجال، مثل الإجراءات التي تنطوي على مخاطر عالية بما يكفي لتتطلب موافقة بشرية.
لم يكن اكتشاف تدقيق مي خرقًا؛ بل كان عدم القدرة على الإجابة. الحوكمة هي العمل غير الجذاب لجعل السؤال قابلاً للإجابة مسبقًا — من، ماذا، كم، أين، وعلى بيانات من — والبوابة هي المكان الذي يتم فيه فرض هذه الإجابات وتسجيلها، طلبًا واحدًا في كل مرة.
بوابة الذكاء الاصطناعي من TrueFoundry هي مستوى تحكم على مستوى المؤسسات يقع بين تطبيقاتك وأكثر من 1600 نموذج — عبر OpenAI، Anthropic، Google، AWS Bedrock، Azure OpenAI، ونماذجك المستضافة ذاتيًا — خلف واجهة برمجة تطبيقات واحدة متوافقة مع OpenAI. إنها تحول ضوابط الحوكمة في هذا المنشور إلى تكوين بدلاً من كود خاص بكل خدمة: حسابات افتراضية للهوية الإنتاجية غير البشرية، ورموز وصول شخصية للتطوير، والتحكم في الوصول المستند إلى الدور (RBAC) محدد النطاق لكل حساب مزود، وقواعد تحديد المعدل والميزانية معبر عنها بصيغة YAML بنطاقات لكل مستخدم/لكل فريق/لكل نموذج/لكل بيانات وصفية، وحواجز حماية السياسة ككود (Cedar و OPA) عند حدود أداة MCP.
نظرًا لأن البوابة موجودة بالفعل على كل طلب وتصدر تتبعًا كاملاً لكل استدعاء، فهي أيضًا المكان الذي يصبح فيه التدقيق المتوافق مع المعايير عمليًا. الهوية، قرارات السياسة، نتائج حواجز الحماية، اختيار النموذج، عدد الرموز، والتكلفة كلها تقع على نفس معرف التتبع — مرئية في تتبعات الطلبات في واجهة المستخدم، قابلة للتصدير عبر OpenTelemetry، ويمكن الوصول إليها بواسطة واجهة برمجة التطبيقات لتكامل SIEM. تضيف نفس البوابة التخزين المؤقت الدقيق والدلالي، وآليات التراجع وإعادة المحاولة، ولوحات معلومات المراقبة، ويتم نشرها كخدمة (SaaS) أو في شبكتك الافتراضية الخاصة (VPC)، أو في الموقع، أو في بيئة معزولة، مع الامتثال لمعايير SOC 2 و HIPAA و ITAR، ومعترف بها في دليل السوق لبوابات الذكاء الاصطناعي من Gartner. انظر الـ التحكم في الوصول، تحديد المعدل، و ضوابط الحماية ، أو نظرة عامة على بوابة الذكاء الاصطناعي للتعمق أكثر.
Northwind و Mei هما مثالان توضيحيان. أنماط الحوكمة — المفاتيح الافتراضية، التحكم في الوصول المستند إلى الأدوار (RBAC)، السياسة كتعليمات برمجية، تسجيل التدقيق، توجيه الإقامة — هي ممارسات قياسية لطبقة التحكم تُطبق على حركة مرور نماذج اللغة الكبيرة (LLM). تم تلخيص تواريخ والتزامات قانون الذكاء الاصطناعي للاتحاد الأوروبي من الجدول الزمني والتقارير المنشورة للمفوضية الأوروبية اعتبارًا من مايو 2026 وهي عرضة للتعديل المستمر (لا سيما اقتراح قانون الحافلة الرقمية في الحوار الثلاثي)؛ هذا المنشور هو إرشادات هندسية، وليس استشارة قانونية، وتساعد ضوابط البوابة الموصوفة في تلبية التزامات محددة بدلاً من أن تشكل امتثالًا كاملاً. يرجى تأكيد المتطلبات الحالية مقابل اللائحة والمستشار القانوني المؤهل لحالة الاستخدام الخاصة بك.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
