




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
تقدم نماذج اللغة الكبيرة (LLMs) إمكانيات قوية، لكنها تجلب أيضًا تكاليف عالية للبنية التحتية، وأنماط استخدام غير متوقعة، واحتمال إساءة الاستخدام. بينما تدمج الشركات نماذج اللغة الكبيرة (LLMs) في الأدوات الموجهة للعملاء، والمساعدين الداخليين، ومنصات واجهة برمجة التطبيقات (API)، تصبح الحاجة إلى وصول محكوم وموثوق أمرًا بالغ الأهمية. وهنا يلعب تحديد المعدل دورًا رئيسيًا.
في سياق استدلال نماذج اللغة الكبيرة (LLM)، تحديد المعدل التقليدي للطلبات في الثانية (RPS) غير كافٍ. نماذج اللغة الكبيرة (LLMs) تستهلك الكثير من الموارد، وتعتمد على الرموز (التوكنات)، وتتسم بتقلب كبير في الحمل الحسابي. يمكن لموجه واحد لنموذج بمعاملات 70 مليار أن يستهلك آلاف الرموز (التوكنات) ويؤثر بشكل كبير على زمن استجابة وحدة معالجة الرسوميات (GPU). بدون ضوابط مناسبة، يمكن أن تصبح البنية التحتية المشتركة غير مستقرة بسرعة أو باهظة التكلفة.
تشرح هذه المقالة كيفية عمل تحديد المعدل في بوابة الذكاء الاصطناعي، ولماذا هو ضروري للبنية التحتية للذكاء الاصطناعي القابلة للتوسع، وكيف تمكّنه TrueFoundry افتراضيًا لضمان الاستخدام العادل، وكفاءة التكلفة، وأداء بمستوى الإنتاج عبر عمليات النشر متعددة المستأجرين.
تحديد المعدل هو آلية تستخدم للتحكم في عدد الطلبات التي يمكن للعميل إرسالها إلى نظام ضمن نافذة زمنية محددة، وهي قدرة أساسية في بوابات الذكاء الاصطناعي الحديثة التي تدير حركة مرور نماذج اللغة الكبيرة (LLM). تضمن العدالة، وتمنع التحميل الزائد، وتحافظ على التوفر، خاصة في البيئات متعددة المستخدمين. غالبًا ما تطبق واجهات برمجة التطبيقات التقليدية حدودًا بسيطة مثل 100 طلب في الدقيقة لكل مستخدم، وهو ما يعمل بشكل جيد لخدمات REST القياسية.
ومع ذلك، تعمل نماذج اللغة الكبيرة (LLMs) بشكل مختلف تمامًا. يمكن لكل طلب أن يضع حملاً مختلفًا بشكل كبير على البنية التحتية بناءً على حجم الإدخال ونوع النموذج والمخرجات المتوقعة. على سبيل المثال، قد يكتمل موجه من 20 رمزًا (توكنًا) لنموذج 7B بسرعة، بينما قد يؤدي طلب من 2000 رمز (توكن) لنموذج 65B إلى حظر وحدات معالجة الرسوميات (GPUs) لعدة ثوانٍ. حتى طلبان متطابقان لنموذجين مختلفين يمكن أن يختلفا بمقدار 5 أضعاف أو أكثر في تكلفة الحوسبة.
هذا يجعل الحدود القائمة على الطلبات غير كافية. يجب على بوابات نماذج اللغة الكبيرة (LLM) الحديثة اعتماد تحديد المعدل المدرك للرموز (التوكنات)، والذي يأخذ في الاعتبار العدد الفعلي للرموز (التوكنات) المعالجة وعبء الحوسبة لكل استدعاء.
تشمل العوامل الرئيسية التي تؤخذ في الاعتبار في تحديد المعدل المدرك للرموز (التوكنات) ما يلي:
مقارنة بحدود الطلبات الثابتة، فإن الحدود التي تأخذ الرموز في الاعتبار:
في سير عمل الذكاء الاصطناعي التوليدي، يصبح تحديد المعدل أكثر أهمية. يمكن لمستخدم واحد أن يؤدي إلى معالجة خلفية واسعة النطاق من خلال المطالبات الطويلة، أو استيعاب المستندات، أو الوكلاء متعددي الخطوات. بدون ضوابط، قد يؤدي ذلك إلى ازدحام وحدات معالجة الرسوميات (GPU)، أو زمن انتقال عالٍ، أو تكاليف غير متوقعة.
غالبًا ما يكون الاستخدام الفعلي غير متوقع، مدفوعًا بتطبيقات الواجهة الأمامية، أو حلقات الاختبار، أو الأتمتة. يضمن تحديد المعدل بقاء هذه التفاعلات مستقرة وفعالة، حتى عندما تكون البنية التحتية مشتركة بين المستخدمين أو المستأجرين.
لأي نشر على مستوى الإنتاج، فإن أفضل بوابة لنموذج اللغة الكبير (LLM) يجب أن توفر تحديدًا ذكيًا للمعدل كمتطلب أساسي للتوسع والموثوقية والتحكم في التكاليف.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

تحديد المعدل هو أكثر من مجرد حماية خلفية. بالنسبة للمنصات التي تخدم نماذج اللغة الكبيرة (LLMs) — خاصة تلك التي تقدم واجهات برمجة تطبيقات عامة أو متعددة المستأجرين — فهو يعمل كطبقة استراتيجية للاستقرار والحوكمة ومواءمة الأعمال. سواء كانت OpenAI أو Anthropic أو المنصات المبنية باستخدام TrueFoundry، فإن حدود المعدل تخدم عدة أغراض حاسمة.
حماية البنية التحتية من سوء الاستخدام
استدلال الذكاء الاصطناعي التوليدي يستهلك الكثير من الموارد. يمكن أن يؤدي تدفق مفاجئ من المطالبات الطويلة أو الطلبات المتزامنة إلى إغراق قوائم انتظار وحدات معالجة الرسوميات (GPU)، وزيادة زمن الانتقال، أو حتى تعطيل الخدمات. تضمن حدود المعدل معالجة حركة المرور بطريقة محكمة وذات أولوية، مما يمنع استنزاف الموارد.
فرض العدالة بين المستخدمين أو المستأجرين
في الأنظمة متعددة المستخدمين، يجب ألا يؤدي استخدام عميل واحد إلى تدهور الأداء للآخرين. تساعد حدود المعدل في فرض العزل بين المستخدمين أو الفرق أو مفاتيح واجهة برمجة التطبيقات. يضمن ذلك مستويات خدمة متسقة بغض النظر عن عدد المستخدمين النشطين في وقت واحد.
مواءمة الاستخدام مع خطط التسعير
تحقق العديد من منصات الذكاء الاصطناعي التوليدي الدخل بناءً على الرموز أو مستويات الاستخدام. تساعد حدود المعدل في فرض هذه الحدود. على سبيل المثال:
تجنب التكاليف غير المتوقعة وتجاوزاتها
يمكن أن يتوسع استخدام نماذج اللغة الكبيرة (LLM) بهدوء وسرعة. بدون قيود مناسبة، يمكن أن يرتفع استهلاك الرموز (tokens) واستخدام وحدة معالجة الرسوميات (GPU) بشكل كبير. يساعد تحديد المعدل (Rate limiting) المنصات على منع تكاليف البنية التحتية غير المتوقعة والحفاظ على التحكم في الميزانية.
تحسين الموثوقية وتجربة المستخدم
عندما يتم التحكم في الاستخدام، تظل قوائم انتظار النظام مستقرة. يؤدي هذا إلى تقليل زمن الاستجابة، وزيادة معدلات النجاح، وتجربة مستخدم أكثر اتساقًا، وهو أمر مهم بشكل خاص في بيئات الإنتاج التي تتضمن اتفاقيات مستوى الخدمة (SLAs).
في الأنظمة القائمة على نماذج اللغة الكبيرة (LLM)، لا يكون لجميع الطلبات نفس التأثير. قد يستخدم توجيه قصير لنموذج صغير الحد الأدنى من الموارد، بينما يمكن أن تستهلك استعلامات طويلة لنموذج كبير وقتًا كبيرًا من وحدة معالجة الرسوميات (GPU). بسبب هذا التباين، تطبق المنصات الحديثة حدود المعدل عبر أبعاد متعددة بدلاً من الاعتماد فقط على عدد الطلبات.
فيما يلي الأبعاد الأكثر شيوعًا المستخدمة لتحديد المعدل الفعال:
يمنح استخدام هذه الأبعاد فرق المنصة المرونة لمواءمة استخدام الموارد مع قيود البنية التحتية، واحتياجات المستخدمين، وتوقعات مستوى الخدمة.
توفر TrueFoundry نظامًا قويًا ومرنًا لتحديد المعدل يسمح لفرق المنصة بالتحكم في الوصول إلى نقاط نهاية LLM بناءً على الطلبات أو استخدام الرموز. وهذا يضمن التوزيع العادل للموارد الحاسوبية، ويمنع إساءة الاستخدام، ويوائم الاستخدام مع سياسات المؤسسة أو خطط الفوترة.
في صميم آلية تحديد المعدل في TrueFoundry يوجد نظام تكوين قائم على القواعد يسمح للفرق بتحديد سياسات دقيقة عبر المستخدمين والفرق والحسابات الافتراضية والنماذج وبيانات تعريف الطلبات.
التكوين القائم على القواعد
يتم تحديد تقييد المعدل في TrueFoundry من خلال قائمة من القواعد، يحدد كل منها:
يتم تقييم القواعد بالترتيب، لذا يجب وضع القواعد الأكثر تحديدًا قبل القواعد الأعم لضمان المطابقة الصحيحة.
أنواع الحدود المدعومة
تدعم TrueFoundry كلاً من الحدود القائمة على الطلبات والحدود القائمة على الرموز عبر فترات زمنية مختلفة:
يتيح ذلك تطبيق سياسات تعكس الاستخدام الفعلي للموارد الحاسوبية، وهو أمر مهم بشكل خاص عند تقديم مطالبات متغيرة الطول لنماذج بأحجام مختلفة.
حالات الاستخدام الشائعة
تدعم مرونة نظام التكوين مجموعة واسعة من حالات الاستخدام:
مثال على التكوين
الاسم: ratelimiting-config
النوع: gateway-rate-limiting-config
القواعد:
- المعرف: "specific-rule"
عندما:
الموضوعات: ["user:bob@email.com"]
النماذج: ["openai-main/gpt4"]
الحد الأقصى: 1000
الوحدة: requests_per_day
يحدد هذا المثال استخدام مستخدم معين لـ GPT-4 بـ 1000 طلب في اليوم. تم تصميم نظام تحديد المعدل (rate-limiting) الخاص بـ TrueFoundry ليكون قويًا وسهل الإدارة في آن واحد. بفضل الضوابط المدركة للرموز، والاستهداف الدقيق، والسياسات الواضحة المستندة إلى YAML، يمكن للفرق توسيع نطاق استخدام نماذج اللغة الكبيرة (LLM) بثقة مع الحفاظ على التحكم في البنية التحتية والتكلفة.
كيفية تطبيق التكوين
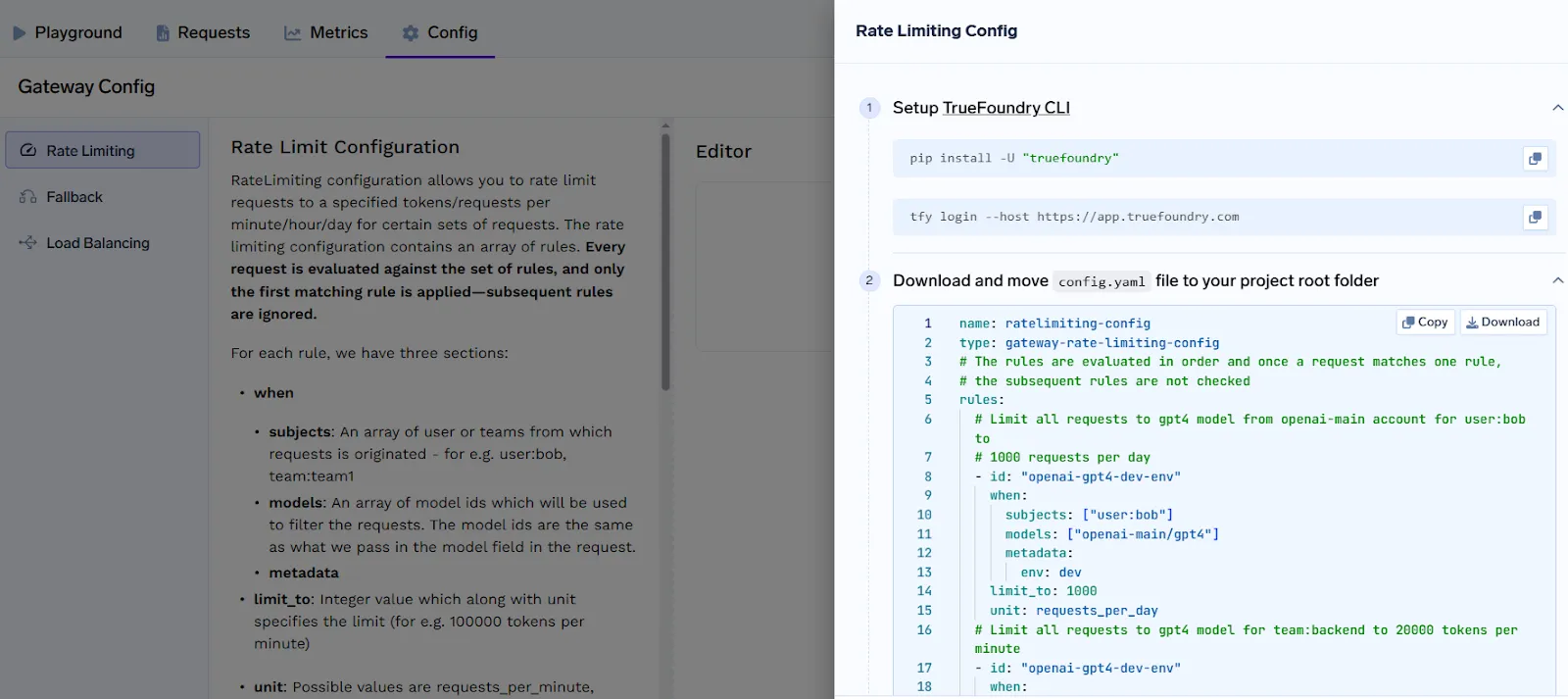
1. قم بتثبيت TrueFoundry CLI:
pip install -U "truefoundry"
tfy login --host https://app.truefoundry.com
2. ضع ملف config.yaml الخاص بك في دليل مشروعك.
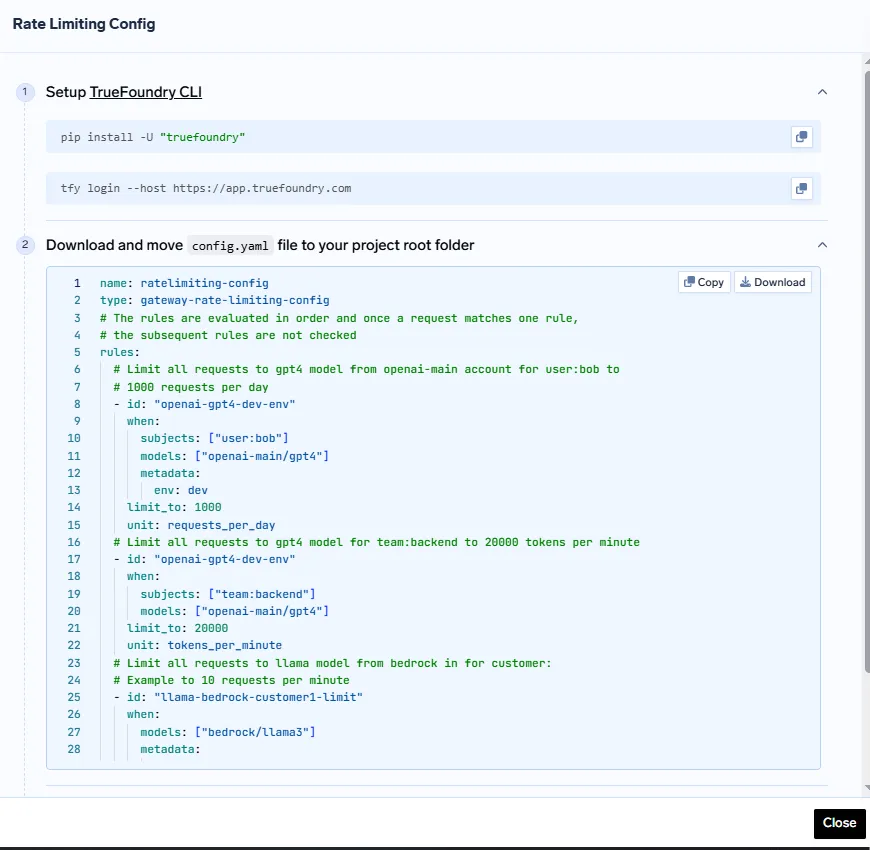
3. طبق التكوين باستخدام:
tfy apply -f config.yaml
يضمن هذا النهج التصريحي أن تكون حدود المعدل خاضعة للتحكم في الإصدار، وقابلة للتكرار، ومتوافقة مع أفضل ممارسات GitOps.
ملاحظات فورية حول حدود المعدل
تم تصميم نظام تحديد المعدل في TrueFoundry لتوفير ملاحظات فورية وشفافة للعملاء عندما يتم تجاوز الحدود أو اقترابها من الاستنفاد. يساعد هذا المطورين على فهم حدود الاستخدام والتعامل مع التقييد بسلاسة في تطبيقاتهم.
عندما يتجاوز طلب ما حد المعدل المحدد:
تدعم آلية الملاحظات هذه سلوكًا أفضل للعميل، وتتيح منطق إعادة المحاولة التلقائي، وتضمن بقاء الاستخدام ضمن حدود الحصص دون تخمين.
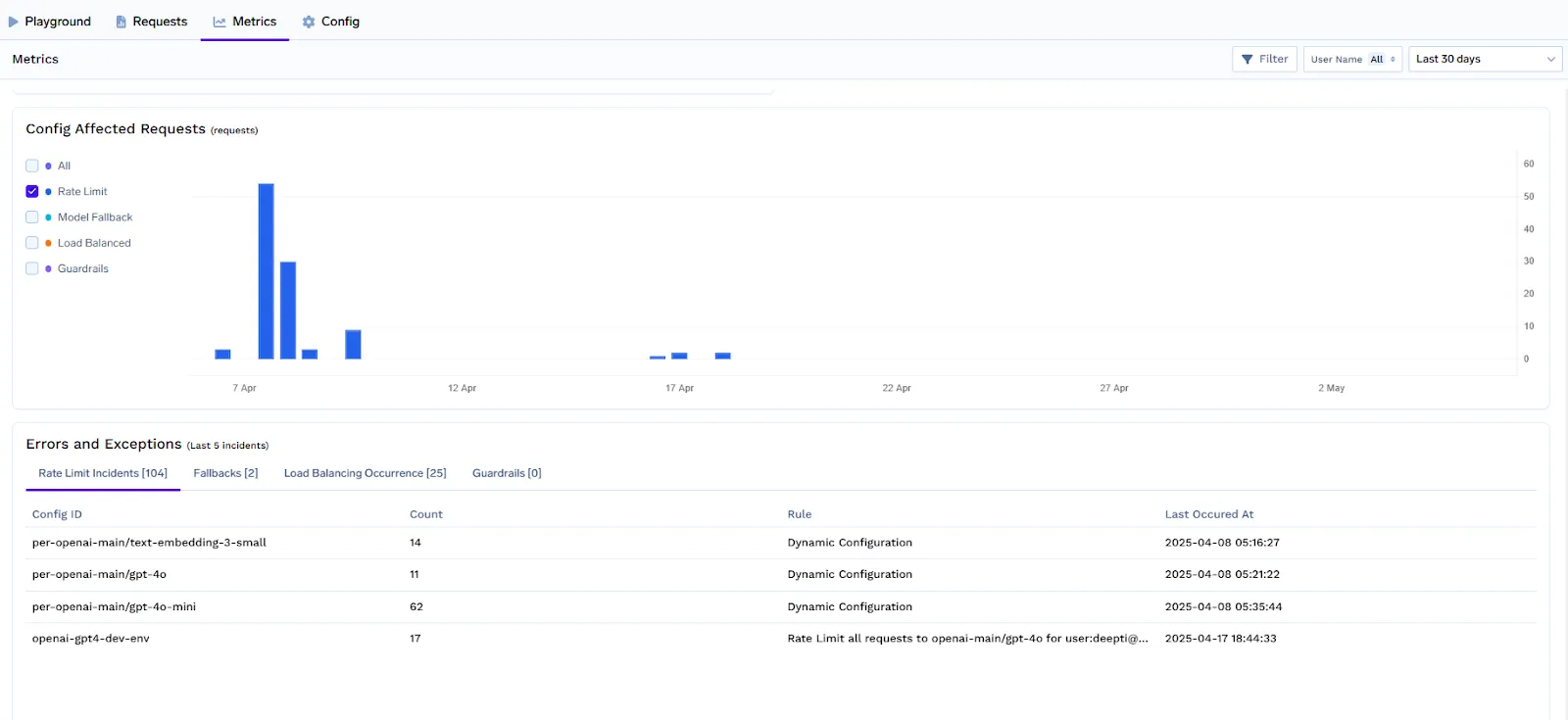
لوحات المعلومات والتنبيهات
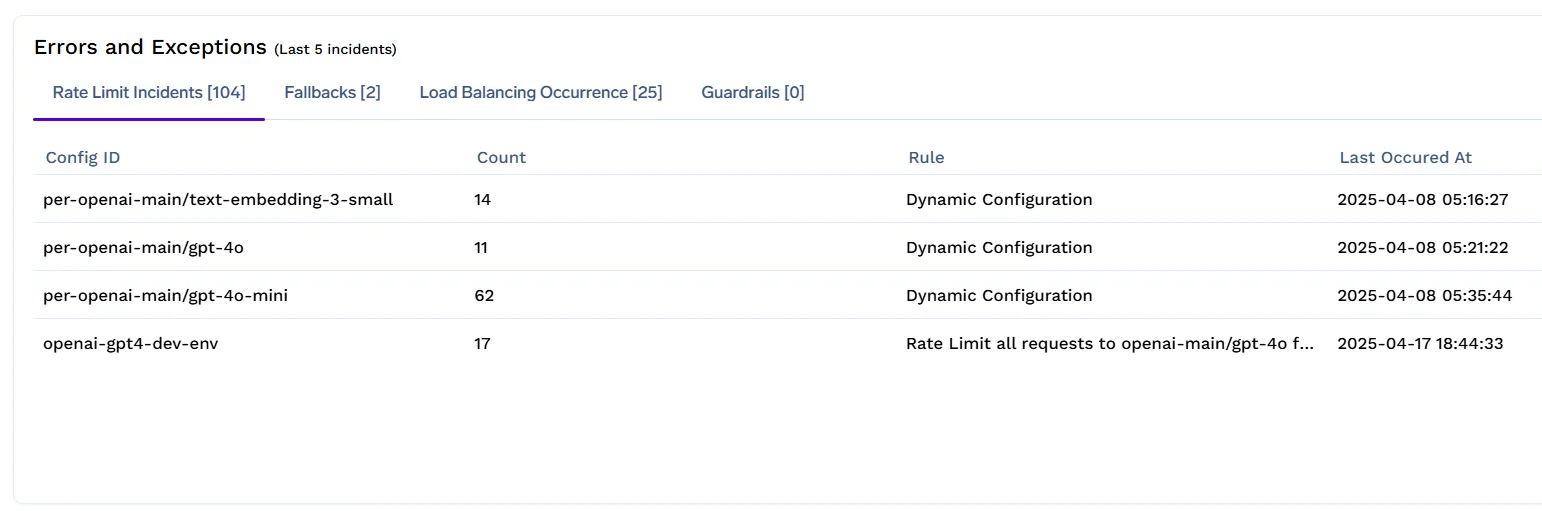
يوفر TrueFoundry إمكانية مراقبة مدمجة لمساعدة فرق المنصة على مراقبة وتحسين سياسات حدود المعدل في الوقت الفعلي.
باستخدام لوحة معلومات LLM Gateway، يمكنك تتبع:
تساعد هذه الرؤى في اكتشاف إساءة الاستخدام، وتعديل الحدود بشكل استباقي، وضمان حصول المستخدمين ذوي القيمة العالية على خدمة متسقة.
عندما تفشل واجهات برمجة تطبيقات نماذج اللغة الكبيرة (LLM APIs)، سواء بسبب حدود المعدل، أو الأخطاء الداخلية، أو الانقطاعات المؤقتة، تحافظ آليات الاسترجاع على تشغيل تطبيقاتك بسلاسة. بدلاً من إرجاع الأخطاء للمستخدم النهائي، يمكن لـ TrueFoundry توجيه الطلب تلقائيًا إلى نموذج أو مزود احتياطي، مما يحافظ على التوفر بأقل قدر من التعطيل.
يتم تفعيل قواعد الاسترجاع بناءً على شروط محددة مثل معرف النموذج، أو المستخدم أو الفريق الطالب، ورموز الاستجابة مثل 429 أو 500. عندما يفي الطلب بهذه الشروط، يتم توجيهه إلى نموذج بديل واحد أو أكثر محدد في إعدادات الاسترجاع. يمكن أن تتضمن أهداف الاسترجاع هذه اختياريًا تجاوزات للمعلمات مثل درجة الحرارة (temperature) أو الحد الأقصى للرموز (max tokens)، مما يسمح بضبط السلوك بدقة اعتمادًا على مزود النموذج. يتم تطبيق القاعدة المطابقة الأولى فقط أثناء التقييم، مما يضمن معالجة الأخطاء بشكل يمكن التنبؤ به وحتمي.
تتضمن قاعدة الاسترجاع النموذجية في TrueFoundry المكونات التالية:
مثال على إعدادات الاسترجاع:
الاسم: model-fallback-config
النوع: gateway-fallback-config
# يتم تقييم القواعد بالترتيب. بمجرد أن يتطابق طلب مع قاعدة واحدة، لا يتم التحقق من القواعد اللاحقة.
القواعد:
# الاسترجاع إلى gpt-4 على Azure أو AWS إذا فشل openai-main/gpt-4 برمز 500 أو 503.
# هدف openai-main يتجاوز أيضًا بعض معلمات الطلب مثل درجة الحرارة والحد الأقصى للرموز.
- معرف: "openai-gpt4-fallback"
عندما:
النماذج: ["openai-main/gpt4"]
رموز_حالة_الاستجابة: [500, 503]
النماذج_الاحتياطية:
- الهدف: openai-main/gpt-4
تجاوز_المعلمات:
درجة_الحرارة: 0.9
الحد_الأقصى_للرموز: 800
# الرجوع إلى LLaMA3 على Azure أو AWS إذا فشل bedrock/llama3 برمز 500 أو 429 للعميل customer1.
- معرف: "llama-bedrock-customer1-fallback"
عندما:
النماذج: ["bedrock/llama3"]
البيانات_الوصفية:
معرف_العميل: customer1
رموز_حالة_الاستجابة: [500, 429]
النماذج_الاحتياطية:
- الهدف: aws/llama3
- الهدف: azure/llama3
تدعم بوابة LLM من TrueFoundry أصلاً إعداد الاستعادة التصريحي كجزء من نظام التكوين الخاص بها. يتيح ذلك للفرق تحديد سياسات توجيه مقاومة للأخطاء والحفاظ على وقت التشغيل دون تدخل يدوي، خاصة عند العمل مع مزودين متعددين. معًا، يضع تحديد المعدل الذكي والاستعادة التلقائية الأساس لخدمات الذكاء الاصطناعي التوليدي عالية التوفر.
في أي منصة ذكاء اصطناعي متعددة المستأجرين، يعد تحديد المعدل أمرًا بالغ الأهمية لضمان الاستقرار والإنصاف وحوكمة التكاليف. يسمح للفرق بتحديد حدود الوصول ليس فقط للمستخدمين الفرديين ولكن أيضًا عبر الفرق والحسابات الافتراضية والنماذج المحددة دون الحاجة إلى منطق مخصص.
تدعم بوابة TrueFoundry تحديد المعدل التصريحي عبر تكوين YAML، حيث يتم تقييم القواعد بالترتيب. يتم تطبيق القاعدة المطابقة الأولى، مما يعني أنه يجب وضع القواعد الأكثر تحديدًا في الأعلى، بينما يجب وضع القواعد الأكثر عمومية في الجزء السفلي من التكوين. يضمن هذا الهيكل تحكمًا طبقيًا مع الحفاظ على تكوينات نظيفة وسهلة القراءة.
يمكن أن تتضمن كل قاعدة المكونات التالية:
أمثلة على تحديد المعدل متعدد المستأجرين
تحديد طلب مستخدم معين: لنفترض أنك تريد تحديد جميع الطلبات إلى نموذج gpt4 من حساب openai-main للمستخدمين bob@email.com و jack@email.com بـ 1000 طلب يوميًا:
- id: "user-gpt4-limit"
when:
subjects: ["user:bob@email.com", "user:jack@email.com"]
models: ["openai-main/gpt4"]
الحد_الأقصى: 1000
الوحدة: طلبات_في_اليوم
تطبيق حدود على مستوى الفريق: إذا كنت ترغب في تقييد العدد الإجمالي للطلبات لفريق 'frontend' إلى 5000 طلب في اليوم
- المعرف: "team-frontend-limit"
عند:
المواضيع: ["team:frontend"]
الحد_الأقصى: 5000
الوحدة: طلبات_في_اليوم
تقييد الحسابات الافتراضية: إذا كنت ترغب في تحديد سقف لعدد الطلبات للحساب الافتراضي 'va-james' عند 1500 طلب في اليوم
- المعرف: "va-james-limit"
عند:
المواضيع: ["virtualaccount:va-james"]
الحد_الأقصى: 1500
الوحدة: طلبات_في_اليوم
تعيين حدود عالمية لجميع المستخدمين والنماذج:
- المعرف: "{user}-{model}-daily-limit"
عند: {}
الحد_الأقصى: 1000000
وحدة: الرموز_يوميًا
يتيح هذا الإعداد لفرق المنصة تقسيم الاستخدام عبر وحدات الأعمال، وفرض حصص لكل بيئة، وحماية نقاط نهاية النماذج باهظة الثمن مع دعم أعباء عمل الذكاء الاصطناعي القابلة للتطوير والموثوقة.
تحديد المعدل هو أكثر من مجرد تحكم في الواجهة الخلفية. إنه عامل تمكين حاسم للاستخدام الموثوق به والفعال من حيث التكلفة والعادل للبنية التحتية لنماذج اللغة الكبيرة (LLM) على نطاق واسع. سواء كنت تدير منصة متعددة المستأجرين، أو تقدم وصولاً متعدد المستويات للعملاء، أو تدير أعباء عمل ذكاء اصطناعي داخلية عبر الفرق، فإن تطبيق حدود معدل ذكية ومدركة للرموز يضمن بقاء نظامك قابلاً للتنبؤ به تحت الضغط.
إلى جانب تحديد المعدل، تمنح ميزات مثل التوجيه الاحتياطي، والملاحظات في الوقت الفعلي، والتكوين الدقيق فرق الهندسة الأدوات اللازمة للموازنة بين الأداء والتحكم. تجمع بوابة LLM من TrueFoundry هذه الإمكانيات مع واجهة تعريفية، مما يسمح لفرق المنصة بتحديد سياسات شفافة وقابلة للتدقيق ومتوافقة مع الأهداف التنظيمية.
مع تسارع تبني الذكاء الاصطناعي التوليدي، ستحدد الأنظمة التي تفرض تحكمًا ذكيًا في الوصول دون التضحية بتجربة المستخدم أو وقت التشغيل الجيل القادم من مرونة البنية التحتية. إذا كنت تقوم ببناء أو توسيع بوابة ذكاء اصطناعي، فإن تحديد المعدل ليس مجرد شيء يجب أخذه في الاعتبار. إنه شيء يجب إتقانه من اليوم الأول.
يشير تحديد المعدل في بوابة LLM إلى الآلية المستخدمة للتحكم في تكرار الطلبات الواردة أو حجم الرموز التي يمكن لمستخدم أو فريق أو تطبيق معالجتها ضمن نافذة زمنية محددة. على عكس تقييد واجهة برمجة التطبيقات التقليدي، فإنه يدرك الرموز ويأخذ في الاعتبار العبء الحسابي الفعلي لبنى النماذج المختلفة، مما يضمن أن الاستعلامات كثيفة الموارد لا تتسبب في تعطل النظام.
يساعد تطبيق تحديد المعدل في بيئات بوابة LLM على التحكم في التكاليف عن طريق منع الارتفاعات غير المتوقعة في استهلاك الرموز والبرامج النصية الجامحة. من خلال تحديد حصص يومية أو ساعية دقيقة، يمكن للمؤسسات تحديد سقف للإنفاق للمستخدمين المحددين أو بيئات غير الإنتاج، مما يضمن بقاء تجارب الذكاء الاصطناعي ضمن ميزانية يمكن التنبؤ بها مع الحماية من مفاجآت الفواتير باهظة الثمن.
يعد تحديد المعدل في إعدادات بوابة LLM ضروريًا لحماية البنية التحتية من سوء الاستخدام وضمان التوافر العالي لجميع المستخدمين. يمنع "الجار المزعج" الواحد من استنفاد حصص المزود أو سعة وحدة معالجة الرسوميات (GPU)، مما قد يؤدي بخلاف ذلك إلى زيادة زمن الوصول وأخطاء "طلبات كثيرة جدًا" (429) المتكررة. تعد طبقة الإدارة هذه حاسمة للحفاظ على اتفاقيات مستوى الخدمة (SLAs) المستقرة في بيئات الإنتاج.
تشمل الاستراتيجيات الشائعة لتحديد المعدل في بوابة LLM حدود الطلبات في الدقيقة (RPM) والرموز في الدقيقة (TPM)، والتي توفر قياسًا دقيقًا لاستخدام الموارد. تدعم البوابات المتقدمة أيضًا حدودًا متعددة المستويات بناءً على أدوار المستخدمين أو أنواع النماذج، مما يسمح للمهام الحيوية بالحصول على أولوية أعلى بينما يتم تقييد أعباء عمل التطوير ذات الأولوية المنخفضة خلال فترات الازدحام.
بينما يضيف خطوة معالجة صغيرة، فإن تحديد المعدل في بوابة LLM عادةً ما يضيف أقل من 4 مللي ثانية من الحمل الزائد، وهو أمر لا يذكر مقارنة بالثواني اللازمة لتوليد النموذج. في الواقع، غالبًا ما يحسن زمن الوصول المتصور عن طريق منع قوائم الانتظار الخلفية من التشبع، مما يضمن معالجة الطلبات بسلاسة دون التسبب في مهلات أو أعطال في الخدمة.
نعم، توفر TrueFoundry تطبيقًا جاهزًا للإنتاج لتحديد المعدل في بوابة LLM من خلال تكوين تعريفي قائم على القواعد. يسمح للفرق بفرض حدود مدركة للرموز عبر العديد من موفري النماذج والمستأجرين باستخدام ملفات YAML بسيطة. يوفر هذا النظام ملاحظات في الوقت الفعلي ولوحات معلومات مفصلة، مما يمكن فرق المنصة من توسيع نطاق أعباء عمل الذكاء الاصطناعي مع الحفاظ على حوكمة صارمة للتكلفة والموارد.
يعمل تحديد معدل الذكاء الاصطناعي عن طريق تتبع عدد مرات إرسال المستخدم للطلبات إلى واجهة برمجة تطبيقات الذكاء الاصطناعي. يقوم النظام بحساب الطلبات أو الرموز ضمن فترة زمنية محددة. إذا تجاوز المستخدم الحد المسموح به، تقوم واجهة برمجة التطبيقات بحظر الطلبات الجديدة مؤقتًا أو تُرجع خطأ حتى يتم إعادة تعيين الحد. هذا يحمي الخوادم من التحميل الزائد.
بالتأكيد. من خلال تحديد سقف لاستخدام الرموز ومعدلات الطلبات، تمنع البوابات الاستخدام المفرط غير المتوقع لوحدات معالجة الرسوميات (GPU) أو الإنفاق السحابي. يمكن للمؤسسات مواءمة الاستخدام مع الميزانيات، والتخطيط للوصول المتدرج، وتقليل التوفير الزائد المكلف مع الحفاظ على خدمة متسقة لأعباء العمل الحيوية.
نعم. تسمح بوابات الذكاء الاصطناعي الحديثة مثل TrueFoundry للفرق بتحديث قواعد تحديد المعدل في الوقت الفعلي أو عبر نصوص برمجية مؤتمتة، مما يضمن قدرة البنية التحتية على التعامل مع الارتفاعات المفاجئة دون توقف أو تدهور في الأداء. تحافظ التعديلات الديناميكية على استجابة الخدمة مع الحفاظ على الاستخدام العادل عبر المستأجرين.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
