Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
Solving SEO Data Bottlenecks with Autonomous Agents and TrueFoundry
Published: April 1, 2026
Built for Speed: ~10ms Latency, Even Under Load
Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed
It’s Monday morning. Your SEO lead is staring at three different browser tabs: Google Search Console (GSC), Looker Studio, and a spreadsheet that crashes if you scroll too fast. They are manually exporting thousands of rows of query data, attempting to VLOOKUP against last week's performance, and applying subjective filters to decide what the engineering team should build content for next.
This is the "Last Mile" problem of data analytics. We have sophisticated collection tools, but the actual synthesis—the decision-making layer—relies on fragile human glue.
At TrueFoundry, we realized our growth engineering workflow was blocked by this manual aggregation. We weren't limited by data; we were limited by the throughput of human analysis. To fix this, we didn't buy another dashboard tool. We built the Keyword Automation Agent, a system that treats SEO metrics as an engineering stream rather than a static report, powered by the TrueFoundry AI Gateway and the Model Context Protocol (MCP).
The Technical Shift: From Static Analysis to Adaptive Pipelines
The standard approach to SEO operations is Polling-based and Manual: humans periodically fetch data, apply hard-coded rules (e.g., "volume > 100"), and guess at relevance.
We shifted to an Event-Driven and Probabilistic model:
Deterministic Scoring: Math handles the obvious metrics (CTR deltas, rank distance).
Probabilistic Filtering: LLMs inject business context (e.g., knowing that "AI Gateway" is relevant to us, but "Gateway Computer Drivers" is not).
Tool Abstraction (MCP): External data sources (Ahrefs, Google Trends) are accessed via standardized protocols, not fragile API wrappers.
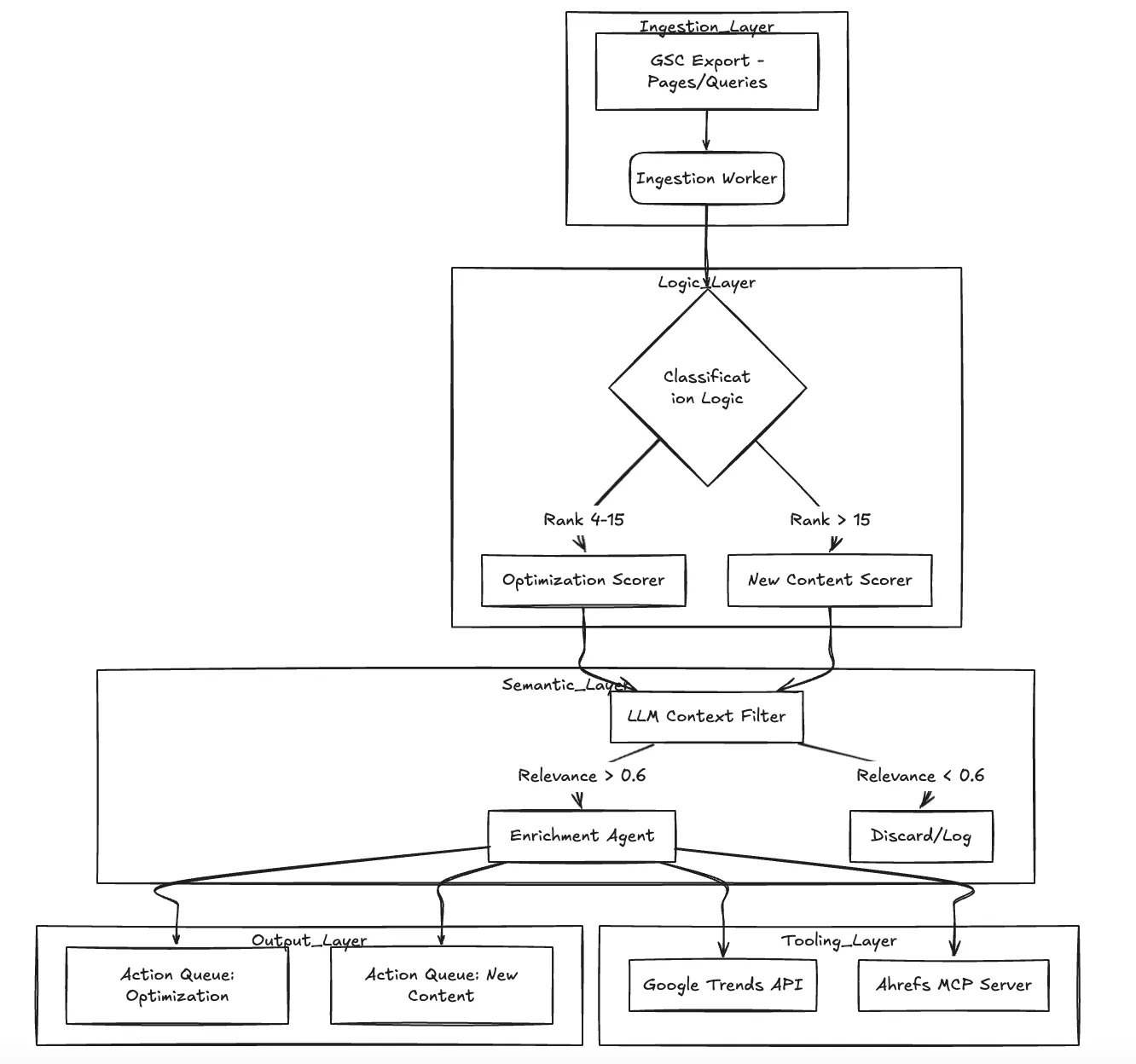
Architecture Deep Dive
The system operates as a directed acyclic graph (DAG) of processing steps. It does not just "summarize" data; it actively filters and enriches it.
Core Components:
Ingestion Worker: Parses raw CSV exports from GSC (Pages and Queries).
Scoring Controller: Applies the mathematical logic. For optimization, we use a distance-based decay function: $Score = \log(1 + impressions) \times (1 - CTR) \times (\max(0, 20 - position))$.
Relevance Agent (LLM): Acts as the semantic gatekeeper. It evaluates keywords against TrueFoundry's domain context (Kubernetes, LLM Ops, Developer Platforms) to filter out noise.
Enrichment Worker: Fetches trend data and (in V2) external difficulty metrics via MCP.
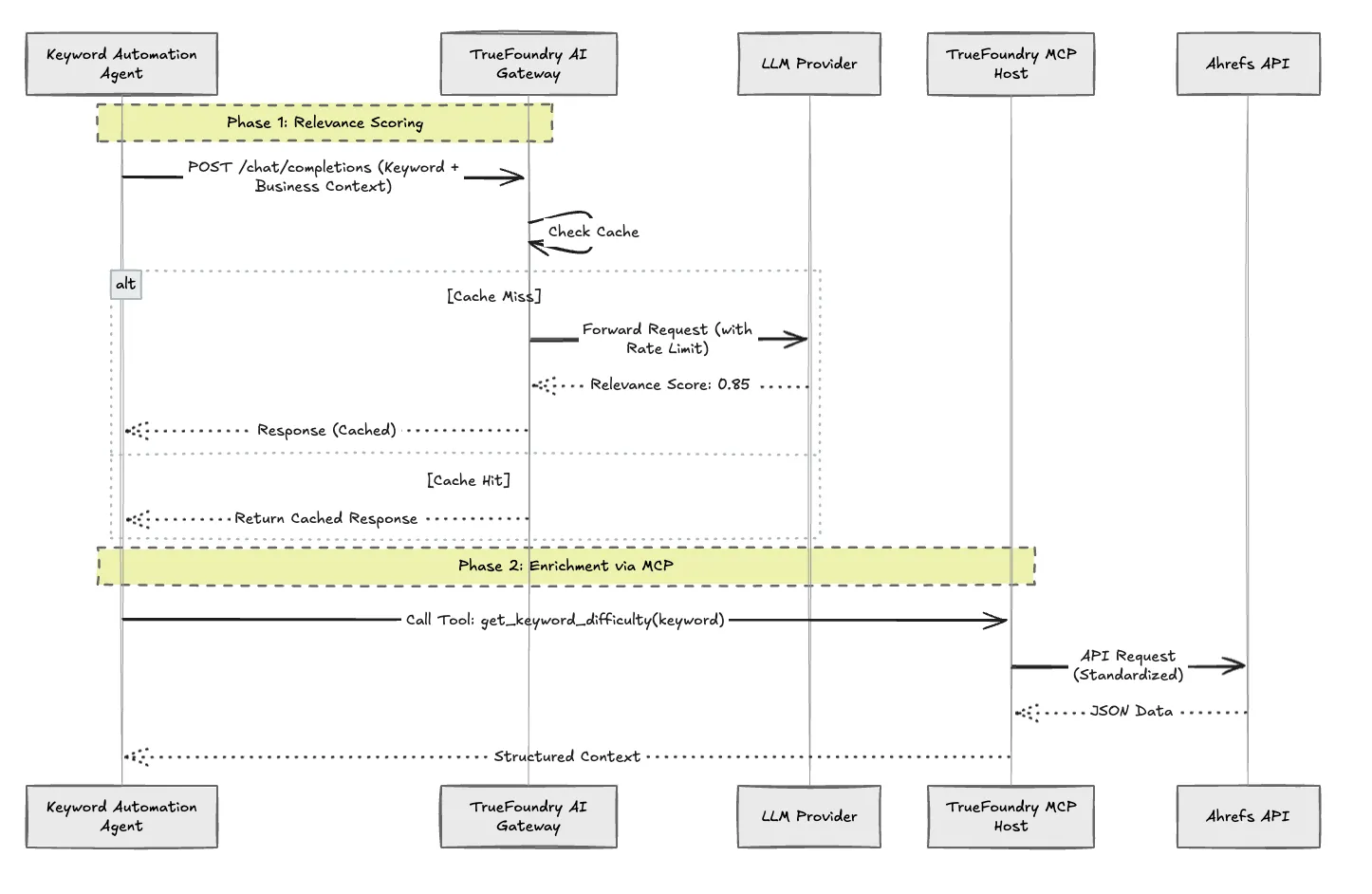
Infrastructure & TrueFoundry: Gateway and MCP
Implementing this architecture introduces two major distributed system challenges: Rate Limiting and Tool Integration.
If you simply loop through 5,000 keywords and hit an LLM API for relevance scoring, you will hit rate limits immediately. If you hardcode Ahrefs API calls into your agent, you create tight coupling that breaks whenever an API version changes.
We utilized the TrueFoundry Platform to solve both:
TrueFoundry AI Gateway: We route all LLM calls (for relevance scoring and brief generation) through the Gateway. This provides:
Centralized Rate Limiting: We set a budget of requests per minute at the gateway level, protecting our downstream providers.
Caching: If we have already scored the keyword "LLM Observability" last week, the Gateway serves the cached verdict, reducing latency and cost to zero.
Model Routing: We can swap the underlying model (e.g., from GPT-4 to a cheaper, faster model like Gemini Flash) for the classification task without changing a line of application code.
Model Context Protocol (MCP): Instead of writing custom functions for Ahrefs, we deploy an Ahrefs MCP Server on TrueFoundry. The Agent simply queries the MCP server for site-explorer-metrics or keyword-difficulty. The MCP server handles the authentication and API specifics. This standardizes how our agents talk to external tools.
Code snippet
Comparison: Standard Scripting vs. TrueFoundry Accelerator
The following table highlights why we moved away from local Python scripts to a managed architecture.
Dimension
Standard Python Script Approach
TrueFoundry Accelerator Approach
Resilience
Fragile. If the GSC API times out or the script hits an LLM rate limit, the entire process crashes. Requires manual restarts.
High. TrueFoundry Gateway handles retries and exponential backoff. Process isolation ensures one failed batch doesn't kill the pipeline.
Security
Low. API keys for OpenAI and Ahrefs are often stored in local .env files or hardcoded.
Enterprise. Keys are managed in TrueFoundry Secrets. Agents access tools via authenticated MCP endpoints, never touching raw credentials.
Scalability
Vertical. Limited by the local machine's memory when processing large CSVs combined with trend data.
Horizontal. Workers run as microservices on Kubernetes. We can parallelize the scoring of 10,000 keywords across multiple pods.
Maintenance
High. Every time Ahrefs changes an API endpoint, the main application code must be refactored.
Low. Tool logic is isolated in the MCP Server. The core agent logic remains untouched during external API updates.
Handling Edge Cases & Reliability
In a production environment, data is rarely clean. We implemented specific guardrails to ensure reliability:
The "Hallucination" Gate: LLMs can be overconfident. We implemented a logic gate where if relevance = false AND confidence < 0.6, the keyword is dropped as noise. However, if relevance = true but confidence < 0.5, it is flagged for human review rather than automatic processing.
Trend Divergence: A common failure mode in SEO is optimizing for a dying keyword. Our Enrichment Worker checks Google Trends. If Impression_Trend is flat but Market_Trend is rising, it flags a "Missed Opportunity." If Impression_Trend is rising but Market_Trend is zero, it flags a likely bot anomaly or seasonal spike, preventing wasted effort.
Conclusion
By moving the SEO workflow from manual spreadsheets to an agentic workflow on TrueFoundry, we reduced the time-to-insight from days to minutes. More importantly, we decoupled the logic from the infrastructure. The TrueFoundry AI Gateway manages the "cost of cognition" (LLM calls), while MCP manages the "complexity of integration" (external tools).
This architecture proves that internal tools don't have to be hacky scripts. They can be resilient, scalable systems that drive actual business value.
Deploy this Accelerator from the TrueFoundry Library today to standardize your own data enrichment workflows.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.






























.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




