




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
A 2026 application doesn't talk to one model — it talks to a menu of them, spanning frontier, mid-tier, cheap, and self-hosted. Routing is the policy that picks one per request, navigating three goals that pull against each other: cost, latency, and quality. This post walks the routing strategies from static rules to semantic routing and model cascades, the hard problem of measuring the quality you want to route on, why routing is not failover, and the instrumentation that keeps a router from quietly betraying you.
Tuesday at Northwind. Omar, a platform engineer, had spent the quarter proud of one number: a 41% drop in the company's LLM bill. He'd built a router. Simple classification and intent-detection calls went to a cheap model; only the genuinely hard requests — multi-step reasoning, code generation — reached the frontier model. It worked. Finance noticed.
Then the second week's bill came in at three times the first week's, with no traffic increase. Omar traced it. His cascade had a verifier — the cheap model's output was schema-checked, and on a failed check the request escalated to the frontier model. A provider-side update had subtly changed the cheap model's output formatting, the schema check started failing on most responses, and the router had quietly escalated about 90% of traffic to the most expensive model. Nothing errored. Nothing alerted. The router did exactly what it was told; it just stopped doing what Omar meant. The escalation rate had been climbing for nine days, and nobody was watching it.
Routing is often one of the highest-leverage cost levers in an LLM stack and one of the easiest to get quietly wrong. This post is the strategies, their tradeoffs, and the instrumentation that keeps a router honest.
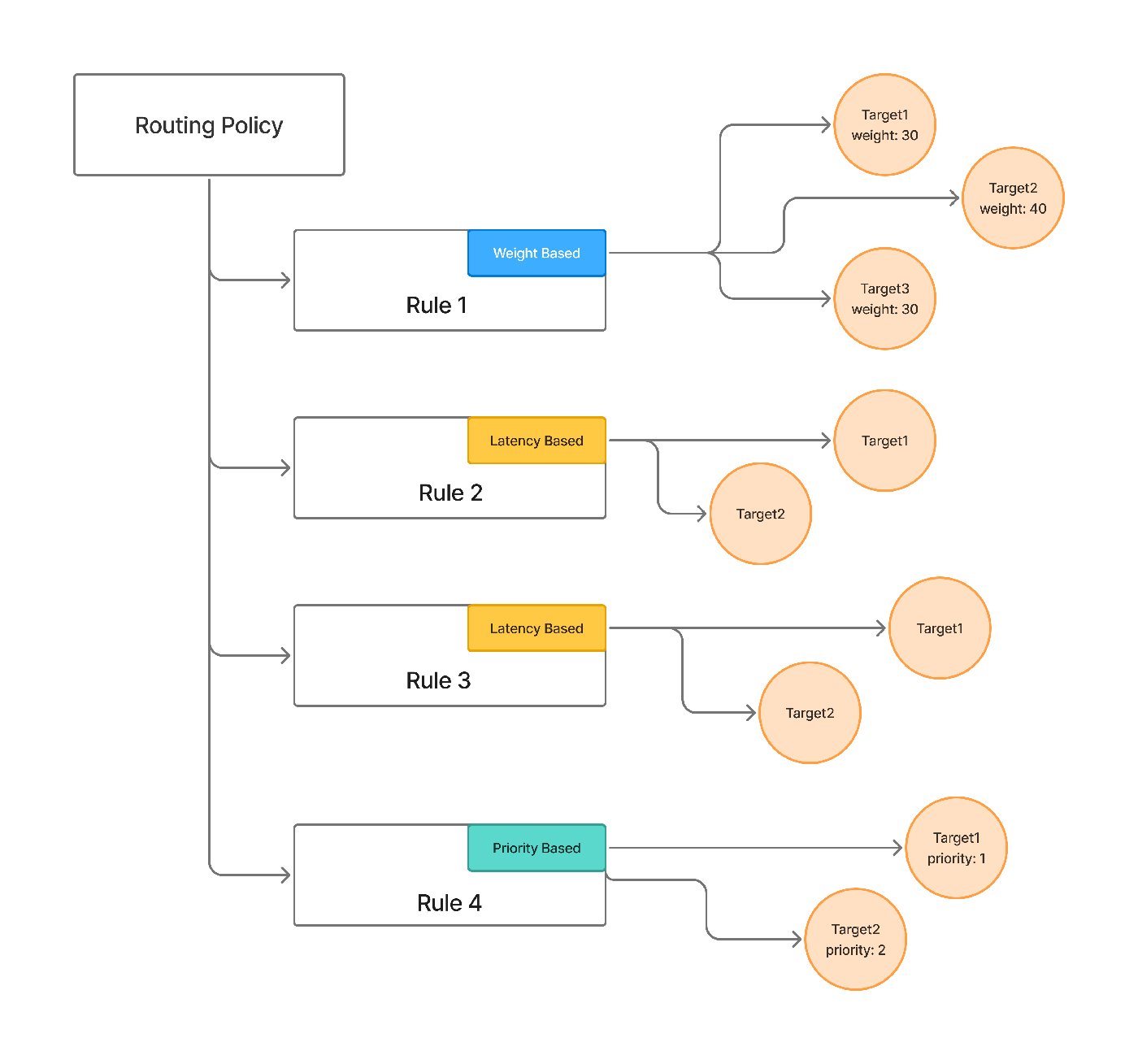
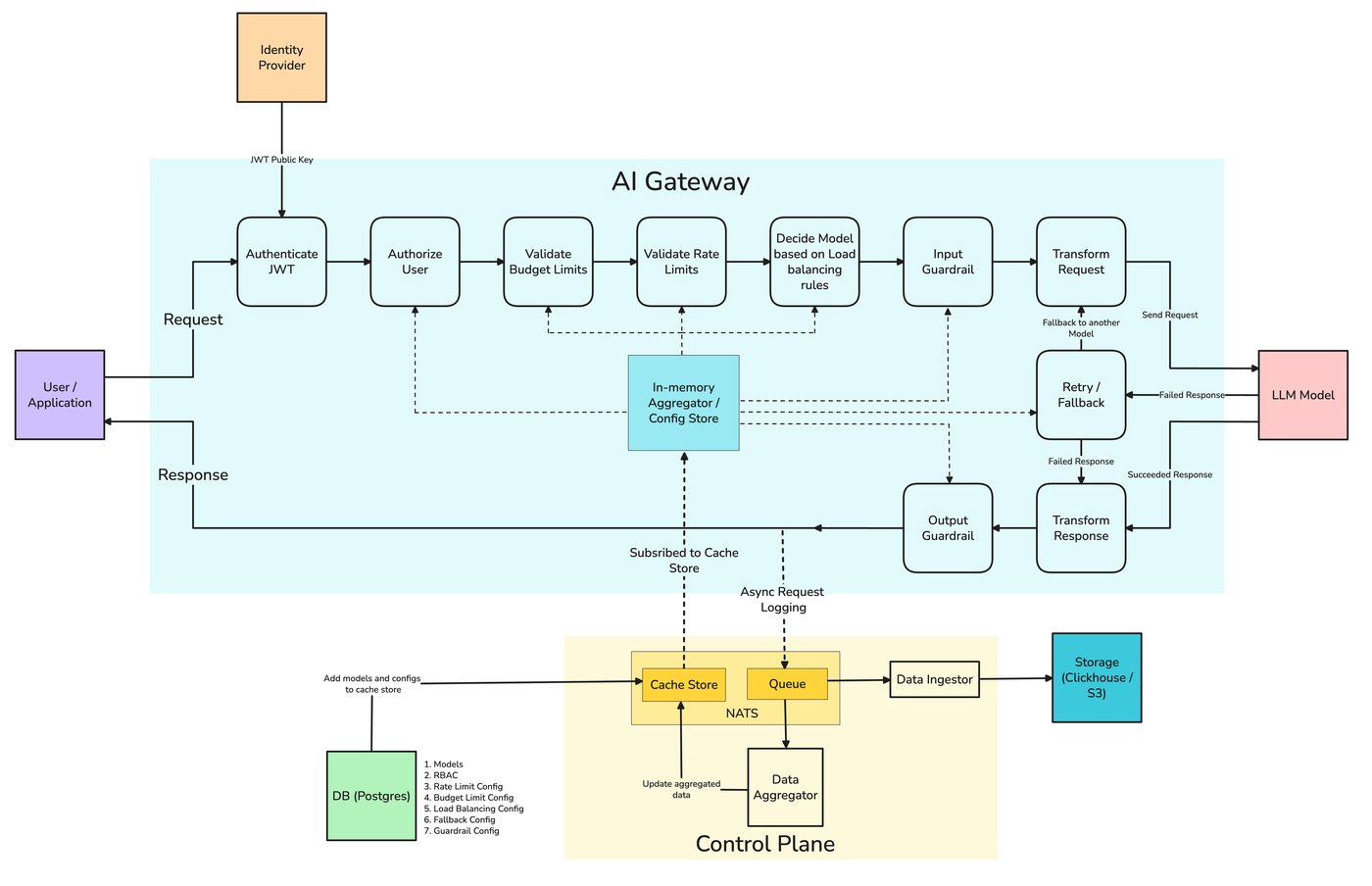
The routing strategies in this post aren't abstractions — they're how TrueFoundry's AI Gateway is configured. Its routing configuration matches each request by model, by subject (user, team, or virtual account), or by an X-TFY-METADATA header, evaluates rules top-to-bottom with first-match-wins, and sends the request to a target model — all as YAML applied at the gateway rather than branching logic in the app.
The three strategies map onto the ladder in section 2: weight-based for splits and canaries, latency-based to favor the lowest-latency healthy target, and priority-based for ordered preference with fallback. Per-target overrides also cover the model-specific-prompt problem this post raises — you can attach a different prompt_version_fqn per target so each model gets a prompt tuned for it — alongside per-target retries and fallback. (For new setups the docs recommend Virtual Models, which package the same strategies, retries, and fallbacks with clearer per-model ownership and access control.)
Calling the gateway from an application is a one-line change for anything already using the OpenAI SDK — same client, different base URL and key — and the routing decision happens at the gateway, not in your code. The application can also pass an X-TFY-METADATA header so the gateway routes by task, environment, or tenant without conditional code paths:
Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="assistant", # logical/virtual model — gateway picks the target
extra_headers={"X-TFY-METADATA": '{"task": "classify"}'}, # drives the matching rule
messages=[{"role": "user", "content": "..."}],
)An enterprise app in 2026 has a menu of models with very different economics. Cheap models (Claude Haiku 4.5 at roughly $1 per million input tokens) are several times less expensive than frontier models on current standard rates, and often lower-latency in practice. Mid-tier models (Sonnet 4.6 at $3 per million input) sit in between. Self-hosted open-weight models (Llama, Mistral) trade per-token pricing for fixed GPU capacity and data control — cheaper at sustained high utilization, but expensive when utilization is low. Each model also has a different quality profile per task: a model that's excellent at code may be mediocre at extraction, and vice versa.
Routing is the policy that maps each incoming request to one of these models. The three goals pull against each other: the cheapest model is rarely the highest-quality, the fastest is not always the cheapest, and the best-quality model for a hard task is wasted on an easy one. The naive default — send everything to the best frontier model — maximizes quality but is the most expensive option and frequently the slowest, applying a multi-step reasoning model to requests a cheap model would answer correctly in a fraction of the time and cost. Routing is where that cost/quality frontier gets navigated, one request at a time.
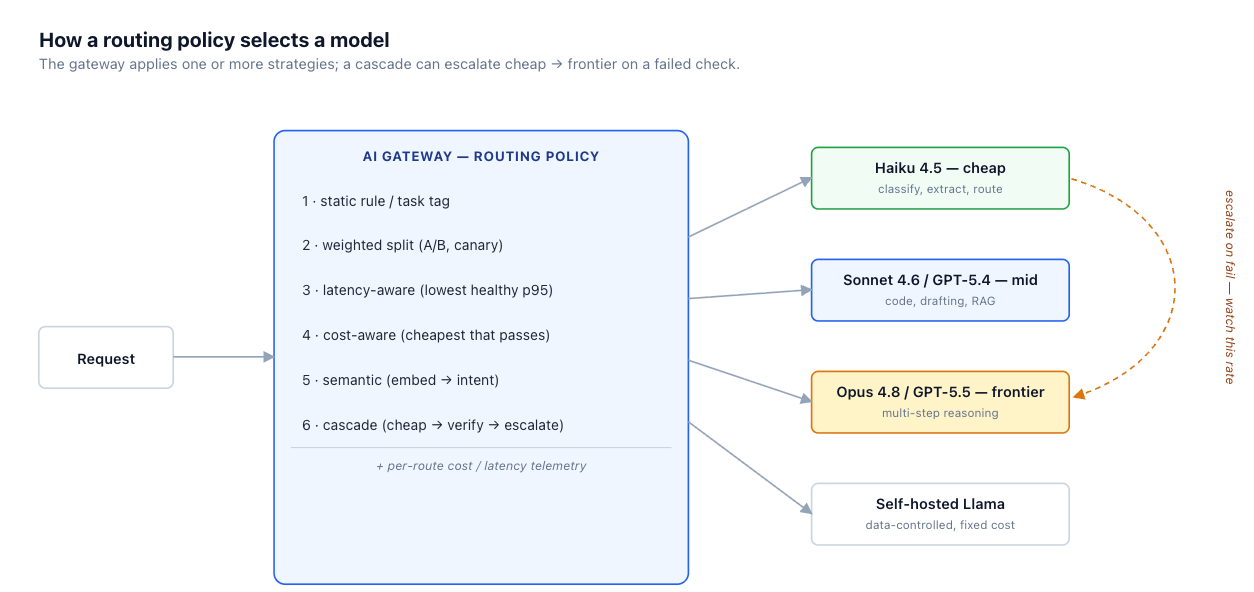
Routing strategies form a ladder. Each rung adds capability and cost, and the right place to stop is wherever the measured benefit stops justifying the added complexity.
Static / rule-based. Route by endpoint, header, or a task tag the caller sets — classification goes to the cheap model, code generation to the mid-tier. Sub-millisecond, deterministic, and trivially debuggable. This works whenever the caller already knows the task type, which is more often than teams assume.
Weighted / load-balanced. Split traffic by percentage across models. This is the basis for A/B testing a new model and for canary rollouts — send 5% of traffic to the new model, watch the metrics, ramp if they hold.
Latency-aware. When several models are acceptable for a request, route to the one with the lowest healthy p95 right now. Useful for latency-sensitive paths where any of a few models would do.
Cost-aware. Pick the cheapest model that clears a quality bar for the task. This requires knowing the quality bar per task (section 5), which is the hard part.
Be careful what "cheapest" means: route on total request cost, not the nominal input-token rate. The real figure is expected input tokens plus expected output tokens, adjusted for cache-hit rate, retry and hedge probability, cascade escalation probability, and any regional, priority, or fast-mode multiplier. Tokenizers differ across families too — Anthropic notes that Opus 4.7 and later can emit up to 35% more tokens for the same text — so an identical prompt produces different billable counts on different models. Estimate route cost from real traces, not by copying a rate card into a static table.
The last two rungs — semantic routing and model cascades — get their own sections. Most production routers are a blend: static rules for known task tags, a cost- or latency-aware default for everything else, and a separate fallback list for availability. The config below is illustrative; the exact schema is gateway-specific.
Illustrative routing policy (conceptual — exact schema is gateway-specific)
routes:
- match: { header: "x-task", equals: "classify" }
target: claude-haiku-4-5 # cheap tier
- match: { header: "x-task", equals: "code" }
target: claude-sonnet-4-6
- default:
strategy: cost_aware # cheapest model that passes the task's quality bar
candidates: [claude-sonnet-4-6, gpt-5.4]
fallback: [gpt-5.5] # availability, NOT optimization — see section 6Here's how the ladder above looks in TrueFoundry's AI Gateway, which is where these strategies actually run. Routing is a YAML gateway-load-balancing-config: each rule matches a slice of traffic — by model, team, or an X-TFY-METADATA header — and routes across its targets using weight-based, latency-based, or priority-based selection. Adding a model or shifting a split is a config change, not a redeploy:
How TrueFoundry expresses these strategies (gateway-load-balancing-config)
name: routing-config
type: gateway-load-balancing-config
rules:
- id: classify-to-cheap # static task tag -> cheap tier
type: weight-based-routing
when:
models: [assistant]
metadata: { task: classify }
load_balance_targets:
- target: anthropic/claude-haiku-4-5
weight: 100
- id: default-lowest-latency # everything else -> fastest healthy target
type: latency-based-routing
when:
models: [assistant]
load_balance_targets:
- target: anthropic/claude-sonnet-4-6
- target: openai/gpt-5.4Each target can also carry retries, a fallback list, and even a per-target prompt (prompt_version_fqn) so each model gets a prompt tuned for it. Because one file expresses both the routing policy and the fallback chain, the two stay distinct and separately observable — the line section 6 draws. The full schema is in the routing config docs.
The same file handles a canary rollout — the weighted-split pattern this post recommends for A/B-ing a new model — with no app-side branching:
Canary rollout with weight-based routing (from the docs)
name: loadbalancing-config
type: gateway-load-balancing-config
rules:
- id: gpt4-canary
type: weight-based-routing
when:
models: [gpt-4]
load_balance_targets:
- target: azure/gpt4-v1
weight: 90
- target: azure/gpt4-v2
weight: 10A few TrueFoundry-specific levers worth flagging for the routing decisions in this post: Virtual Models are the gateway's recommended replacement for the global routing config — they package the same weight/latency/priority strategies, retries, and fallbacks behind a single logical model name with its own access control, so a route can be promoted or swapped without changing every caller. Exact and semantic caching sit in front of the routing decision and return a stored response for repeat queries, cutting both cost and tail latency on read-heavy workloads. And the same routing config matches on X-TFY-METADATA, so one rule file can serve dev/prod and per-tenant routing — the routing layer reads what the client sent rather than the client encoding the route choice.
Static tags assume the caller knows the task. Sometimes it doesn't — a general assistant exposes one endpoint and everything arrives there. Semantic routing infers the task from the request itself: embed the prompt, find the nearest intent centroid (or run a small classifier), and route by the inferred intent.
Semantic routing — embed the request, route by nearest intent
emb = embed(req.text) # ~5–20 ms, small per-call cost
intent = nearest_centroid(emb, centroids) # e.g. "sql", "summarize", "chat", "reason"
model = ROUTING_TABLE.get(intent, DEFAULT) # intent -> specialized modelThe cost is an embedding call (roughly 5–20 ms and a small per-token charge) plus a cheap classifier step. The thing to be honest about is when this earns its keep: only when intent isn't already known at the call site. If the calling code can set a header like x-task=classify, that is free, deterministic, and better. Semantic routing belongs at the front door of a general assistant where requests are unlabeled — not bolted onto an internal pipeline that already knows what each call is for. The downsides: centroids and classifiers drift as the product's intents change and need maintenance, and a misclassification routes to the wrong model — so a semantic router still needs a sane default and a fallback. Wherever the embed-and-classify step runs, the gateway is the natural place to record the inferred intent and the model it selected on the trace, which is the per-route visibility TrueFoundry's AI Gateway already provides for the simpler strategies — and what turns a misroute into something debuggable rather than invisible.
A cascade tries a cheap model first, checks the result, and escalates to a stronger model only if the check fails. The check can be schema validation (does the output parse against the expected structure?), a confidence or self-consistency signal, or a judge model.
Cheap-first cascade with schema verification
def answer(req):
draft = call_model("claude-haiku-4-5", req)
if schema_ok(draft) and confident(draft):
return draft, "haiku"
# Escalate — but COUNT it. A rising escalation rate is a cost incident.
metrics.incr("router.escalation")
return call_model("gpt-5.5", req), "gpt-5.5"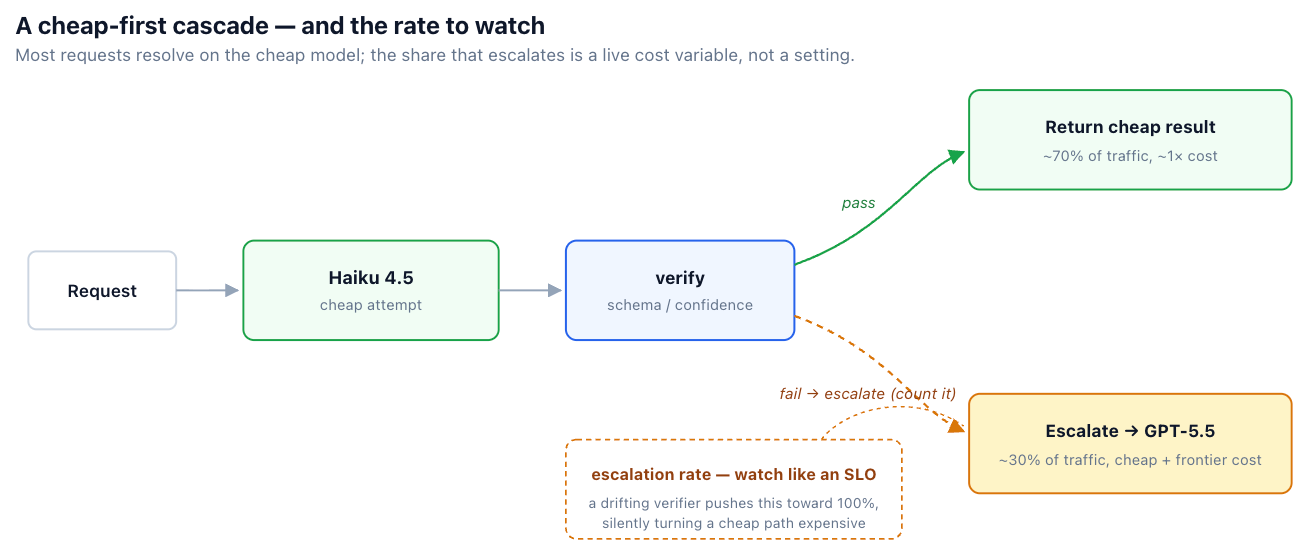
The economics can be compelling. If the cheap tier resolves most requests, blended cost falls toward the cheap tier's price. As an illustrative model: at the roughly 5× standard-rate gap between Haiku and the named frontier models, a 70% cheap-resolution rate brings blended cost to about half of frontier-everywhere — even after paying for the cheap attempt on the 30% that escalate. (Widen the gap to 10×, as some premium, pro, or priority tiers do, and the same cascade lands nearer 40%.) The exact savings depend on your resolution rate and the real price gap, so measure them rather than assuming them.
A cascade also adds the cheap model's latency to every escalated request — you pay the cheap call's time, then the frontier call's time. For interactive, latency-sensitive paths that double hop can be the wrong tradeoff; cascades shine on throughput-oriented or asynchronous workloads where the blended-cost win outweighs the tail latency on escalations.
Routing on cost or latency is straightforward because both are directly observable. Routing on quality is harder, because quality has to be measured before it can be optimized. Three approaches, in increasing order of fidelity and cost:
Offline eval sets. A curated, labeled set per task type. Run each candidate model against it and build the routing table from the results — this model for SQL, that one for summarization. Cheap to run repeatedly, but only as representative as the eval set.
نموذج لغوي كبير كحَكَم عبر الإنترنت. خذ عينة من حركة المرور الإنتاجية وقيّم الاستجابات باستخدام نموذج حَكَم. هذا أقرب إلى التوزيع الحقيقي، لكنه يضيف تكلفة ووقت استجابة، والحَكَم نفسه عرضة للخطأ — فالحَكَم الذي يشارك النقاط العمياء للمولّد سيوافق عليها دون تمحيص.
اختبار A/B مقابل مقاييس الأعمال. المعيار الذهبي: وجّه جزءًا من حركة المرور إلى مرشح وقم بقياس المقياس الذي تهتم به حقًا — معدل الحل، الإعجابات، التحويل اللاحق. إنه بطيء ويتطلب جهدًا كبيرًا، لكنه يقيس الشيء نفسه بدلاً من مؤشر بديل.
التحذير الذي يربط هذه الأمور معًا: لا توجه بناءً على الانطباعات. فالنموذج الرخيص الذي "يبدو جيدًا" في عرض توضيحي يمكن أن يؤدي بهدوء إلى تدهور مقياس لاحق لأسابيع. اربط كل تغيير في التوجيه ببوابة جودة مقاسة، وتذكر أن الجودة خاصة بالمهمة — فترتيب واحد في لوحة الصدارة ليس جدول توجيه، لأن النموذج الذي يتصدر معيارًا عامًا قد يكون متوسطًا في مهمة الاستخراج الخاصة بك. إشارة الإنتاج التي تحتاجها جميع الطرق الثلاث — أي نموذج تعامل مع أي طلب، وماذا حدث بعد ذلك — هي ما تسجله البوابة بالفعل؛ تتبع TrueFoundry لكل مسار هو مصدر طبيعي لمجموعات التقييم غير المتصلة بالإنترنت وأخذ العينات عبر الإنترنت المذكور أعلاه.
أمر واحد يجب أن تتعامل معه جميع الطرق الثلاث: موجه الإنتاج يرى فقط النموذج الذي اختاره. وجّه طلبًا إلى Haiku ولن تعرف أبدًا ما إذا كان Sonnet أو Opus أو GPT-5.5 كان سيؤدي بشكل أفضل — فالنقيض الافتراضي غير مرئي. للحفاظ على مصداقية جدول التوجيه، خذ عينة من حركة المرور للتقييم الخفي، أو أعد تشغيل الطلبات الحقيقية عبر المرشحين الآخرين دون اتصال بالإنترنت، أو قم بإجراء اختبارات البطل/المنافس الدورية. بدون ذلك، يستغل الموجه بهدوء سياسة قديمة ويتوقف عن ملاحظة متى أصبح نموذج آخر أفضل أو أرخص أو أكثر أمانًا لمهمة ما.
يتشارك التوجيه وتجاوز الفشل في الآلية — قائمة بالنماذج المرشحة وسياسة للاختيار من بينها — مما يجعل من السهل الخلط بينهما. إنهما هدفان مختلفان، ودمجهما يسبب حوادث.
التوجيه هو تحسين: عندما تكون جميع المرشحات سليمة، اختر الأفضل من حيث التكلفة أو وقت الاستجابة أو الجودة. تجاوز الفشل هو التوفر: عندما يكون النموذج المختار معطلاً أو يتجاوز المهلة، ارجع إلى آخر لكي يظل الطلب ناجحًا (موضوع المنشور التالي في هذه السلسلة). هذا التمييز مهم من الناحية التشغيلية. قد يؤدي الرجوع إلى نموذج أرخص بسبب انقطاع الخدمة إلى تدهور الجودة بصمت، وتريد أن يتم تسجيل ذلك على أنه "عدنا إلى نموذج احتياطي لأن الأساسي كان معطلاً"، لا أن يُساء فهمه كقرار تكلفة متعمد. على العكس، يجب أن يؤدي خطأ 500 العابر إلى تجاوز الفشل، وليس تغييرًا دائمًا في التوجيه. حافظ على السياسات منفصلة وقابلة للمراقبة بشكل منفصل: "تم التوجيه إلى X للتكلفة" و "تم الرجوع إلى Y لأن X كان غير سليم" هما حدثان مختلفان يجب أن يظهرا بشكل مختلف في تتبعاتك. بوابة مثل TrueFoundry هي المكان الذي يعيشان فيه جنبًا إلى جنب دون تداخل — حيث يتم تكوين سياسة التوجيه وسلسلة الرجوع الاحتياطي وتتبعها كأشياء مميزة.
يمكن أن يعيش منطق التوجيه في التطبيق، لكن البوابة هي المكان الأكثر طبيعية لسببين. أولاً، إنها توحد واجهات برمجة تطبيقات المزودين بالفعل، لذا فإن تبديل المسار من نموذج إلى آخر هو تغيير في التكوين وليس تغييرًا في الكود — والتبديل بين، على سبيل المثال، نموذج OpenAI ونموذج Anthropic لا يعني إعادة كتابة بناء الطلب. ثانيًا، إنها تحتفظ بالفعل ببيانات القياس عن بعد للتكلفة ووقت الاستجابة التي تعتمد عليها قرارات التوجيه؛ فالبيانات التي تحتاجها للتوجيه الجيد هي البيانات التي تجمعها البوابة بالفعل.
مركزة التوجيه في بوابة TrueFoundry للذكاء الاصطناعي يعني سياسة واحدة مطبقة عبر الخدمات، ومكانًا واحدًا لاختبار نموذج جديد (A/B testing)، ومكانًا واحدًا لمراقبة التكلفة المجمعة ومعدل تصعيد التسلسل الذي تم تفعيله عند البدء البارد. تعرض البوابة قواعد التوجيه، وموازنة التحميل الموزونة، وسلاسل التراجع عبر النماذج المستضافة ذاتيًا والمستضافة من خلال واجهة برمجة تطبيقات موحدة ومتوافقة مع OpenAI، وتظهر تكلفة كل مسار وزمن الاستجابة في نفس عرض الإسناد من منشور إسناد التكلفة. تجدر الإشارة بوضوح إلى تقسيم العمل: تقوم البوابة بالتوجيه وتوفر لك الأرقام؛ بينما لا يزال التطبيق يمتلك تعريف الجودة ومجموعات التقييم التي تحدد النموذج الفائز لكل مهمة.
التوجيه ليس مجانيًا، وتختلف النفقات العامة باختلاف الاستراتيجية. يتم تقييم القاعدة الثابتة في أقل بكثير من ميلي ثانية. يتطلب التوجيه المدرك لزمن الاستجابة بيانات قياس عن بعد حية (p95 telemetry)، وهي رخيصة القراءة. يضيف التوجيه الدلالي استدعاء التضمين (embedding call) — حوالي 5-20 مللي ثانية — بالإضافة إلى مصنف خفيف الوزن. يضيف التسلسل زمن الاستجابة الكامل للنموذج الرخيص في كل طلب يتم تصعيده.
المبدأ التصميمي هو إبقاء قرار التوجيه غير مكلف مقارنة باستدعاء النموذج الذي يسبقه. القاعدة التي تستغرق أقل من ميلي ثانية هي مجرد ضوضاء مقارنة بتوليد يستغرق 500 مللي ثانية أو أكثر؛ والخطوة الدلالية ميسورة التكلفة بشكل مريح عند مدخل المساعد؛ أما زمن الاستجابة المزدوج للتسلسل عند التصعيد فهو ما يجب التدقيق فيه في المسارات التفاعلية. ولا تضف استدعاء نموذج حكم (judge-model) إلى كل مسار لقياس الجودة إلا إذا كان التسلسل أو مكسب الجودة يبرر بوضوح دفع تكلفة استدعاء نموذج ثانٍ في كل طلب — عادةً ما يمنحك أخذ عينات من جزء من حركة المرور للتقييم عبر الإنترنت الإشارة المطلوبة دون ضريبة كل طلب. ولأن قرار التوجيه واستدعاء النموذج يقعان على نفس التتبع، فإن النفقات العامة للقرار نفسه قابلة للقياس بدلاً من الافتراض: بوابة الذكاء الاصطناعي من TrueFoundry تسجل زمن الاستجابة لكل مسار، حتى تتمكن من التأكد من أن الخطوة الدلالية أو قفزة التسلسل رخيصة بالفعل كما تتوقع.
هل يجب أن يكون التوجيه في البوابة أم في التطبيق؟
تنتمي الآليات إلى البوابة — فهي توحد واجهات برمجة تطبيقات المزودين وتحتفظ ببيانات القياس عن بعد للتكلفة/زمن الاستجابة، لذا يصبح التوجيه إعدادًا بدلاً من كود برمجي. لا يزال التطبيق يمتلك تعريف الجودة ومجموعات التقييم التي تحدد النموذج الأفضل لكل مهمة. فكر في الأمر على النحو التالي: البوابة تقرر أين ترسل الطلب بناءً على سياسة معينة؛ والتطبيق يقرر ما يجب أن تكون عليه هذه السياسة.
ألن يؤدي التوجيه إلى نماذج أرخص إلى الإضرار بالجودة؟
فقط إذا قمت بالتوجيه بناءً على "المشاعر". النقطة الأساسية في القسم 5 هي أن أي تغيير في التوجيه يجب أن يجتاز بوابة جودة مقاسة لكل مهمة قبل نشره. النموذج الرخيص الذي يلبي معايير التصنيف ليس تراجعًا في الجودة؛ أما النموذج الرخيص الذي يُفترض أنه "جيد بما فيه الكفاية" دون قياس، فهو ما يؤدي إلى حدوث ذلك.
كيف أختار مدقق تسلسل؟
يعد التحقق من المخطط (Schema validation) هو المدقق الأرخص والأكثر موثوقية عندما يكون الإخراج منظمًا — فهو حتمي ولا يضيف أي استدعاء للنموذج. بالنسبة للمخرجات المفتوحة، يكون نموذج الحكم (judge model) أكثر قدرة ولكنه يكلف استدعاءً ثانيًا وقد يكون خاطئًا. أيًا كان اختيارك، قم بقياس معدل التصعيد وقم بتنبيه بشأنه، لأن المدقق المتغير هو طريقة شائعة لتحول التسلسل بهدوء إلى مشكلة تكلفة.
هل يضيف التوجيه الدلالي الكثير من زمن الاستجابة؟
يضيف حوالي 5-20 مللي ثانية للتضمين بالإضافة إلى خطوة تصنيف رخيصة — وهو مقبول عادةً مقابل توليد يستغرق مئات المللي ثانية، على الرغم من أنه ليس مجانيًا للتصنيف الذي يستغرق أقل من 100 مللي ثانية أو المسارات الداخلية عالية QPS، لذا قم بقياسه في مسارك الخاص بدلاً من افتراض أنه مجرد ضوضاء. السؤال الحقيقي ليس زمن الاستجابة، بل ما إذا كنت بحاجة إليه على الإطلاق: إذا كان المتصل يمكنه تسمية المهمة برأس (header)، فهذا مجاني وحتمي، ولا يكتسب التوجيه الدلالي أهميته إلا عندما تصل الطلبات غير مصنفة.
كيف يتفاعل هذا مع إسناد التكلفة والتجاوز؟
ترتبط قرارات التوجيه والتكلفة المجمعة الناتجة بنفس إسناد التتبع لكل طلب والمغطى في منشور التكلفة، حتى تتمكن من رؤية المسارات التي تدفع الإنفاق. التجاوز (Failover) هو اهتمام منفصل — يتعلق بالتوافر، وليس التحسين — وسيتم تغطيته في المنشور التالي؛ حافظ على الاثنين كأحداث مميزة ومسجلة بشكل منفصل حتى لا يبدو التراجع الناتج عن انقطاع الخدمة وكأنه قرار تكلفة.
لم يكن جهاز توجيه عمر خاطئًا؛ بل كان غير مراقب. الاستراتيجيات في هذا المنشور آمنة بقدر الأرقام التي تراقبها جنبًا إلى جنب معها — معدل التصعيد، التكلفة المجمعة لكل مسار، بوابة الجودة عند كل تغيير في النموذج. قم بالتوجيه بقوة، ولكن قم بالقياس أولاً.
بوابة الذكاء الاصطناعي من TrueFoundry هي لوحة تحكم على مستوى المؤسسات تقع بين تطبيقاتك وأكثر من 1600 نموذج — عبر OpenAI، وAnthropic، وGoogle، وAWS Bedrock، وAzure OpenAI، ونماذجك المستضافة ذاتيًا — خلف واجهة برمجة تطبيقات واحدة متوافقة مع OpenAI. إنها تحول استراتيجيات التوجيه في هذا المنشور إلى إعدادات بدلاً من تعليمات برمجية: توجيه قائم على الوزن، وقائم على زمن الوصول، وقائم على الأولوية، وتسلسلات النماذج، والحلول الاحتياطية، وتجاوزات المطالبات لكل هدف، وكلها معبر عنها بصيغة YAML وتطبق لكل مسار.
نظرًا لأن البوابة تقوم بالفعل بتوحيد كل مزود وتسجل التكلفة وزمن الوصول وبيانات تعريف الطلب/التوجيه لكل مسار، فهي أيضًا المكان الذي يصبح فيه التوجيه قابلاً للقياس — مكان واحد لاختبار A/B لنموذج، ومراقبة معدل تصعيد التسلسل، وتحديد التكلفة المدمجة. ادمج هذه التتبعات مع إشارات التقييم والملاحظات التي تجمعها من أماكن أخرى، ويصبح نفس العرض عرضًا للجودة أيضًا. يضيف التخزين المؤقت الدقيق والدلالي، والتحكم في الوصول المستند إلى الدور (RBAC)، والميزانيات، وحدود المعدل، والحواجز الوقائية، ويتم نشره كخدمة (SaaS)، في شبكتك الافتراضية الخاصة (VPC)، أو في الموقع (on-prem)، أو معزولًا عن الشبكة (air-gapped) مع الامتثال لمعايير SOC 2 وHIPAA وITAR، ومعترف به في دليل السوق للبوابات الذكاء الاصطناعي من Gartner. راجع الـ وثائق التوجيه وموازنة التحميل أو الـ نظرة عامة على بوابة الذكاء الاصطناعي للتعمق أكثر.
Northwind وعمر هما أمثلة توضيحية. تعكس أسماء النماذج وأسعار الرمز المميز الواحد بطاقات الأسعار العامة للمزودين اعتبارًا من يونيو 2026 وتتغير بمرور الوقت. أرقام التكلفة وزمن الوصول — الفجوة السعرية التي تبلغ حوالي 5 أضعاف، ومثال الدقة المنخفضة بنسبة 70%، والنفقات العامة للتضمين من 5 إلى 20 مللي ثانية — هي افتراضات تمثيلية لتوضيح المفاضلات، وليست قياسات؛ قم بقياس استراتيجيات التوجيه مقابل حركة المرور الخاصة بك ومجموعات التقييم قبل تحديد سياسة الإنتاج.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
