













August 3, 2026
|
5 min read

Published: May 6, 2026

Blazingly fast way to build, track and deploy your models!
These terms are used interchangeably until something breaks. They describe distinct architectures with distinct guarantees, and the cost of conflating them is paid in security gaps, audit failures, and rebuilds you should not have had to do.
As Model Context Protocol becomes the default wire for connecting AI agents to data sources and tools, the infrastructure terminology has tangled. Vendors, blog posts, and internal design docs use “proxy,” “router,” and “gateway” interchangeably. The distinction is fuzzy when everything is on a developer's laptop and lethal when you start shipping production agents — because the three words name structurally different things, and the difference shows up only when an auditor asks a question one of them cannot answer.
Borrowing from networking gives the cleanest mental model. A proxy operates at L4 — it forwards bytes and does not interpret them. A router operates at L7 capability dispatch — it knows the tool, but does not know the principal calling it. A gateway operates at L7 policy — it knows the tool, the principal, the budget, and the audit trail. Each tier is strictly more capable, strictly more expensive to run, and answers strictly more questions about each request.
A proxy is the simplest piece in the diagram. Its job is protocol mediation. MCP makes heavy use of stdio for local execution; a proxy can wrap a stdio-based MCP server and expose it over HTTP/SSE or WebSockets so a remote client can reach it. That is the entire job.
A proxy does zero interpretation of the payload. It does not parse JSON-RPC, does not understand tool calls, does not know what “tool” means. It forwards bytes. That makes it sub-millisecond fast and almost free to operate. A single developer connecting Claude Desktop to an MCP server inside a Docker container on the same machine — that is a proxy use case. No governance, no state, no reason for either.
The mistake is thinking the proxy will scale. It will not. The moment you have more than one developer or more than one downstream MCP server, the proxy stops being load-bearing and the router takes over. A proxy is not a building block of an enterprise stack; it is a personal convenience tool that a gateway might wrap internally for transport adaptation. Treating it as either more or less than that — overbuilding it, underestimating it — produces architecture that ages badly.

As environments grow, hardcoding server URLs into clients stops being maintainable. A router solves discovery: instead of the client knowing where github-mcp-server lives, the client connects to the router and asks what tools are available. The router maintains a registry of downstream servers and a capability map.
When the LLM calls search_repositories, the router inspects the JSON-RPC payload, identifies the target tool, and dispatches the call to the correct backend. It is, mechanically, an aggregator with a routing table — fast, simple, and a clean abstraction. Most internal teams reach for one as soon as they have more than two MCP servers, and they are not wrong to.
What the router does not do is ask the question that matters most in production: is the identity making this call actually authorized to invoke this tool? It routes by capability. It does not gate by policy. The model can call delete_branch on prod just as easily as it can call list_issues on a public repo. The router will obediently dispatch both, and the audit log it does or does not produce is shaped only by the wire — not by who held the wire.
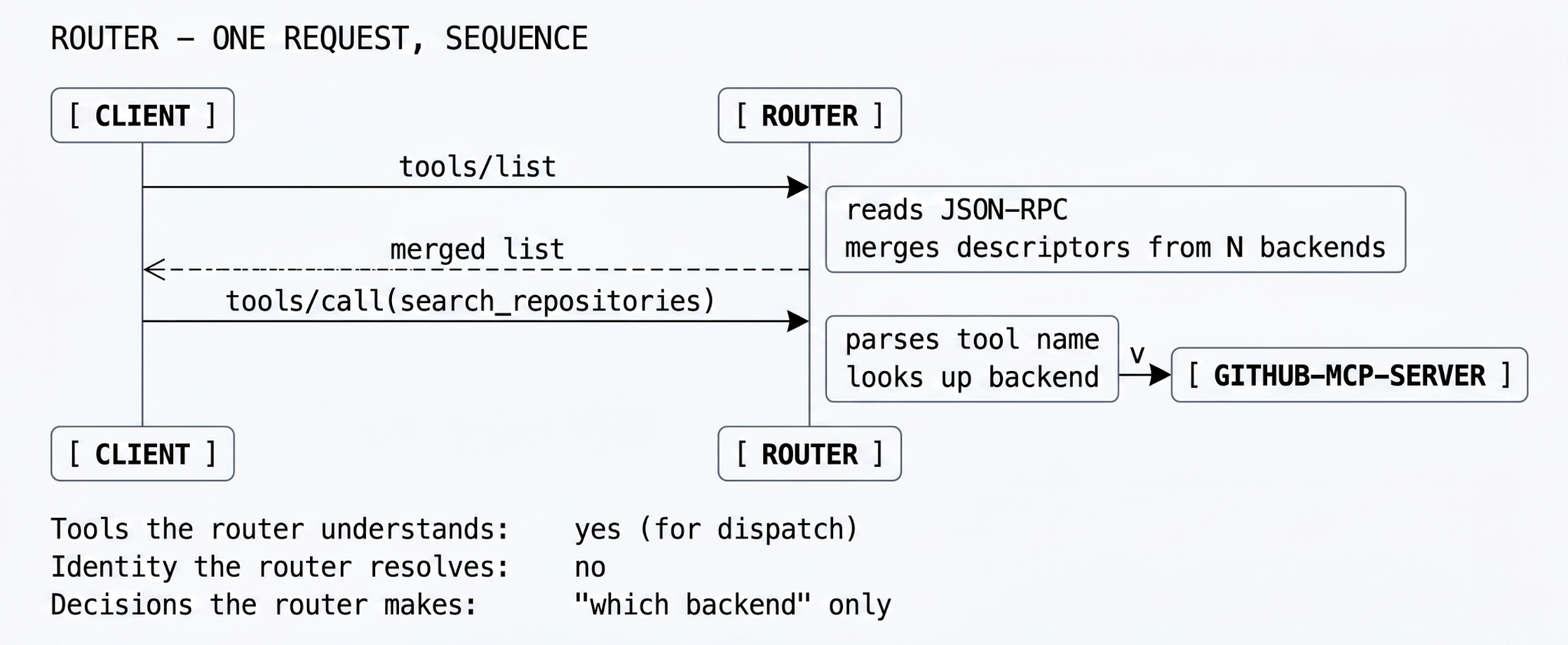
Router is the right tier when the agents are internal, the network is trusted, and the worst-case action is undoable. The transition that bites teams is router → gateway, and it usually happens the day someone asks who called delete_branch on prod last Tuesday. The router has no answer to give, because it never knew.
A gateway subsumes the proxy and the router and adds an L7 control plane on top. This is the layer where enterprise AI operations actually happen — and the layer where a security review will start, regardless of whether anyone called it that during design.
A gateway inspects every packet. It integrates with corporate identity (OAuth 2.0, SAML, OIDC) to establish who the agent is acting on behalf of. It enforces tool-level RBAC. It runs the schema sanitization that catches MCP poisoning. It tracks token usage for budget attribution. It writes tamper-evident logs to external SIEMs. It is, structurally, the place where the organization's AI policy is encoded — and the only place where an off-boarded contractor's agent stops working at the right moment.
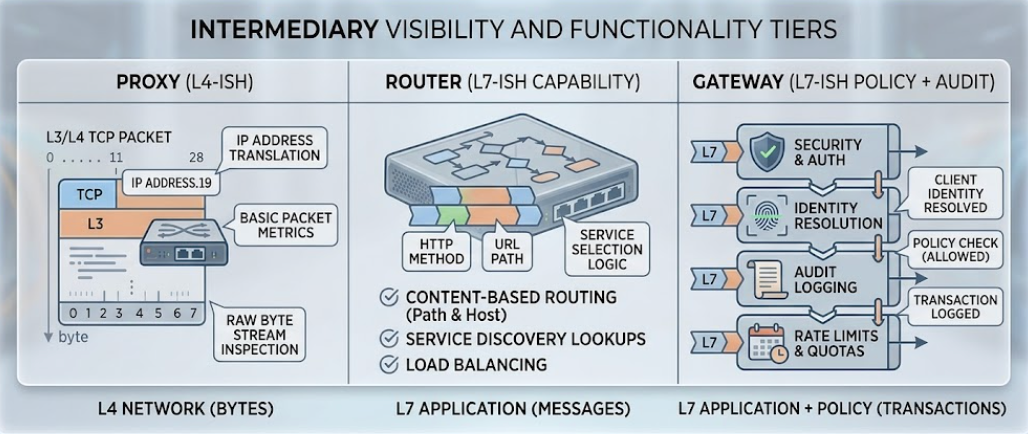
The same comparison in tabular form, for the design-doc reviewers who will skim. Read the columns; each one answers a question about a request.
Table 1 — Capability matrix. The right column is what your auditor will ask about; the middle column is what your team will reach for first; the left column is what runs on your laptop.
A short decision tree, written in the order in which production teams actually answer the questions:
The transition that bites most teams is router → gateway, and it always happens at the same moment: someone asks an audit question that requires identity-correlated logs, and the router has no answer because the router never knew who was calling. The cheap fix at that point is to add a gateway. The expensive fix is to rebuild the agent platform after a security incident — which is what some fraction of teams will end up doing instead, because the cheap fix is invisible until the incident.
TrueFoundry is built as a federated gateway. The control plane (where policies are authored, models are registered, and observability lives) is separated from the gateway plane (where traffic flows). The gateway plane is completely stateless — every gateway pod subscribes to the control plane via NATS for configuration updates, and every check it performs is in-memory against that synced state. There is no single point of failure between the agent and the backend. If the control plane goes down, gateways keep serving with their last-known configuration; when the control plane returns, NATS reconciles. As a final failsafe, the control plane re-publishes the entire configuration every 10 minutes — eventual consistency is guaranteed even if an intermediate update was missed.
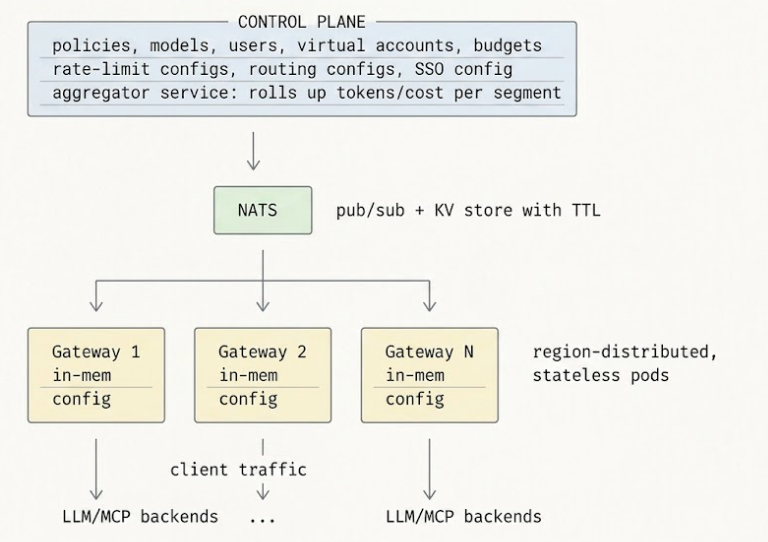
The data plane is built on Hono — a Web Fetch API-aligned framework optimized for the edge — and performs all rate-limit, auth, and routing checks in process memory. The control plane syncs configuration over NATS at sub-second cadence; the request path itself never makes an external call unless the cache or a network-based guardrail is invoked. The structural property that matters is statelessness: a gateway pod can be killed at any moment without losing in-flight policy decisions, because there are no in-flight policy decisions — every decision is made from local memory against config that arrived asynchronously.
The feature that ties the architecture together is virtual MCP server composition. The gateway merges schemas from dozens of backend MCP servers into a single API surface, dynamically scoped per caller. A frontend developer's IAM token produces a different unified tool list than a platform engineer's, and neither sees tools the other isn't allowed to use. From the model's perspective there is one MCP server. From the platform team's perspective there is one place to set policy. From the auditor's perspective every tool call has a trace ID that links the model decision to the developer identity that authorized it.
Same client, same backends, vastly different middle. The middle is the part that ages well.
Architecture is mostly the practice of choosing where boundaries go, and the cost of getting that choice wrong is paid not at design time but at the next incident, the next audit, the next migration. The proxy/router/gateway distinction is not a vocabulary problem. It is a question of whether your platform has a control point at the seam where corporate identity meets the agent loop, or whether it has a routing table where a control point should be.
Most teams discover this distinction the hard way. Some discover it during a postmortem; some during a compliance review; some when an off-boarded contractor's agent keeps working for a week longer than it should. The discovery moment is the same in all three cases. The cost of the discovery is what varies.
Yes, and most teams do. The migration path is clean: the gateway speaks the same MCP wire protocol, so existing clients keep working. What changes is the URL they point at and the auth header they include. Plan the migration around two phases — first stand the gateway up in audit mode (logging, no enforcement) and validate that the logs match expectations; then flip enforcement on per-server, starting with the lowest-risk MCP servers and ending with the production database.
Gateways continue serving traffic on whatever configuration they last fetched, indefinitely. They subscribe to NATS for live updates, and as a backup they retry HTTP-fetching the configuration from the control plane backend service. If both NATS and the backend are down, existing gateway pods keep running on last-known config; new pods that try to start during the outage will fail their readiness probe and not receive traffic. The recommendation is to run multiple gateway replicas — the chance of all of them restarting during a control-plane outage is the chance you have to engineer against, and it is small.
Hono is built on the Web Fetch API and is designed for edge runtimes (Cloudflare Workers, Deno, Bun, Node). It is small, fast, and runs identically across runtimes — which matters because the gateway has to be portable across SaaS, on-prem Kubernetes, and air-gapped Squid-proxied environments. Express has too much surface area; Fastify is fine but tied to Node specifics. The relevant property is consistent low overhead at high concurrency, which Hono delivers reliably.
It scopes per caller. The gateway evaluates the principal's IAM and ABAC attributes against the policy bundle every time it serves a tools/list, and emits a filtered union of tool descriptors. Two developers logging in seconds apart can receive different tool lists from the same gateway endpoint. The model never knows there are multiple backends, and it never knows there are tools its current caller cannot reach. This is also how you get clean multi-tenant deployments — the same gateway serves different tenants different worlds.
Three mechanisms. Configuration payloads are idempotent — the control plane publishes the entire current state to NATS on every change, so receiving the same message twice has no effect. NATS provides at-least-once delivery, so the gateway will see every update at least once. And as a belt-and-suspenders measure, the control plane re-publishes the full configuration every 10 minutes — even if an intermediate update was missed, the gateway converges to the correct state within 10 minutes at worst. Drift is bounded by design.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox








.webp)




.webp)



