




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
Prefix caching reuses identical prompts. Semantic caching reuses similar ones — embed the incoming request, and if a near-identical question was answered recently, serve the stored answer instead of calling the model. It's one of the highest-leverage cost and latency levers a gateway can pull, and one where "it works in the demo" and "it's safe in production" are very different claims. This post is how it works, the single knob that governs it, the cases where it quietly serves the wrong answer, and where the cache should live.
Kabir, a backend engineer, had a good week and then a bad one. The good week: he'd put a semantic cache in front of Northwind's support assistant — embed each incoming question, and if a near-identical question had been answered recently, return the stored answer instead of calling the model. Model-call volume dropped 35%. Latency on cache hits fell from roughly 900 ms to under 40 ms. The bad week: a customer asked "where's my delivery?" and got a confident, detailed answer — about someone else's order. Two customers had asked semantically identical questions minutes apart; the cache embedded both to nearly the same vector, scored a hit, and served the first customer's answer to the second.
The cache was working exactly as designed. It just had no idea that "where's my delivery?" means something different depending on who is asking. Semantic caching trades a model call for a similarity match, and the entire safety of that trade lives in two places: the threshold you match on, and what you allow into the cache in the first place. This post is both.
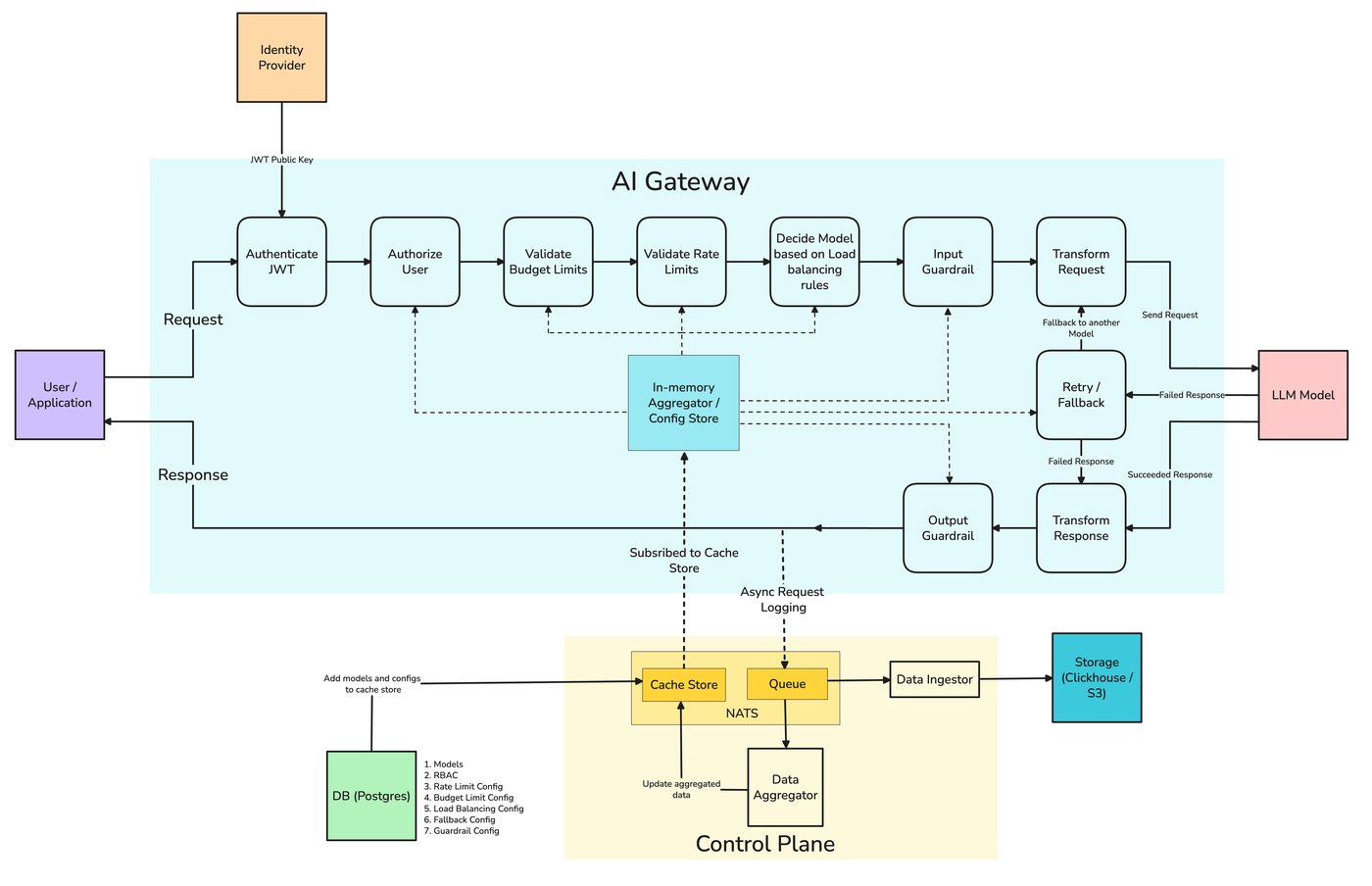
Everything in this post — exact-match and semantic caching, the similarity threshold as a per-route knob, per-tenant scoping so Kabir's bug from the cold open never happens, and the hit-rate / cost-saved telemetry that tells you whether the cache is actually paying off — is something TrueFoundry's AI Gateway caching expresses as gateway configuration. A single header on the request turns it on; the gateway hashes the request (or embeds the last message for semantic), compares against a Redis-backed store, and returns the cached response on a hit. On a miss, the request goes to the provider and the new response and embedding are cached for next time.
The correctness story — making sure two semantically similar requests from different users never return each other's answers — is built in via two-level namespacing. Level 1 is automatic: every cache entry is scoped to the calling user or virtual account, so User A's request can never hit User B's entry, full stop. Level 2 is optional: a namespace field in the cache config partitions further (per tenant, per environment, per system-prompt version), which is what the post's namespace argument needs in practice. Together, they're what makes a gateway-level semantic cache safe to share across services without each one re-implementing isolation.
Application code stays the same — the cache is opt-in per request via a single header. The example below uses semantic, which is a superset of exact-match (it will also serve identical-text hits), with a conservative starting threshold of 0.9 and a custom namespace so a multi-tenant app keeps each tenant's cache isolated even beyond the automatic per-user scoping:
Calling the gateway with semantic caching enabled (Python, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>",
api_key="<your-virtual-account-token>",
)
resp = client.chat.completions.with_raw_response.create( # raw_response → see headers
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": user_question}],
extra_headers={
# Semantic is a superset of exact-match. Start strict (0.9) and tune from there.
"x-tfy-cache-config": (
'{"type":"semantic",'
'"similarity_threshold":0.9,'
'"ttl":600,'
'"namespace":"tenant-acme-faq"}'
),
},
)
print(resp.headers.get("x-tfy-cache-status")) # "hit", "miss", or "error"
print(resp.headers.get("x-tfy-cache-similarity-score")) # e.g. "0.95" on a semantic hit
print(resp.parse().choices[0].message.content)"Caching" covers three distinct mechanisms with very different reach and risk, and it's worth being precise about which one you're deploying.
Provider prefix caching reuses an exact, identical prompt prefix — the system prompt and tool definitions that repeat unchanged across calls. The provider matches on an exact prefix and bills the repeated portion at a steep discount. It's automatic, safe, and covered in our context-engineering post; it never serves a wrong answer because it only matches identical text.
Exact-match response caching hashes the entire normalized request and returns the stored response on an identical hash. Also safe — identical input, identical output — but the hit rate is low, because users rarely phrase things identically.
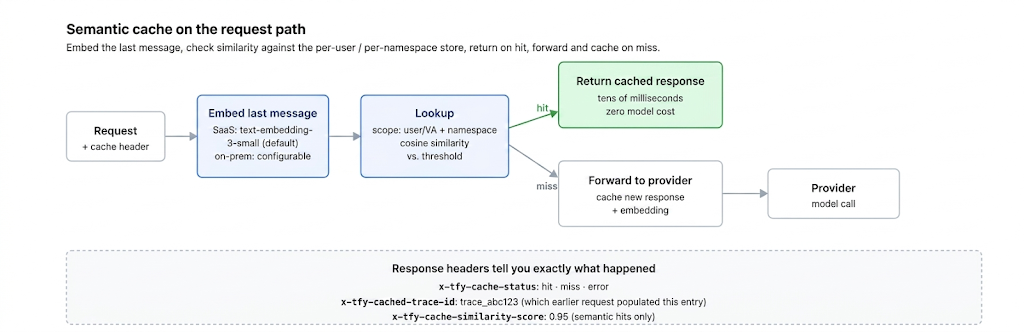
Semantic caching is the subject here: embed the request and serve a cached response when a similar prior request exists. This is where the hit rate jumps, because "where's my package?" and "has my order shipped yet?" can share a cached answer — and it's also where the risk appears, because "similar" is a judgment call made by a similarity threshold rather than an exact match.
The mechanism is three steps. Embed the incoming request into a vector. Search a vector store for the nearest prior request within the right scope. If the nearest neighbor's similarity exceeds a threshold, return its stored response; otherwise call the model and store the new request/response pair for next time.
Semantic cache lookup — embed, search within scope, serve on a confident hit
emb = embed(request.text) # ~10-30 ms
hit = vector_store.nearest(emb, scope=tenant_id) # scoped search — never global for user data
if hit and hit.score >= THRESHOLD: # the knob that governs everything
return hit.response, "cache_hit" # tens of ms, no model call
resp = call_model(request) # miss -> full model call
vector_store.put(emb, resp, scope=tenant_id, ttl=TTL)
return resp, "cache_miss"On a hit, you've replaced a model call — typically several hundred milliseconds and a per-token charge — with an embedding call and a vector lookup, on the order of tens of milliseconds and a fraction of the cost. On a miss, you've added the embedding and lookup latency to the normal model call, which is the small tax you pay for the chance at a hit. The economics of that trade depend entirely on the hit rate (section 7), and the safety depends entirely on the threshold (next).
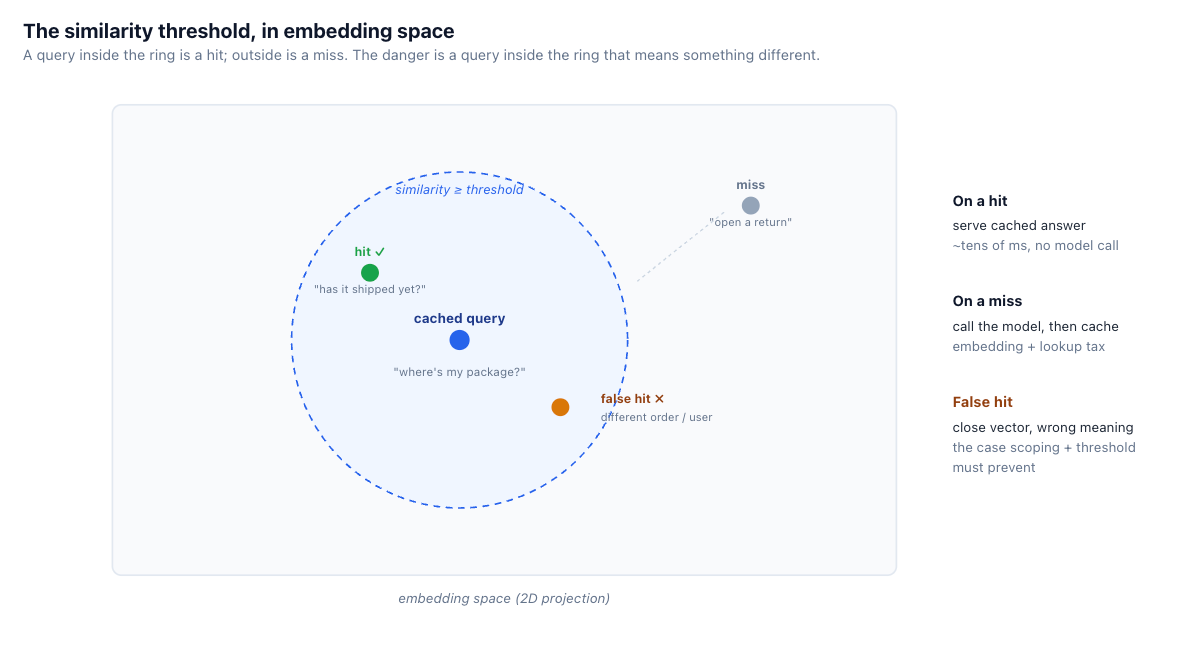
The threshold decides how close a new request must be to a cached one to count as a hit, and it is a direct precision/recall tradeoff. Set it too low — accept loose matches — and the hit rate is high but you serve answers to questions that weren't quite asked (false hits). Set it too high — demand near-identical phrasing — and the cache is safe but rarely fires, collapsing toward exact-match caching with extra steps.
There is no universal correct value, because it depends on the embedding model, the domain, and how much a wrong answer costs you. The way to set it is empirical: assemble labeled pairs of requests that should and should not share an answer, sweep the threshold, and pick the point where false hits drop to an acceptable rate for that route. High-stakes routes (anything touching money, health, or identity) warrant a conservative threshold or no semantic caching at all; low-stakes informational routes (documentation Q&A, general explanations) can run looser. Per-route thresholds, not one global number, are the production pattern — and a gateway like TrueFoundry's AI Gateway, which already sits on every route, is the natural place to set them per route and watch each route's false-hit rate rather than scattering the policy across services.
The core hazard is simple to state and easy to underestimate: embedding-close is not meaning-equal. Embeddings capture topical similarity, not logical equivalence. "What is the capital of France?" and "What is the capital of Germany?" are extremely close in embedding space — same structure, same domain, one word different — yet require different answers. A threshold tuned for recall will treat them as the same question.
The mitigations stack, and none is complete on its own. A conservative threshold reduces loose matches. Entity and keyword guards add a check that the salient entities (the country, the order number, the product) match before serving a hit, catching the France/Germany case that pure cosine similarity misses. Per-namespace caches keep distinct contexts from colliding. And the most reliable mitigation is upstream: don't cache the classes of request where a near-miss is dangerous at all, which is the next section. Treat semantic caching as a tool with a known failure mode you design around, not a transparent speedup you can apply everywhere.
Some responses are unsafe to serve from a similarity match regardless of how good the threshold is, because the thing that makes two requests different isn't in the text the embedding sees.
A semantic cache entry is not keyed by text alone; it's keyed by an embedding inside a namespace, and the namespace is where correctness is enforced. The namespace should encode everything that makes two textually-similar requests genuinely different: the tenant or user (for anything user-specific), the model, the system-prompt version, and the active tool set. Two identical questions under different system-prompt versions are different questions, because the instructions that shape the answer changed.
Namespacing a cache entry (illustrative)
# Same text in a different namespace is a different entry — by design.
namespace = f"{tenant_id}:{model}:{system_prompt_version}"
# For user-specific answers, the user/tenant MUST be in the namespace,
# so a lookup can never return another user's cached response.
vector_store.put(emb, resp, namespace=namespace, ttl=TTL)Invalidation has two triggers. Time, via a TTL chosen for how fast the underlying truth changes — short for anything that drifts, longer for stable reference answers. And version, via the namespace: bumping the system-prompt version or changing the tool set rolls the cache forward, so stale answers from the old configuration are never served. The failure to invalidate on a prompt change is a common and subtle bug — the prompt improves, but cached answers keep reflecting the old one until the TTL expires.
In TrueFoundry's caching, all of this is the x-tfy-cache-config header (or a centrally-managed policy that sets the same fields). The schema is small and the controls match what this section just described:
Per-route caching for a multi-tenant assistant — three patterns, same schema
# Route A: low-risk FAQ. Broad matching is fine; cache for 1 hour.
x-tfy-cache-config: {"type":"semantic","similarity_threshold":0.88,"ttl":3600,
"namespace":"faq:v3"}
# Route B: per-tenant support. Per-tenant namespace + stricter threshold to
# avoid cross-tenant near-misses (automatic per-user scoping ALREADY isolates
# users; the namespace partitions further along business boundaries).
x-tfy-cache-config: {"type":"semantic","similarity_threshold":0.93,"ttl":600,
"namespace":"tenant-acme:assistant:v7"}
# Route C: deterministic dev/test. Exact-match only.
x-tfy-cache-config: {"type":"exact-match","ttl":600,"namespace":"staging"}The docs' threshold guidance matches the post: 0.95–1.0 for very strict use cases where a wrong hit is costly, 0.85–0.95 for balanced conversational assistants, below 0.85 for exploratory or low-risk routes. Starting at 0.9 and adjusting based on observed false-hit rate is what they recommend, and the response header x-tfy-cache-similarity-score is what makes that measurable — every hit tells you the score it cleared on, so a sweep across labeled pairs becomes a few queries, not a custom evaluation harness.
Two implementation details worth knowing. The embedding model on SaaS is OpenAI's text-embedding-3-small by default and is not configurable in that mode; on self-hosted deployments it's pickable via Controls → Settings → Semantic Cache, and the chosen model applies to all semantic-cache operations gateway-wide.
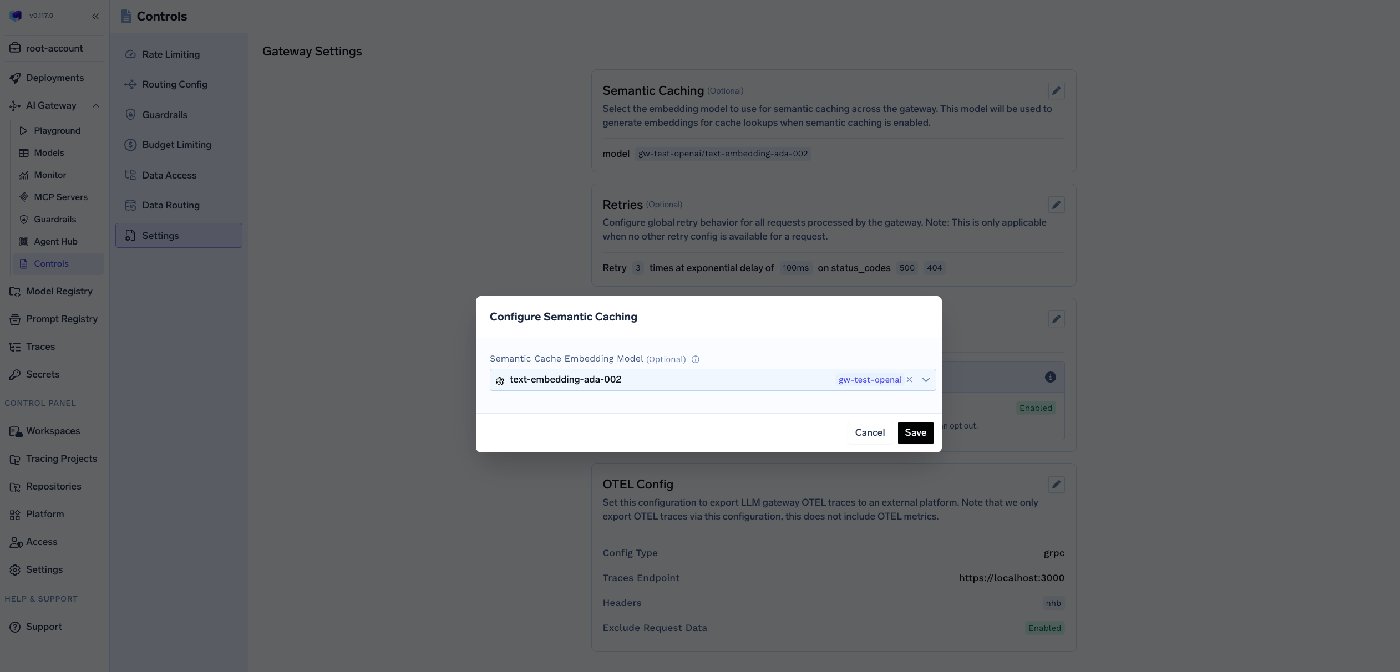
The store on self-hosted is Redis — either the bundled Redis from the tfy-llm-gateway Helm chart, or your own Redis (or Redis-compatible like Valkey) via env vars. Both choices matter because the cache only earns its keep when the embedding+lookup is genuinely faster and cheaper than the model call it's avoiding.
The other side of the namespace argument from the post is the part the gateway makes automatic: Level-1 isolation. Every entry is implicitly scoped to the user or virtual account that created it, so even if you forget to set namespace، طلب المستخدم أ لا يعيد أبدًا الإجابة المخزنة مؤقتًا للمستخدم ب. الـ مساحة الاسم هي تقسيم إضافي للحالات التي يصفها المنشور — تطبيقات متعددة المستأجرين تتشارك حسابًا افتراضيًا واحدًا، إصدارات موجه النظام، بيئات — وليس الشيء الوحيد الذي يفصل بين إجابات متصلين مختلفين. هذه الطبقية هي ما يجعل "مشاركة ذاكرة تخزين مؤقت واحدة عبر الخدمات" خيارًا افتراضيًا يمكن الدفاع عنه بدلاً من أن يكون مصدر مشاكل.
تُحدد قيمة التخزين المؤقت الدلالي برقم واحد: معدل الإصابة. كمثال توضيحي، لنفترض أن مسارًا معينًا يعمل بتكلفة نموذجية لكل استدعاء، وأن ذاكرة التخزين المؤقت تحقق معدل إصابة بنسبة 30% عند عتبة آمنة. حوالي 30% من الطلبات تتجاوز الآن استدعاء النموذج، لذا تنخفض التكلفة على هذا المسار بنسبة تقارب 30% (ناقص تكلفة التضمين والبحث، وهي صغيرة مقارنة بالتوليد). يتحسن زمن الاستجابة في تلك الـ 30% من الطلبات تحديدًا، حيث ينخفض من توليد يستغرق عدة مئات من المللي ثانية إلى بحث يستغرق عشرات المللي ثانية، مما يقلل من المتوسط والحد الأقصى.
ملاحظتان صريحتان حول الحسابات. معدل الإصابة خاص بحمل العمل — قد يشهد مساعد بأسلوب الأسئلة الشائعة الضيقة أكثر بكثير من 30%، بينما قد لا يشهد حمل عمل إبداعي ذو ذيل طويل أي شيء تقريبًا — لذا فإن الرقم الوحيد الموثوق به هو الذي تقيسه على حركة المرور الخاصة بك. والوفورات هي صافي ضريبة التضمين على كل إخفاق؛ إذا كان معدل الإصابة لديك منخفضًا جدًا، فقد تنفق على التضمينات أكثر مما توفره. قس الجزء القابل للتخزين المؤقت قبل الالتزام، بدلاً من افتراض معدل عام. تشغيل ذاكرة التخزين المؤقت خلف TrueFoundry's AI Gateway هو ما يجعل ذلك قابلاً للقياس في المقام الأول — يظهر معدل الإصابة والإنفاق الذي يتجنبه بجانب تكلفة كل استدعاء من عمل تحديد التكلفة، لذا فإن الوفورات هي رقم مُلاحظ وليست مجرد توقع.
يمكن أن توجد ذاكرة التخزين المؤقت الدلالية في التطبيق، لكن البوابة هي الخيار الافتراضي الأقوى لنفس الأسباب التي تنطبق على التوجيه والموثوقية: فهي موجودة بالفعل على كل طلب، لذا يتم مشاركة ذاكرة التخزين المؤقت عبر الخدمات بدلاً من إعادة تنفيذها في كل منها، وهي تحتوي بالفعل على بيانات القياس عن بعد لتكلفة كل استدعاء وزمن الاستجابة اللازمة لقياس ما إذا كانت ذاكرة التخزين المؤقت تحقق الفائدة المرجوة بالفعل.
تشغيل ذاكرة التخزين المؤقت في TrueFoundry's AI Gateway يعني مكانًا واحدًا لفرض تحديد النطاق لكل مستأجر (حتى لا يحدث الفتح البارد)، ومكانًا واحدًا لرؤية معدل الإصابة، والتكلفة الموفرة، وزمن الاستجابة الموفر، ونفس عرض تحديد التكلفة من cost-attribution post الذي يوضح تقسيم البيانات المخزنة مؤقتًا مقابل غير المخزنة مؤقتًا لكل فريق ومسار. تقسيم العمل هو ما يتكرر عبر هذه السلسلة: توفر البوابة ذاكرة التخزين المؤقت المشتركة، المحددة النطاق، والقابلة للمراقبة؛ ويمتلك التطبيق قرار السياسة بشأن المسارات الآمنة للتخزين المؤقت وعند أي عتبة — لأن التطبيق وحده هو الذي يعرف أن "أين طلبي؟" شخصي وأن "ما هي فترة الإرجاع الخاصة بكم؟" ليست كذلك.
كيف يختلف هذا عن التخزين المؤقت للموجه في منشور هندسة السياق؟
تناول ذلك المنشور التخزين المؤقت لبادئة المزود — إعادة استخدام بادئة موجه نظام متطابقة بخصم على الفاتورة، والذي لا يقدم إجابة خاطئة أبدًا لأنه يطابق النص تمامًا. التخزين المؤقت الدلالي يعيد استخدام مشابهة الطلبات عن طريق تضمينها، وهذا هو مصدر كل من معدل الإصابات الأعلى وخطر الإصابات الخاطئة. وهي تجمع بين: تخزين البادئة الثابتة مؤقتًا في كل استدعاء، وتخزين الاستجابات الكاملة دلاليًا مؤقتًا فقط على المسارات الآمنة.
كيف أختار عتبة التشابه؟
تجريبيًا، لكل مسار. قم بإنشاء مجموعة مصنفة من أزواج الطلبات التي يجب أن تتشارك إجابة والتي لا يجب أن تتشاركها، ثم اختبر العتبة، واختر النقطة التي تنخفض فيها الإصابات الخاطئة إلى معدل مقبول بالنظر إلى تكلفة الإجابة الخاطئة على هذا المسار. المسارات عالية المخاطر تحصل على عتبة متحفظة أو لا يوجد تخزين دلالي مؤقت؛ أما المسارات المعلوماتية منخفضة المخاطر فيمكن أن تعمل بمرونة أكبر. عتبة عالمية واحدة تكون خاطئة دائمًا تقريبًا لبعض المسارات.
هل يمكنني تخزين أي شيء مخصص بأمان؟
فقط بنطاق صريح لكل مستخدم (أو لكل مستأجر) في مساحة اسم التخزين المؤقت، بحيث لا يمكن للبحث أبدًا أن يعيد استجابة مستخدم آخر — وحتى في هذه الحالة، انتبه للحساسية للوقت. الافتراضي الآمن للاستجابات المخصصة، أو الحساسة للوقت، أو ذات الحالة، أو عالية المخاطر هو عدم تخزينها دلاليًا مؤقتًا. "الافتتاح البارد" هو ما يحدث عندما يتم تخزين إجابة مخصصة مؤقتًا بدون نطاق مستخدم.
ماذا يحدث لذاكرة التخزين المؤقت عندما أغير موجه النظام؟
يجب عليك إبطال الصلاحية، وإلا ستقدم إجابات تشكلت بواسطة الموجه القديم حتى انتهاء صلاحية TTL الخاص بها. الطريقة النظيفة هي وضع إصدار موجه النظام في مساحة اسم التخزين المؤقت، بحيث يؤدي تغيير الموجه إلى تحديث ذاكرة التخزين المؤقت تلقائيًا، ولا تتم مطابقة الإدخالات القديمة مرة أخرى ببساطة.
بوابة أم تطبيق؟
البوابة للآليات — ذاكرة تخزين مؤقت مشتركة، وتحديد نطاق لكل مستأجر، وقابلية المراقبة لمعدل الإصابات/التكلفة/الكمون التي تخبرك ما إذا كانت تعمل. والتطبيق للسياسة — أي المسارات قابلة للتخزين المؤقت وعند أي عتبة — لأن هذا الحكم يتطلب معرفة بالمجال لا تملكها البوابة.
ذاكرة التخزين المؤقت لكبير لم تكن فكرة سيئة؛ بل كانت غير محددة النطاق. يحقق التخزين المؤقت الدلالي مكاسب حقيقية في التكلفة والكمون على المسارات التي تتشارك فيها الأسئلة المتشابهة إجابة حقيقية — والانضباط الذي يجعلها آمنة هو معرفة، مسارًا بمسار، ما هي تلك الأسئلة.
بوابة الذكاء الاصطناعي من TrueFoundry هي لوحة تحكم على مستوى المؤسسات تقع بين تطبيقاتك وأكثر من 1600 نموذج — عبر OpenAI، وAnthropic، وGoogle، وAWS Bedrock، وAzure OpenAI، ونماذجك المستضافة ذاتيًا — خلف واجهة برمجة تطبيقات واحدة متوافقة مع OpenAI. إنها تحول استراتيجيات التخزين المؤقت في هذا المنشور إلى إعدادات بدلاً من كود خاص بكل خدمة: التخزين المؤقت بالمطابقة التامة والتخزين المؤقت الدلالي عبر رأس واحد x-tfy-cache-config ، وعتبات تشابه لكل مسار و TTLs، وعزل تلقائي لكل مستخدم / لكل حساب افتراضي، وتقسيم اختياري لمساحة الاسم للتطبيقات متعددة المستأجرين وإصدارات الموجهات، وتخزين مدعوم بـ Redis يعمل بنفس الطريقة على SaaS والمستضاف ذاتيًا (مع إمكانية تهيئة نموذج التضمين في الموقع).
نظرًا لأن البوابة تعترض كل طلب وتصدر تتبعًا كاملاً لكل استدعاء، تصبح ذاكرة التخزين المؤقت قابلة للقياس في نفس العرض مثل كل شيء آخر: x-tfy-cache-status، ومعرف التتبع المخزن مؤقتًا، ودرجة التشابه الفعلية على كل استجابة، وتُجمع في لوحات معلومات توفير التكلفة وتقليل زمن الاستجابة. تضيف نفس البوابة التحكم في الوصول المستند إلى الدور (RBAC)، والحسابات الافتراضية، والميزانيات وحدود المعدل، وآليات التراجع وإعادة المحاولة، وضوابط الحماية، ولوحات معلومات المراقبة. يتم نشرها كخدمة برمجية (SaaS)، أو في شبكتك الافتراضية الخاصة (VPC)، أو محليًا، أو معزولة هوائيًا، مع الامتثال لمعايير SOC 2 و HIPAA و ITAR، وهي معترف بها في دليل السوق للبوابات الذكية من Gartner. انظر وثائق التخزين المؤقت أو نظرة عامة على بوابة الذكاء الاصطناعي للتعمق أكثر.
Northwind و Kabir هما مثالان توضيحيان. إن آليات التخزين المؤقت القائم على التضمين، وسلوك الدقة/الاستدعاء لعتبة التشابه، ووضع الفشل حيث "التضمين القريب لا يعني التكافؤ في المعنى" هي خصائص عامة لهذه التقنية. الأرقام المحددة — تخفيض المكالمات بنسبة 35%، وزمن الاستجابة من 900 مللي ثانية إلى 40 مللي ثانية عند النجاح، ومثال معدل النجاح بنسبة 30%، وتكلفة التضمين من 10 إلى 30 مللي ثانية — هي افتراضات تمثيلية لتقدير الحجم لتوضيح المفاضلات، وليست قياسات؛ قم بقياس نسبة التخزين المؤقت الخاصة بك ومعدل النجاح الخاطئ قبل تمكين التخزين المؤقت الدلالي في الإنتاج.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.






.png)
.webp)










.webp)
