
TrueFoundry anuncia la adquisición de Seldon AI, ampliando su plataforma de control para IA empresarial. Lea el informe completo →

Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.










Solución de IA para evaluar y mejorar las habilidades de lectura de los niños en comunidades marginadas
Wadhwani AI es una organización sin fines de lucro que trabaja en múltiples soluciones de IA llave en mano para las poblaciones desatendidas de los países en desarrollo.
A través del proyecto Vachan Samiksha, el equipo está desarrollando una solución de inteligencia artificial personalizada que los profesores de las zonas rurales de la India pueden utilizar para evaluar la fluidez lectora de los estudiantes y desarrollar un plan de contingencia personalizado para mejorar las habilidades de lectura de cada estudiante.
El equipo había desplegado la solución en las escuelas primarias para llevar a cabo proyectos piloto. Sin embargo, el equipo se enfrentaba a los siguientes problemas que debían resolverse antes de ampliar el alcance del proyecto a más escuelas y estudiantes:
El equipo de TrueFoundry se asoció con el equipo para resolver estos problemas. Con la plataforma TrueFoundry, el equipo pudo:
Wadhwani AI fue fundada por Romesh y Sunil Wadhwani (Parte de la lista de IA de Times100) para aprovechar la IA para resolver los problemas que enfrentan las comunidades desatendidas en los países en desarrollo. Se asocian con organismos gubernamentales y globales sin fines de lucro de todo el mundo para ofrecer valor a través de la solución. Como organización sin fines de lucro, Wadhwani AI utiliza inteligencia artificial para resolver problemas sociales en los campos de la agricultura, la educación y la salud, entre otros. Algunos de sus proyectos incluyen:
Wadhwani AI también trabaja con organizaciones asociadas para evaluar su preparación para la IA, es decir, su capacidad para crear y utilizar soluciones de IA de manera eficaz y sostenible. El trabajo de Wadhwani AI tiene como objetivo utilizar la IA para el bien y mejorar la vida de miles de millones de personas en los países en desarrollo.
Las habilidades de lectura son fundamentales para la base educativa de cualquier niño. Desafortunadamente, muchos estudiantes de las regiones rurales y desfavorecidas de la India y otros países en desarrollo carecen de estas habilidades. Para resolver este problema desde un punto de vista fundamental, el equipo de IA de Wadhwani ha desarrollado una herramienta de frecuencia de lectura oral basada en la IA llamada Vachan Samiksha.
La herramienta utiliza la inteligencia artificial para analizar el rendimiento de lectura de cada niño. Por el momento, se dirige principalmente a las regiones rurales y semiurbanas del país y se utiliza en todos los grupos de edad. Para que la solución sea generalizable en la mayor parte del país, el equipo ha creado un modelo que incluye el acento para evaluar los idiomas regionales y el inglés. La evaluación manual de estas habilidades tiene sus sesgos y, a menudo, es inexacta.
La solución se ofrece a los usuarios (profesores de las escuelas objetivo) a través de una aplicación que invoca el modelo que se implementa en la nube. Se obliga al estudiante a leer un párrafo, que la aplicación graba y lo envía a la nube. En la nube, el modelo evalúa la precisión, la velocidad y la comprensión de la lectura y otros retrasos complejos en el aprendizaje que podrían pasarse por alto en una evaluación normal. Además de evaluar estas habilidades, la aplicación también crea un plan de aprendizaje personalizado para cada estudiante a fin de facilitar su aprendizaje y también crea informes demográficos para que las autoridades gubernamentales tomen medidas a nivel macroeconómico. El equipo había desplegado el modelo para el proyecto piloto con el servicio de aprendizaje automático gestionado del proveedor de la nube
Cuando comenzamos nuestra colaboración con el equipo de Vachan Samiksha dentro de Wadhwani AI, el equipo había estado aprovechando la pila nativa de MLOps de su proveedor de nube para implementar el modelo para su proyecto piloto en el Departamento de Educación de Gujarat.
La configuración de su infraestructura era la siguiente:
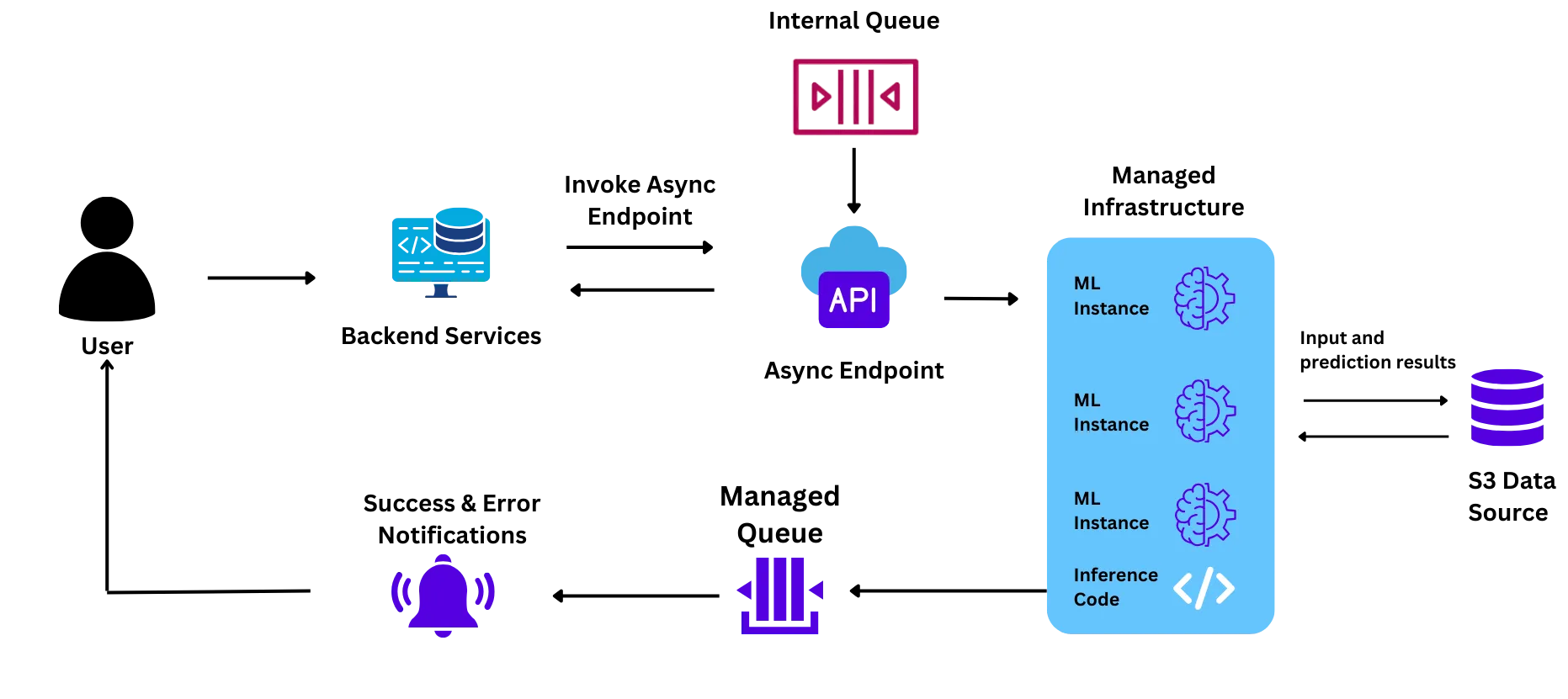
El equipo se enfrentó a desafíos con esta configuración al intentar llevar a cabo la primera prueba piloto, lo que los motivó a probar otras soluciones:
Se esperaba que el proyecto piloto se ejecutara a gran escala (unos 6 millones de estudiantes en un mes). Sin embargo, el equipo no confiaba en que el servicio de aprendizaje automático gestionado pudiera soportar esta escala porque:
Durante la prueba piloto, el equipo tuvo problemas con la velocidad de escalado y algunas cápsulas no salieron como se esperaba. Sin embargo, para resolver el problema, el equipo se puso en contacto con los representantes del proveedor de servicios en la nube, quienes a su vez se pusieron en contacto con el equipo técnico. Esto provocó un retraso en el sistema y provocó un retraso en el piloto.
Cuando el tráfico de solicitudes aumentó durante la fase piloto, los módulos tuvieron que escalar horizontalmente (crear nuevos nodos que pudieran captar y procesar algunas de las solicitudes de la cola). Este proceso tardaba entre 9 y 10 minutos por cada pod nuevo que se generaba, lo que provocaba retrasos en las respuestas y una mala experiencia para el usuario final.
Las instancias de GPU son muy caras debido a la escasez mundial de chips. A esto hay que añadir el margen de beneficio del 20 al 40% para las instancias de aprendizaje automático que aplica el proveedor de la nube. Esto hizo que el coste de las instancias fuera muy elevado e inviable para el equipo a la escala en la que querían ejecutar el proyecto.
Cuando conocimos al equipo de Vachan Samiksha, estaban en el período entre su primer piloto y el segundo. Faltaba menos de una semana para el piloto y tuvimos que:

Durante el tiempo anterior al piloto:
Nuestro equipo ayudó al equipo de IA de Wadhwan a instalar la plataforma en sus propios Kubernetes sin procesar. Tanto el plano de control como el clúster de carga de trabajo se instalaron en su propia infraestructura. Todos los datos, los elementos de la interfaz de usuario necesarios para interactuar con la plataforma y los procesos de carga de trabajo para entrenar e implementar los modelos permanecieron en su propia VPC. La plataforma también cumplía con todas las normas y prácticas de seguridad de la empresa.
Ayudamos al equipo a entender cómo interactúan los diferentes componentes durante el proceso de formación e incorporación. Les explicamos cómo configurar los recursos, configurar el escalado automático e implementar el modelo.
El equipo de IA de Wadhwani pudo migrar la aplicación por sí solo con la mínima ayuda del equipo de TrueFoundry. Esto se hizo en una llamada de 1 hora con el equipo.
Una vez implementada la aplicación, el equipo comenzó a probar la carga a nivel de producción en ella. El equipo amplió la aplicación de forma independiente a más de 100 nodos con un argumento sencillo basado en la interfaz de usuario de TrueFoundry, que es 5 veces mayor que la escala más alta alcanzable anteriormente. También intentaron comparar la velocidad de escalado de los nodos, que era mucho más rápida (entre 3 y 4 veces) que la proporcionada por ellos.
Una vez finalizadas las pruebas de carga, el equipo implementó la aplicación piloto y estaba preparado para implementarla en la segunda fase del piloto, que se implementó en 1000 escuelas, 9000 profesores y más de 2 lakh de estudiantes.
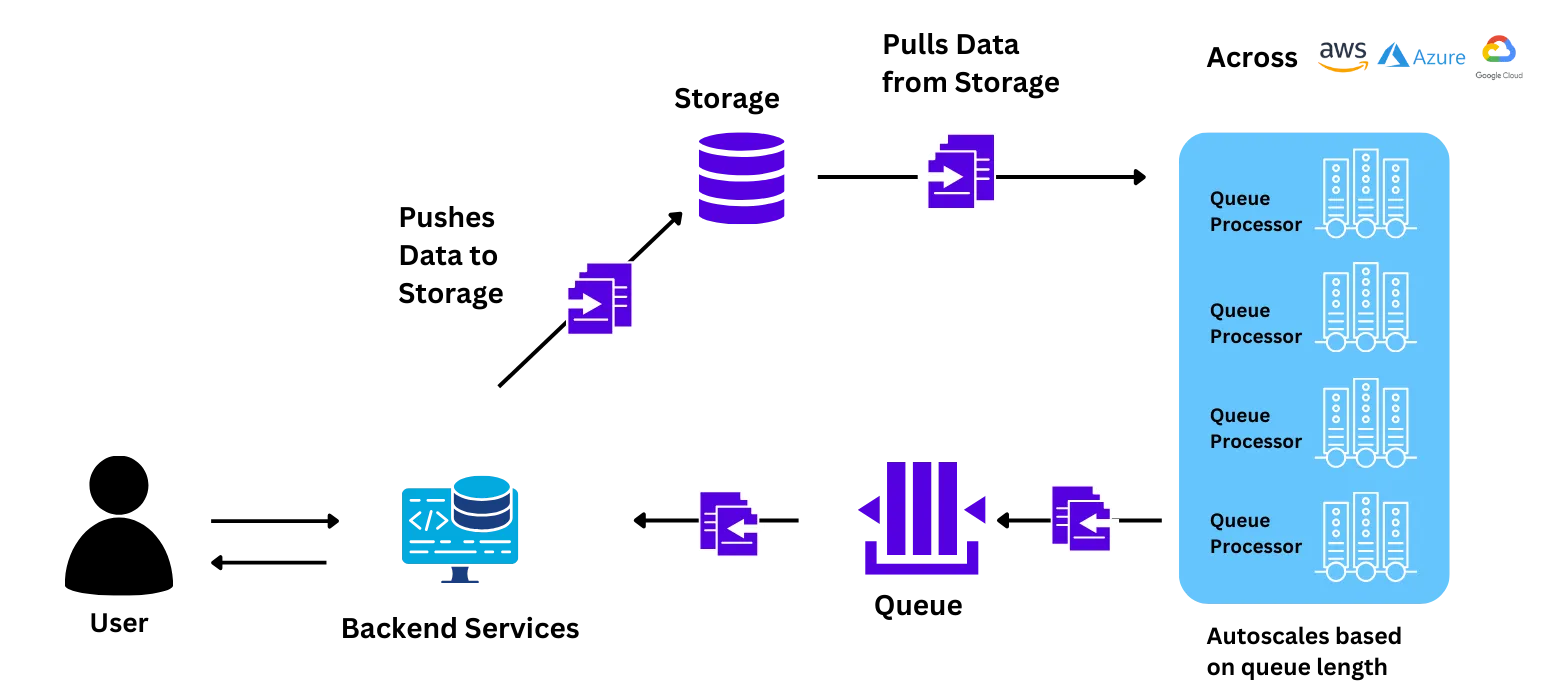
Con un esfuerzo mínimo de menos de 10 horas, el equipo de IA de Wadhwani pudo lograr una mejora significativa en la velocidad, el control y los costos. Algunos de los principales cambios que se dieron cuenta fueron los siguientes:
Los científicos de datos y los ingenieros de aprendizaje automático pudieron configurar varios elementos, lo que les resultó difícil hacerlo a través de la consola del proveedor de la nube o tuvieron que confiar en el equipo de ingeniería:
En función de la longitud de la cola y en el aumento del número máximo de réplicas o nodos a 70 en lugar del límite anterior de 20
Como la mayor parte del tráfico piloto llegaba durante el horario escolar, cuando los profesores interactuaban con los estudiantes, hubo un mínimo de solicitudes, si es que las hubo, durante la noche y por la noche. Teamconstant pudo establecer un cronograma escalable con el que los módulos se redujeron al mínimo durante las horas de inactividad (por la tarde y por la noche). Esto permitió ahorrar entre un 15 y un 20% del coste del proyecto piloto.
El equipo podía supervisar fácilmente el tráfico, la utilización de los recursos y las respuestas directamente desde la interfaz de usuario de TrueFoundry. También recibían sugerencias a través de la plataforma cada vez que había un sobreaprovisionamiento o un aprovisionamiento insuficiente de recursos
Para probar el escalado con TrueFoundry, el equipo envió una ráfaga de 88 solicitudes a la aplicación y comparó el rendimiento del servicio de aprendizaje automático gestionado del proveedor de nube con el de TrueFoundry. Todas las configuraciones del sistema se mantuvieron según la lógica de escalado (en función de la longitud de la cola de espera, la cantidad inicial de nodos, el tipo de instancia, etc.)
Nos dimos cuenta de que TrueFoundry podía ampliarse un 78% más rápido que el servicio de aprendizaje automático gestionado, lo que proporcionaba al usuario respuestas mucho más rápidas. El tiempo total necesario para responder a la consulta fue un 40% menor con TrueFoundry.
El costo en el que incurrió el equipo para el proyecto piloto se redujo en aproximadamente un 50% al trasladarse a TrueFoundry. Esto se debió a los siguientes factores:
Si bien el servicio Managed ML Service estaba limitado por la disponibilidad de instancias de GPU en la misma región del proveedor de nube, TrueFoundry puede agregar nodos de trabajo al sistema que podrían estar en cualquier región o proveedor de nube.
Esto significa que:
TrueFoundry proporciona una integración perfecta con cualquier herramienta que el equipo quiera usar. Con el proveedor de la nube, esto estaba limitado por las opciones de diseño adoptadas por el proveedor y sus integraciones nativas. Por ejemplo, el equipo quería usar NATS para publicar mensajes, algo que el servicio nativo del proveedor de nube no ofrecía actualmente. TrueFoundry hizo que tomar este tipo de decisiones fuera algo trivial para el equipo de IA de Wadhwani.







Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada



