














June 30, 2026
|
5 min read

Published: February 16, 2026

Blazingly fast way to build, track and deploy your models!
Deploying Generative AI on Google Cloud Platform (GCP) requires orchestrating a complex set of primitives: Google Kubernetes Engine (GKE), Cloud TPUs, and Vertex AI. While GCP provides the raw compute, wiring these into a compliant Internal Developer Platform (IDP) requires substantial custom engineering.
TrueFoundry acts as the infrastructure overlay. We handle the orchestration, leaving you with control over the VPC and data residency. This post details our integration patterns with GCP, specifically regarding the split-plane architecture, Workload Identity Federation, and TPU management.
We use a split-plane architecture to isolate the management interface from your workload execution environment.
Security Boundary We do not require inbound firewall rules. The Agent in your cluster initiates a secure, outbound-only WebSocket or gRPC stream to our Control Plane. It polls for deployment manifests and pushes telemetry. Your VPC remains private to external ingress traffic.
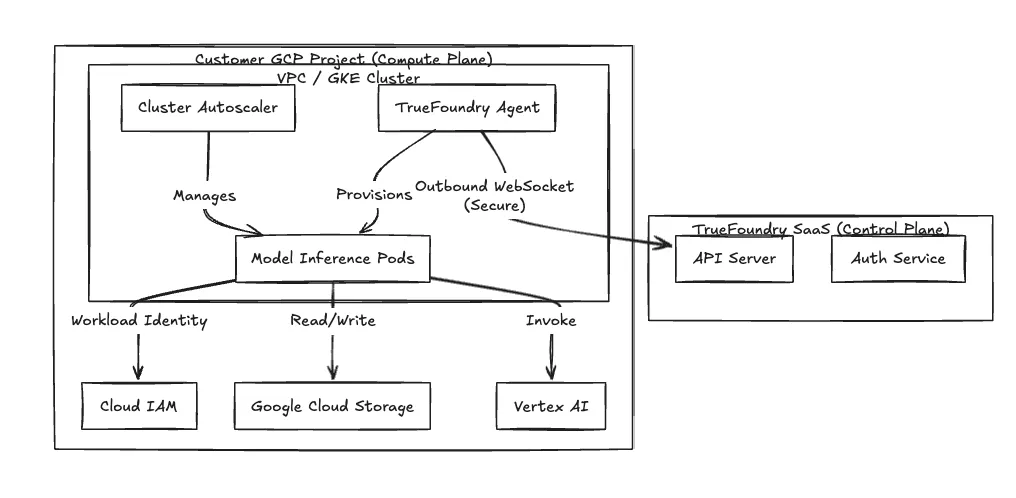
Fig 1: The Split-Plane Architecture isolates data processing within the customer VPC.
For high performance, we configure the compute plane to use VPC-native clusters using Alias IPs. All compute resources reside within private subnets.
Ingress (Inference Requests) Application traffic enters the VPC via Cloud Load Balancing (typically a Global External ALB). The ALB terminates TLS and forwards requests to the Istio Ingress Gateway running within the GKE cluster.
Private Google Access To maintain compliance, traffic to Google APIs (Cloud Storage, Vertex AI) routes via Private Google Access. This keeps traffic between inference pods and GCP managed services on the Google network backbone, bypassing the public internet.
Egress GKE worker nodes require outbound access to pull container images from Artifact Registry. We route this traffic through Cloud NAT attached to the private subnets.
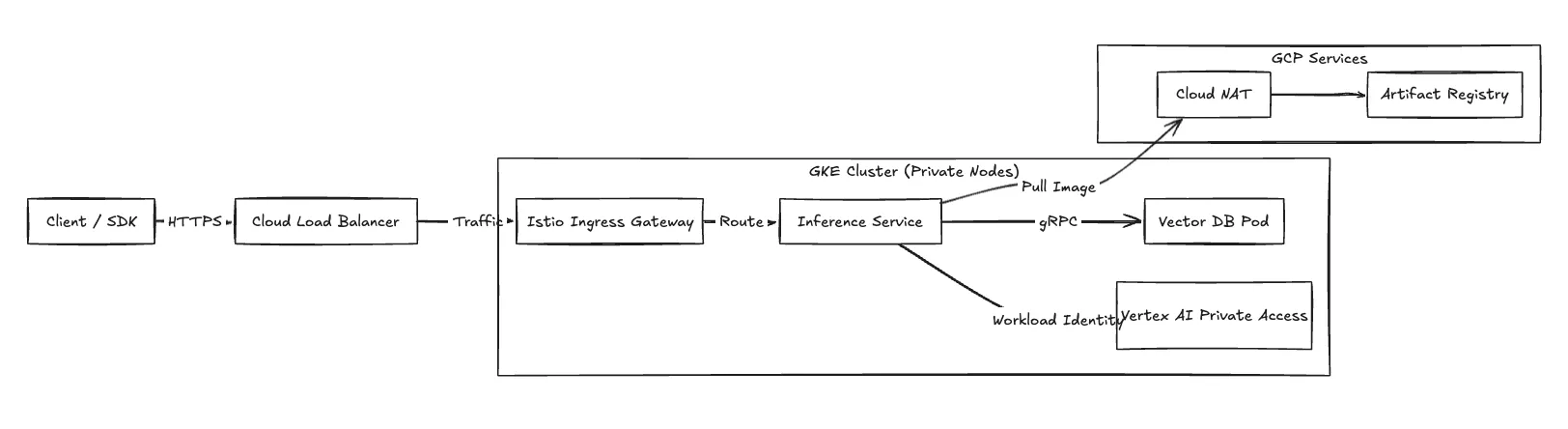
Fig 2: Network traffic flow detailing ingress and private connectivity.
We enforce the removal of static Service Account keys (.json files). TrueFoundry implements GKE Workload Identity for all workload authentication.
The Authentication Sequence
If a pod is compromised, the blast radius is limited strictly to the IAM roles granted to that specific GSA.
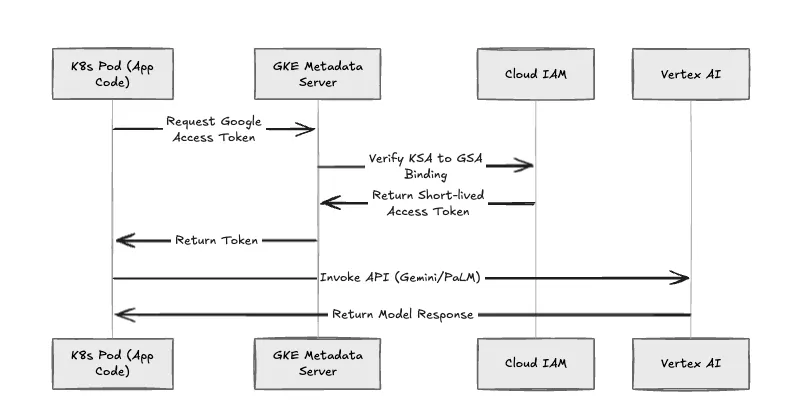
Fig 3: The GKE Workload Identity authentication flow.
We integrate with GKE Node Pools to orchestrate NVIDIA GPUs and Cloud TPUs.
TPU Orchestration Scheduling on TPUs requires handling specific topology constraints. TrueFoundry manages the nodeSelector and tolerations required to schedule pods onto TPU slices (e.g., v4-8, v5e). We automatically inject the necessary drivers and resource limits into the deployment manifest, abstracting the low-level Kubernetes configuration.
Spot VM Management For batch processing or development workloads, we manage Spot VMs to reduce costs (typically 60-90% vs on-demand).
Managing distinct keys for models like Gemini Pro creates operational overhead. TrueFoundry provides an AI Gateway that acts as a unified API interface.
This integration enables your team to fully exploit GCP’s hardware advantages—specifically TPUs and high-throughput networking—without getting bogged down in the operational friction of raw Kubernetes management. TrueFoundry acts as a force multiplier for your infrastructure: we abstract the complexity of GKE orchestration while you retain absolute authority over security and data residency. This balance allows you to operationalize GenAI workloads immediately, turning infrastructure from a constraint into a competitive velocity advantage.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.



.png)

.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




