November 5, 2025
|
5 min read

Published: June 10, 2026

Blazingly fast way to build, track and deploy your models!
On June 9, 2026, Anthropic did something it had never done before: it handed the public a model from its top-secret "Mythos" tier, the class of models that, until now, only cyber-defense partners and a handful of biology researchers were allowed to touch. The public-safe version is called Claude Fable 5, and it doesn't sit in the Opus family. It sits above it.
If you've spent the last year watching models inch forward half a point at a time on a benchmark, Fable 5 is a jolt. It posts 80.3% on SWE-Bench Pro while the next-best model sits 11 points behind. It finished a migration in a 50-million-line codebase in a day. And Andrej Karpathy called it "a major-version-bump-deserving step change forward." This guide covers what it is, how it benchmarks, what it costs, and exactly how to put it into production, with every figure traced back to Anthropic's launch materials.
Think of Anthropic's lineup as a ladder: Haiku for speed, Sonnet for balance, Opus for hard problems, and now Mythos-class for the genuinely brutal ones. Fable 5 is the first Mythos-class model released for general use. It's designed for ambitious, long-running, asynchronous tasks: large-scale code migrations, multi-day agentic sessions, deep research, and dense knowledge work that previous models simply couldn't hold together.
Anthropic's own framing is the key insight: "the longer and more complex the task, the larger Fable 5's lead over our other models." On a quick one-shot question, you might not notice the difference. Hand it a problem that takes hours and dozens of steps, and the gap becomes obvious.
One wrinkle worth understanding up front: Fable 5 shares its underlying weights with Claude Mythos 5, a restricted release for vetted cybersecurity and biology partners that runs the same model with certain safeguards removed. Fable 5 is the safe-for-everyone twin. (Anthropic notes the name comes from the Latin fabula, "that which is told", a cousin of the Greek mythos. The safeguards are the only thing separating the two.)
Here's the complete benchmark set Anthropic published at launch. A few things to read carefully:
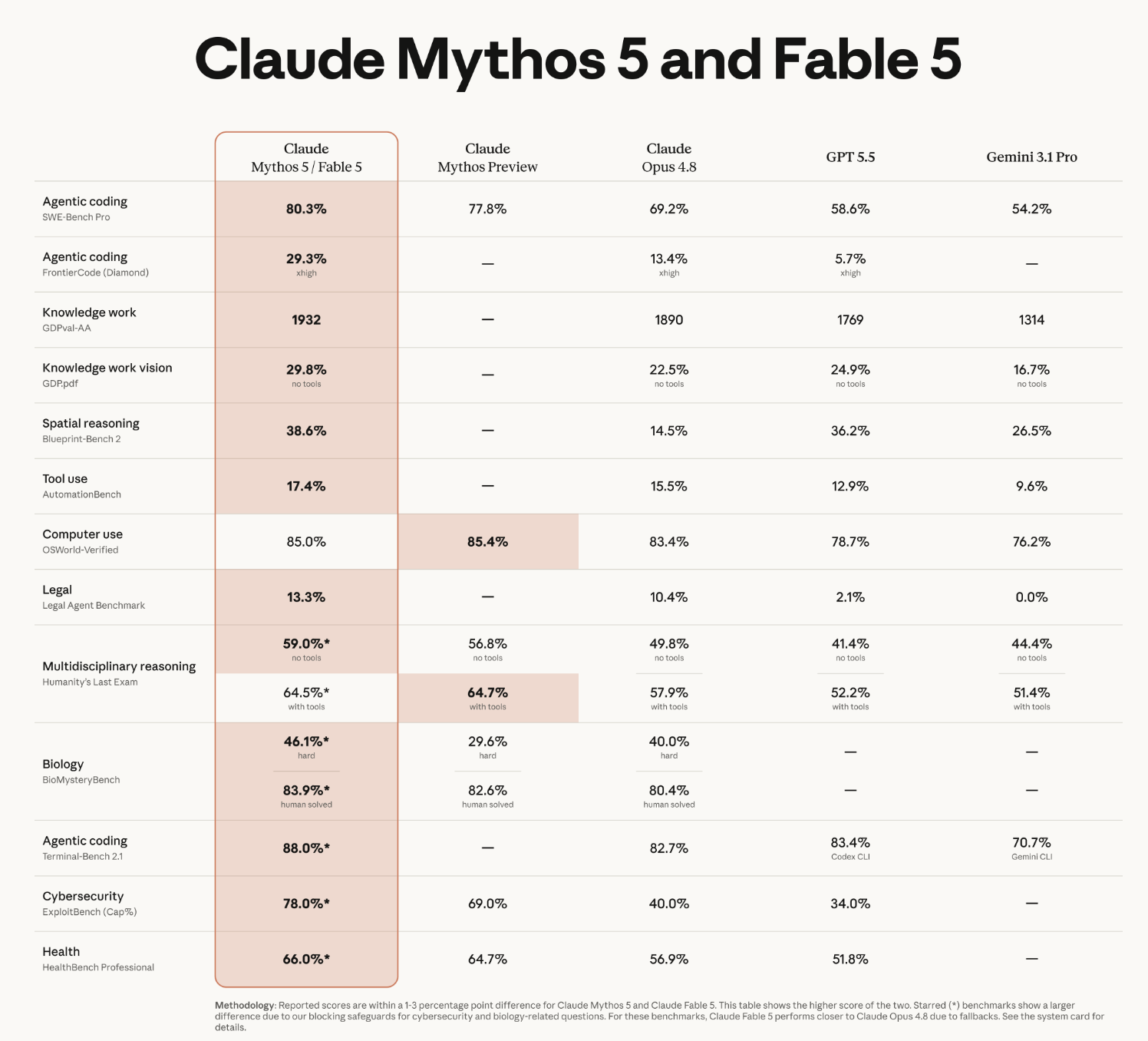
Andrej Karpathy's launch-day reaction captured the mood, and notably backed up the "step change" framing with a qualitative read, not just the scores:

"The benchmarks are great and it's SOTA on everything by a margin but I'll add that qualitatively also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model 'gets it' and it will just go..."
He also flagged the catch that early users are running into: the launch-day safeguards are "configured to be a little too trigger happy," something Anthropic itself acknowledges and says it will tune over time. Which brings us to the part of Fable 5 every API builder needs to understand.
Because Mythos-class capabilities carry real misuse risk, Fable 5 ships with classifiers covering cybersecurity, biology/chemistry, and distillation. When a request trips one, it's automatically answered by Claude Opus 4.8 instead, and the user is told. Anthropic reports this happens in fewer than 5% of sessions; over 95% of Fable sessions involve no fallback at all.
This is also exactly why the starred benchmark rows above matter: on those cyber/bio tasks, the published high score is Mythos 5's, while Fable 5, with safeguards active, performs closer to Opus 4.8.
What you need to know as a developer:
A gateway helps here: you can log which requests fell back, route them consistently, and keep the behavior uniform across your app.
Fable 5 is a premium model, roughly 2x the price of Claude Opus 4.8. Full token economics:
The nuances that decide your real bill:
Because Fable 5 is both expensive per token and token-hungry on long tasks, cost control isn't optional. Routing it through a gateway lets you cap spend, cache aggressively, and reserve Fable 5 for the jobs that actually justify it.
Fable 5 is available today on:
Grab an API key from the Claude Console and call the model with the string claude-fable-5. Anthropic's quickstart walks through authentication and your first request: see the Claude API docs.
Calling the API directly is perfect for a quick test or a single app. The moment Fable 5 goes into production across more than one team, you need access control, budgets, and fallbacks, and that is where a gateway comes in.
Direct API access is enough to prototype. Running a premium, token-hungry model like Fable 5 across an organization is a different problem: you have to control who can use it, cap spend, handle the safeguard fallbacks consistently, and keep one view of cost across providers. A gateway sits between your apps and the model and handles all of that.
In practice that means a platform team can turn Fable 5 on for the whole company in minutes, with spend controls and fallbacks already in place, instead of each team wiring up the raw API and hoping the bill stays sane.
In the TrueFoundry gateway, open your connected Anthropic provider, search for claude-fable-5 on the Models Selection screen, enable it (its $10 / $50 pricing is shown inline), and use Access Control to decide which teams and virtual keys can call it.
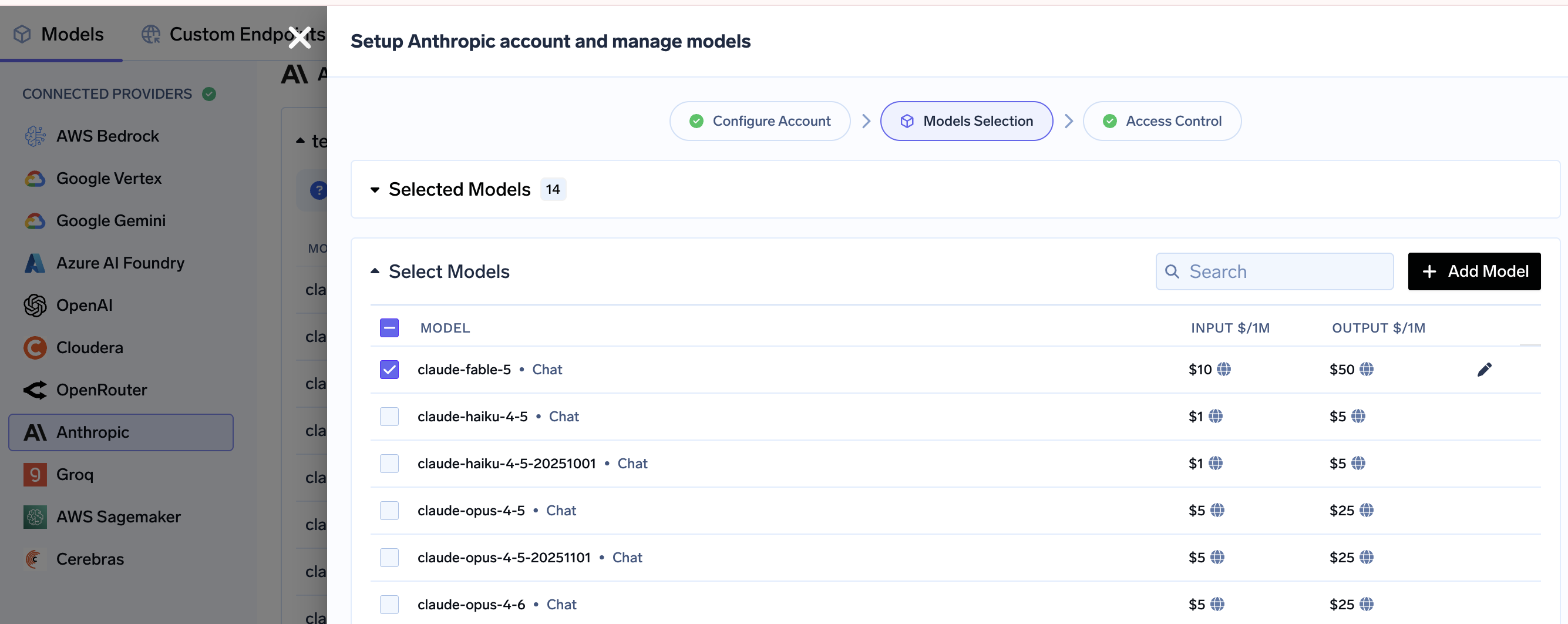
Open the Playground, pick claude-fable-5, and copy the ready-made Usage code snippet. TrueFoundry generates it for OpenAI, LangChain, Node.js, cURL, LlamaIndex, and more, in both streaming and non-streaming modes.
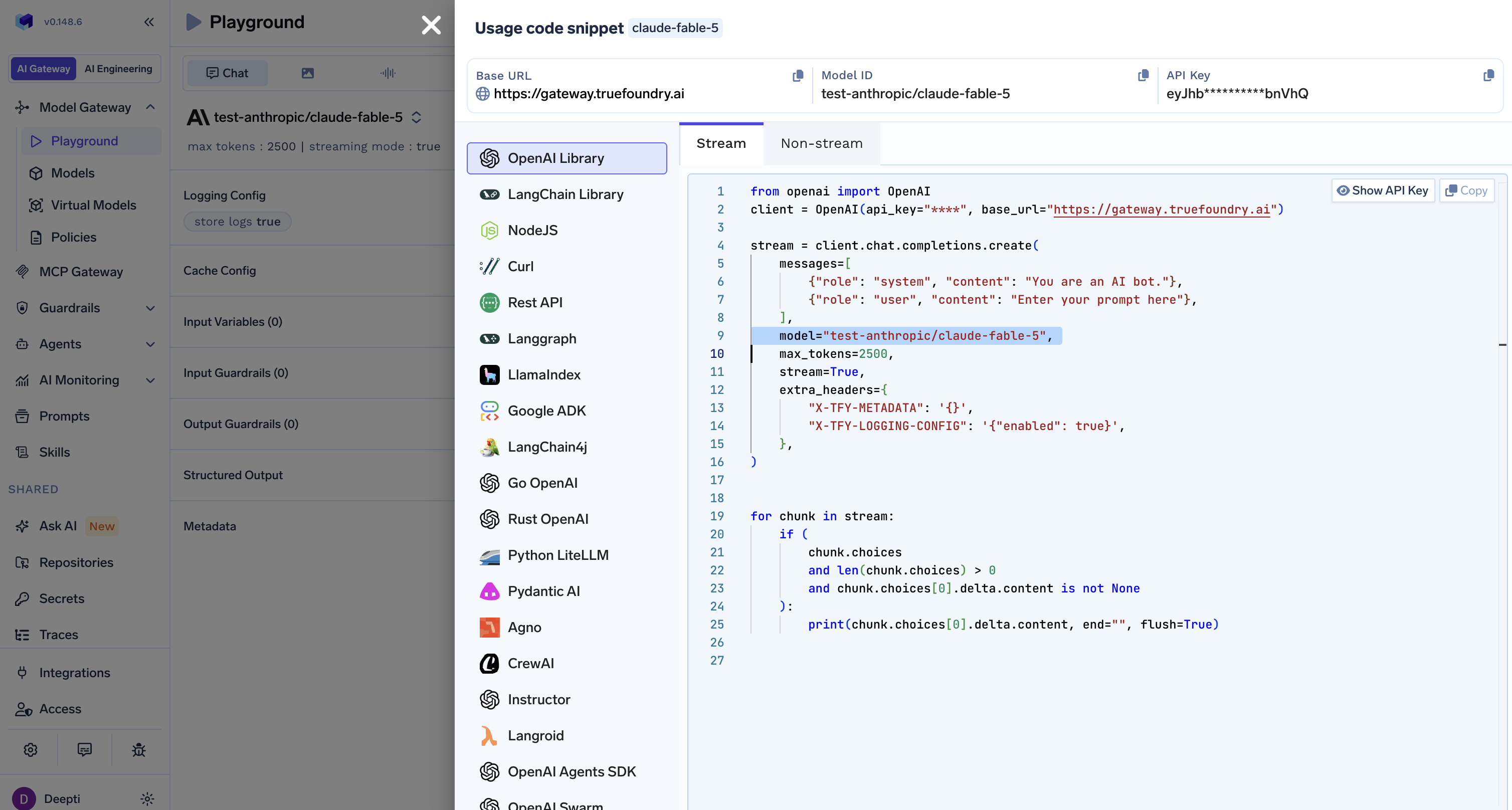
The win: switching between Fable 5, Opus 4.8, GPT-5.5, or any other model is a one-line change, and every call is governed, logged, and observable. Add the X-TFY-LOGGING-CONFIG and X-TFY-METADATA headers to tag and track spend per team or feature.
Ready to put Fable 5 into production with cost controls and fallbacks from day one? Try Claude Fable 5 on the TrueFoundry AI Gateway.
Use Fable 5 when the task is genuinely hard and long: large migrations, multi-stage agent workflows, deep research, complex document analysis, the jobs where Karpathy's "give it a lot more ambitious tasks" actually pays off. For shorter, latency-sensitive, or high-volume work, Opus 4.8 (half the price) or a smaller model is usually the smarter call. The pattern most teams settle on: route by task complexity, hard, high-value jobs to Fable 5, everything else to a cheaper model, all from one gateway.
What is the Claude Fable 5 API model name? claude-fable-5, available via the Claude API and major cloud marketplaces.
How much does Claude Fable 5 cost? $10 per million input tokens and $50 per million output tokens, with a 90% prompt-caching discount on input, about double Claude Opus 4.8.
What's the context window? 1,000,000 tokens, with text, image, and file inputs.
Is Claude Fable 5 better than GPT-5.5? On SWE-Bench Pro, Fable 5 (80.3%) outperforms GPT-5.5 (58.6%) and leads on nearly every benchmark Anthropic published. Validate on your own workload before committing.
How is Fable 5 different from Mythos 5? Same underlying model. Fable 5 is the safe-for-general-use release; Mythos 5 lifts certain safeguards and is restricted to vetted partners.
Why did my request return an Opus 4.8 response? Fable 5's safeguards route flagged cybersecurity/biology/chemistry/distillation queries to Opus 4.8 (under 5% of sessions), and you aren't charged Fable prices for them.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox



.webp)