











Créez, déployez et échelle GenAI en production


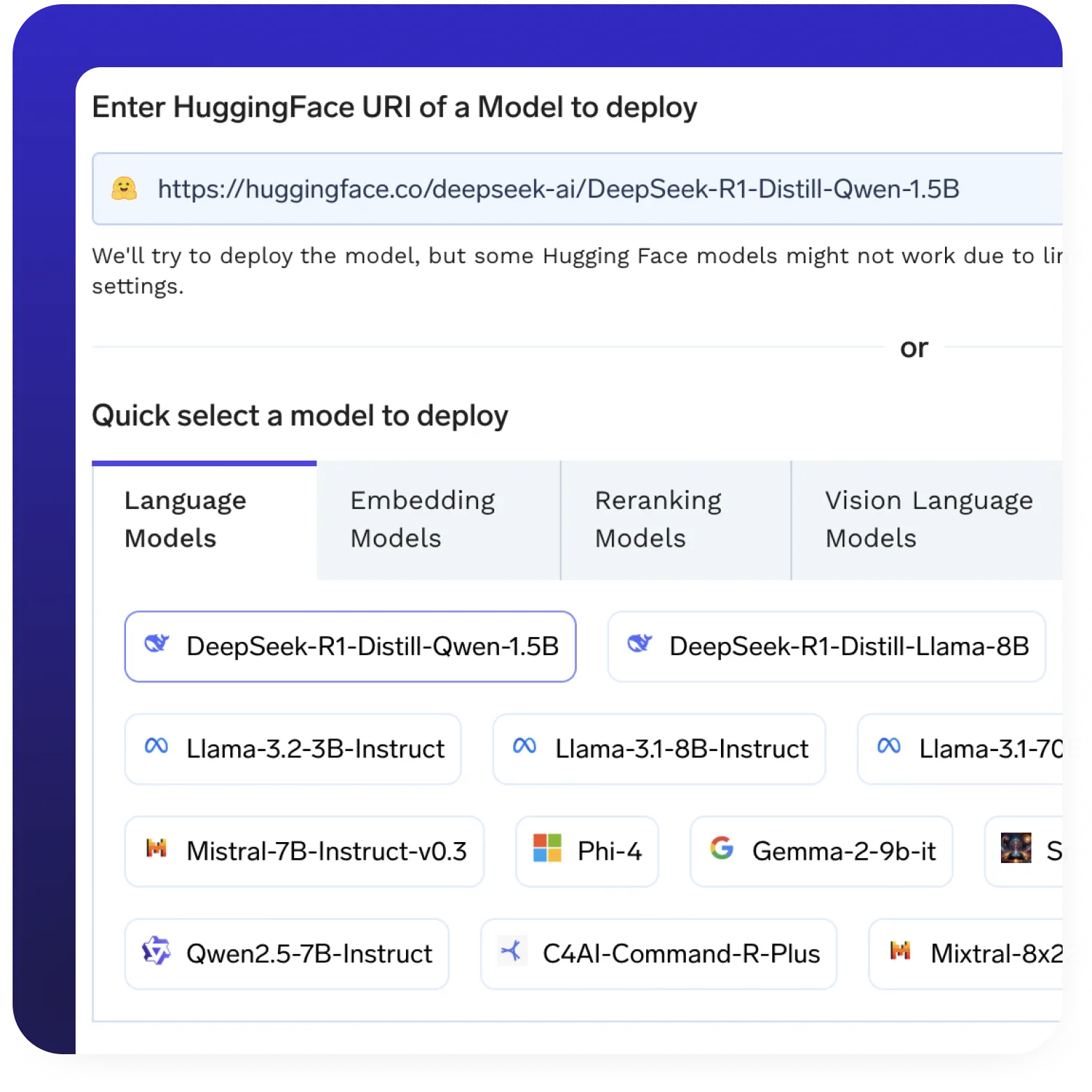
Service de modèles et inférence
- Sans effort déployer n'importe quel LLM open source avec des optimisations préconfigurées.
- Connectez-vous facilement à Hugging Face ou à votre liste de modèles préférée.
- Tirez parti de modèles de serveurs haut de gamme tels que VLLm et SGlang pour une inférence de haute performance.
- Mise à l'échelle automatique et provisionnement intelligent de l'infrastructure
Essayez-le dès maintenant
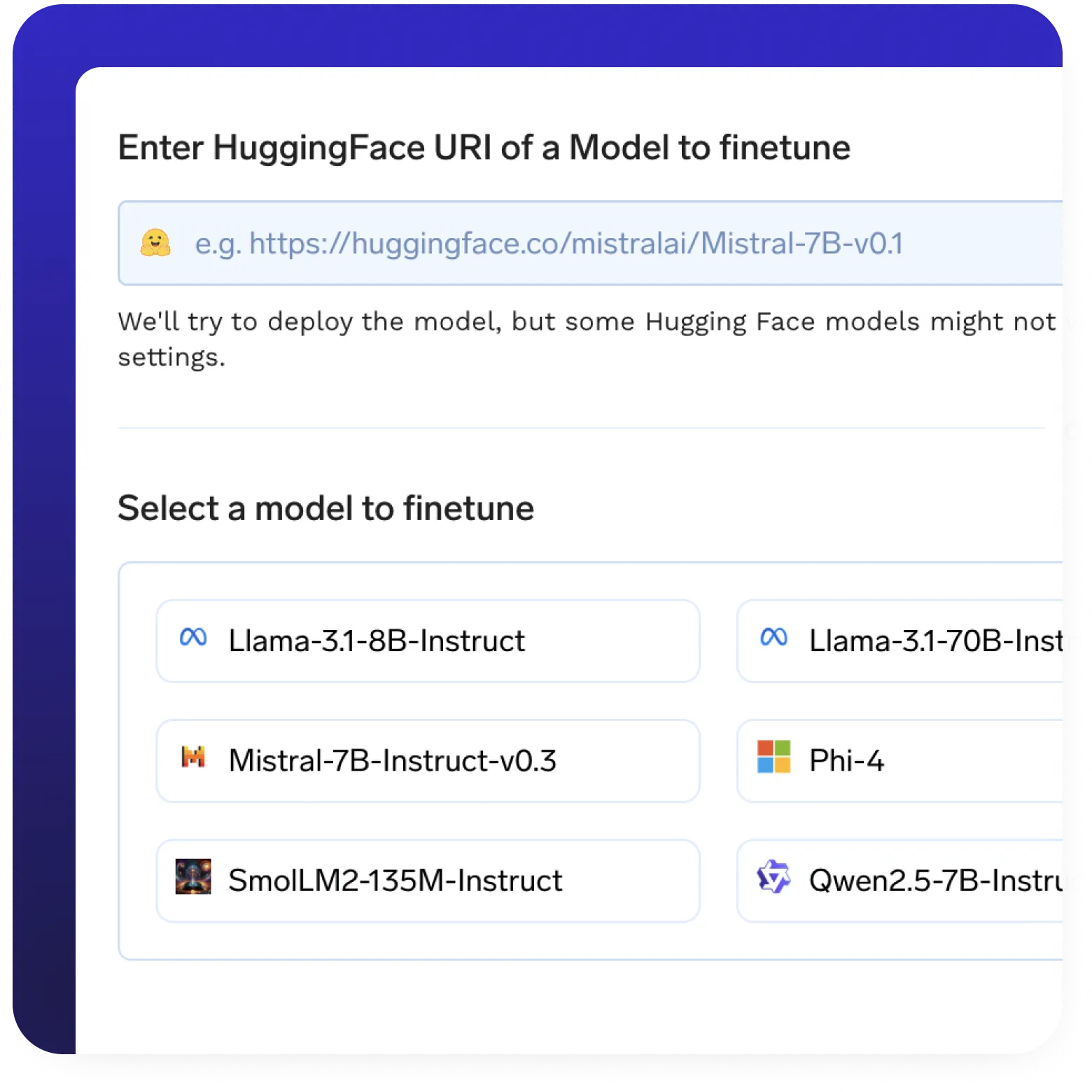
Modèle Finetuning
- Prise en charge de l'ajustement sans code et en code complet sur les ensembles de données personnalisés.
- LoRa et QLoRa pour une adaptation efficace à un rang inférieur.
- Pointage de contrôle soutien pour une reprise sans faille de l'entraînement.
- Déploiement en un clic de modèles affinés avec les meilleurs modèles de serveurs de leur catégorie.
- Canalisations de formation automatisées avec intégration suivi des expériences.
- Support de formation distribué pour une optimisation plus rapide et à grande échelle des modèles.
Essayez-le dès maintenant
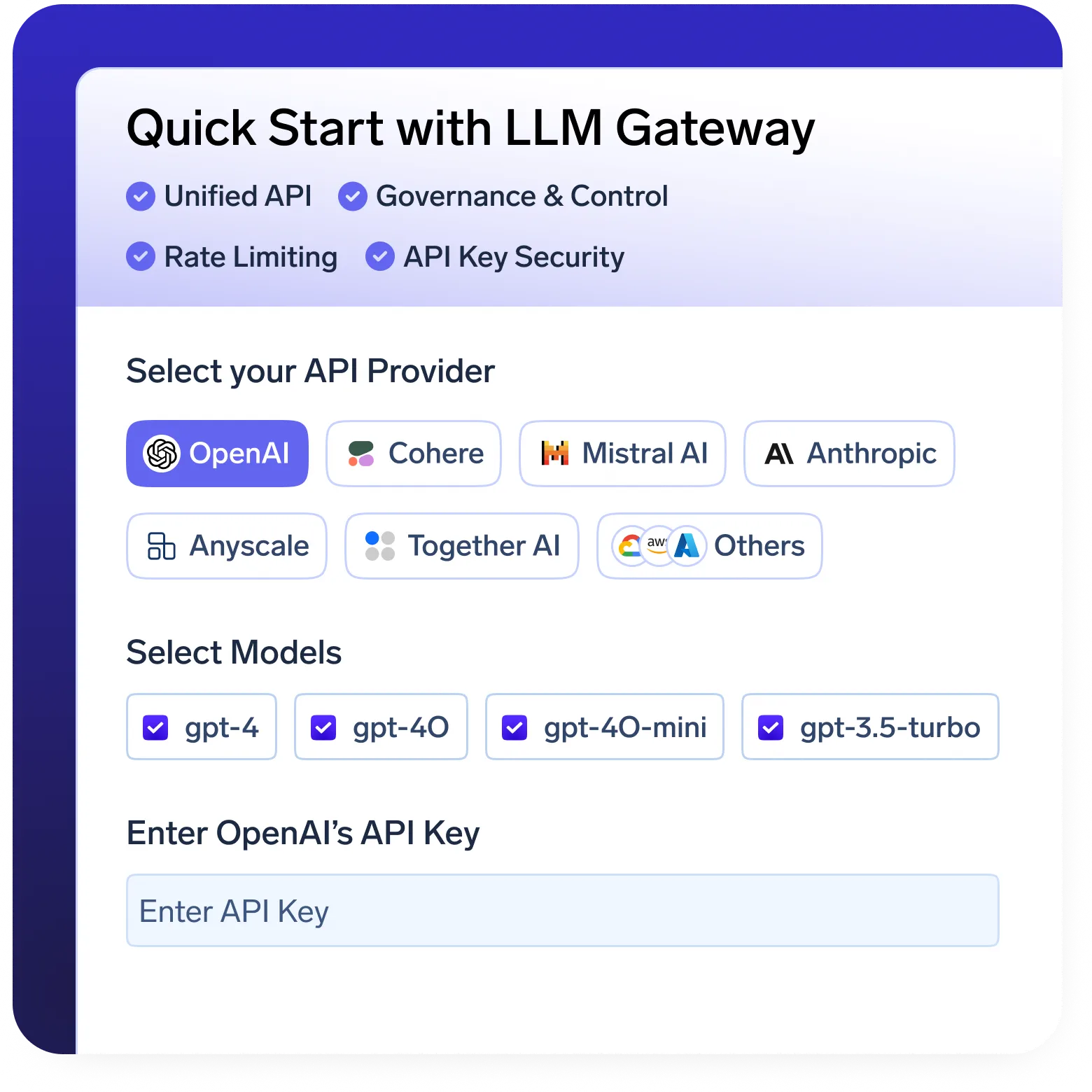
Passerelle IA
- Couche API unifiée pour servir et gérer des modèles sur OpenAI, Llama, Gemini, etc.
- Limitation de débit et contrôle d'accès intégrés pour gérer l'utilisation en toute sécurité.
- Mesures d'utilisation et de coûts en temps réel pour un meilleur suivi et une meilleure optimisation.
- Solution de repli et nouvelles tentatives automatiques pour garantir une disponibilité et une fiabilité élevées.
Essayez-le dès maintenant
Gestion rapide
- Expérimentez et répétez sur les instructions à l'aide d'un cadre de test structuré
- Ingénierie rapide contrôlée par version
Essayez-le dès maintenant


Traçage et garde-corps
- Capturez et analysez chaque invite, chaque réponse et chaque utilisation de jeton pour garantir la transparence et la traçabilité.
- Enregistrez la latence, les taux d'achèvement et les appels d'API pour optimiser les performances du modèle.
- Intégrez des barrières personnalisées ou des outils externes pour la détection des informations personnelles, la modération du contenu, etc.
Essayez-le dès maintenant
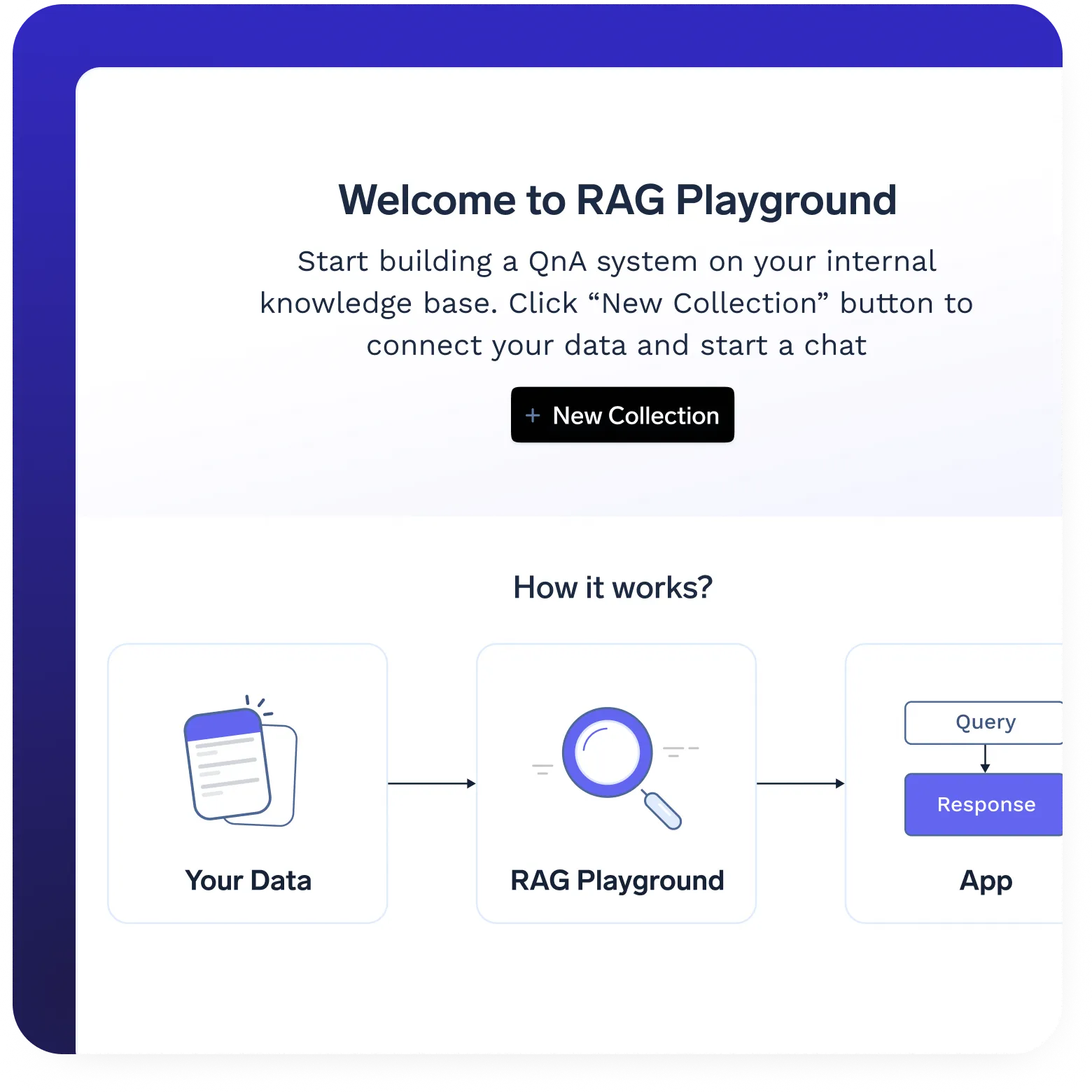
Déploiement de RAG en un clic
- Déploie tous les composants RAG en un seul clic, y compris VectorDB, les modèles d'intégration, le frontend et le backend.
- Infrastructure configurable pour optimiser le stockage, la récupération et le traitement des requêtes.
- Architecture évolutive pour prendre en charge des bases de connaissances dynamiques et en pleine croissance.
Essayez-le dès maintenant

Déployez n'importe quel framework d'agents
- Déployez et gérez des agents d'IA dans plusieurs frameworks, notamment LangChain, AutoGen, CrewAI et des agents personnalisés.
- Déploiement indépendant du framework, garantissant la compatibilité avec toute architecture basée sur des agents.
- Prise en charge de la collaboration multi-agents, permettant aux agents d'interagir, de partager le contexte et d'exécuter des tâches de manière autonome.
Essayez-le dès maintenant
Prêt pour les entreprises
Vos données et modèles sont hébergés en toute sécurité dans votre infrastructure cloud ou sur site.

Systèmes entièrement modulaires
S'intègre à votre stack existant et le complèteConformité véritable
Normes SOC 2, HIPAA et GDPR pour garantir une protection robuste des donnéesSécurisé dès la conception
Contrôle d'accès et pistes d'audit flexibles basés sur les rôlesAuthentification conforme aux normes du secteur
Intégration SSO via OIDC ou SAML
Soutenu par des investisseurs de renommée mondiale

.webp)
.webp)


Témoignages TrueFoundry rend votre équipe ML 10 fois plus rapide
.webp)
Deepanshi S.
Scientifique des données en chef
TrueFoundry simplifie le déploiement de modèles de machine learning complexes grâce à une interface utilisateur conviviale, libérant ainsi les data scientists des problèmes d'infrastructure. Il améliore l'efficacité, optimise les coûts et résout sans effort les défis DevOps, ce qui s'avère inestimable pour nous.



Matthieu Perrinel
Responsable du ML
Les économies de coûts informatiques que nous avons réalisées grâce à l'adoption de TrueFoundry étaient supérieures au coût du service (sans compter le temps et les maux de tête que cela nous permet d'économiser).


Soma Dhavala
Directeur de l'apprentissage automatique
TrueFoundry nous a permis de réduire de 40 à 50 % les coûts liés au cloud. La plupart des entreprises vous fournissent un outil et vous quittent, mais TrueFoundry nous a apporté un excellent soutien chaque fois que nous en avions besoin.


Rajesh Chaganti
CTO
Grâce à la plateforme TrueFoundry, nous avons pu réduire considérablement nos coûts liés au cloud. Nous avons pu passer facilement d'un système basé sur AMI à une architecture basée sur Docker-Kubernetes en quelques semaines.


Summit Rao
Vice-président de la science des données
TrueFoundry a joué un rôle central dans nos cas d'utilisation de l'apprentissage automatique. Ils ont aidé notre équipe à tirer parti plus rapidement de l'apprentissage automatique.


Vivek Suyambu
Ingénieur logiciel senior
TrueFoundry facilite le déploiement et le réglage de LLM open source. Sa plateforme intuitive, enrichie d'un tableau de bord riche en fonctionnalités pour la gestion des modèles, est complétée par une équipe d'assistance qui fait un effort supplémentaire.

9,9
Qualité du support


GenAI infra- simple, plus rapide et moins cher
Plus de 30 entreprises et sociétés du Fortune 500 nous font confiance








