














July 11, 2026
|
5 min read

Published: May 27, 2026

Blazingly fast way to build, track and deploy your models!
Every major LLM provider implements prompt caching differently. Here's how the TrueFoundry AI Gateway translates cache directives across providers, handles fallback when a target doesn't support caching, and exposes unified hit metrics — with token savings benchmarks.

Prompt caching is the single highest-leverage cost optimization for any LLM workload built on a long, stable prefix — a 10K-token system prompt, a tool registry, a retrieval bundle. The discount is roughly 90% off cached input tokens, large enough to change the unit economics of an agent product.
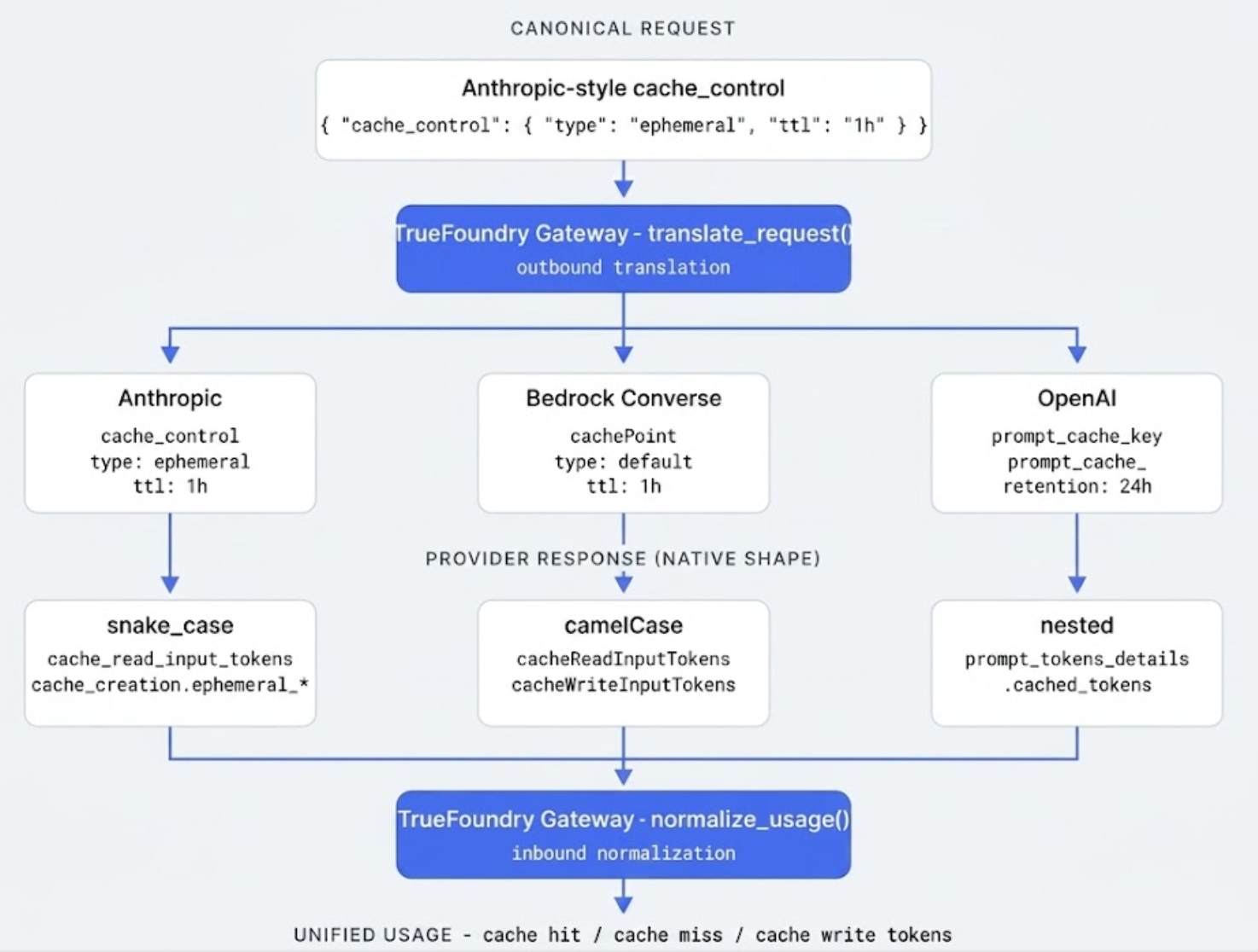
The catch is that the three major LLM provider APIs — Anthropic native, OpenAI, AWS Bedrock Converse — each model caching differently in ways that aren't cosmetic: directive shape, response shape, TTL options, and even when caching is invoked at all.
Anthropic's prompt caching is the most expressive of the three. You explicitly mark which portion of the request should be cached using the cache_control attribute on a system or message block:
anthropic request · json
{
"model": "claude-sonnet-4-6",
"system": [{
"type": "text",
"text": "<10,000 token system prompt>",
"cache_control": {"type": "ephemeral"}
}],
"messages": [{"role": "user", "content": "<query>"}]
}Three rules govern when this actually caches. The prefix must clear a model-specific minimum: 1,024 tokens for Sonnet-class and 2,048 tokens for Opus-class. Below the threshold the directive is silently dropped. The default TTL is 5 minutes, refreshed on each hit. And the prefix must be byte-identical — a stray timestamp before the cached block kills the hit (we return to this in §08).
Pricing has two non-obvious components. Cache reads are billed at 10% of the base input rate — the 90% discount you came for. Cache writes carry a 25% premium over base input pricing. The cache must pay for itself across enough subsequent hits to recover the write surcharge; for a 10K-token prefix on Sonnet 4.6, breakeven is two follow-up hits.
The response surfaces caching in three usage fields: cache_read_input_tokens (served from cache), cache_creation_input_tokens (written this turn), and input_tokens (everything else). Since extended-TTL caching now lets you opt into a 1-hour retention at a 2× write premium, Anthropic also surfaces a per-TTL breakdown under cache_creation.ephemeral_5m_input_tokens and cache_creation.ephemeral_1h_input_tokens. That breakdown matters more than it looks — we'll come back to it in §04.
OpenAI's prompt caching takes the opposite philosophy. There is no directive. The cache turns on automatically once the prompt prefix exceeds 1,024 tokens, and OpenAI's infrastructure caches the KV activations server-side. Subsequent requests with the same prefix get the cached state automatically.
The developer-facing surface is two optional parameters that influence — but don't trigger — caching. prompt_cache_key is a string combined with the prefix hash to influence backend routing: same key, same backend, higher hit rate. prompt_cache_retention accepts "in_memory" (default, 5–10 minutes) or "24h" for extended retention. Both are documented in OpenAI's prompt caching guide.
The asymmetry with Anthropic is sharp: you cannot choose which prefix is cached. OpenAI's caching layer picks the longest repeated prefix it observes on a given backend. If your system prompt is followed by a frequently-changing tool registry, the cache may land on the system prompt alone or on a different boundary, with no visibility into which. The response surfaces only one cache field — cached_tokens nested under usage.prompt_tokens_details — and no write-side counter, because OpenAI doesn't bill for cache writes.
The practical implication: OpenAI caching is well-suited to workloads where the stable prefix is one block. Anthropic's explicit breakpoints give you fine-grained control over multi-region prefixes; OpenAI doesn't.
Bedrock's prompt caching sits in the Converse API and uses a cachePoint marker block placed after the content it caches:
bedrock converse · json
{
"modelId": "anthropic.claude-sonnet-4-6-v1:0",
"system": [
{"text": "<long system prompt>"},
{"cachePoint": {"type": "default", "ttl": "1h"}}
],
"messages": [/* ... */]
}Three things make this trickier than it looks. First, the marker placement is the opposite of Anthropic's — the directive comes after the content it caches, not on it. Implementations that lift Anthropic's pattern directly silently disable caching. Second, this is the Converse API specifically; Bedrock's native InvokeModel endpoint accepts the Anthropic-style format verbatim for Claude models, but Converse is the path most newer integrations use.
Third, TTL support shifted recently. Before January 26, 2026, Bedrock Converse only supported a 5-minute TTL. On that date AWS shipped 1-hour TTL support for the Claude 4.5+ family and Amazon Nova; the new ttl: "1h" field on the cachePoint opts in. Older models reject the field — no graceful downgrade.
The response uses camelCase: cacheReadInputTokens, cacheWriteInputTokens, and inputTokens. Unlike Anthropic, Bedrock Converse does not expose a per-TTL breakdown on writes. The gateway that translated the request knows which TTL was requested; the response alone doesn't tell you.
The translation problem the gateway has to solve is: a client sends a single canonical request with Anthropic-style cache_control, and the gateway routes to whichever provider the policy selects. Three strategies are possible — strip the directive when the target doesn't understand it, translate to the target's native cache primitive, or error and refuse to route.
TrueFoundry's gateway picks translate-where-possible, strip-and-log otherwise. Anthropic and Bedrock Converse get full translation — cache_control with a TTL becomes a cachePoint with the equivalent ttl field. OpenAI gets a translated intent: the directive itself is dropped, but prompt_cache_retention is set to "24h" for a 1-hour canonical TTL, and prompt_cache_key is forwarded from the canonical cache_key. When a downgrade is forced — a 1-hour TTL routed to a model that doesn't support extended TTL — the gateway emits a warning span attribute (gen_ai.tfy.cache_ttl_downgrade=5m) so the regression is observable.
One subtler trap on the response side is the mixed-TTL cost accounting bug.
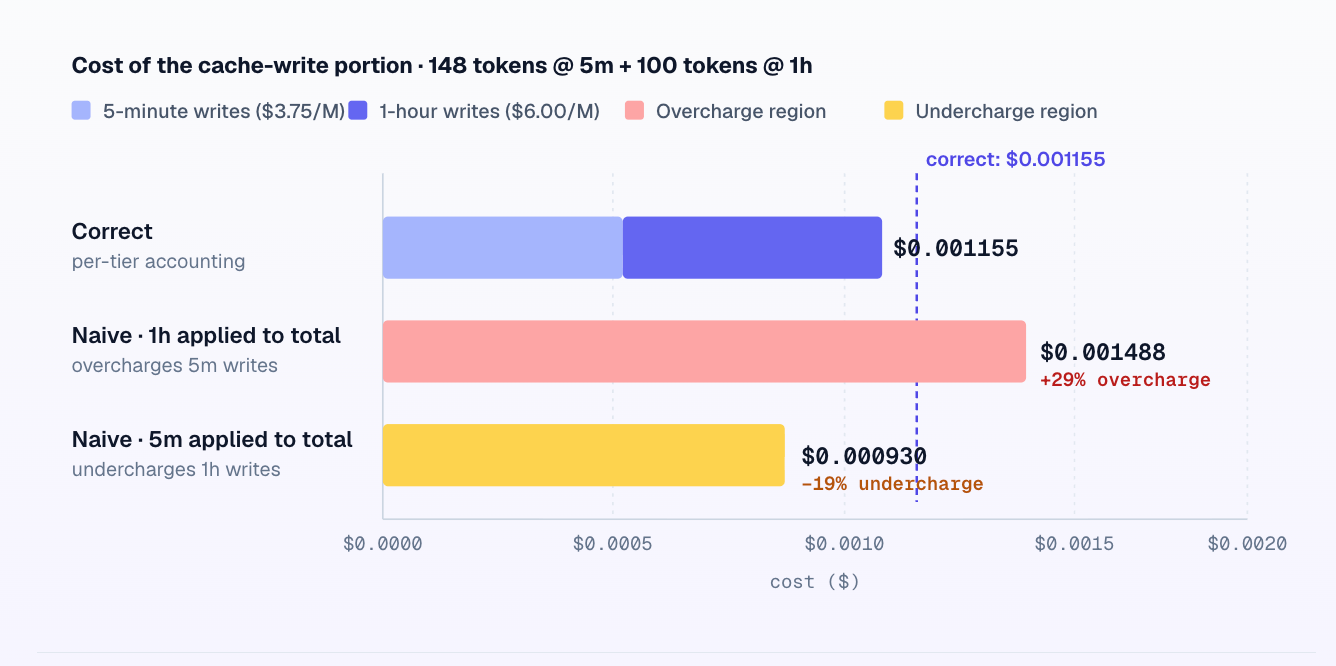
The unified usage object the gateway exposes downstream therefore has five token fields, not four: cache_hit_tokens, cache_miss_tokens, cache_write_5m_tokens, cache_write_1h_tokens, and .
The interesting failure mode for any multi-provider gateway is what happens when the primary target is rate-limited or down and the request falls back to a secondary. For caching, caches don't follow traffic across providers. A request whose 10K-token system prompt has been hot in Anthropic's cache for the last fifteen minutes will, on fallback to Azure OpenAI, hit a completely cold prefix cache. The fallback succeeds — but it pays full input-token cost on the prefix, and the trace correctly reports a cache miss.
For a 10K-token prefix on Sonnet 4.6, that's the difference between $0.003 (cached read) and $0.030 (full input) per request — a 10× cost spike during the failover window. Even after the secondary warms up, the warm-up isn't free: every fresh request on a cold target pays the write premium.
The mitigation has two parts. Keep the secondary warm — send 1% of traffic to the fallback provider continuously, not just during incidents. Monitor fallback cache hit rate separately. A useful alert isn't "fallback rate exceeded 5%"; it's "fallback rate exceeded 5% AND fallback cache hit rate below 50%." The first is a routing event; the second is a routing event with a measurable cost penalty attached.
The payoff of the normalization layer is that every trace span carries the same cache attributes regardless of which provider served the request:
otel span attributes · gateway-emitted
gen_ai.provider.name = anthropic
gen_ai.request.model = claude-sonnet-4-6
gen_ai.usage.cache_hit_tokens = 9800
gen_ai.usage.cache_miss_tokens = 248
gen_ai.usage.cache_write_tokens = 0
gen_ai.usage.output_tokens = 503
gen_ai.cache.hit_rate = 0.975
gen_ai.cache.ttl_tier = 1h
gen_ai.tfy.virtual_account = tenant-123Any dashboard query, cost-attribution job, or router-tuning analysis can read these fields without branching on provider. The cache hit rate computed from them is comparable across Anthropic, OpenAI, and Bedrock traffic, which means one dashboard panel can answer "which provider is giving us the best cache economics on this workload" without three different SQL templates.
Two caveats. The cache-specific attributes follow OTel's gen_ai.* namespace pattern but aren't (yet) part of the official semantic conventions spec. And hit_rate is an operationally useful summary, not a precise efficiency metric; for forensic cost reconciliation, read the underlying token fields directly.
The workload most agent applications actually run: a stable 10,000-token system prompt, a 200-token user query that changes per request, a 500-token model response, and 1,000 requests across a session window. Assume a realistic 95% cache hit rate — 950 hits, 50 misses from TTL expirations during idle gaps. All numbers in $USD against May-2026 list pricing.
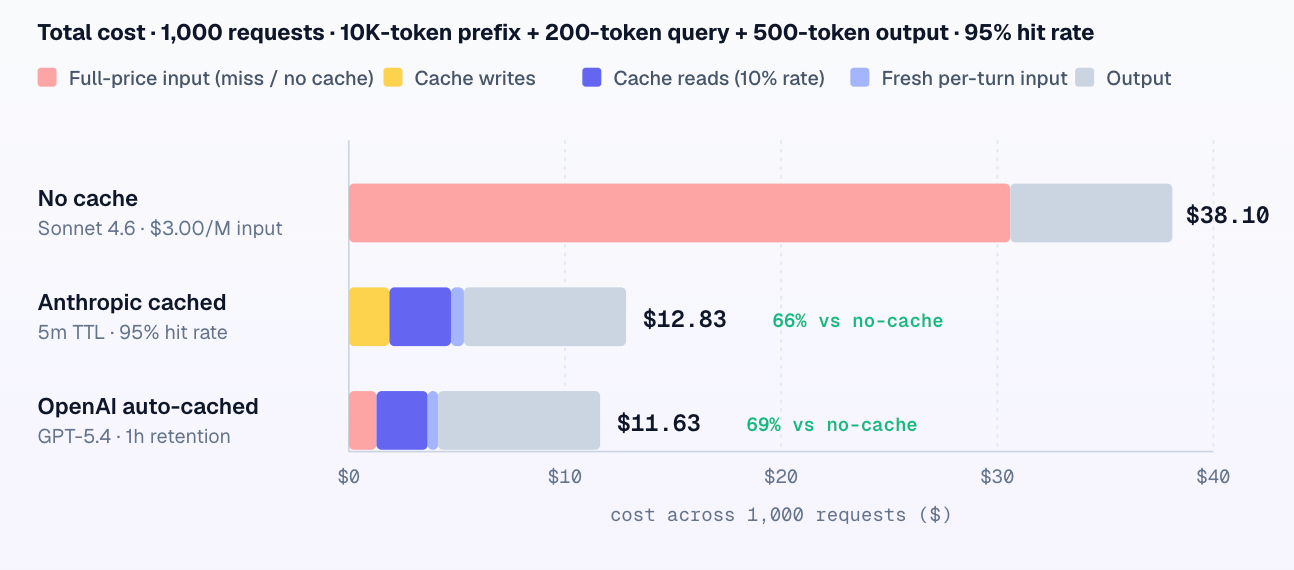
Two things stand out. Both providers deliver large, roughly comparable savings — the gap between them is small relative to the gap from no-caching. And with caching enabled, output tokens become the dominant cost line (~58% of the Anthropic total, ~65% of the OpenAI total). That changes which optimizations matter next: once caching is on, the next dollar comes from output-length control, not from a deeper input optimization.
The cache key is exact-match on bytes, before any of the cleverness above kicks in. A handful of common patterns silently destroy hit rates, and they all share the same shape: something volatile gets concatenated before or inside the supposedly stable prefix.
The gateway can detect most of these passively by watching cache hit rate per virtual account. A 10K-token system prompt consistently running below a 40% hit rate is almost always a content-volatility problem, and the trace timeline usually shows which segment is changing. The TrueFoundry dashboard surfaces this as a "low cache hit rate" alert with prefix-diff context, so the fix is usually a five-minute prompt edit.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)





.webp)
.webp)
.webp)


.png)


